视觉单词
参考
视觉词袋(BoVW,Bag of Visual Words)模型,是“词袋”(BoW,Bag of Words)模型从自然语言处理与分析领域向图像处理与分析领域的一次自然推广。对于任意一幅图像,BoVW模型提取该图像中的基本元素,并统计该图像中这些基本元素出现的频率,用直方图的形式来表示。通常使用“图像局部特征”来类比BoW模型中的单词,如SIFT、SURF、HOG等特征,所以也称视觉词袋模型。
利用BoVW模型表示图像,获得图像的全局直方图表示,主要有四个关键步骤:
- 图像局部特征提取(Image Local Features Extrication)
一般是SIFT算法提取图像的局部特征。 - 视觉词典构造(Visual Dictionary Construction)
通常所采用的处理方法是对训练图像的所有局部特征向量进行聚类分析,将聚类中心定义为视觉单词。所有视觉单词组成视觉词典,用于图像的直方图表示。所有的局部特征数量太多,我们应该用一个特征表示相似的一类特征向量。 - 特征向量量化(Feature Vector Quantization)
向量量化结果是将图像的局部特征向量量化为视觉单词中与其距离最相似的视觉单词。向量量化过程实际上是一个搜索过程,通常采用最近邻搜索算法,搜索出与图像局部特征向量最为匹配的视觉单词。对一张图像,我们像查字典一样,将每个局部特征归类到视觉词典中的某一类。 - 用视觉单词直方图表示图像,也称为量化编码集成(Pooling)
最后得到词典中每个视觉单词出现的频率,用直方图表示。
TF-IDF算法
参考
TF-IDF有两层意思,一层是"词频"(Term Frequency,缩写为TF),另一层是"逆文档频率"(Inverse Document Frequency,缩写为IDF)。

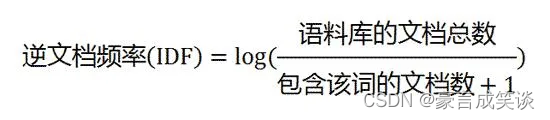
当有TF(词频)和IDF(逆文档频率)后,将这两个词相乘,就能得到一个词的TF-IDF的值。某个词在文章中的TF-IDF越大,那么一般而言这个词在这篇文章的重要性会越高,所以通过计算文章中各个词的TF-IDF,由大到小排序,排在最前面的几个词,就是该文章的关键词。
Inverse index倒排索引
一个未经处理的数据库中,一般是以文档ID作为索引,以文档内容作为记录。
而Inverted index 指的是将单词或记录作为索引,将文档ID作为记录,这样便可以方便地通过单词或记录查找到其所在的文档。

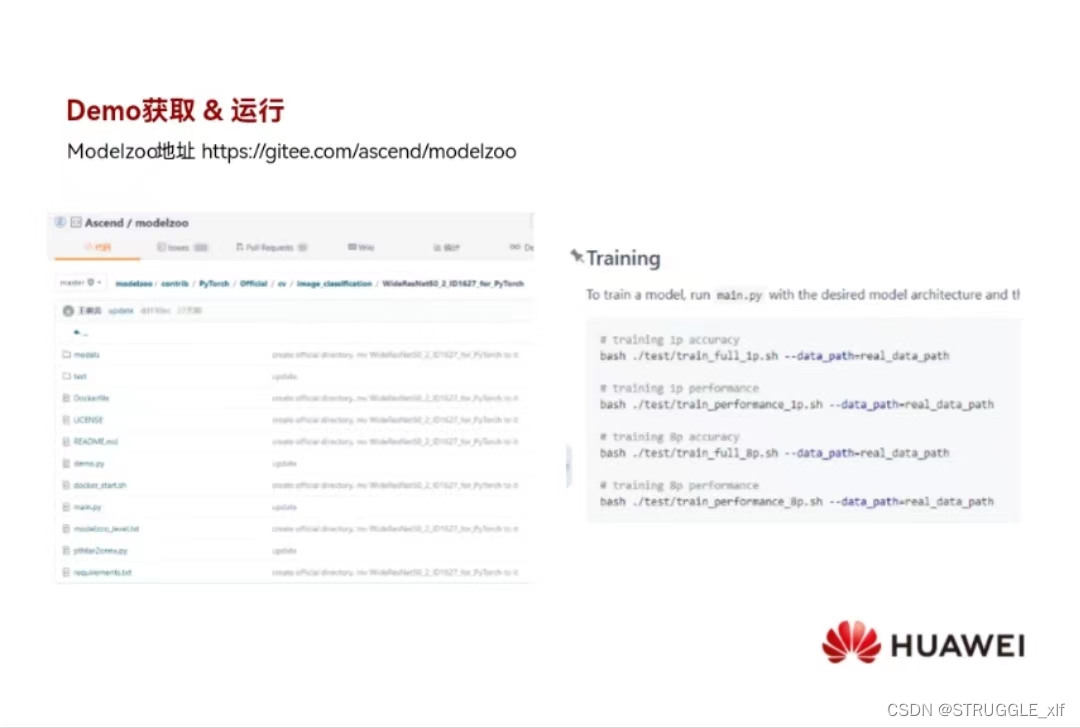
3. Building and Using the Vocabulary Tree
词汇树是一个分层的聚类得到的分层的量化。在树的无监督训练中使用了大量的代表性描述符向量。
在一开始的视觉词典中,是直接得到k个聚类(或量化单元),词汇树中k是每个节点的孩子的数量。一开始,一个最初的聚类用于数据得到k和聚类中心,然后将训练数据分成k组,根据距聚类中心的距离。
然后对每个组进行相同的过程,词汇树一层一层的生成,直到最大层数L。每层聚类中心只由父节点量化单元中的描述符得到。
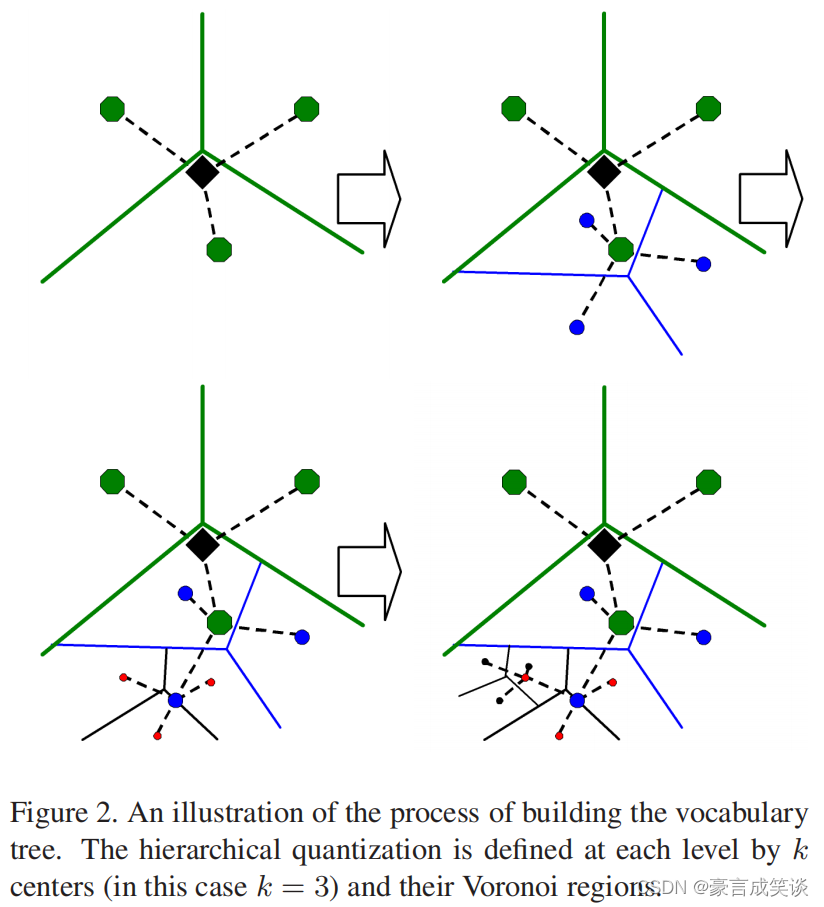
总共生成kL个节点,如果k不是太大,这是非常有效的。
词汇树以一种集成的方式定义了视觉词典和一个高效的检索过程。这与传统的视觉词典不同。
传统的视觉词典,增加词汇数据量的花费是非常大的,然而在词汇树中是叶子节点(单词数量)的对数。内存花费是
k
L
k^L
kL的线性关系。总节点的数量是
k
L
k^L
kL
4. Definition of Scoring
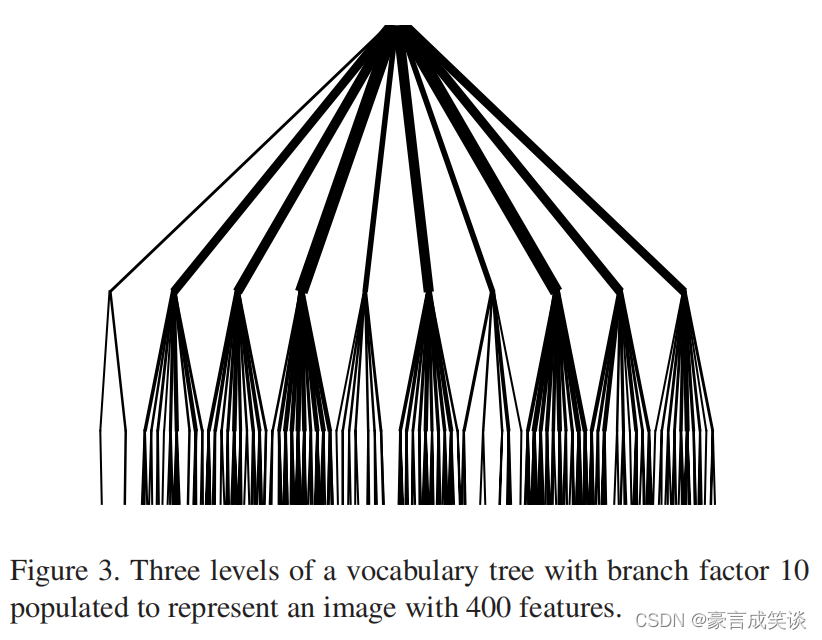
一旦定义了量化,我们希望根据数据库图像和查询图像的描述符的词汇表树的路径的相似性来确定数据库图像与查询图像的相关性。图3给出了这种图像的表示方式。
每个节点赋予一个权重
w
i
w_i
wi(通常基于熵得到),然后计算查询向量q和数据向量d如下公式所示。i表示节点i。
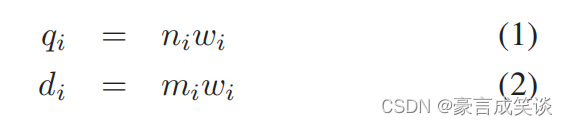
n和m分别是查询图片和数据集图片的描述符向量,然后计算数据库图像的相关性评分。
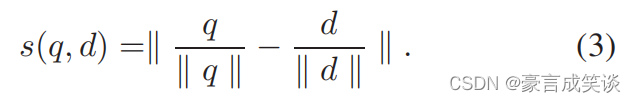
范数选择L1范数比L2范数效果好。
简单的情况下w被设置为一个常数,N是image的数量,Ni是至少有一个描述符经过节点i的图片的数量。也就是TFIDF算法。

与TFIDF算法比较,可以看出这里计算的是IDF,也就是总的图片数和包含该节点表示的特征描述符的图片数。
不同层的w可以通过好几种方式得到,比如分配每个节点相对于路径中它上面的节点的熵,这似乎是正确的,但是我们发现使用相对于树的根的熵和忽略路径内的依赖关系更好。
我们发现,对于检索质量来说,最重要的是拥有大量的词汇表(大量的叶节点),而不是给词汇表树的内部节点过强的权重。原则上,叶子节点的数量越多检索效果最好,所以根据根节点计算叶子节点的熵效果好。也就是说可以之给叶子节点赋值w。这里作者给的解释是如果词汇数量过多,那么描述向量的可变性和噪声等会使得其很容易属于其他的量化单元,但是树型结构限制了这一风险,是的其不会偏离太多。(聚类中心越多,每个聚类的区域越小,每个点很容易偏移进其他区域,而树型结构由于其父节点的限制,很难偏移很远)。
也可以使用stop list,其中wi为最频繁和/或不频繁的符号设置为零。
5. Implementation of Scoring
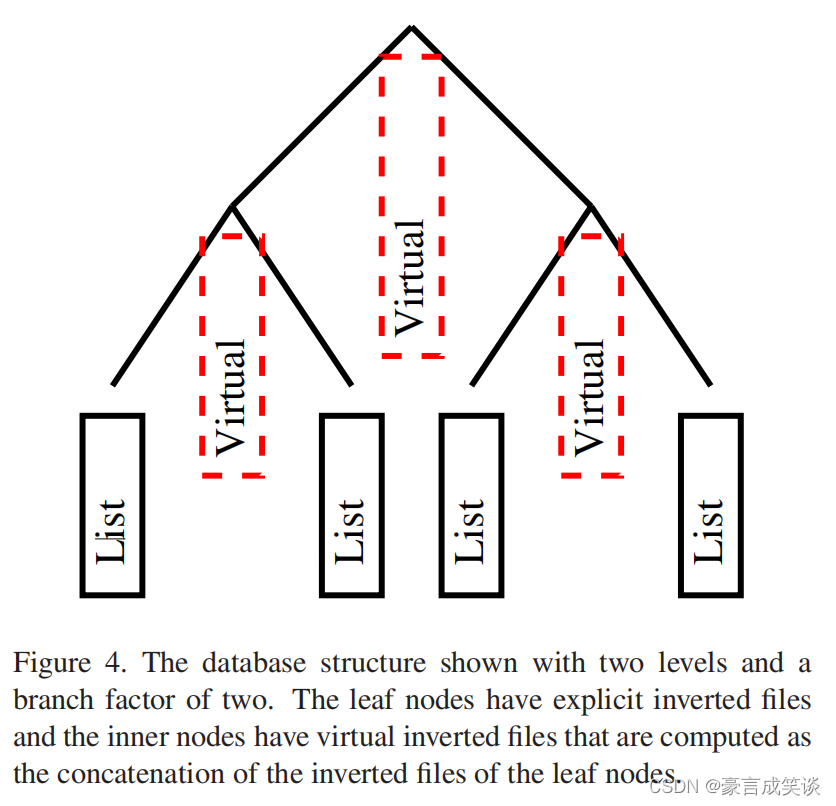
使用了倒排索引,具体来说就是每个节点对应一个文件,文件中存有包含这个节点特征的图像的id。以及出现的频率。正向文件也可以用作补充,以查找特定图像中存在哪些视觉单词。在我们的实现中,只有叶节点被显式表示,而内部节点的反向文件只是叶节点的反向文件的连接,见图4。倒排文件的长度存储在词汇表树的每个节点中,这个长度实际上就是定义节点熵的文档频率,超过一定长度将阻止评分。假设每个节点的熵是固定的和已知的,这可以通过对特定数据库的预先计算来完成,或者通过使用一个大型的代表性数据库来确定熵。然后,可以预先计算表示数据库图像的向量,并归一化到单位大小,例如,当图像被输入数据库时。类似地,查询向量被归一化为单位大小,然后计算他们的p范数。
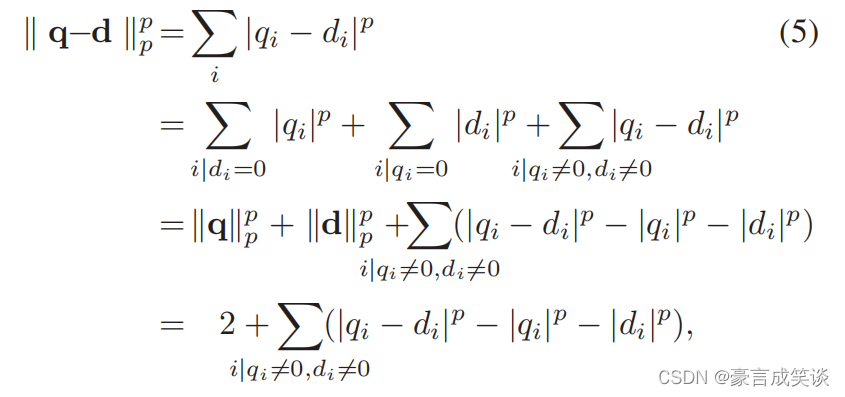
假设需要查询的图片有M个word,首先取得第一个word,从树中找到最近的最下层子节点。这个字节点中可以找到很多图片的索引以及各自的权重。这样循环M次每一个word都能拿到各自的图片索引和权重(上一节计算的评分)。最终把M个word的图片索引和权重汇聚到一起,哪个图片的权重最大自然也就计算出来了。
总结一下,词汇树的三个步骤:
- 构建词汇树:使用聚类算法,构建一个树型的视觉词典,叶子节点表示单词。
- 计算每个数据库图像的评分:对于数据库中每个图像,对其每个单词(叶子节点)计算评分。这样词汇树中每个叶子节点存储图像索引和得分。
- 图像检索:对查询图像中每个单词,从树中找到对应叶子,拿到图像索引和得分,计算查询图像和数据库图像的p范数,最后对所有单词的p范数求和,并比较所有数据库图像(已经得到索引的)的大小。(即比较查询图像与数据库图像的距离)