【(强推)李宏毅2021/2022春机器学习课程】
Slide地址
一、问题引入
1.模型的输入
无论是预测视频观看人数、视频处理、语言识别,这些所有的model中,输入数据都可以视作为一个向量(vector),模型的输出为一个数值或者一个类别。考虑一种情况下,模型输入的向量(序列)的长度不会一直保持不变,因此就可以将句子中的每个单词描述为一个向量,整个句子就是一组向量的集合,并且每个向量集合的大小都不相同:
一般在文字处理任务中,采用One-Hot Encoding(独热编码)方法。每个向量的长度为世界上所有词汇的数目,永不同位置为1表示不同的单词,可以表示为如下:
- apple = [ 1 0 0 0 0 …… ]
- bag = [ 0 1 0 0 0 …… ]
- cat = [ 0 0 1 0 0 …… ]
- dog = [ 0 0 0 1 0 …… ]
- elephant = [ 0 0 0 0 1 …… ]
这类方法虽然可以实现对所有的单词的表示,但是其向量的长度过长不利于后续数据处理,其次其也没有包含单词间关系的其他任何有意义的信息。
另外一种方法采用word Embedding,其可以包括更多有效的信息,可以描述词汇类别间的关系。其实际上也是一种语义向量,一个句子可以被描述为长度不一的向量。利用word Embedding描述的词汇之间会展现出词汇类别间的关系,因此可以被描述为:
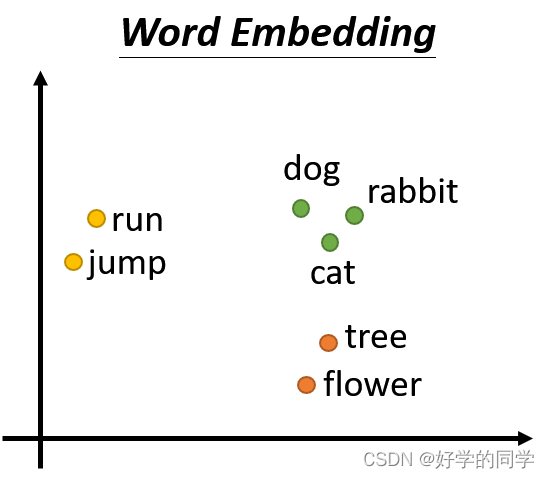
同类别间的词汇信息相互靠近。
除此以外,语音信号和图像信号都可以被描述为一组向量:
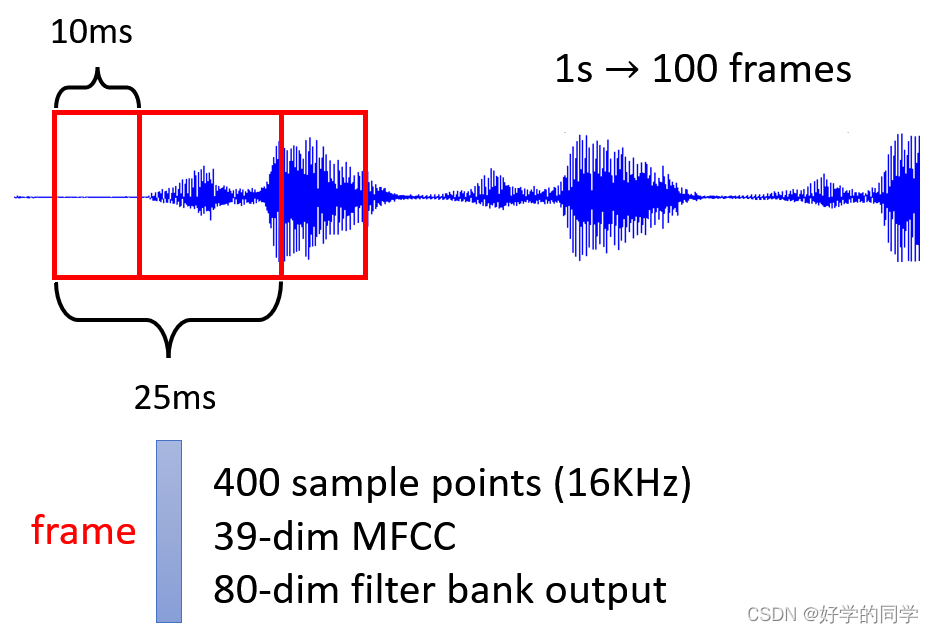
语音信号
对一段语音信号进行处理,可以选取一个固定长度的滑动窗口,把一个滑动窗口内部的数据可以称为语音数据的一个帧,按照预定的步长移动这个窗口就可以得到这一段语音信号对应的向量集。
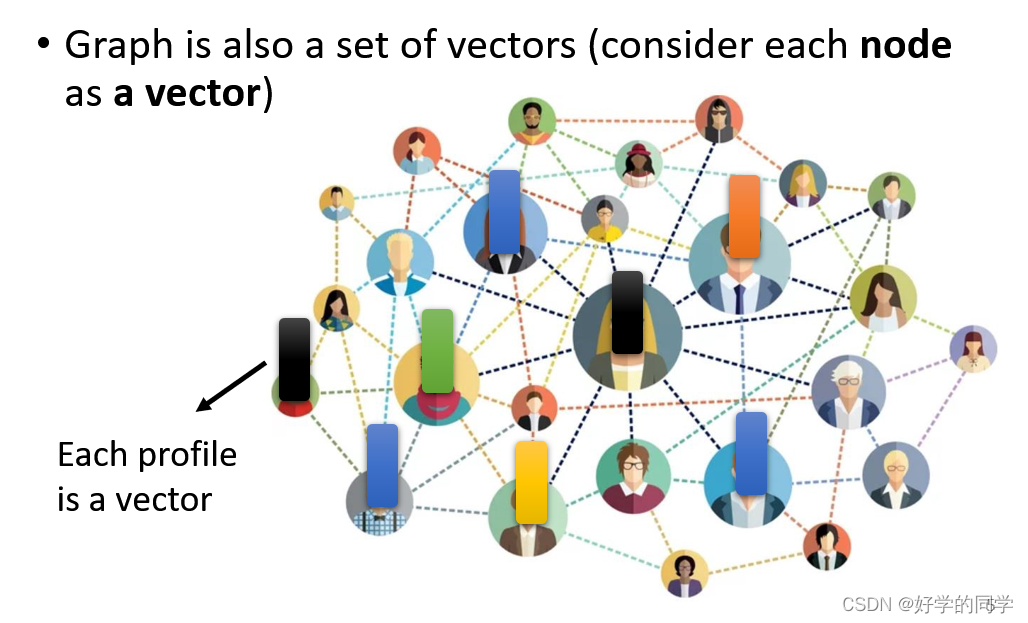
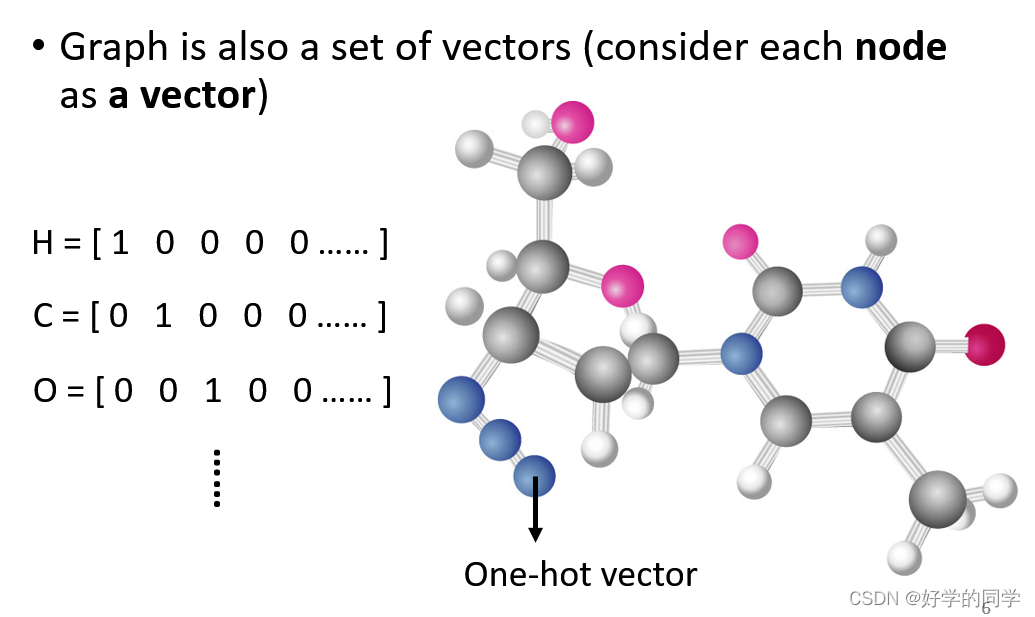
图论数据
1.在社交网络中,每个人可以代表社交网络的一个节点,根据每个人的个人与社交网络其他节点的关系,可以将每个人描述一个向量。
2.在分子的构成中,分子中的每个原子与社交网络中的每个个体一样可以被描述为向量,因此每个分子实际上就是一个向量集合。
2.模型的输出
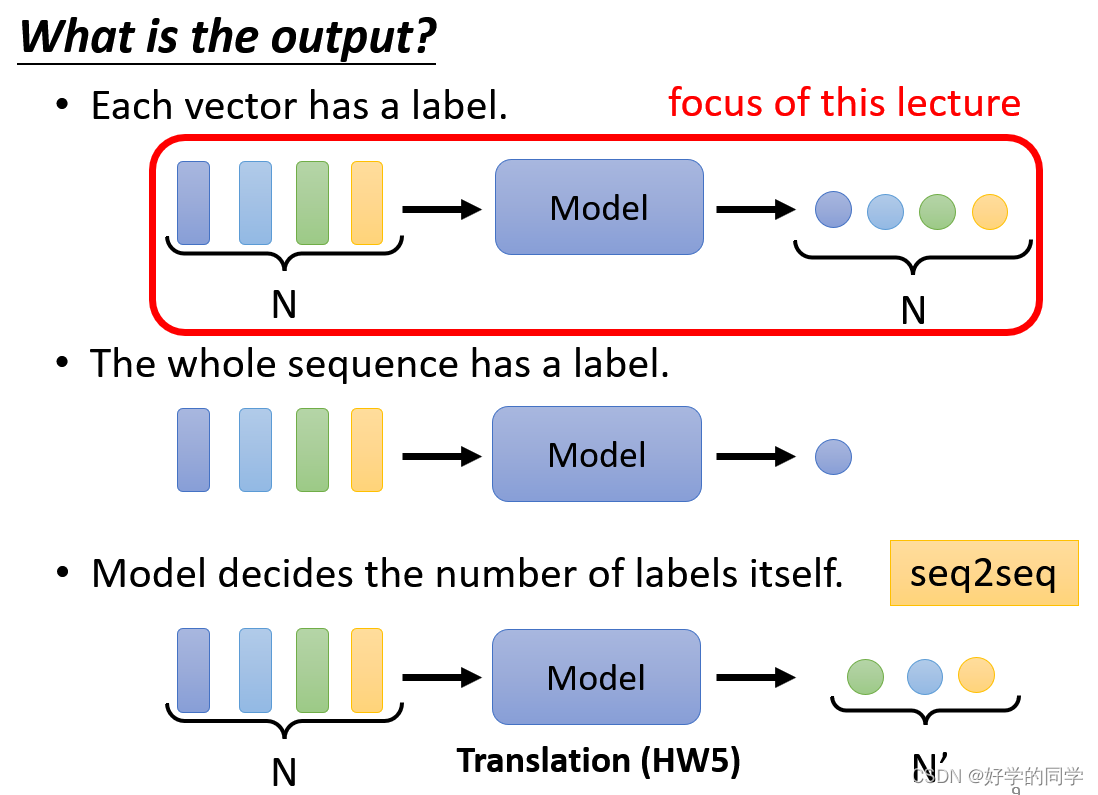
输出类型分别有三种
1.一对一:每个向量会对应一个输出
- 文字处理:词性标注(标注每一个单词实际为动词、名词or形容词etc...)
- 语音处理:一段声音中有一系列的向量,每个向量会对应语音的一个音标
- 图像识别:在进行图像识别分类时,每张图片会对应一个相应的类别
2.多对一:多个向量对应一个输出
- 语义分析:语言的正负面评价
- 语音识别:识别某人的音色
- 图网络:给出当前分子的属性
3.多对多:多个向量对应多个向量,输出向量的长度由机器自行确定
- 翻译:语言A翻译为语言B
- 语言识别:多个frame转换为一段话
3.序列表注问题(Sequence Labeling)
在对Sequence进行标注的时候,会出现这样的问题。采用FC网络结构,输入一个句子,输出对应的单词数据的标签。当一个句子中出现相同的单词时,同时相同的单词具有不同词性的时候(I saw a saw.)此时如果不考虑上下文信息,就无法对两个saw进行区分。利用滑动窗口,考虑每个向量其向量其他向量的性质。
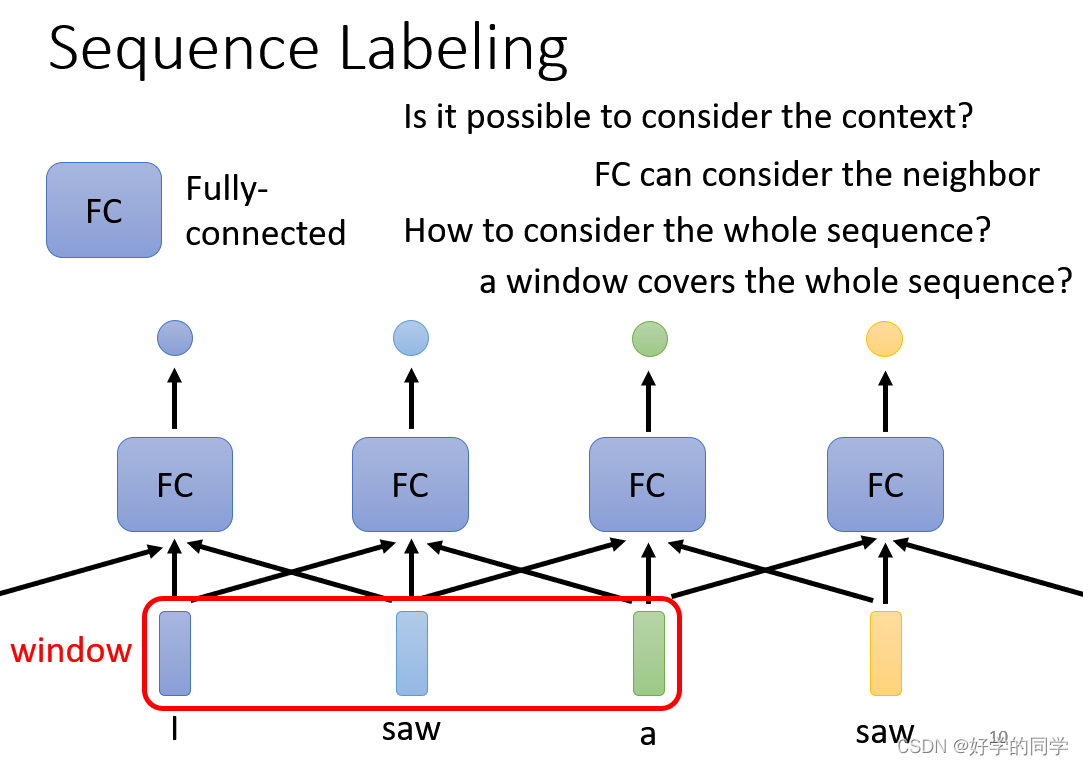
但这一类方法有极限,不能考虑整个Sequence的信息,同时Sequence的长度也不是固定的,其也是有长有短的。同时大的window的参数会很多,对计算能力提出了挑战。在这样的背景之下Self-attention应运而生。
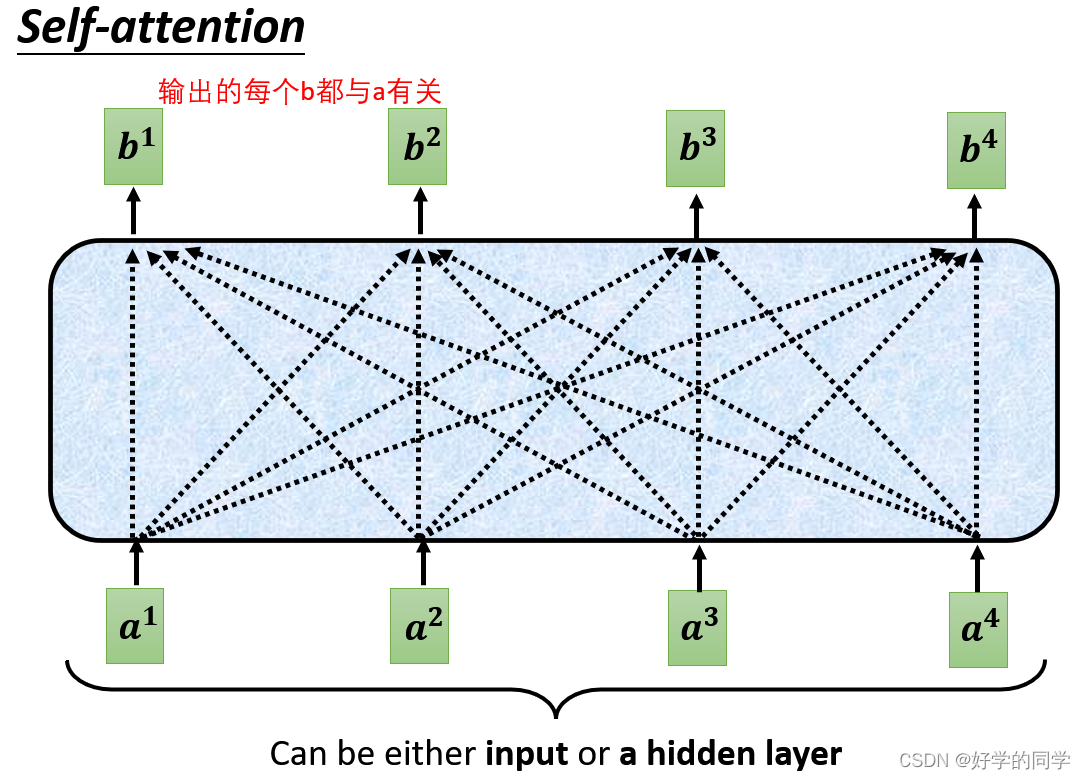
二、Self-Attention自注意力机制
将考虑整个Sequence信息的向量输入到Self-Attention中,输出对应个数的向量,并将其输出的向量作为全连接层的输出,最后输出标签,多次重复此过程即可。
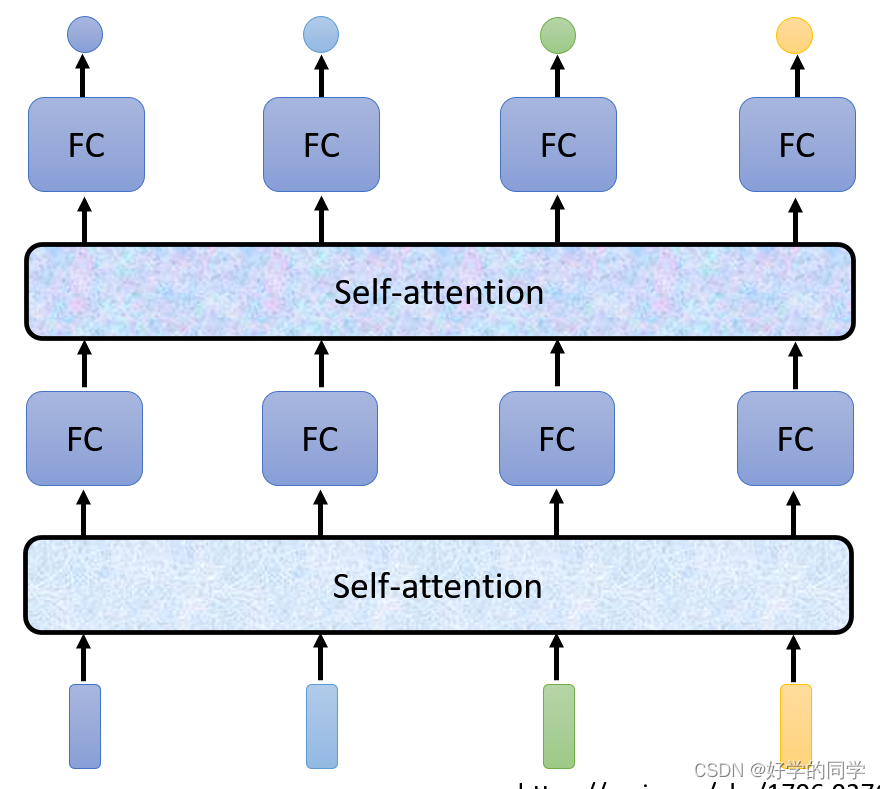
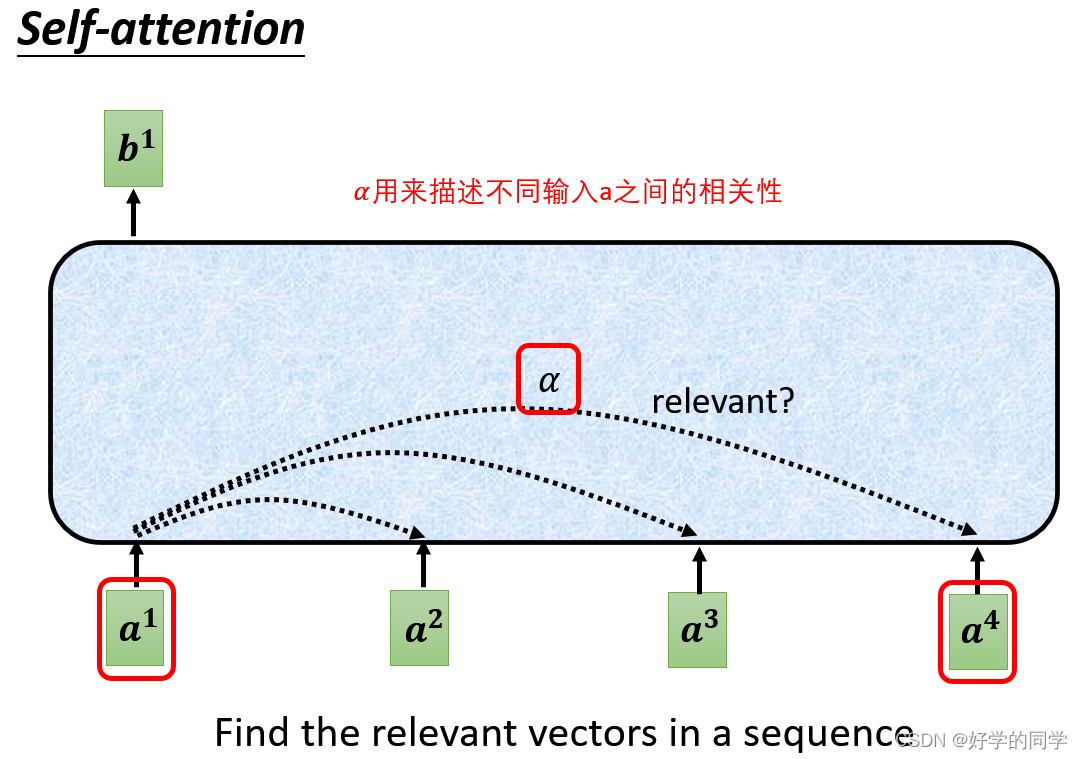
1.自注意力机制的工作原理
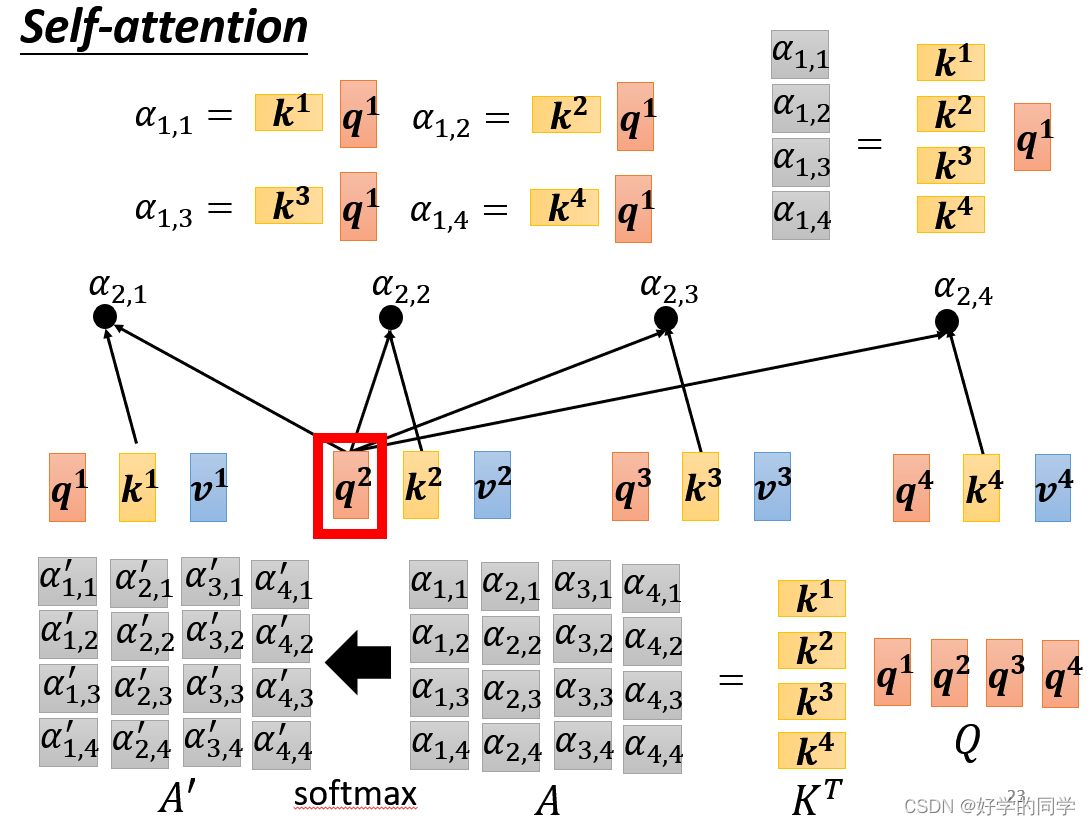
在工作中实际上只需要确定三个向量:Query、Key和Value。
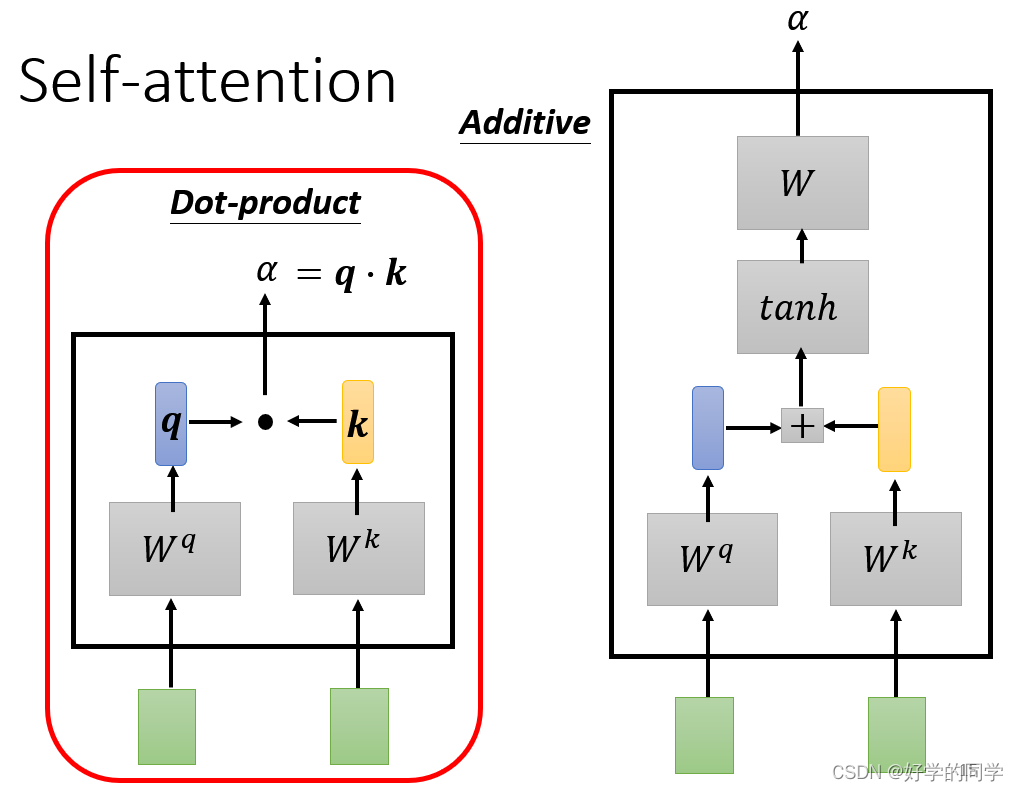
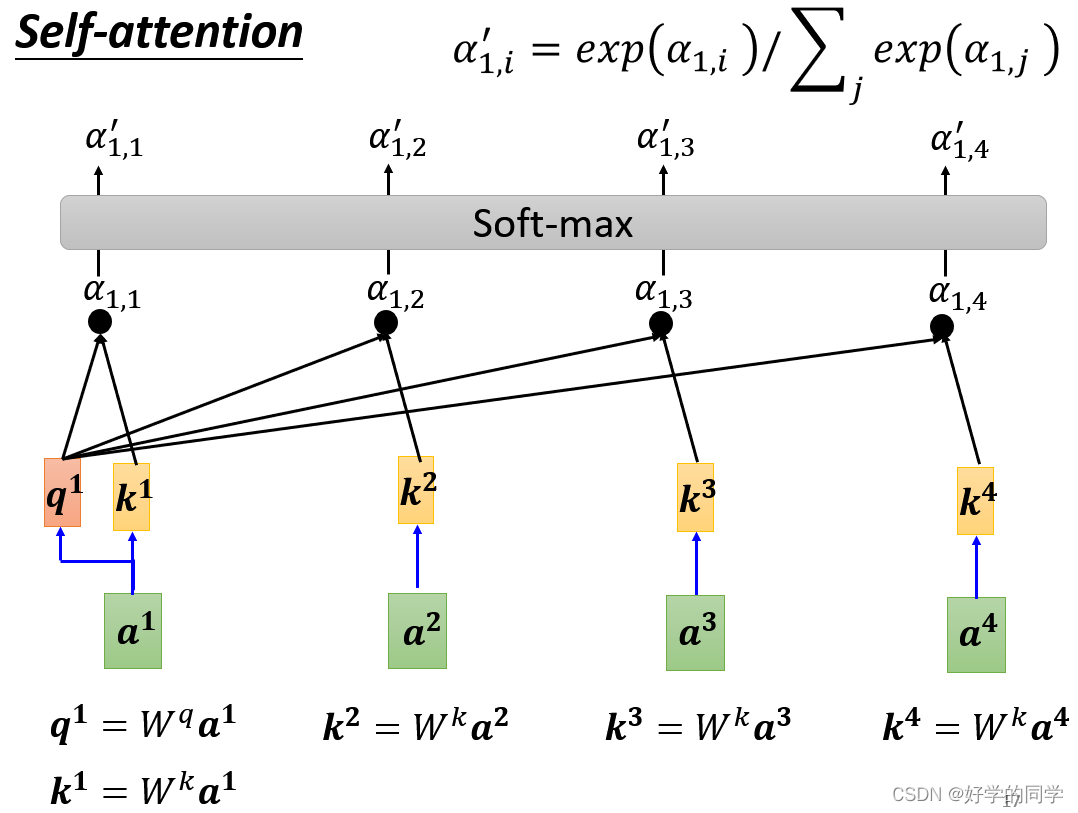
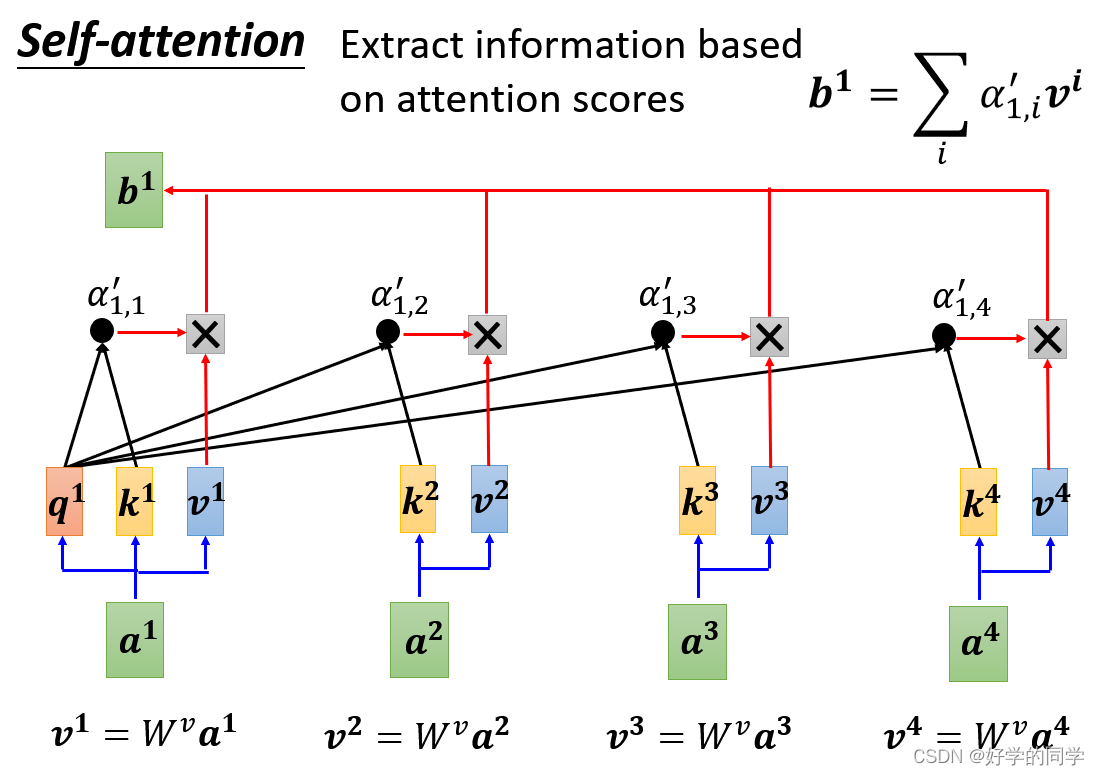
自注意力机制实际的计算过程可以分解为一下三步:
- 输入矩阵
分别乘以三个
得到三个矩阵
,经过处理可以计算得到注意力矩阵
- 输出
即:
其中表示向量的长度。

 2.多头注意力机制(Multi-head Self-attention)
2.多头注意力机制(Multi-head Self-attention)
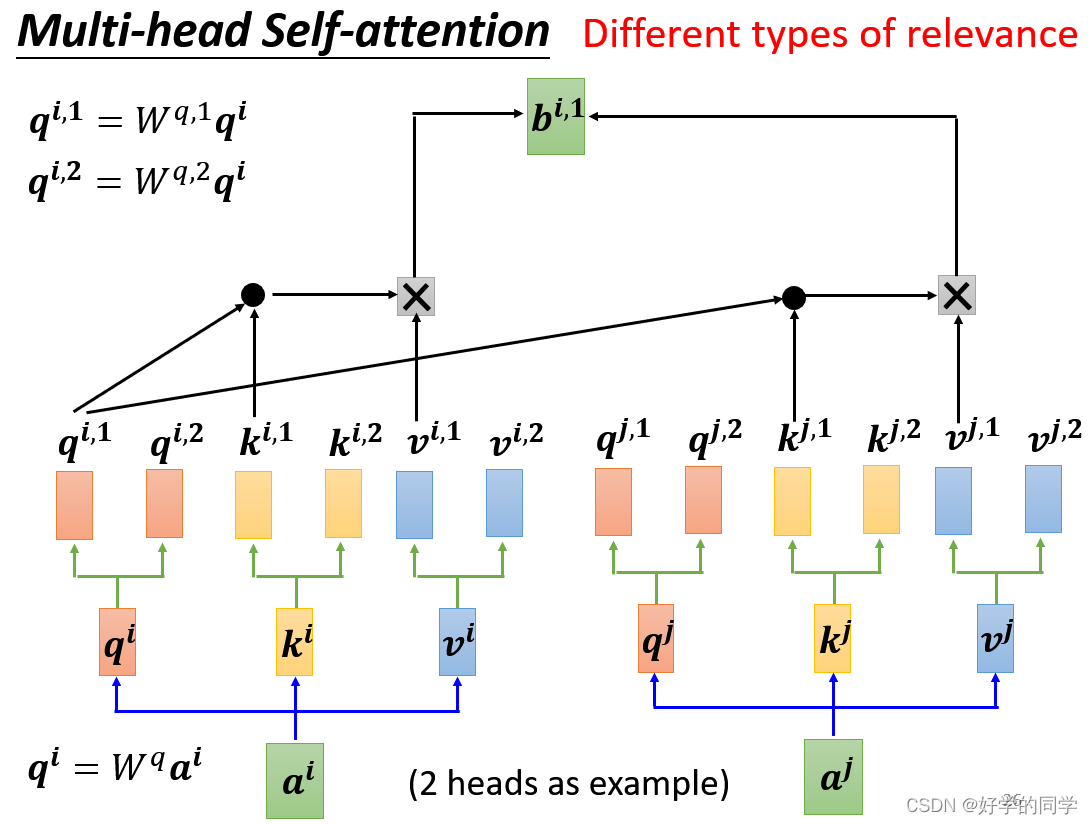
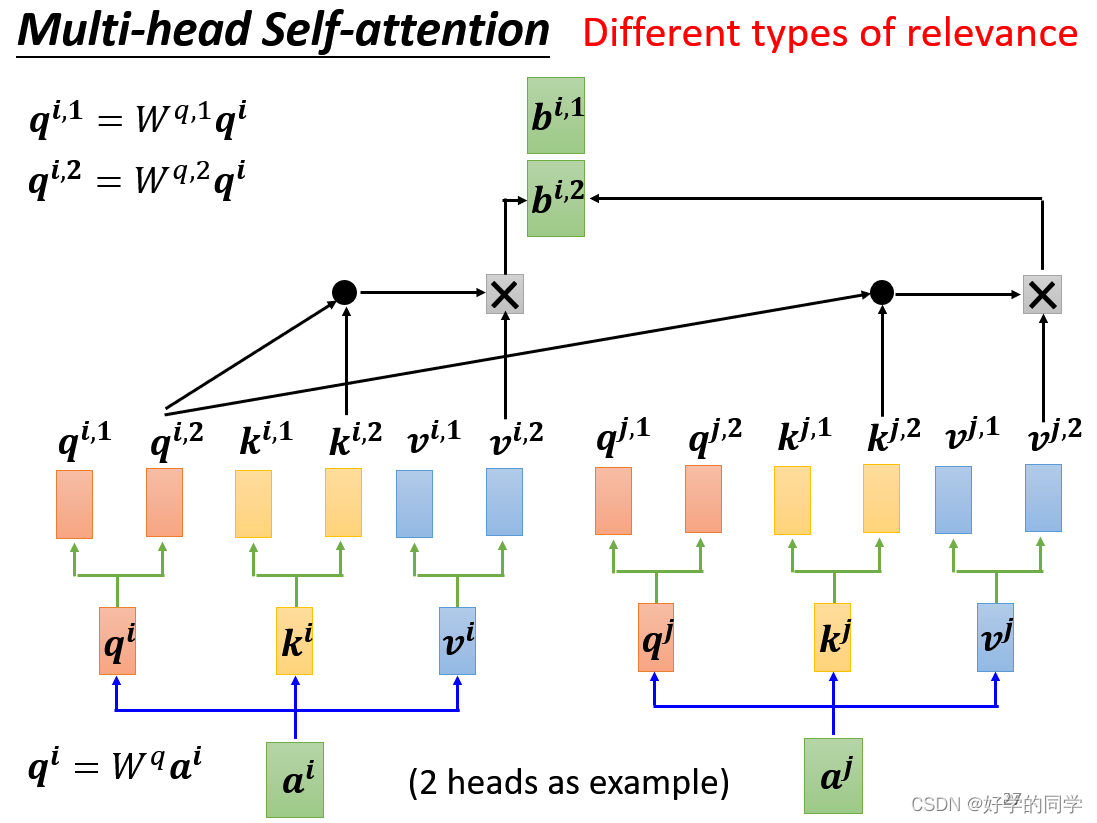
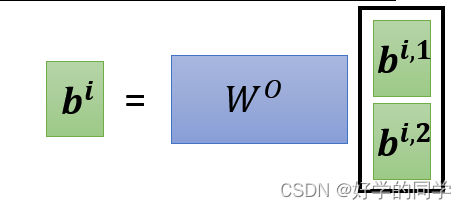
在上述公式中,在MutiHead的情况下,输入还是Q,K,V,输出为不同Head的输出结果,接着将结果投影到。其中对每一个Head,可以将Q,K,V通过不同的可学习参数
投影到一个低维面上,再做注意力机制Attention,最后输出结果。
对于Self-attention来说,并没有序列中字符位置的信息。例如动词是不太可能出现在句首的,因此可以降低动词在句首的可能性,但是自注意力机制并没有该能力。因此需要加入 Positional Encoding 的技术来标注每个词汇在句子中的位置信息。
为什么要在Self-Attention中进行缩放?
维度较大时,向量内积容易使得 SoftMax 将概率全部分配给最大值对应的 Label,其他 Label 的概率几乎为 0,反向传播时这些梯度会变得很小甚至为 0,导致无法更新参数。因此,一般会对其进行缩放,缩放值一般使用维度 dk 开根号,是因为点积的方差是 dk,缩放后点积的方差为常数 1,这样就可以避免梯度消失问题。
3.位置编码(Position Encoding)
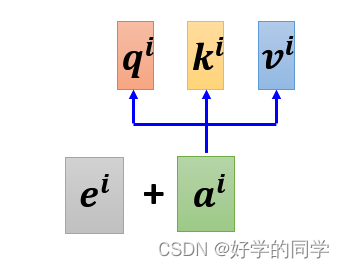
有时候位置信息对Sequence也很重要,因此需要对这个信息也进行考虑。在实验中为每一个位置设定一个vector,定义为Position Vector (),不同位置具有不同的vector。尽管如此,位置编码也可以通过学习来得出。
三、其他相关的应用
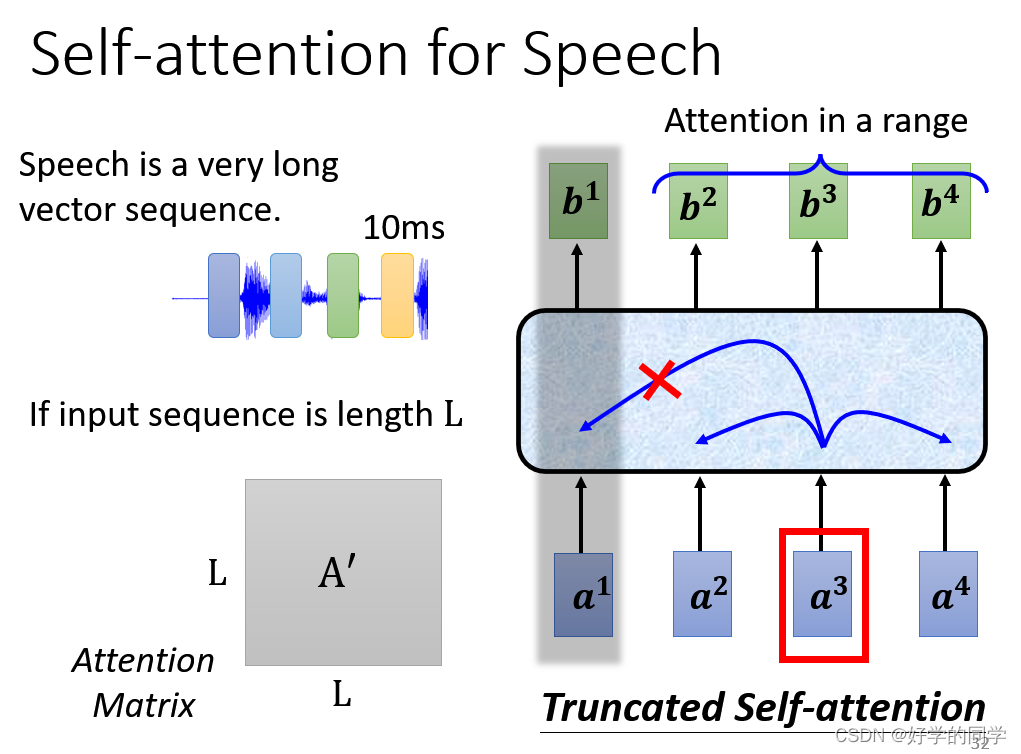
1.语音辨识(只看前后一部分的信息Truncated Self-attention)
2.图像识别
将不同通道的每一个像素点(pixel)视作为一个vector,这样图片就可以被视为vector set,就可以采用self-attention。

使用案例:
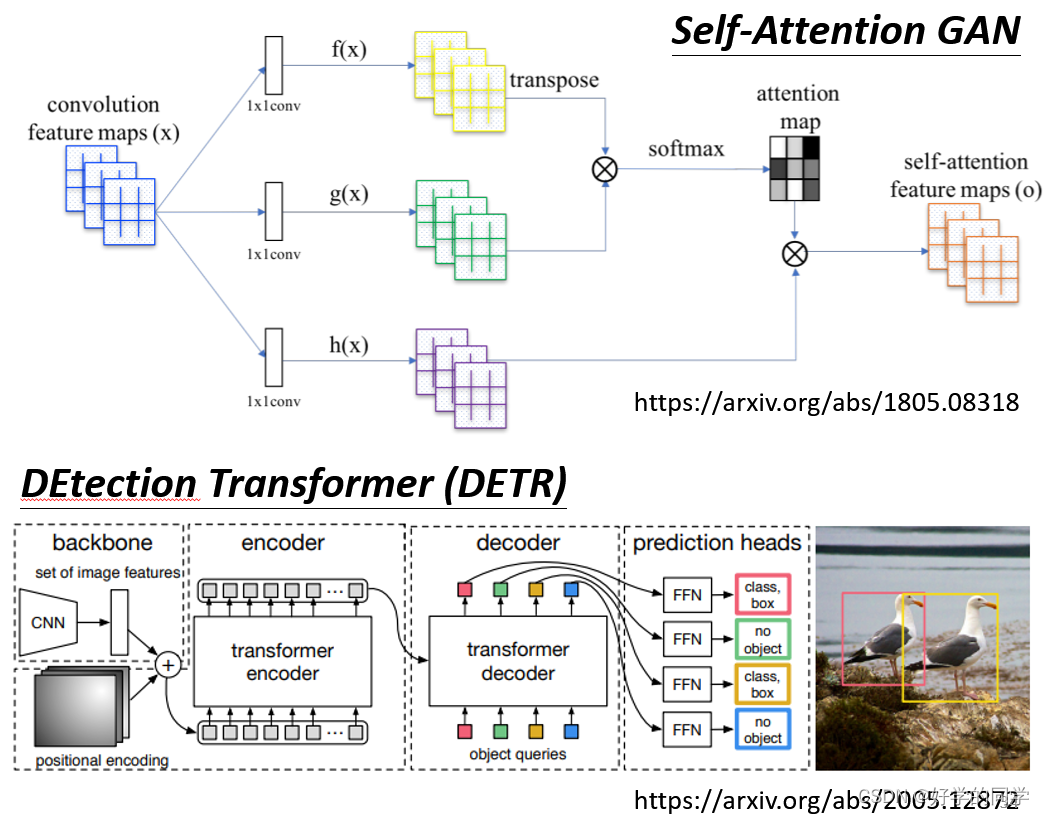
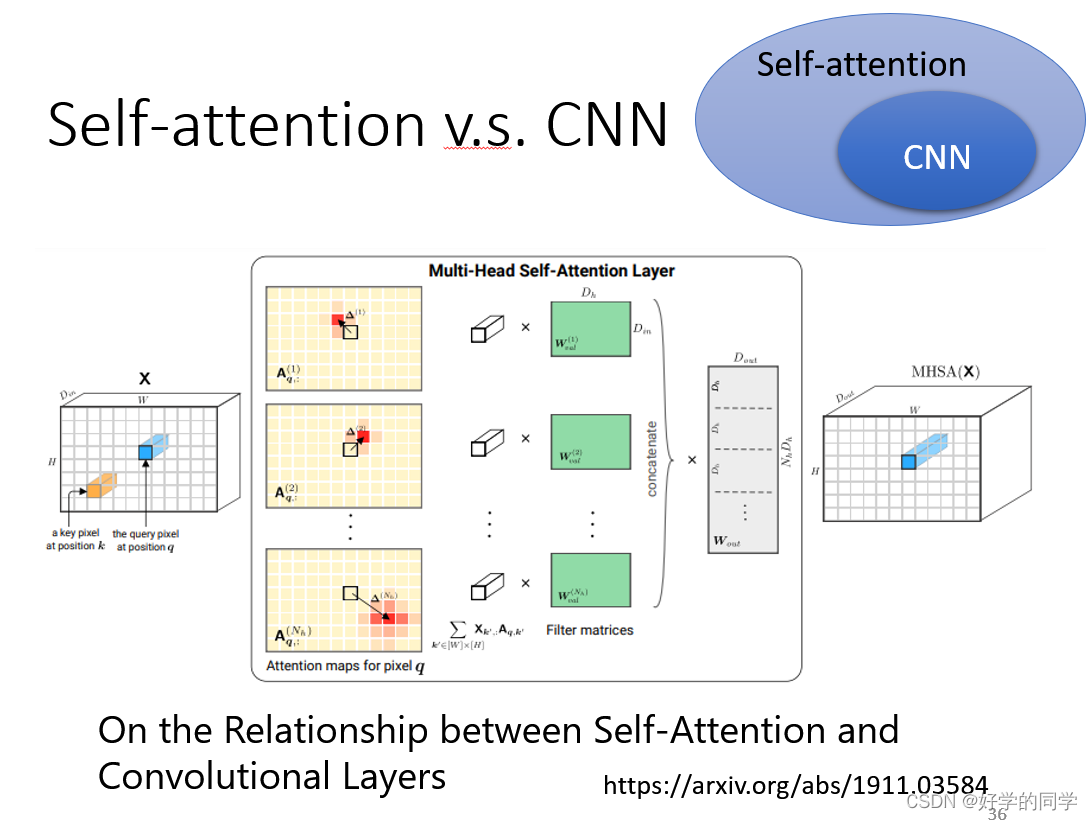
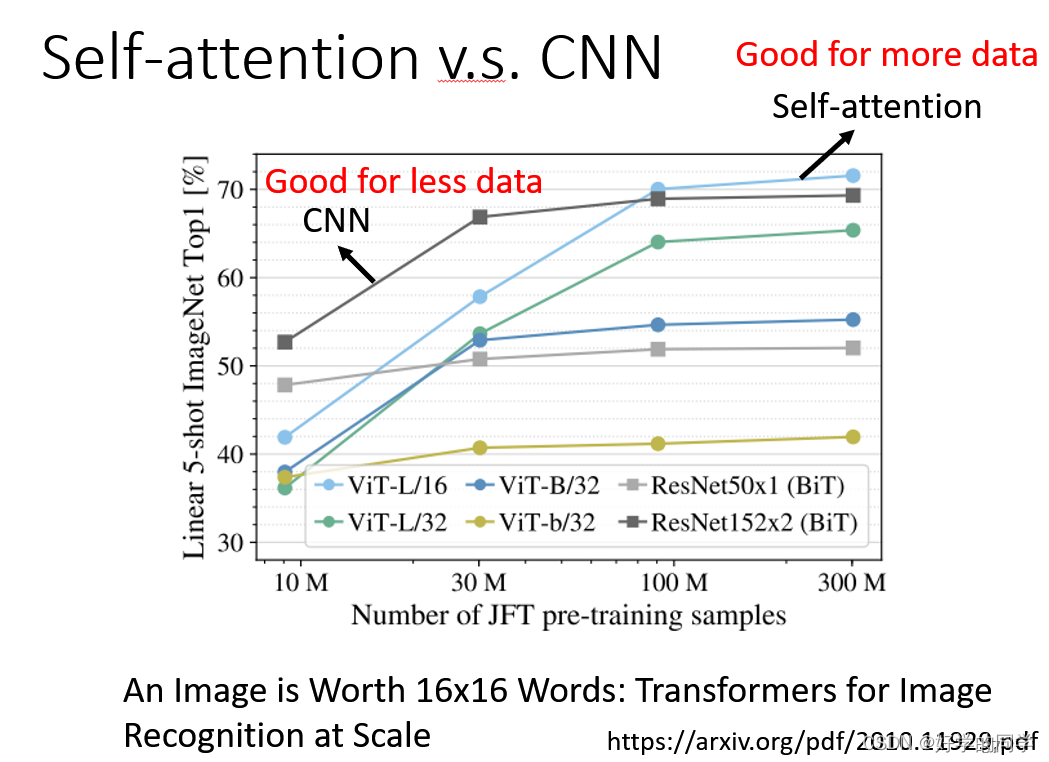
Self-Attention考虑所有的pixel,CNN只要在receptive Fields内的pixel,CNN可以被视作为一种简化版的Self-Attention。

使用Self-Attention可以让模型自己去得到相应的Receptive Fields,而不像CNN需要人为指定receptive fields的大小。
Self-Attention与RNN的对比
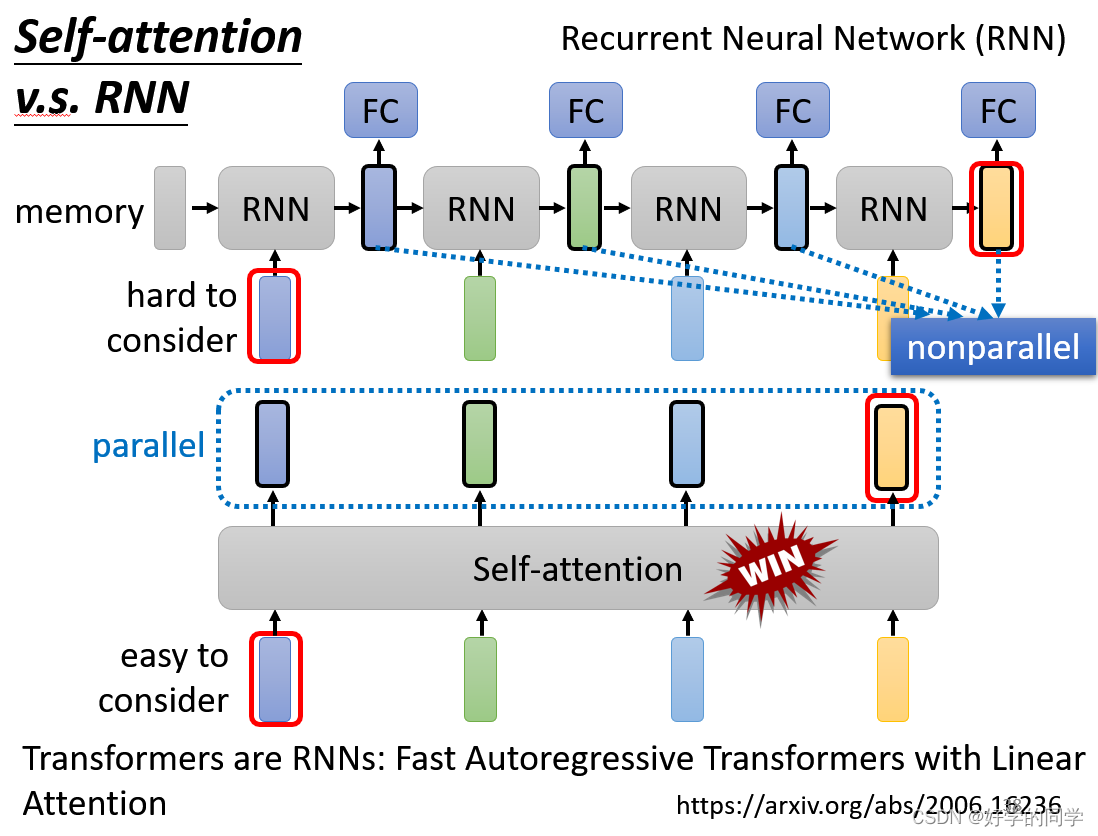
RNN不能并行计算,RNN只考虑过去的已经输入的vector的信息,双向的RNN就都可以考虑进去。
Self-Atterntion 使用中在Graph中
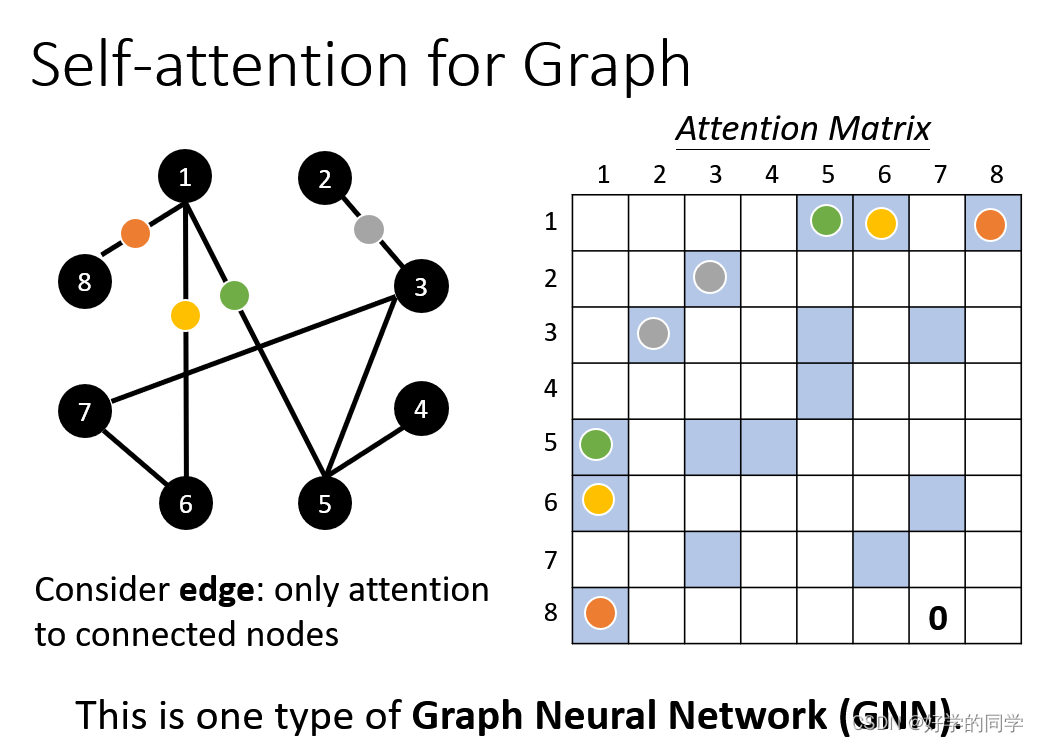
在计算不同节点的Attention时,只需要计算存在Edge存在的节点之间的attention。
扩展:self-attention的各种变形