Vision Transformer
将Transformer应用于CV领域。
不了解Transformer的先去看下:一文看懂Transformer
对比Transformer,ViT的特殊之处不多。因为作者说了他们想要做“尽量少的改动”将Transformer直接应用于图像领域
论文下载地址:https://arxiv.org/abs/2010.11929
github:https://github.com/google-research/vision_transformer
pytorch:https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/tree/master/pytorch_classification/vision_transformer
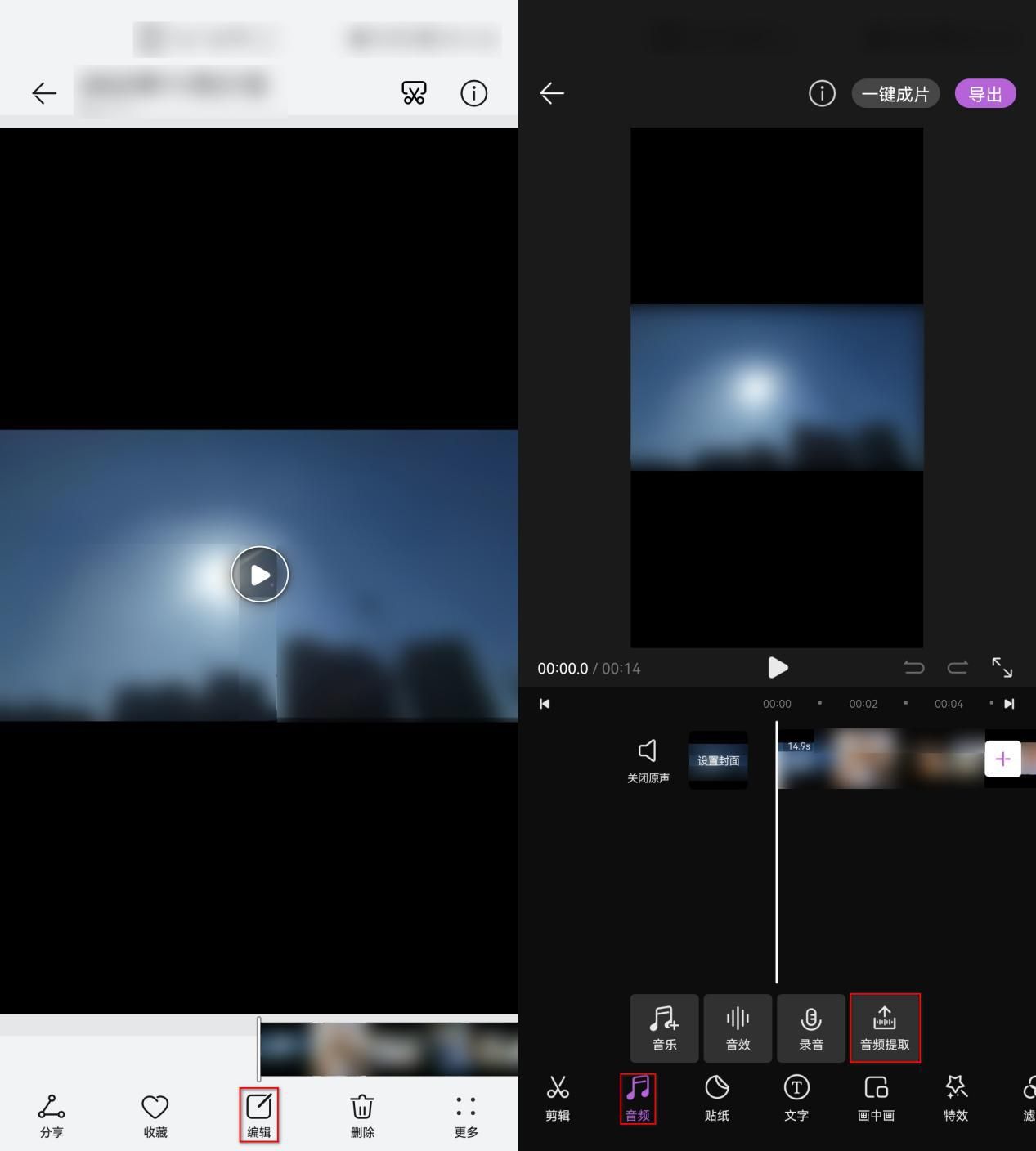
网络结构图
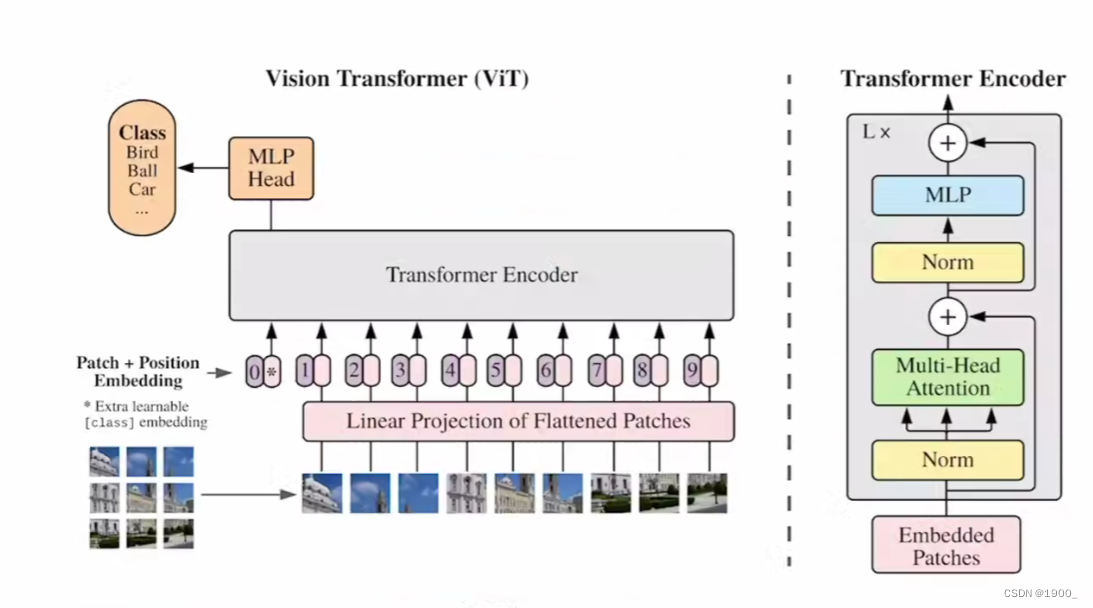
patch embedding
一步一步来看,首先呢处理文本的时候我们将每一个单词转化为一个向量。那么处理图像的时候我们采用的办法是将一张图像划分为16x16大小的块Patch(也可以是8x8,也可以是32x32)。
假如输入图片大小为224x224,将图片划分为固定大小的patch,patch大小假设为16x16,则每张图像会生成(224/16)^2=196个patch,
分块之后对每一块进行展平,16x16x3展平之后就是768。所以整个输入的大小就是196x768。
然后就像我们处理单词一样,我们用一个线性投射层,大小为768xN(N=768)
所以经过线性层之后,大小仍然为196x768,尺寸没变
这里还需要加上一个特殊字符cls。
传统的Transformer采取的是类似seq2seq编解码的结构,而ViT只用到了Encoder编码器结构,缺少了解码的过程,假设你16个向量经过编码器之后,你该选择哪一个向量拿去做最后的分类呢?因此这里作者给了额外的一个用于分类的向量,与输入进行拼接。同样这是一个可学习的变量。作者认为,由于自注意力的机制 ,这个向量也会从其他向量里面学到有用的信息。
因为是直接拼接,所以尺寸就变为197x768
positional encoding
图片虽然划分了,但是也是有顺序的,所以我们也需要加入位置信息。
这里可以学习的变量来表示位置信息,大小为197x768,与输入尺寸一样,直接与输入的做加法,最终得到还是197x768。
用这个来学习位置信息。
Transformer Encoder
至此,我们将一张图片,处理为了197个token,每个token长度为768。就将图像问题转化为了nlp问题了,转化成了序列。
直接输入Transformer Encoder就行。

MLP:将维度放大再缩小回去,197x768放大为197x3072,再缩小变为197x768
堆叠多个Block,最后将特殊字符cls对应的输出 Z 0 Z_0 Z0最为Encoder最终的输出
(另一种做法是不加cls字符,对所有的tokens的输出做一个平均)
分类头
最后把输出,送进分类头就好了
分类头就是一个LN,加两个线性层。