前言
在github上找案例推理相关实现代码,找到这个项目,记录一下运行过程。项目地址:https://github.com/jcf-junior/Diabetes-CBR
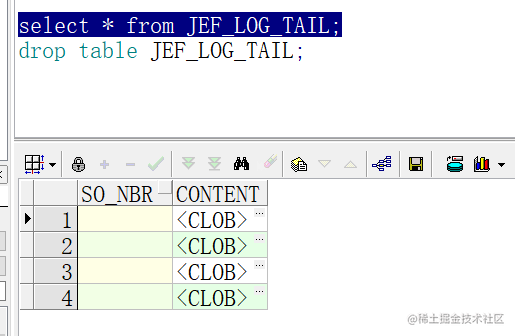
运行记录
运行项目的前提是已经装好的所有request的包,电脑里已经安装过mongodb数据库。
原项目直接运行会报错,需要修改一下,我直接放上已经修改好的代码。
(1)get_parameters.py
from db_connection import *
# 从配置文件获取k值
p1=config["parameters"]["p1"] # "k,3"
k=int(p1.split(",")[1])
(2)k_nn.py
from db_connection import *
from recommended_bolus import *
from find_neighbors import *
from get_parameters import *
# 设置输入参数
nearest_neighbors = find_nearest_neighbors(new_case["data"], k, selected_distance_metric)
(3)将 config 中 selected_algorithm 的值改成k_nn。
做完以上的修改就可以开始运行项目了。
1. 运行 db.py
连接 mongodb 数据库,在 mongodb 中创建新的数据库 cbr,在 cbr 中新建 config 和 inputs 两个表格,config 存储用户选择的案例检索算法和计算两个案例之间相似度的算法,inputs 存储用户输入的推荐所需参数。

2. 运行 generator.py
随机生成10个糖尿病案例,添加到 cases 表格中,作为案例库。
import random
from pymongo import MongoClient
# 连接到 MongoDB
client = MongoClient("mongodb://localhost:27017")
# 获取数据库
db = client['cbr']
# Get the cases collection
cases_collection = db['cases']
# 随机生成10个案例
cases = []
for i in range(10):
case = {}
case["Preprandial BG"] = random.randint(50, 250) # 餐前血糖
case["IOB"] = round(random.uniform(0, 1), 2)
case["BG Target"] = random.choice([100, 110])
case["CHO"] = random.randint(25, 80) # 碳水化合物含量
case["Patient weight"] = random.randint(50, 140) # 患者体重
case["ICR"] = random.randint(8, 23)
case["ISF"] = random.randint(25, 55)
case["Physical activity preprandial - Duration"] = random.randint(0, 100) # 餐前身体活动时长
case["Physical activity preprandial - Heart rate"] = random.randint(40, 110) # 餐前身体活动心率
case["Physical activity preprandial - Intensity"] = random.randint(0, 6) # 餐前身体活动时长
case["Physical activity postprandial - Duration"] = random.randint(0, 100) # 餐后身体活动强度
case["Physical activity postprandial - Intensity"] = random.randint(0, 6) # 餐后身体活动时长
case["Time of day"] = f"{random.randint(0,23)}:{random.randint(0,59)}" # 当前时间
case["Recommended Insulin Bolus"] = round(random.uniform(0, 12), 2) # 推荐胰岛素注射量
cases.append(case)
# 向 MongoDB 中添加案例
cases_collection.insert_many([{"type" : "cases", "data": case} for case in cases]) # 案例库中每条案例以字典的形式存储
3. 运行main.py
返回推荐的胰岛素注射量。运行结果如下:

【注】如果数据库中已经创建好 cases、inputs 等表格,那就直接运行 main.py 就行,不用每次都运行 db.py 好generator.py两个文件。
总结
(1)该项目的输入设计的不太好,是直接固定在db.py文件中的,不能由用户手动输入,是需要改进的;
(2)计算案例相似度部分,由于案例各属性都是数值型的,所以便于实现,但文本型数据的计算还要再找找别的代码;
(3)该项目整体对于我还是有用的,继续加油吧,这该死的项目进展会 😦