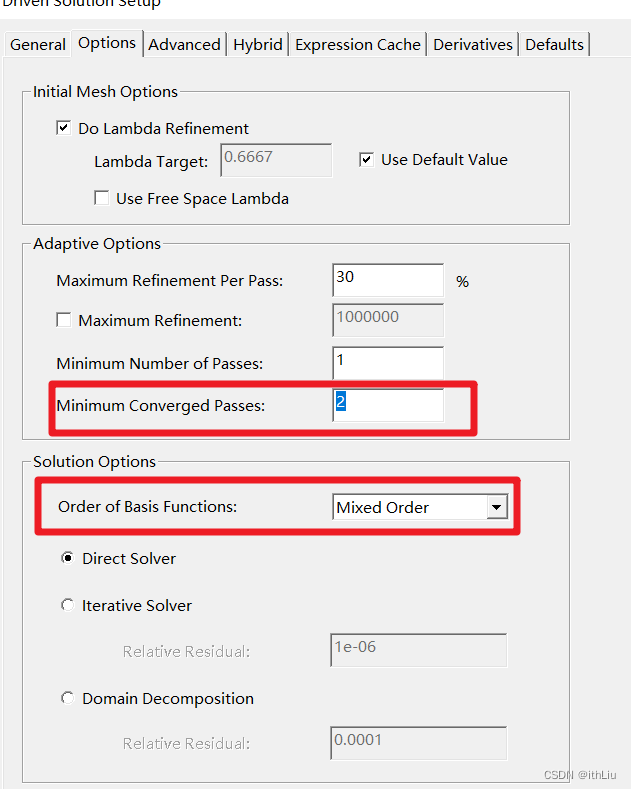
论文地址:https://arxiv.org/pdf/2303.17603.pdf
源码地址:https://nerfstereo.github.io/
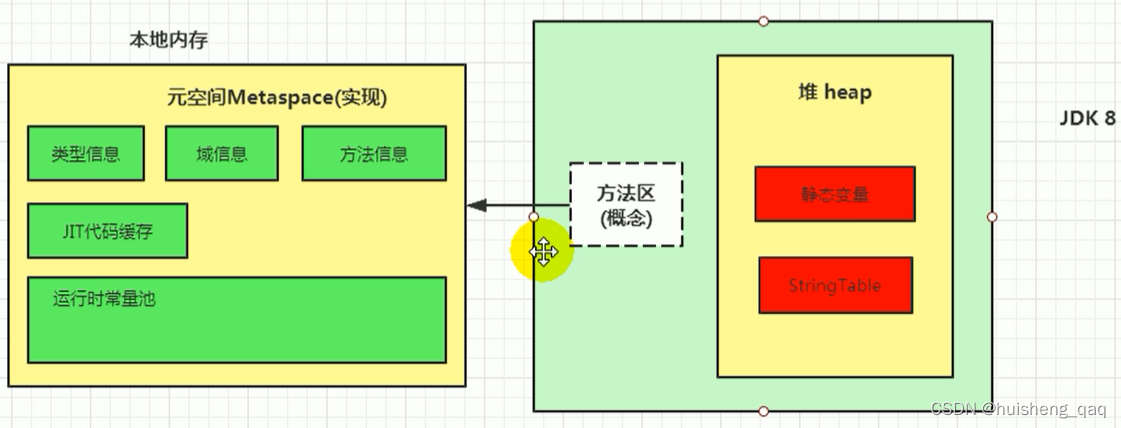
概述
针对深度估计的标签数据难以获取,自监督方法在病态(遮挡、非朗伯面)区域的表现差,跨域泛化能力弱的问题,本文提出了一种新的框架用于在无标签条件下训练双目立体深度估计模型,该方法通过NeRF来对单目拍摄的图像序列进行有监督训练得到目标场景的神经辐射场,使用体渲染得到的立体三元组来补偿遮挡区域的信息,并将深度图作为代理标签(proxy label)对双目深度估计模型进行训练。实验结果表明,这种方式填补了无监督模型与有监督模型之间的Gap,比现有的自监督方法在Middleburry数据集上有30% 到 40% 的性能提升,并在 Zero-shot 泛化方面有较好的表现。

本文的主要贡献如下:
- 提出一种新的范式,用神经渲染与无标签的图像序列来生成立体匹配模型训练数据。
- 提出一种NeRF-Supervised训练框架,结合渲染得到的三元组和深度图来解决立体匹配中的遮挡问题,并增强了细节信息。
- 在MiddleBurry数据集上取得了SOTA的 Zero-shot 泛化性能。
模型架构

模型的整体框架如图2所示,首先在多个场景中使用多视图来训练神经辐射场,然后使用提渲染技术来获取立体图像与对应的标签深度图,最后用渲染的数据来训练立体匹配网络。
图像收集与位姿估计
使用收集拍摄一系列照片,使用COLMAP估计图像的位姿信息用于NeRF的训练。
NeRF训练
通过批量采样光线信息,基于
L
2
L_2
L2 损失对每个场景的训练一个独立的神经辐射场:
L
r
e
n
d
=
∑
r
∈
R
∣
∣
C
^
(
r
)
−
C
(
r
)
∣
∣
2
2
(1)
\mathcal{L}_{rend}=\sum_{r\in R}||\hat{C}(r)-C(r)||^2_2\tag{1}
Lrend=r∈R∑∣∣C^(r)−C(r)∣∣22(1)
立体图像对数据渲染生成
- 定义虚拟的相机外参 S = I ∣ b S=\mathbb{I}|\mathbf{b} S=I∣b: I \mathbb{I} I 为 3 × 3 3\times 3 3×3 的单位矩阵, b = ( b , 0 , 0 ) T \mathbf{b} = (b, 0, 0)^T b=(b,0,0)T表示只在 x x x 轴移动的平移向量。
- 基于任意视角的内参 E k = R k ∣ t k \mathbf{E}_k = \mathbf{R}_k|\mathbf{t}_k Ek=Rk∣tk 来生成中间视角的图像 I c I_c Ic
- 基于内参 E k L = E k × S − 1 = R k ∣ ( t k − b ) \mathbf{E}_{k}^{\mathrm{L}}=\mathbf{E}_{k} \times \mathbf{S}^{-1}=\mathbf{R}_{k} \mid\left(\mathbf{t}_{k}-\mathbf{b}\right) EkL=Ek×S−1=Rk∣(tk−b) 来生成左视角图像 I l I_l Il
- 基于内参 E k R = E k × S = R k ∣ ( t k + b ) \mathbf{E}_{k}^{\mathrm{R}}=\mathbf{E}_{k} \times \mathbf{S}=\mathbf{R}_{k} \mid\left(\mathbf{t}_{k}+\mathbf{b}\right) EkR=Ek×S=Rk∣(tk+b) 来生成右视角图像 I r I_r Ir
- 根据渲染生成的深度
z
r
z_r
zr 与虚拟内参获取视差
d
r
d_r
dr:
z ( r ) = ∑ i = 1 N T i ( 1 − exp ( − σ i δ i ) ) σ i , d ( r ) = b ⋅ f z ( r ) , (2) z(\mathbf{r})=\sum_{i=1}^{N} T_{i}\left(1-\exp \left(-\sigma_{i} \delta_{i}\right)\right) \sigma_{i}, \quad d(\mathbf{r})=\frac{b \cdot f}{z(\mathbf{r})},\tag{2} z(r)=i=1∑NTi(1−exp(−σiδi))σi,d(r)=z(r)b⋅f,(2)
其中 f f f 为 COLMAP 估计的焦距。
损失函数
给定三元图像组
I
l
,
I
c
,
I
r
I_l,I_c, I_r
Il,Ic,Ir,将
I
c
,
I
r
I_c, I_r
Ic,Ir 作为立体匹配网络的输入,使用NS损失来训练模型,NS损失包含以下两方面:
三元光度一致性损失
L ρ ( I c , I ^ c r ) = β ⋅ 1 − SSIM ( I c , I ^ c r ) 2 + ( 1 − β ) ⋅ ∣ I c − I ^ c r ∣ (3) \mathcal{L}_{\rho}\left(I_{c}, \hat{I}_{c}^{r}\right)=\beta \cdot \frac{1-\operatorname{SSIM}\left(I_{c}, \hat{I}_{c}^{r}\right)}{2}+(1-\beta) \cdot\left|I_{c}-\hat{I}_{c}^{r}\right|\tag{3} Lρ(Ic,I^cr)=β⋅21−SSIM(Ic,I^cr)+(1−β)⋅ Ic−I^cr (3)
其中
I
^
c
r
\hat{I}_{c}^{r}
I^cr 为右视图基于预测的视差图warp回中间视图的图像。
SSIM
(
⋅
)
\operatorname{SSIM}(\cdot)
SSIM(⋅) 为结构一致性损失。结构一致性损失在遮挡区域无法起到很好的监督作用,如
I
c
I_c
Ic 左边界的像素点,为此使用左视图
I
l
I_l
Il沿着预测视差图投影到中间视图
I
^
c
l
\hat{I}_{c}^{l}
I^cl,用于计算光度一致性损失
L
ρ
(
I
^
l
c
,
I
c
)
\mathcal{L}_{\rho}\left(\hat{I}_{l}^{c}, I_{c}\right)
Lρ(I^lc,Ic),用于补偿遮挡区域的预测误差。最后的三元光度损失函数为:
L
3
ρ
(
I
^
l
c
,
I
c
,
I
^
r
c
)
=
min
(
L
ρ
(
I
^
l
c
,
I
c
)
,
L
ρ
(
I
c
,
I
^
r
c
)
)
(4)
\mathcal{L}_{3 \rho}\left(\hat{I}_{l}^{c}, I_{c}, \hat{I}_{r}^{c}\right)=\min \left(\mathcal{L}_{\rho}\left(\hat{I}_{l}^{c}, I_{c}\right), \mathcal{L}_{\rho}\left(I_{c}, \hat{I}_{r}^{c}\right)\right)\tag{4}
L3ρ(I^lc,Ic,I^rc)=min(Lρ(I^lc,Ic),Lρ(Ic,I^rc))(4)

上图展示了遮挡区域(明亮部分)对计算三元光度一致性损失的影响,计算三元光度一致性损失时忽略遮挡,最后无纹理区域被掩膜
μ
\mu
μ 消除:
μ = [ min L 3 ρ ( I ^ l c , I c , I ^ r c ) < min L 3 ρ ( I l , I c , I r ) ] (5) \mu=\left[\min \mathcal{L}_{3 \rho}\left(\hat{I}_{l}^{c}, I_{c}, \hat{I}_{r}^{c}\right)<\min \mathcal{L}_{3 \rho}\left(I_{l}, I_{c}, I_{r}\right)\right]\tag{5} μ=[minL3ρ(I^lc,Ic,I^rc)<minL3ρ(Il,Ic,Ir)](5)
渲染视差损失
计算匹配网络预测的视差图与NeRF渲染的视差图之间的
L
1
L_1
L1 损失
L
disp
=
∣
d
c
−
d
^
c
∣
(6)
\mathcal{L}_{\text {disp }}=\left|d_{c}-\hat{d}_{c}\right|\tag{6}
Ldisp =
dc−d^c
(6)
为了消除NeRF渲染视差图的伪影,使用 Ambient Occlusion(AO) 来计算渲染视差图的置信度:
A
O
=
∑
i
=
1
N
T
i
α
i
,
α
i
=
1
−
exp
(
−
σ
i
δ
i
)
(7)
\mathrm{AO}=\sum_{i=1}^{N} T_{i} \alpha_{i}, \quad \alpha_{i}=1-\exp \left(-\sigma_{i} \delta_{i}\right)\tag{7}
AO=i=1∑NTiαi,αi=1−exp(−σiδi)(7)
使用两部分的加权损失作为最后的损失:
L
N
S
=
γ
d
i
s
p
⋅
η
disp
⋅
L
disp
+
μ
⋅
γ
3
ρ
⋅
(
1
−
η
disp
)
⋅
L
3
ρ
(8)
\begin{aligned} \mathcal{L}_{N S} & =\gamma_{d i s p} \cdot \eta_{\text {disp }} \cdot \mathcal{L}_{\text {disp }} +\mu \cdot \gamma_{3 \rho} \cdot\left(1-\eta_{\text {disp }}\right) \cdot \mathcal{L}_{3 \rho} \end{aligned}\tag{8}
LNS=γdisp⋅ηdisp ⋅Ldisp +μ⋅γ3ρ⋅(1−ηdisp )⋅L3ρ(8)
η disp = { 0 if A O < t h A O otherwise (9) \eta_{\text {disp }}=\left\{\begin{array}{ll} 0 & \text { if } \mathrm{AO}<t h \\ \mathrm{AO} & \text { otherwise } \end{array}\right. \tag{9} ηdisp ={0AO if AO<th otherwise (9)
实验结果