- 版本: Hoxton SR6
1.什么是微服务
官网
In short, the microservice architectural(架构) style is an approach to developing a single application as a suite(系列) of small services, each running in its own process(进程) and communicating with lightweight mechanisms, often an HTTP resource API. These services are built around business(业务) capabilities(单元) and independently(独立) deployable(部署) by fully automated deployment machinery. There is a bare(基于) minimum of centralized(分布式) management(管理) of these services, which may be written in different programming languages and use different data storage technologies. -----[摘自官网]
- a suite of small services --一系列微小服务
- running in its own process --运行在自己的进程里
- built around business capabilities --围绕自己的业务开发
- independently deployable --独立部署
- bare minimum of centralized management of these services --基于分布式管理
官方定义:微服务就是由一系列围绕自己业务开发的微小服务构成,他们独立部署运行在自己的进程里,基于分布式的管理
通俗定义:微服务是一种架构,这种架构是将单个的整体应用程序分割成更小的项目关联的独立的服务。一个服务通常实现一组独立的特性或功能,包含自己的业务逻辑和适配器。各个微服务之间的关联通过暴露api来实现。这些独立的微服务不需要部署在同一个虚拟机,同一个系统和同一个应用服务器中。
2.为什么是微服务?
单体应用
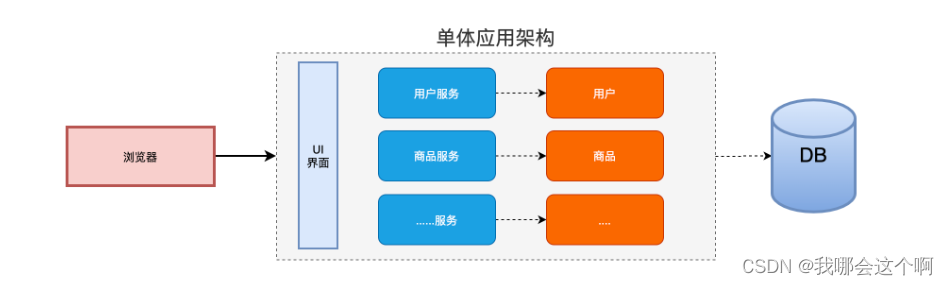
单体项目的优点:单一架构模式在项目初期很小的时候开发方便,测试方便,部署方便,运行良好。
缺点:
- 应用随着时间的推进,加入的功能越来越多,最终会变得巨大,一个项目中很有可能数百万行的代码,互相之间繁琐的jar包。
- 久而久之,开发效率低,代码维护困难
- 还有一个如果想整体应用采用新的技术,新的框架或者语言,那是不可能的。
- 任意模块的漏洞或者错误都会影响这个应用,降低系统的可靠性
微服务架构应用
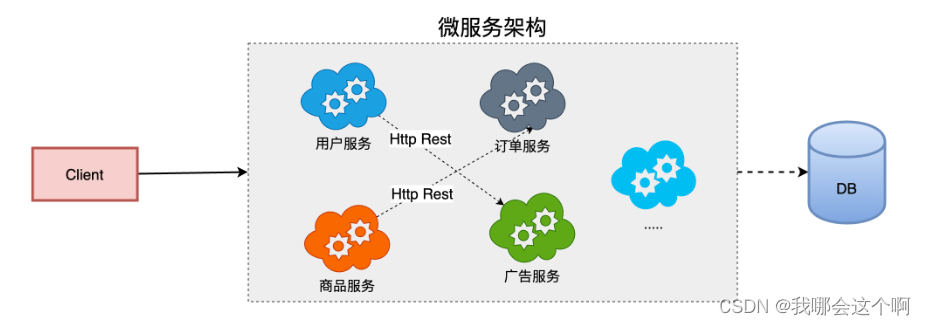
1.优点
- 将服务拆分成多个单一职责的小的服务,进行单独部署,服务之间通过网络进行通信
- 每个服务应该有自己单独的管理团队,高度自治
- 服务各自有自己单独的职责,服务之间松耦合,避免因一个模块的问题导致服务崩溃
2.缺点
- 开发人员要处理分布式系统的复杂性
- 多服务运维难度,随着服务的增加,运维的压力也在增大
- 服务治理 和 服务监控 关键
架构的演变
1.架构的演变过程
- [单一应用架构]
===>[垂直应用架构]===>[分布式服务架构]===>[流动计算架构]||[微服务架构]===>[未知]
dubbo官网:点击跳转
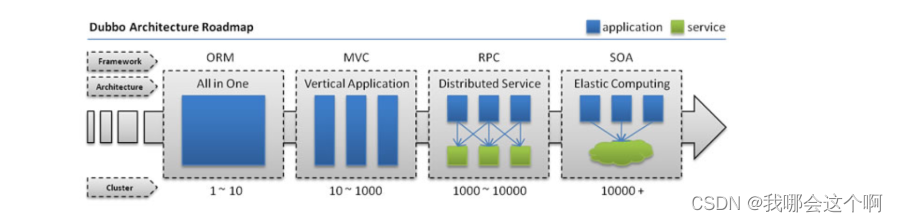
1. All in One Application 单一架构
- 起初当网站流量很小时,将所有功能都写在一个应用里面,对整个应用进行部署,以减少部署节点和成本。对于这个架构简化增删改查的工作量的数据访问框架(ORM)是关键。
2. Vertical Application 垂直架构
- 当访问量逐渐增大,单一应用增加机器带来的加速度越来越小,提升效率的方法之一是将应用拆成互不相干的几个应用,以提升效率。此时,用于加速前端页面开发的Web框架(MVC)是关键。
3. Distributed Service 分布式服务架构
- 当垂直应用越来越多,应用之间交互不可避免,将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,使前端应用能更快速的响应多变的市场需求。此时,用于提高业务复用及整合的分布式服务框架(RPC)是关键。
4. Elastic Computing 流动计算架构即微服务架构
- 当服务越来越多,容量的评估,小服务资源的浪费等问题逐渐显现,此时需增加一个调度中心基于访问压力实时管理集群容量,提高集群利用率。此时,用于提高机器利用率的资源调度和治理中心(SOA)是关键
好的架构并不是设计出来的,一定是进化来的!!!
3.微服务的解决方案
1.Dubbo (阿里系)
-
初出茅庐:2011年末,阿里巴巴在GitHub上开源了基于Java的分布式服务治理框架Dubbo,之后它成为了国内该类开源项目的佼佼者,许多开发者对其表示青睐。同时,先后有不少公司在实践中基于Dubbo进行分布式系统架构,目前在GitHub上,它的fork、star数均已破万。Dubbo致力于提供高性能和透明化的RPC远程服务调用方案,以及SOA服务治理方案,使得应用可通过高性能RPC实现服务的输出、输入功能和Spring框架无缝集成。Dubbo包含远程通讯、集群容错和自动发现三个核心部分。
-
停止维护:从2012年10月23日Dubbo 2.5.3发布后,在Dubbo开源将满一周年之际,阿里基本停止了对Dubbo的主要升级。只在之后的2013年和2014年更新过2次对Dubbo 2.4的维护版本,然后停止了所有维护工作。Dubbo对Srping的支持也停留在了Spring 2.5.6版本上。
-
死而复生:多年漫长的等待,随着微服务的火热兴起,在国内外开发者对阿里不再升级维护Dubbo的吐槽声中,阿里终于开始重新对Dubbo的升级和维护工作。在2017年9月7日,阿里发布了Dubbo的2.5.4版本,距离上一个版本2.5.3发布已经接近快5年时间了。在随后的几个月中,阿里Dubbo开发团队以差不多每月一版本的速度开始快速升级迭代,修补了Dubbo老版本多年来存在的诸多bug,并对Spring等组件的支持进行了全面升级。
-
2018年1月8日,Dubbo创始人之一梁飞在Dubbo交流群里透露了Dubbo 3.0正在动工的消息。Dubbo 3.0内核与Dubbo 2.0完全不同,但兼容Dubbo 2.0。Dubbo 3.0将以Streaming为内核,不再是Dubbo 时代的RPC,但是RPC会在Dubbo 3.0中变成远程Streaming对接的一种可选形态。从Dubbo新版本的路线规划上可以看出,新版本的Dubbo在原有服务治理的功能基础上,将全面拥抱微服务解决方案。
-
结论:当前由于RPC协议、注册中心元数据不匹配等问题,在面临微服务基础框架选型时Dubbo与Spring Cloud是只能二选一,这也是为什么大家总是拿Dubbo和Spring Cloud做对比的原因之一。Dubbo之后会积极寻求适配到Spring Cloud生态,比如作为Spring Cloud的二进制通信方案来发挥Dubbo的性能优势,或者Dubbo通过模块化以及对http的支持适配到Spring Cloud。

Spring Cloud:
-
Spring Cloud NetFlix
基于美国Netflix公司开源的组件进行封装,提供了微服务一栈式的解决方案。 -
Spring Cloud alibaba
在Spring cloud netflix基础上封装了阿里巴巴的微服务解决方案。 -
Spring Cloud Spring
目前spring官方趋势正在逐渐吸收Netflix组件的精华,并在此基础进行二次封装优化,打造spring专有的解决方案
4.什么是SpringCloud
官方定义
- 官方网址: https://cloud.spring.io/spring-cloud-static/Hoxton.SR5/reference/html/
Spring Cloud provides tools for developers to quickly build some of the common patterns in distributed systems (e.g. configuration management, service discovery, circuit breakers, intelligent routing, micro-proxy, control bus). Coordination of distributed systems leads to boiler plate patterns, and using Spring Cloud developers can quickly stand up services and applications that implement those patterns. -------[摘自官网]
1.翻译
- springcloud为开发人员提供了在分布式系统中快速构建一些通用模式的工具(例如配置管理、服务发现、断路器、智能路由、微代理、控制总线)。分布式系统的协调导致了锅炉板模式,使用springcloud开发人员可以快速地建立实现这些模式的服务和应用程序。
2.通俗理解
- springcloud是一个含概多个子项目的开发工具集,集合了众多的开源框架,他利用了Spring Boot开发的便利性实现了很多功能,如服务注册,服务注册发现,负载均衡等.SpringCloud在整合过程中主要是针对Netflix(耐非)开源组件的封装.SpringCloud的出现真正的简化了分布式架构的开发。NetFlix 是美国的一个在线视频网站,微服务业的翘楚,他是公认的大规模生产级微服务的杰出实践者,NetFlix的开源组件已经在他大规模分布式微服务环境中经过多年的生产实战验证,因此Spring Cloud中很多组件都是基于NetFlix
spring netflix 维护 闭源
核心架构及其组件
1.核心组件说明
eurekaserver、consul、nacos 服务注册中心组件rabbion & openfeign 服务负载均衡 和 服务调用组件hystrix & hystrix dashboard 服务断路器 和 服务监控组件zuul、gateway 服务网关组件config 统一配置中心组件bus 消息总线组件
5.环境搭建
版本命名
- 官网地址:https://spring.io/projects/spring-cloud
Spring Cloud is an umbrella(伞) project consisting of independent projects with, in principle, different release cadences. To manage the portfolio a BOM (Bill of Materials) is published with a curated set of dependencies on the individual project (see below). The release trains have names, not versions, to avoid confusion with the sub-projects. The names are an alphabetic sequence (so you can sort them chronologically) with names of London Tube stations (“Angel” is the first release, “Brixton” is the second). When point releases of the individual projects accumulate to a critical mass, or if there is a critical bug in one of them that needs to be available to everyone, the release train will push out “service releases” with names ending “.SRX”, where “X” is a number. —[摘自官网]
1.翻译
- springcloud是一个由众多独立子项目组成的大型综合项目,原则每个子项目上有不同的发布节奏,都维护自己发布版本号。为了更好的管理springcloud的版本,通过一个资源清单BOM(Bill of Materials),为避免与子项目的发布号混淆,所以没有采用版本号的方式,而是通过命名的方式。这些名字是按字母顺序排列的。如伦敦地铁站的名称(“天使”是第一个版本,“布里斯顿”是第二个版本,"卡姆登"是第三个版本)。当单个项目的点发布累积到一个临界量,或者其中一个项目中有一个关键缺陷需要每个人都可以使用时,发布序列将推出名称以“.SRX”结尾的“服务发布”,其中“X”是一个数字。
2.伦敦地铁站名称 [了解]
- Angel、Brixton、Camden、Dalston、Edgware、Finchley、Greenwich、Hoxton
版本选择
1.版本选择官方建议 https://spring.io/projects/spring-cloud
- Angel 版本基于springboot1.2.x版本构建与1.3版本不兼容
- Brixton 版本基于springboot1.3.x版本构建与1.2版本不兼容
`2017年Brixton and Angel release官方宣布报废 - Camden 版本基于springboot1.4.x版本构建并在1.5版本通过测试
`2018年Camden release官方宣布报废 - Dalston、Edgware 版本基于springboot1.5.x版本构建目前不能再springboot2.0.x版本中使用
`Dalston(达尔斯顿)将于2018年12月官方宣布报废。Edgware将遵循Spring Boot 1.5.x的生命周期结束。 - Finchley 版本基于springboot2.0.x版本进行构建,不能兼容1.x版本
- Greenwich 版本基于springboot2.1.x版本进行构建,不能兼容1.x版本
- Hoxton 版本基于springboot2.2.x版本进行构建
Spring Cloud Dalston, Edgware, Finchley, and Greenwich have all reached end of life status and are no longer supported.

环境搭建
0.说明
- springboot 2.2.5.RELEASE
- springcloud Hoxton.SR6
- java8
- maven 3.3.9
- idea 2018.3.5
1.创建springboot项目 指定版本为 2.2.5版本
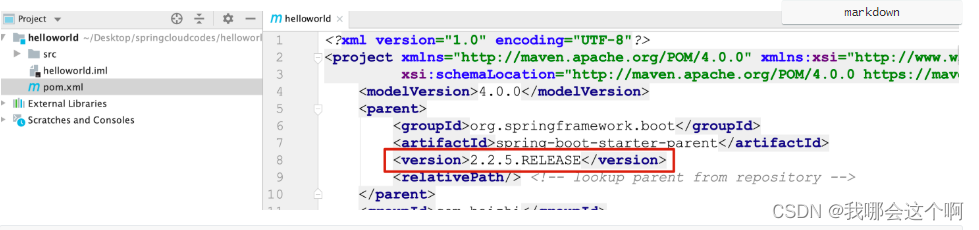
2.引入springcloud的版本管理
<!--继承springboot的父项目-->
<parent>
<groupId>org.springframework.boot</groupId>
<version>2.2.5.RELEASE</version>
<artifactId>spring-boot-starter-parent</artifactId>
</parent>
<!--定义springcloud使用版本号-->
<properties>
<java.version>1.8</java.version>
<spring-cloud.version>Hoxton.SR6</spring-cloud.version>
</properties>
<!--全局管理springcloud版本,并不会引入具体依赖-->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
完成上述操作springboot与springcloud环境搭建完成接下来就是使用到具体的springcloud组件,在项目中引入具体的组件即可
6.服务注册中心
什么服务注册中心
所谓服务注册中心就是在整个的微服务架构中单独提出一个服务,这个服务不完成系统的任何的业务功能,仅仅用来完成对整个微服务系统的服务注册和服务发现,以及对服务健康状态的监控和管理功能。
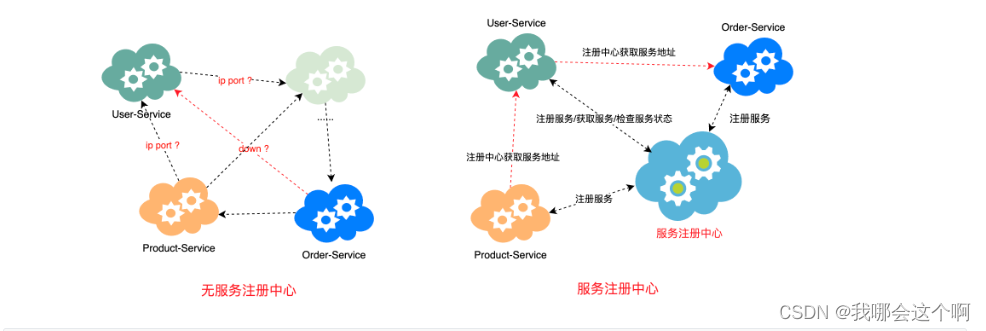
1.服务注册中心
- 可以对所有的微服务的信息进行存储,如微服务的名称、IP、端口等
- 可以在进行服务调用时通过服务发现查询可用的微服务列表及网络地址进行服务调用
- 可以对所有的微服务进行心跳检测,如发现某实例长时间无法访问,就会从服务注册表移除该实例。
常用的注册中心
springcloud支持的多种注册中心Eureka、Consul、Zookeeper、以及阿里巴巴推出Nacos。这些注册中心在本质上都是用来管理服务的注册和发现以及服务状态的检查的。
1.Eureka
0.简介
- https://github.com/Netflix/eureka/wiki
- Eureka是Netflix开发的服务发现框架,本身是一个基于REST的服务。SpringCloud将它集成在其子项目spring-cloud-netflix中, 以实现SpringCloud的服务注册和发现功能。
Eureka包含两个组件:Eureka Server和Eureka Client。
开发Eureka Server
1.创建项目并引入eureka server依赖及springboot web依赖
<!--引入 eureka server-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
2.编写配置application.properties
server.port=8761 #执行服务端口
spring.application.name=eurekaserver #指定服务名称 唯一标识
eureka.client.service-url.defaultZone=http://localhost:8761/eureka #指定服务注册中心的地址
3.开启Eureka Server,入口类加入注解
@SpringBootApplication
@EnableEurekaServer
public class Eurekaserver8761Application {
public static void main(String[] args) {
SpringApplication.run(Eurekaserver8761Application.class, args);
}
}
4.访问Eureka的服务注册页面
- http://localhost:8761/eureka

5.虽然能看到管理界面为什么项目启动控制台报错?

出现上述问题原因:eureka组件包含 eurekaserver 和 eurekaclient。server是一个服务注册中心,用来接受客户端的注册。client的特性会让当前启动的服务把自己作为eureka的客户端进行服务中心的注册,当项目启动时服务注册中心还没有创建好,所以找我不到服务的客户端组件就直接报错了,当启动成功服务注册中心创建好了,日后client也能进行注册,就不再报错啦!
6.关闭Eureka自己注册自己
server.port=8761
spring.application.name=eurekaserver
eureka.client.service-url.defaultZone=http://localhost:8761/eureka
eureka.client.register-with-eureka=false #不再将自己同时作为客户端进行注册
eureka.client.fetch-registry=false #关闭作为客户端时从eureka server获取服务信息
7.再次启动,当前应用就是一个单纯Eureka Server,控制器也不再报错
开发Eureka Client
<!--引入eureka client-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
2.编写配置application.properties
server.port=8888 #服务端口号
spring.application.name=eurekaclient8888 #服务名称唯一标识
eureka.client.service-url.defaultZone=http://localhost:8761/eureka #eureka注册中心地址
3.开启eureka客户端加入注解
@SpringBootApplication
@EnableEurekaClient
public class Eurekaclient8888Application {
public static void main(String[] args) {
SpringApplication.run(Eurekaclient8888Application.class, args);
}
}
4.启动之前的8761的服务注册中心,在启动eureka客户端服务
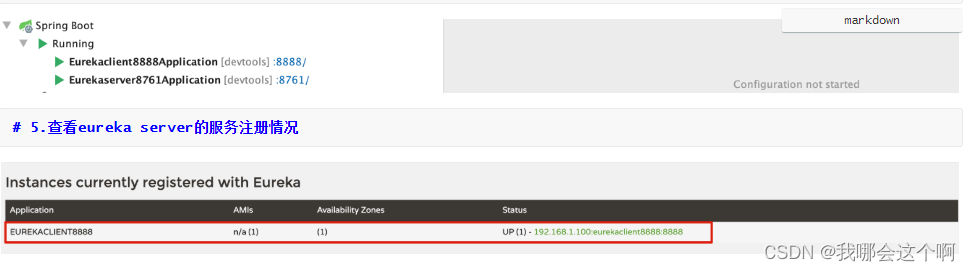
eureka自我保护机制
- EMERGENCY! EUREKA MAY BE INCORRECTLY CLAIMING INSTANCES ARE UP WHEN THEY’RE NOT. RENEWALS ARE LESSER THAN THRESHOLD AND HENCE THE INSTANCES ARE NOT BEING EXPIRED JUST TO BE SAFE.
1.自我保护机制
- 官网地址: https://github.com/Netflix/eureka/wiki/Server-Self-Preservation-Mode
- 默认情况下,如果Eureka Server在一定时间内(默认90秒)没有接收到某个微服务实例的心跳,Eureka Server将会移除该实例。但是当网络分区故障发生时,微服务与Eureka Server之间无法正常通信,而微服务本身是正常运行的,此时不应该移除这个微服务,所以引入了自我保护机制。Eureka Server在运行期间会去统计心跳失败比例在 15 分钟之内是否低于 85%,如果低于 85%,Eureka Server 会将这些实例保护起来,让这些实例不会过期。这种设计的哲学原理就是"宁可信其有不可信其无!"。自我保护模式正是一种针对网络异常波动的安全保护措施,使用自我保护模式能使Eureka集群更加的健壮、稳定的运行。
2.在eureka server端关闭自我保护机制
eureka.server.enable-self-preservation=false #关闭自我保护
eureka.server.eviction-interval-timer-in-ms=3000 #超时3s自动清除

3.微服务修改减短服务心跳的时间
eureka.instance.lease-expiration-duration-in-seconds=10 #用来修改eureka server默认接受心跳的最大时间 默认是90s
eureka.instance.lease-renewal-interval-in-seconds=5 #指定客户端多久向eureka server发送一次心跳 默认是30s
4.尽管如此关闭自我保护机制还是会出现警告
- THE SELF PRESERVATION MODE IS TURNED OFF. THIS MAY NOT PROTECT INSTANCE EXPIRY IN CASE OF NETWORK/OTHER PROBLEMS.
- `官方并不建议在生产情况下关闭

eureka 停止更新
1.官方停止更新说明
- https://github.com/Netflix/eureka/wiki
- 在1.x版本项目还是活跃的,但是在2.x版本中停止维护,出现问题后果自负!!!

2.Consul
- https://www.consul.io
- consul是一个可以提供服务发现,健康检查,多数据中心,Key/Value存储等功能的分布式服务框架,用于实现分布式系统的服务发现与配置。与其他分布式服务注册与发现的方案,使用起来也较为简单。Consul用Golang实现,因此具有天然可移植性(支持Linux、Windows和Mac OS X);安装包仅包含一个可执行文件,方便部署。
安装consul
1.下载consul
- https://www.consul.io/downloads

2.安装consul
- 官方安装视频地址: https://learn.hashicorp.com/consul/getting-started/install.html
- 1.解压之后发现consul只有一个脚本文件
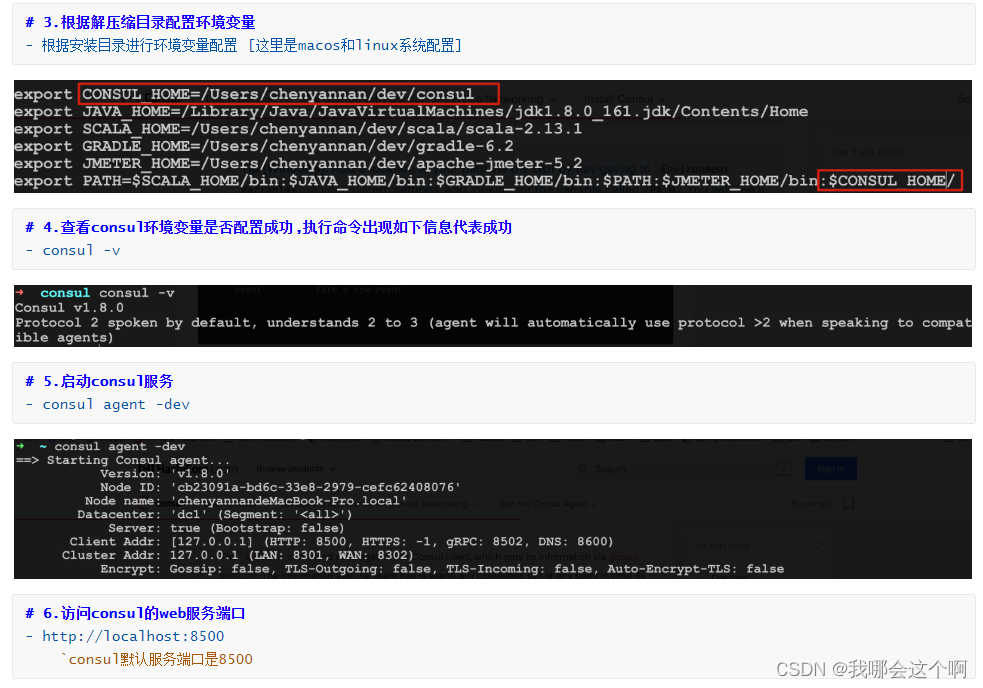

开发consul 客户端即微服务
1.创建项目并引入consul客户端依赖
<!--引入consul依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-consul-discovery</artifactId>
</dependency>
2.编写properties配置
server.port=8889
spring.application.name=consulclient8889
spring.cloud.consul.host=localhost #注册consul服务的主机
spring.cloud.consul.port=8500 #注册consul服务的端口号
spring.cloud.consul.discovery.register-health-check=false #关闭consu了服务的健康检查[不推荐]
spring.cloud.consul.discovery.service-name=${spring.application.name} #指定注册的服务名称 默认就是应用名
在主启动类上面加上@EnableDiscoveryClient ,代表该服务可以被注册到注册中心
注意: 这个注解是springcloud推行的一个通用注解,除了eureka做注册中心外,使用别的注册中心都可以使用该注解代表被服务发现与注册到注册中心上
@SpringBootApplication
@EnableDiscoveryClient // 作用:通用服务注册客户端注解 代表 consult client zk client nacos client
public class ConsulClientApplication {
public static void main(String[] args) {
SpringApplication.run(ConsulClientApplication.class,args);
}
}
3.启动服务查看consul界面服务信息

consul 开启健康监控检查
1.开启consul健康监控
- 默认情况consul监控健康是开启的,但是必须依赖健康监控依赖才能正确监控健康状态所以直接启动会显示错误,引入健康监控依赖之后服务正常
<!-- 这个包是用做健康度监控的-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
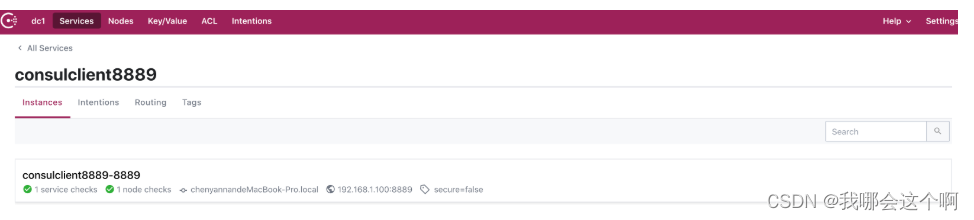
consul 关闭健康监控检查
server.port=8889
spring.application.name=consulclient8889
spring.cloud.consul.host=localhost #注册consul服务的主机
spring.cloud.consul.port=8500 #注册consul服务的端口号
spring.cloud.consul.discovery.register-health-check=false #关闭consu了服务的健康检查[不推荐]
spring.cloud.consul.discovery.service-name=${spring.application.name} #指定注册的服务名称 默认就是应用名
不同注册中心区别
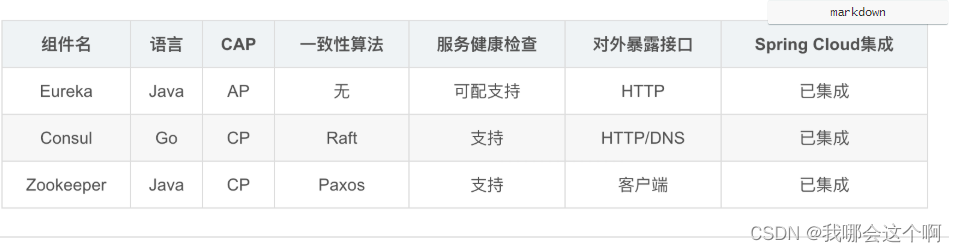
1.CAP定理
- CAP定理:CAP定理又称CAP原则,指的是在一个分布式系统中,
一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)。CAP 原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。 一致性(C):在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本)可用性(A):在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(对数据更新具备高可用性)分区容忍性(P),就是高可用性,一个节点崩了,并不影响其它的节点(100个节点,挂了几个,不影响服务,越多机器越好)
2.Eureka特点
- Eureka中没有使用任何的数据强一致性算法保证不同集群间的Server的数据一致,仅通过数据拷贝的方式争取注册中心数据的最终一致性,虽然放弃数据强一致性但是换来了Server的可用性,降低了注册的代价,提高了集群运行的健壮性。
3.Consul特点
- 基于Raft算法,Consul提供强一致性的注册中心服务,但是由于Leader节点承担了所有的处理工作,势必加大了注册和发现的代价,降低了服务的可用性。通过Gossip协议,Consul可以很好地监控Consul集群的运行,同时可以方便通知各类事件,如Leader选择发生、Server地址变更等。
4.zookeeper特点
- 基于Zab协议,Zookeeper可以用于构建具备数据强一致性的服务注册与发现中心,而与此相对地牺牲了服务的可用性和提高了注册需要的时间。
7. 服务间通信方式
接下来在整个微服务架构中,我们比较关心的就是服务间的服务改如何调用,有哪些调用方式?
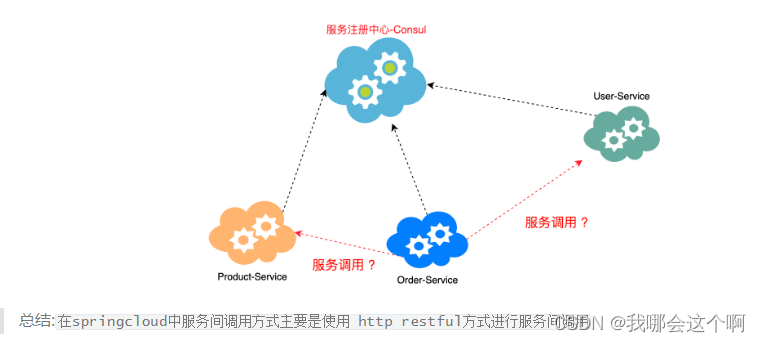
基于RestTemplate的服务调用
0.说明
- spring框架提供的RestTemplate类可用于在应用中调用rest服务,它简化了与http服务的通信方式,统一了RESTful的标准,封装了http链接, 我们只需要传入url及返回值类型即可。相较于之前常用的HttpClient,RestTemplate是一种更优雅的调用RESTful服务的方式。
RestTemplate 服务调用
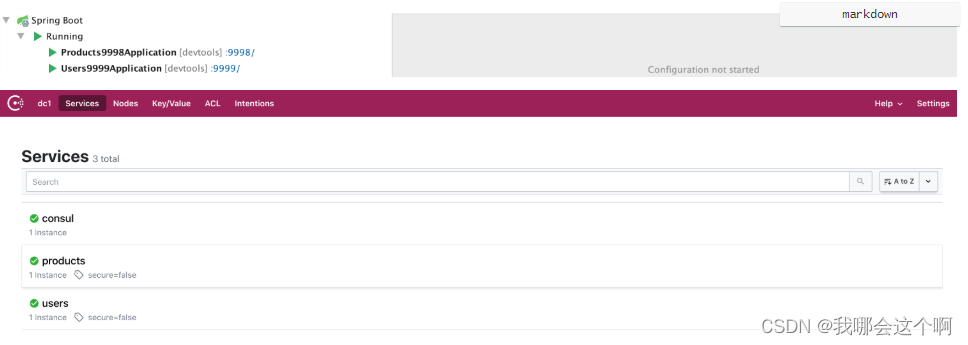
1.创建两个服务并注册到consul注册中心中
- users 代表用户服务 端口为 9999
- products 代表商品服务 端口为 9998
`注意:这里服务仅仅用来测试,没有实际业务意义

2.在商品服务中提供服务方法
@RestController
@Slf4j
public class ProductController {
@Value("${server.port}")
private int port;
@GetMapping("/product/findAll")
public Map<String,Object> findAll(){
log.info("商品服务查询所有调用成功,当前服务端口:[{}]",port);
Map<String, Object> map = new HashMap<String,Object>();
map.put("msg","服务调用成功,服务提供端口为: "+port);
map.put("status",true);
return map;
}
}
3.在用户服务中使用restTemplate进行调用
@RestController
@Slf4j
public class UserController {
@GetMapping("/user/findAll")
public String findAll(){
log.info("调用用户服务...");
//1.使用restTemplate调用商品服务
RestTemplate restTemplate = new RestTemplate();
String forObject = restTemplate.getForObject("http://localhost:9998/product/findAll",
String.class);
return forObject;
}
}
4.启动服务
5.测试服务调用
浏览器访问用户服务 http://localhost:9999/user/findAll

6.总结
- rest Template是直接基于服务地址调用没有在服务注册中心获取服务,也没有办法完成服务的负载均衡如果需要实现服务的负载均衡需要自己书写服务负载均衡策略。
基于Ribbon的服务调用
官方网址: https://github.com/Netflix/ribbon
- Spring Cloud Ribbon是一个基于HTTP和TCP的客户端负载均衡工具,它基于Netflix Ribbon实现。通过Spring Cloud的封装,可以让我们轻松地将面向服务的REST模版请求自动转换成客户端负载均衡的服务调用。
1.Ribbon 服务调用
1.项目中引入依赖
- 说明:
1.如果使用的是eureka client和consul client,无须引入依赖,因为在eureka,consul中默认集成了ribbon组件
2.如果使用的client中没有ribbon依赖需要显式引入如下依赖
<!--引入ribbon依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-ribbon</artifactId>
</dependency>
2.查看consul client中依赖的ribbon

3.使用restTemplate + ribbon进行服务调用
使用discovery client 进行客户端调用使用loadBalanceClient 进行客户端调用使用@loadBalanced 进行客户端调用
3.1 使用discovery Client形式调用
@Autowired
private DiscoveryClient discoveryClient;
//获取服务列表
List<ServiceInstance> products = discoveryClient.getInstances("服务ID");
for (ServiceInstance product : products) {
log.info("服务主机:[{}]",product.getHost());
log.info("服务端口:[{}]",product.getPort());
log.info("服务地址:[{}]",product.getUri());
log.info("====================================");
}
3.2 使用loadBalance Client形式调用
@Autowired
private LoadBalancerClient loadBalancerClient;
//根据负载均衡策略选取某一个服务调用
ServiceInstance product = loadBalancerClient.choose("服务ID");
log.info("服务主机:[{}]",product.getHost());
log.info("服务端口:[{}]",product.getPort());
log.info("服务地址:[{}]",product.getUri());
3.3 使用@loadBalanced
//1.整合restTemplate + ribbon
@Bean
@LoadBalanced
public RestTemplate getRestTemplate(){
return new RestTemplate();
}
//2.调用服务位置注入RestTemplate
@Autowired
private RestTemplate restTemplate;
//3.调用
String forObject = restTemplate.getForObject("http://服务ID/hello/hello?name=" + name, String.class);
2.Ribbon负载均衡策略
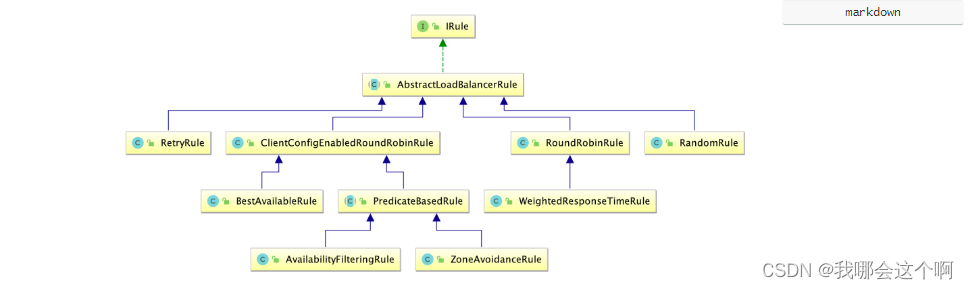
1.ribbon负载均衡算法
-
RoundRobinRule轮训策略 按顺序循环选择 Server -
RandomRule随机策略 随机选择 Server -
AvailabilityFilteringRule可用过滤策略
`会先过滤由于多次访问故障而处于断路器跳闸状态的服务,还有并发的连接数量超过阈值的服务,然后对剩余的服务列表按照轮询策略进行访问 -
WeightedResponseTimeRule响应时间加权策略
`根据平均响应的时间计算所有服务的权重,响应时间越快服务权重越大被选中的概率越高,刚启动时如果统计信息不足,则使用
RoundRobinRule策略,等统计信息足够会切换到 -
RetryRule重试策略
`先按照RoundRobinRule的策略获取服务,如果获取失败则在制定时间内进行重试,获取可用的服务。 -
BestAviableRule最低并发策略
`会先过滤掉由于多次访问故障而处于断路器跳闸状态的服务,然后选择一个并发量最小的服务
3.修改服务的默认负载均衡策略
1.修改服务默认随机策略
- 服务id.ribbon.NFLoadBalancerRuleClassName=com.netflix.loadbalancer.RandomRule 下面的products为服务的唯一标识
products.ribbon.NFLoadBalancerRuleClassName=com.netflix.loadbalancer.RandomRule

4.Ribbon停止维护
1.官方停止维护说明
- https://github.com/Netflix/ribbon

8.OpenFeign组件的使用
- 思考: 使用RestTemplate+ribbon已经可以完成对端的调用,为什么还要使用feign?
String restTemplateForObject = restTemplate.getForObject("http://服务名/url?参数" + name, String.class);
存在问题:
- 1.每次调用服务都需要写这些代码,存在大量的代码冗余
- 2.服务地址如果修改,维护成本增高
- 3.使用时不够灵活
OpenFeign 组件
0.说明
- https://cloud.spring.io/spring-cloud-openfeign/reference/html/
- Feign是一个声明式的伪Http客户端,它使得写Http客户端变得更简单。使用Feign,只需要创建一个接口并注解。它具有可插拔的注解特性(可以使用springmvc的注解),可使用Feign 注解和JAX-RS注解。Feign支持可插拔的编码器和解码器。Feign默认集成了Ribbon,默认实现了负载均衡的效果并且springcloud为feign添加了springmvc注解的支持。
1.openFeign 服务调用
1.服务调用方法引入依赖OpenFeign依赖
<!--Open Feign依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
2.入口类加入注解开启OpenFeign支持
@SpringBootApplication
@EnableFeignClients
public class Users9999Application {
public static void main(String[] args) {
SpringApplication.run(Users9999Application.class, args);
}
}
3.创建一个客户端调用接口
//value属性用来指定:调用服务名称
@FeignClient("PRODUCTS")
public interface ProductClient {
@GetMapping("/product/findAll") //书写服务调用路径
String findAll();
}
4.使用feignClient客户端对象调用服务
//注入客户端对象
@Autowired
private ProductClient productClient;
@GetMapping("/user/findAllFeignClient")
public String findAllFeignClient(){
log.info("通过使用OpenFeign组件调用商品服务...");
String msg = productClient.findAll();
return msg;
}
5.访问并测试服务
- http://localhost:9999/user/findAllFeignClient

2.调用服务并传参
.说明:服务和服务之间通信,不仅仅是调用,往往在调用过程中还伴随着参数传递,接下来重点来看看OpenFeign在调用服务时如何传递参数
GET方式调用服务传递参数
1.GET方式调用服务传递参数
- 在商品服务中加入需要传递参数的服务方法来进行测试
- 在用户服务中进行调用商品服务中需要传递参数的服务方法进行测试
// 1.商品服务中添加如下方法
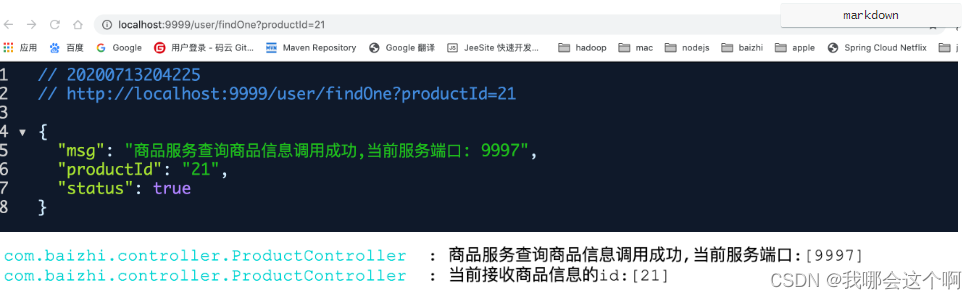
@GetMapping("/product/findOne")
public Map<String,Object> findOne(String productId){
log.info("商品服务查询商品信息调用成功,当前服务端口:[{}]",port);
log.info("当前接收商品信息的id:[{}]",productId);
Map<String, Object> map = new HashMap<String,Object>();
map.put("msg","商品服务查询商品信息调用成功,当前服务端口: "+port);
map.put("status",true);
map.put("productId",productId);
return map;
}
//2.用户服务中在product客户端中声明方法
@FeignClient("PRODUCTS")
public interface ProductClient {
@GetMapping("/product/findOne")
String findOne(@RequestParam("productId") String productId);
}
//3.用户服务中调用并传递参数
//注入客户端对象
@Autowired
private ProductClient productClient;
@GetMapping("/user/findAllFeignClient")
public String findAllFeignClient(){
log.info("通过使用OpenFeign组件调用商品服务...");
String msg = productClient.findAll();
return msg;
}
测试访问
post方式调用服务传递参数
2.post方式调用服务传递参数
- 在商品服务中加入需要传递参数的服务方法来进行测试
- 在用户服务中进行调用商品服务中需要传递参数的服务方法进行测试
//1.商品服务加入post方式请求并接受name
@PostMapping("/product/save")
public Map<String,Object> save(String name){
log.info("商品服务保存商品调用成功,当前服务端口:[{}]",port);
log.info("当前接收商品名称:[{}]",name);
Map<String, Object> map = new HashMap<String,Object>();
map.put("msg","商品服务查询商品信息调用成功,当前服务端口: "+port);
map.put("status",true);
map.put("name",name);
return map;
}
//2.用户服务中在product客户端中声明方法
//value属性用来指定:调用服务名称
@FeignClient("PRODUCTS")
public interface ProductClient {
@PostMapping("/product/save")
String save(@RequestParam("name") String name);
}
//3.用户服务中调用并传递参数
@Autowired
private ProductClient productClient;
@GetMapping("/user/save")
public String save(String productName){
log.info("接收到的商品信息名称:[{}]",productName);
String save = productClient.save(productName);
log.info("调用成功返回结果: "+save);
return save;
}
测试访问

2.传递对象类型参数
- 商品服务定义对象
- 商品服务定义对象接收方法
- 用户服务调用商品服务定义对象参数方法进行参数传递
//1.商品服务定义对象
@Data
public class Product {
private Integer id;
private String name;
private Date bir;
}
//2.商品服务定义接收对象的方法
@PostMapping("/product/saveProduct")
public Map<String,Object> saveProduct(@RequestBody Product product){
log.info("商品服务保存商品信息调用成功,当前服务端口:[{}]",port);
log.info("当前接收商品名称:[{}]",product);
Map<String, Object> map = new HashMap<String,Object>();
map.put("msg","商品服务查询商品信息调用成功,当前服务端口: "+port);
map.put("status",true);
map.put("product",product);
return map;
}
//3.将商品对象复制到用户服务中
//4.用户服务中在product客户端中声明方法
@FeignClient("PRODUCTS")
public interface ProductClient {
@PostMapping("/product/saveProduct")
String saveProduct(@RequestBody Product product);
}
// 5.在用户服务中调用保存商品信息服务
//注入客户端对象
@Autowired
private ProductClient productClient;
@GetMapping("/user/saveProduct")
public String saveProduct(Product product){
log.info("接收到的商品信息:[{}]",product);
String save = productClient.saveProduct(product);
log.info("调用成功返回结果: "+save);
return save;
}
测试

OpenFeign超时设置
默认情况下,openFiegn在进行服务调用时,要求服务提供方处理业务逻辑时间必须在1S内返回,如果超过1S没有返回则OpenFeign会直接报错,不会等待服务执行,但是往往在处理复杂业务逻辑是可能会超过1S,因此需要修改OpenFeign的默认服务调用超时时间。
- 调用超时会出现如下错误:
1.模拟超时
- 服务提供方加入线程等待阻塞
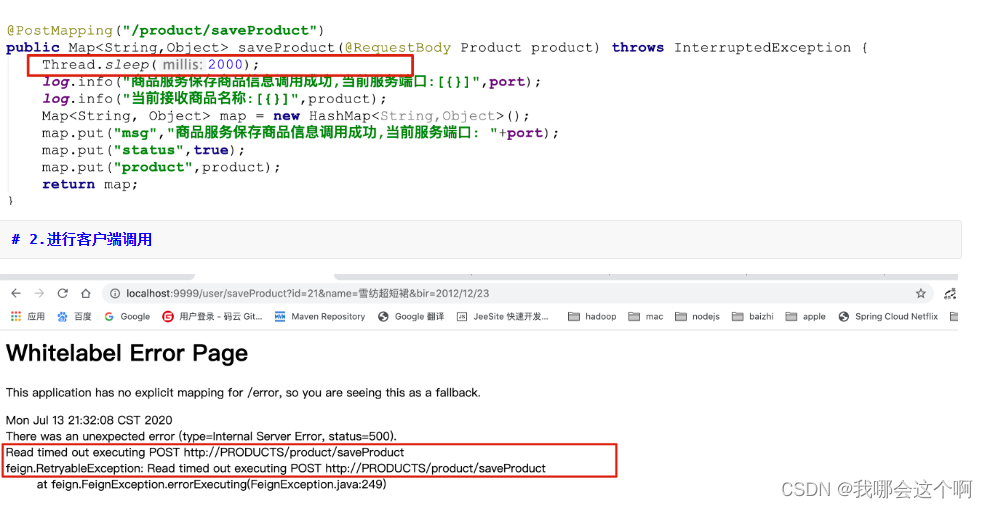
3.修改OpenFeign默认超时时间
feign.client.config.PRODUCTS.connectTimeout=5000 #配置指定服务连接超时
feign.client.config.PRODUCTS.readTimeout=5000 #配置指定服务等待超时
#feign.client.config.default.connectTimeout=5000 #配置所有服务连接超时
#feign.client.config.default.readTimeout=5000 #配置所有服务等待超时
OpenFeign调用详细日志展示
0.说明
-
往往在服务调用时我们需要详细展示feign的日志,默认feign在调用是并不是最详细日志输出,因此在调试程序时应该开启feign的详细日志展示。feign对日志的处理非常灵活可为每个feign客户端指定日志记录策略,每个客户端都会创建一个logger默认情况下logger的名称是feign的全限定名需要注意的是,feign日志的打印只会DEBUG级别做出响应。
-
我们可以为feign客户端配置各自的logger.lever对象,告诉feign记录那些日志logger.lever有以下的几种值
NONE 不记录任何日志BASIC 仅仅记录请求方法,url,响应状态代码及执行时间HEADERS 记录Basic级别的基础上,记录请求和响应的headerFULL 记录请求和响应的header,body和元数据
1.开启日志展示
feign.client.config.PRODUCTS.loggerLevel=full #开启指定服务日志展示
#feign.client.config.default.loggerLevel=full #全局开启服务日志展示
logging.level.com.baizhi.feignclients=debug #指定feign调用客户端对象所在包,必须是debug级别
2.测试服务调用查看日志

Hystrix组件使用
Hystrix组件

0.说明
- https://github.com/Netflix/Hystrix
- 译: 在分布式环境中,许多服务依赖项不可避免地会失败。Hystrix是一个库,它通过添加延迟容忍和容错逻辑来帮助您控制这些分布式服务之间的交互。Hystrix通过隔离服务之间的访问点、停止它们之间的级联故障以及提供后备选项来实现这一点,所有这些都可以提高系统的整体弹性。
- 通俗定义: Hystrix是一个用于处理分布式系统的延迟和容错的开源库,在分布式系统中,许多依赖不可避免的会调用失败,超时、异常等,Hystrix能够保证在一个依赖出问题的情况下,不会导致整体服务失败,避免级联故障(服务雪崩现象),提高分布式系统的弹性。
1.作用
-
hystrix 用来保护微服务系统 实现 服务降级 服务熔断
-
服务雪崩
-
服务降级
-
服务熔断
1.服务雪崩
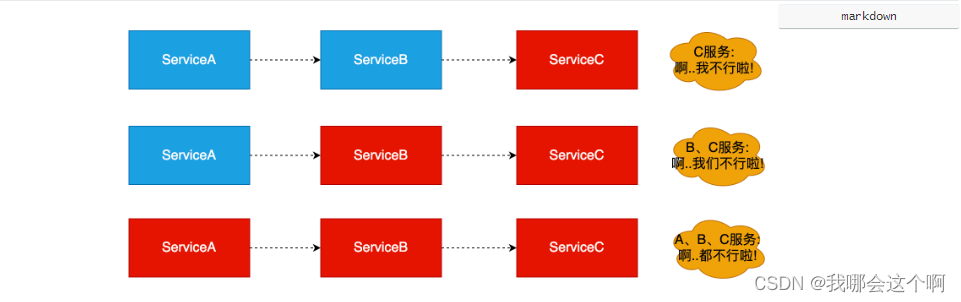
1.服务雪崩
- 在微服务之间进行服务调用是由于某一个服务故障,导致级联服务故障的现象,称为雪崩效应。雪崩效应描述的是提供方不可用,导致消费方不可用并将不可用逐渐放大的过程。
2.图解雪崩效应
- 如存在如下调用链路:

- 而此时,Service A的流量波动很大,流量经常会突然性增加!那么在这种情况下,就算Service A能扛得住请求,Service B和Service C未必能扛得住这突发的请求。此时,如果Service C因为抗不住请求,变得不可用。那么Service B的请求也会阻塞,慢慢耗尽Service B的线程资源,Service B就会变得不可用。紧接着,Service A也会不可用,这一过程如下图所示
2.服务熔断
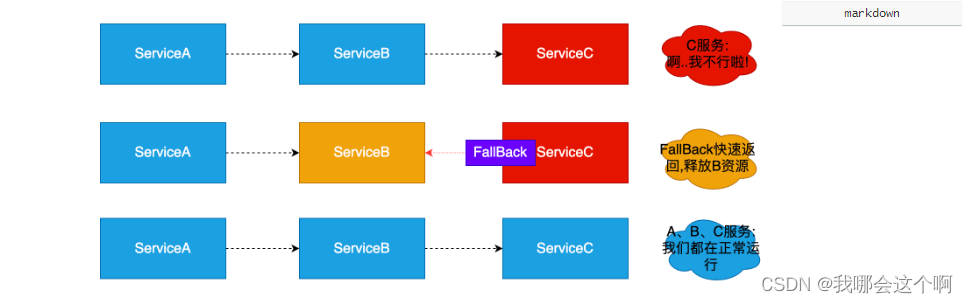
服务熔断
- “熔断器”本身是一种开关装置,当某个服务单元发生故障之后,通过断路器(hystrix)的故障监控,某个异常条件被触发,直接熔断整个服务。向调用方法返回一个符合预期的、可处理的备选响应(FallBack),而不是长时间的等待或者抛出调用方法无法处理的异常,就保证了服务调用方的线程不会被长时间占用,避免故障在分布式系统中蔓延,乃至雪崩。如果目标服务情况好转则恢复调用。服务熔断是解决服务雪崩的重要手段。
服务熔断图示
3.服务降级
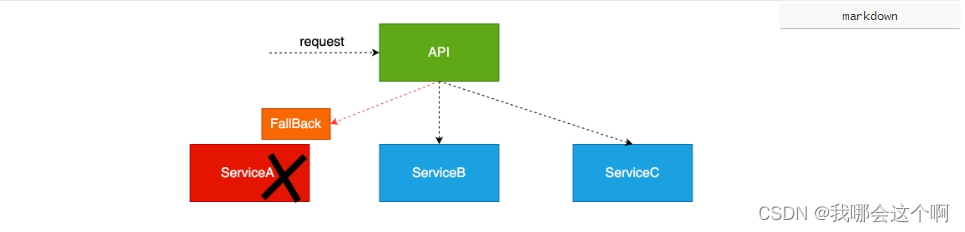
服务降级说明
-
服务压力剧增的时候根据当前的业务情况及流量对一些服务和页面有策略的降级,以此缓解服务器的压力,以保证核心任务的进行。同时保证部分甚至大部分任务客户能得到正确的响应。也就是当前的请求处理不了了或者出错了,给一个默认的返回。
-
服务降级: 关闭微服务系统中某些边缘服务 保证系统核心服务正常运行
-
12 淘宝 京东
-
删除订单 — 关闭订单 确认收货 ----> 服务繁忙,!!!
服务降级图示
4.降级和熔断总结
1.共同点
- 目的很一致,都是从可用性可靠性着想,为防止系统的整体缓慢甚至崩溃,采用的技术手段;
- 最终表现类似,对于两者来说,最终让用户体验到的是某些功能暂时不可达或不可用;
- 粒度一般都是服务级别,当然,业界也有不少更细粒度的做法,比如做到数据持久层(允许查询,不允许增删改);
- 自治性要求很高,熔断模式一般都是服务基于策略的自动触发,降级虽说可人工干预,但在微服务架构下,完全靠人显然不可能,开关预置、配置中心都是必要手段;sentinel
2.异同点
- 触发原因不太一样,服务熔断一般是某个服务(下游服务)故障引起,而服务降级一般是从整体负荷考虑;
- 管理目标的层次不太一样,熔断其实是一个框架级的处理,每个微服务都需要(无层级之分),而降级一般需要对业务有层级之分(比如降级一般是从最外围服务边缘服务开始)
3.总结
- 熔断必会触发降级,所以熔断也是降级一种,区别在于熔断是对调用链路的保护,而降级是对系统过载的一种保护处理
5.服务熔断的实现
0.服务熔断的实现思路
- 引入hystrix依赖,并开启熔断器(断路器)
- 模拟降级方法
- 进行调用测试
1.项目中引入hystrix依赖
<!--引入hystrix-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
2.开启断路器
@SpringBootApplication
@EnableCircuitBreaker //用来开启断路器
public class Products9998Application {
public static void main(String[] args) {
SpringApplication.run(Products9998Application.class, args);
}
}
3.使用HystrixCommand注解实现断路
//服务熔断
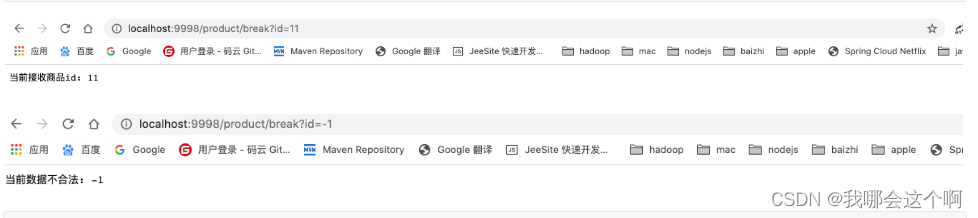
@GetMapping("/product/break")
@HystrixCommand(fallbackMethod = "testBreakFall" )
public String testBreak(int id){
log.info("接收的商品id为: "+ id);
if(id<=0){
throw new RuntimeException("数据不合法!!!");
}
return "当前接收商品id: "+id;
}
public String testBreakFall(int id){
return "当前数据不合法: "+id;
}
4.访问测试
- 正常参数访问
- 错误参数访问
5.总结
- 从上面演示过程中会发现如果触发一定条件断路器会自动打开,过了一点时间正常之后又会关闭。那么断路器打开条件是什么呢?
6.断路器打开条件
- 官网: https://cloud.spring.io/spring-cloud-netflix/2.2.x/reference/html/#circuit-breaker-spring-cloud-circuit-breaker-with-hystrix
A service failure in the lower level of services can cause cascading failure all the way up to the user. When calls to a particular service exceed circuitBreaker.requestVolumeThreshold (default: 20 requests) and the failure percentage is greater than circuitBreaker.errorThresholdPercentage (default: >50%) in a rolling window defined by metrics.rollingStats.timeInMilliseconds (default: 10 seconds), the circuit opens and the call is not made. In cases of error and an open circuit, a fallback can be provided by the developer. --摘自官方
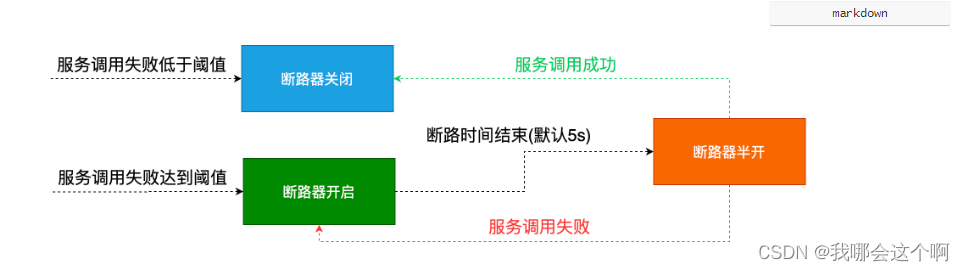
原文翻译之后,总结打开关闭的条件:
- 1、 当满足一定的阀值的时候(默认10秒内超过20个请求次数)
- 2、 当失败率达到一定的时候(默认10秒内超过50%的请求失败)
- 3、 到达以上阀值,断路器将会开启
- 4、 当开启的时候,所有请求都不会进行转发
- 5、 一段时间之后(默认是5秒),这个时候断路器是半开状态,会让其中一个请求进行转发。如果成功,断路器会关闭,若失败,继续开启。重复4和5。
面试重点问题: 断路器流程
7.默认的服务FallBack处理方法
- 如果为每一个服务方法开发一个降级,对于我们来说,可能会出现大量的代码的冗余,不利于维护,这个时候就需要加入默认服务降级处理方法
@GetMapping("/product/hystrix")
@HystrixCommand(fallbackMethod = "testHystrixFallBack") //通过HystrixCommand降级处理 指定出错的方法
public String testHystrix(String name) {
log.info("接收名称为: " + name);
int n = 1/0;
return "服务[" + port + "]响应成功,当前接收名称为:" + name;
}
//服务降级处理
public String testHystrixFallBack(String name) {
return port + "当前服务已经被降级处理!!!,接收名称为: "+name;
}

6.服务降级的实现
服务降级: 站在系统整体负荷角度 实现: 关闭系统中某些边缘服务 保证系统核心服务运行
Emps 核心服务 Depts 边缘服务
1.客户端openfeign + hystrix实现服务降级实现
- 引入hystrix依赖
- 配置文件开启feign支持hystrix
- 在feign客户端调用加入fallback指定降级处理
- 开发降级处理方法
2.开启openfeign支持服务降级
feign.hystrix.enabled=true #开启openfeign支持降级
3.在openfeign客户端中加如Hystrix
@FeignClient(value = "PRODUCTS",fallback = ProductFallBack.class)
public interface ProductClient {
@GetMapping("/product/hystrix")
String testHystrix(@RequestParam("name") String name);
}

4.开发fallback处理类
public class ProductFallBack implements ProductClient {
@Override
public String testHystrix(String name) {
return "我是客户端的Hystrix服务实现!!!";
}
}

7.Hystrix Dashboard(仪表盘)
Hystrix DashBoard 仪表盘
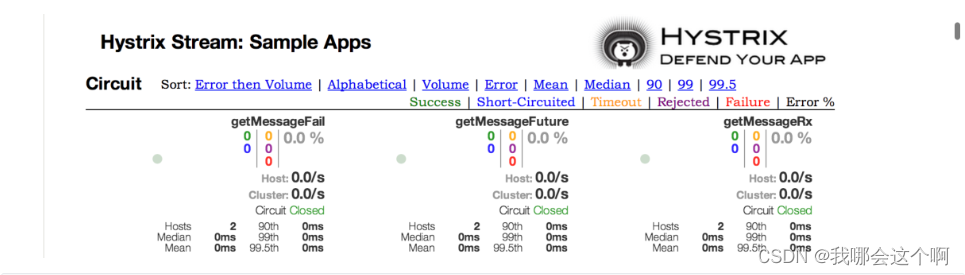
0.说明
- Hystrix Dashboard的一个主要优点是它收集了关于每个HystrixCommand的一组度量。Hystrix仪表板以高效的方式显示每个断路器的运行状况。
1.项目中引入依赖
<!--引入hystrix dashboard 依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId>
</dependency>
2.入口类中开启hystrix dashboard
@SpringBootApplication
@EnableHystrixDashboard //开启监控面板
public class Hystrixdashboard9990Application {
public static void main(String[] args) {
SpringApplication.run(Hystrixdashboard9990Application.class, args);
}
}
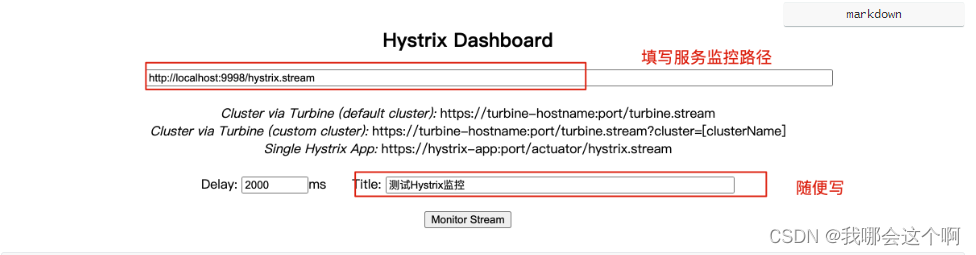
3.启动hystrix dashboard应用
- http://localhost:9990(dashboard端口)/hystrix

4.监控的项目中入口类中加入监控路径配置[新版本坑],并启动监控项目
@Bean
public ServletRegistrationBean getServlet() {
HystrixMetricsStreamServlet streamServlet = new HystrixMetricsStreamServlet();
ServletRegistrationBean registrationBean = new ServletRegistrationBean(streamServlet);
registrationBean.setLoadOnStartup(1);
registrationBean.addUrlMappings("/hystrix.stream");
registrationBean.setName("HystrixMetricsStreamServlet");
return registrationBean;
}
5.通过监控界面监控
6.点击监控,一致loading,打开控制台发现报错[特别坑]

解决方案
-
新版本中springcloud将jquery版本升级为3.4.1,定位到monitor.ftlh文件中,js的写法如下:
$(window).load(function() -
jquery 3.4.1已经废弃上面写法
-
修改方案 修改monitor.ftlh为如下调用方式:
$(window).on(“load”,function() -
编译jar源文件,重新打包引入后,界面正常响应。
10.Gateway组件使用
什么是服务网关
1.说明
-
网关统一服务入口,可方便实现对平台众多服务接口进行管控,对访问服务的身份认证、防报文重放与防数据篡改、功能调用的业务鉴权、响应数据的脱敏、流量与并发控制,甚至基于API调用的计量或者计费等等。
-
网关 = 路由转发 + 过滤器
- 路由转发:接收一切外界请求,转发到后端的微服务上去;
- 在服务网关中可以完成一系列的横切功能,例如权限校验、限流以及监控等,这些都可以通过过滤器完成
2.为什么需要网关
- 1.网关可以实现服务的统一管理
- 2.网关可以解决微服务中通用代码的冗余问题(如权限控制,流量监控,限流等)
3.网关组件在微服务中架构
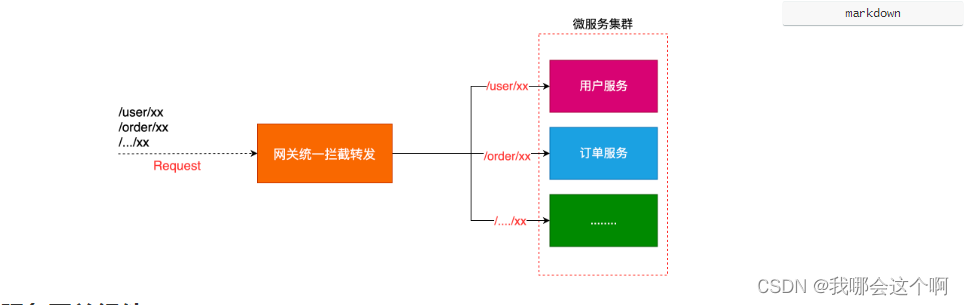
.
服务网关组件
zuul 1.x 2.x(netflix 组件)
Zuul is the front door for all requests from devices and web sites to the backend of the Netflix streaming application. As an edge service application, Zuul is built to enable dynamic routing, monitoring, resiliency and security.
0.原文翻译
- https://github.com/Netflix/zuul/wiki
- zul是从设备和网站到Netflix流媒体应用程序后端的所有请求的前门。作为一个边缘服务应用程序,zul被构建为支持动态路由、监视、弹性和安全性。
1.zuul版本说明
- 目前zuul组件已经从1.0更新到2.0,但是作为springcloud官方不再推荐使用zuul2.0,但是依然支持zuul2.
2.springcloud 官方集成zuul文档
- https://cloud.spring.io/spring-cloud-netflix/2.2.x/reference/html/#netflix-zuul-starter
gateway (spring)
This project provides a library for building an API Gateway on top of Spring MVC. Spring Cloud Gateway aims to provide a simple, yet effective way to route to APIs and provide cross cutting concerns to them such as: security, monitoring/metrics, and resiliency.
0.原文翻译
- https://spring.io/projects/spring-cloud-gateway
- 这个项目提供了一个在springmvc之上构建API网关的库。springcloudgateway旨在提供一种简单而有效的方法来路由到api,并为api提供横切关注点,比如:安全性、监控/度量和弹性。
1.特性
- 基于springboot2.x 和 spring webFlux 和 Reactor 构建 响应式异步非阻塞IO模型
- 动态路由
- 请求过滤
1.开发网关动态路由
0.翻译
- 网关配置有两种方式一种是快捷方式(Java代码编写网关),一种是完全展开方式(配置文件方式)[推荐]
1.创建项目引入网关依赖
<!--引入gateway网关依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
快捷方式配置路由
2.编写网关配置
spring:
application:
name: gateway
cloud:
consul:
host: localhost
port: 8500
gateway:
routes:
- id: user_route # 指定路由唯一标识
uri: http://localhost:9999/ # 指定路由服务的地址
predicates:
- Path=/user/** # 指定路由规则
- id: product_route
uri: http://localhost:9998/
predicates:
- Path=/product/**
server:
port: 8989
3.启动gateway网关项目
- 直接启动报错:

再次启动成功启动

4.测试网关路由转发
- 测试通过网关访问用户服务: http://localhost:8989/user/findOne?productId=21
- 测试通过网关访问商品服务: http://localhost:8989/product/findOne?productId=1
java方式配置路由
@Configuration
public class GatewayConfig {
@Bean
public RouteLocator customRouteLocator(RouteLocatorBuilder builder) {
return builder.routes()
.route("order_route", r -> r.path("/order/**")
.uri("http://localhost:9997"))
.build();
}
}
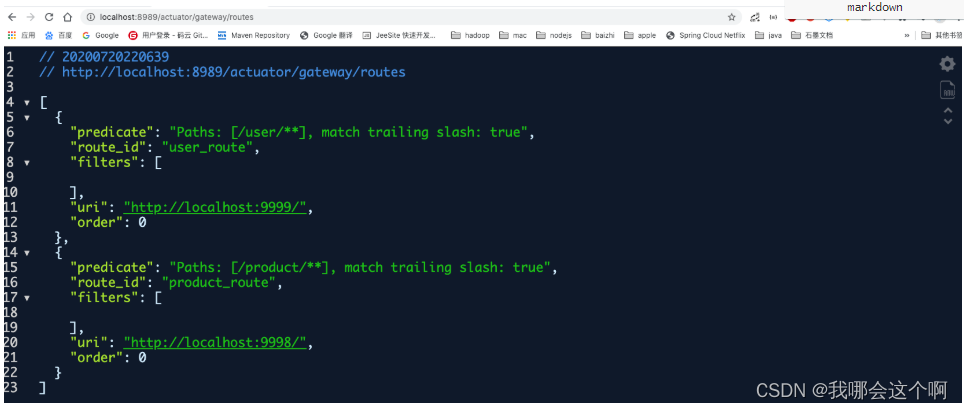
2.查看网关路由规则列表
1.说明
- gateway提供路由访问规则列表的web界面,但是默认是关闭的,如果想要查看服务路由规则可以在配置文件中开启
management:
endpoints:
web:
exposure:
include: "*" #开启所有web端点暴露
访问路由管理列表地址
- http://localhost:8989/actuator/gateway/routes
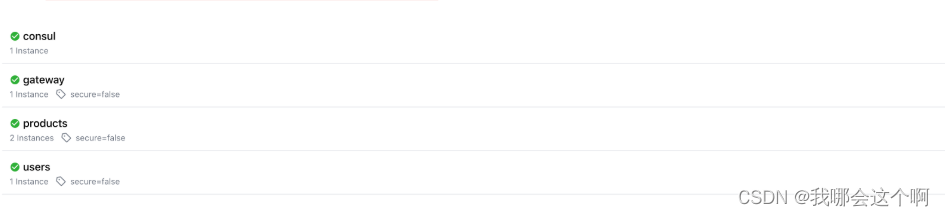
3.配置路由服务负载均衡
1.说明
- 现有路由配置方式,都是基于服务地址写死的路由转发,能不能根据服务名称进行路由转发同时实现负载均衡的呢?
2.动态路由以及负载均衡转发配置
spring:
application:
name: gateway
cloud:
consul:
host: localhost
port: 8500
gateway:
routes:
- id: user_route
#uri: http://localhost:9999/
uri: lb://users # lb代表转发后台服务使用负载均衡,users代表服务注册中心上的服务名
predicates:
- Path=/user/**
- id: product_route
#uri: http://localhost:9998/
uri: lb://products # lb(loadbalance)代表负载均衡转发路由
predicates:
- Path=/product/**
discovery:
locator:
enabled: true #开启根据服务名动态获取路由
4.常用路由predicate(断言,验证)
1.Gateway支持多种方式的predicate

After=2020-07-21T11:33:33.993+08:00[Asia/Shanghai] `指定日期之后的请求进行路由
-
Before=2020-07-21T11:33:33.993+08:00[Asia/Shanghai] `指定日期之前的请求进行路由
-
Between=2017-01-20T17:42:47.789-07:00[America/Denver], 2017-01-21T17:42:47.789-07:00[America/Denver]
-
Cookie=username,chenyn `基于指定cookie的请求进行路由
-
Cookie=username,[A-Za-z0-9]+
基于指定cookie的请求进行路由curl http://localhost:8989/user/findAll --cookie “username=zhangsna” -
Header=X-Request-Id, \d+ ``基于请求头中的指定属性的正则匹配路由(这里全是整数)
`curl http://localhost:8989/user/findAll -H “X-Request-Id:11” -
Method=GET,POST `基于指定的请求方式请求进行路由
-
官方更多: https://cloud.spring.io/spring-cloud-static/spring-cloud-gateway/2.2.3.RELEASE/reference/html/#the-cookie-route-predicate-factory
2.使用predicate
spring:
application:
name: gateway
cloud:
consul:
host: localhost
port: 8500
gateway:
routes:
- id: user_route
#uri: http://localhost:9999/
uri: lb://users
predicates:
- Path=/user/**
- After=2020-07-21T11:39:33.993+08:00[Asia/Shanghai]
- Cookie=username,[A-Za-z0-9]+
- Header=X-Request-Id, \d+

5.常用的Filter以及自定义filter
Route filters allow the modification of the incoming HTTP request or outgoing HTTP response in some manner. Route filters are scoped to a particular route. Spring Cloud Gateway includes many built-in GatewayFilter Factories.
1.原文翻译
-
官网:
https://cloud.spring.io/spring-cloud-static/spring-cloud-gateway/2.2.3.RELEASE/reference/html/#gatewayfilter-factories -
路由过滤器允许以某种方式修改传入的HTTP请求或传出的HTTP响应。路由筛选器的作用域是特定路由。springcloudgateway包括许多内置的GatewayFilter工厂。
2.作用
- 当我们有很多个服务时,比如下图中的user-service、order-service、product-service等服务,客户端请求各个服务的Api时,每个服务都需要做相同的事情,比如鉴权、限流、日志输出等。

2.使用内置过滤器

- AddRequestHeader=X-Request-red, blue
增加请求头的filter - AddRequestParameter=red, blue
增加请求参数的filterr - AddResponseHeader=X-Response-Red, AAA
增加响应头filter - PrefixPath=/emp
增加前缀的filter - StripPrefix=2
去掉前缀的filter
3.使用自定义filter
@Configuration
@Slf4j
public class CustomGlobalFilter implements GlobalFilter, Ordered {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
log.info("进入自定义的filter");
if(exchange.getRequest().getQueryParams().get("username")!=null){
log.info("用户身份信息合法,放行请求继续执行!!!");
return chain.filter(exchange);
}
log.info("非法用户,拒绝访问!!!");
return exchange.getResponse().setComplete();
}
@Override
public int getOrder() {
return -1;
}
}
11.Config组件使用
什么是Config
0.说明
-
https://cloud.spring.io/spring-cloud-static/spring-cloud-config/2.2.3.RELEASE/reference/html/#_spring_cloud_config_server
-
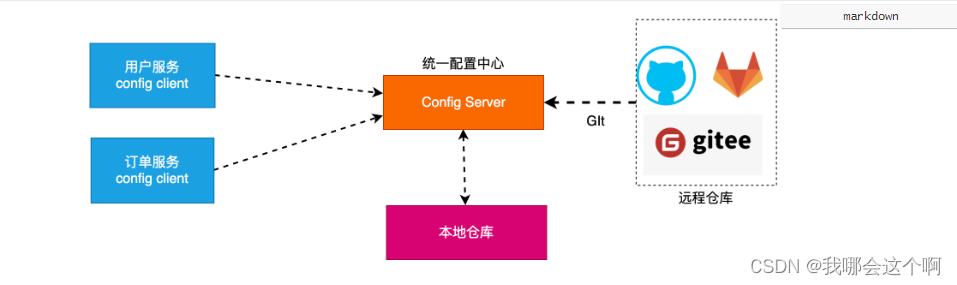
config(配置)又称为 统一配置中心顾名思义,就是将配置统一管理,配置统一管理的好处是在日后大规模集群部署服务应用时相同的服务配置一致,日后再修改配置只需要统一修改全部同步,不需要一个一个服务手动维护。
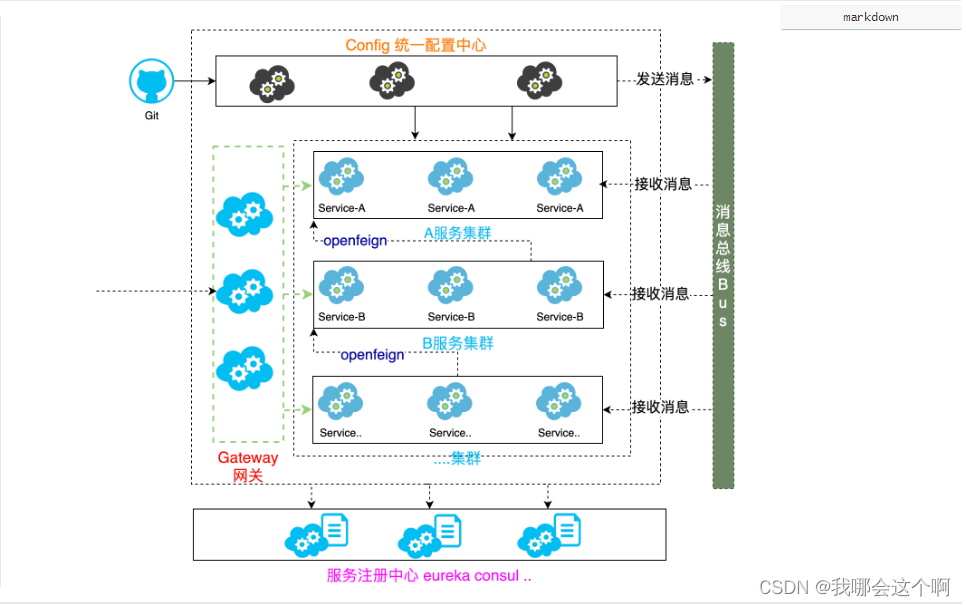
1.统一配置中心组件流程图
Config Server 开发
1.引入依赖
<!--引入统一配置中心-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-config-server</artifactId>
</dependency>
2.开启统一配置中心服务
@SpringBootApplication
@EnableConfigServer
public class Configserver7878Application {
public static void main(String[] args) {
SpringApplication.run(Configserver7878Application.class, args);
}
}
3.修改配置文件
server.port=7878
spring.application.name=configserver
spring.cloud.consul.host=localhost
spring.cloud.consul.port=8500
4.直接启动服务报错
- 没有指定远程仓库的相关配置
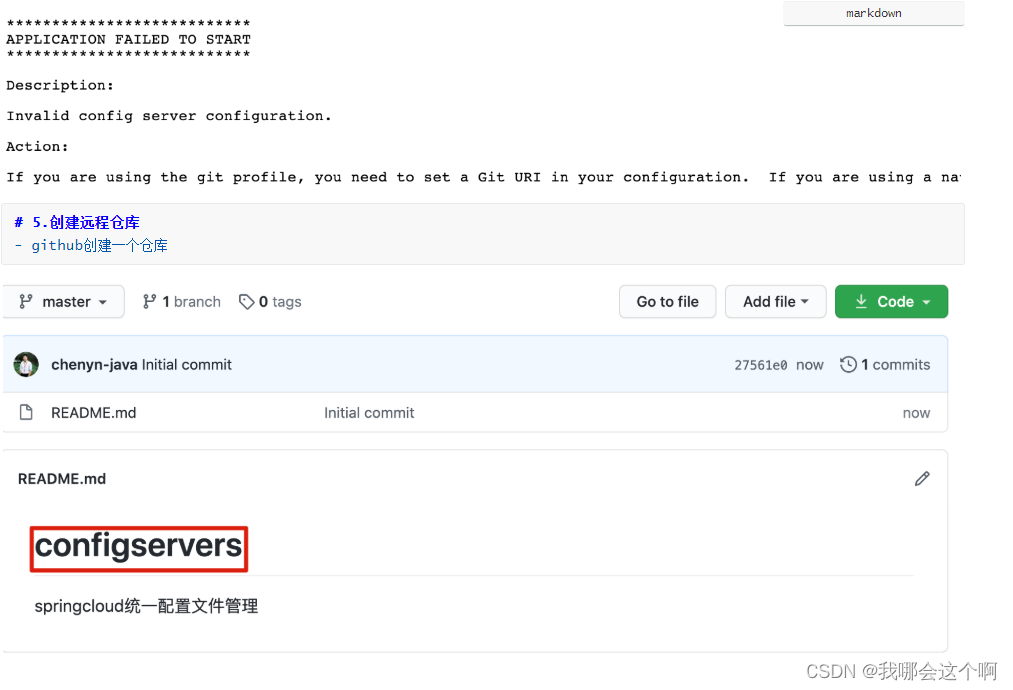
6.复制仓库地址
- https://github.com/chenyn-java/configservers.git

7.在统一配置中心服务中修改配置文件指向远程仓库地址
spring.cloud.config.server.git.uri=https://github.com/chenyn-java/configservers.git 指定仓库的url
spring.cloud.config.server.git.default-label=master 指定访问的分支
#spring.cloud.config.server.git.username= 私有仓库访问用户名
#spring.cloud.config.server.git.password= 私有仓库访问密码
8.再次启动统一配置中心

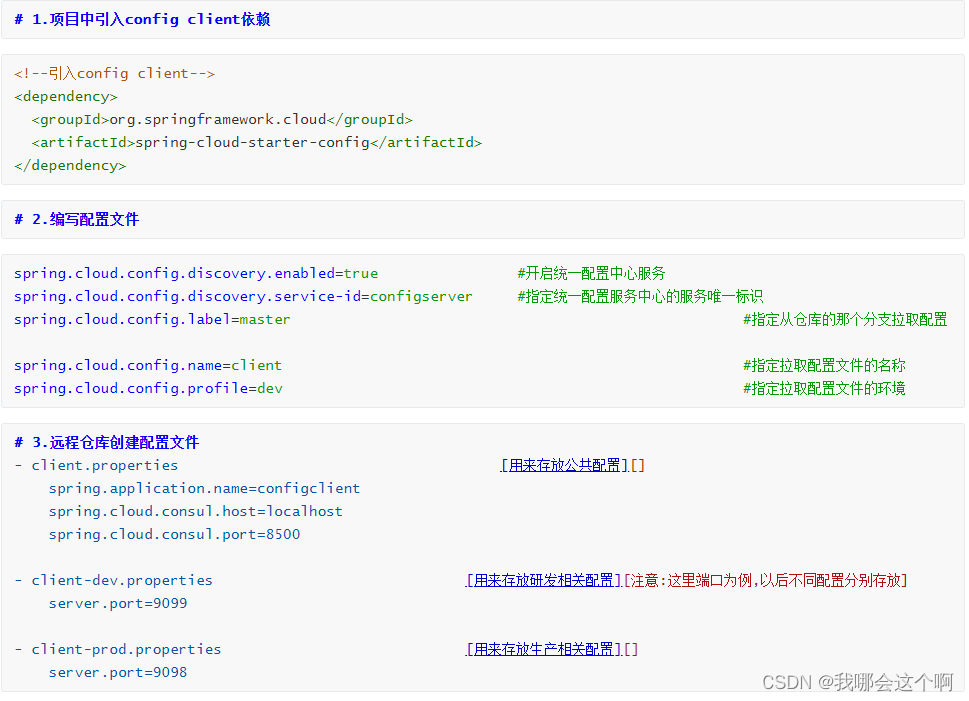
Config Client 开发
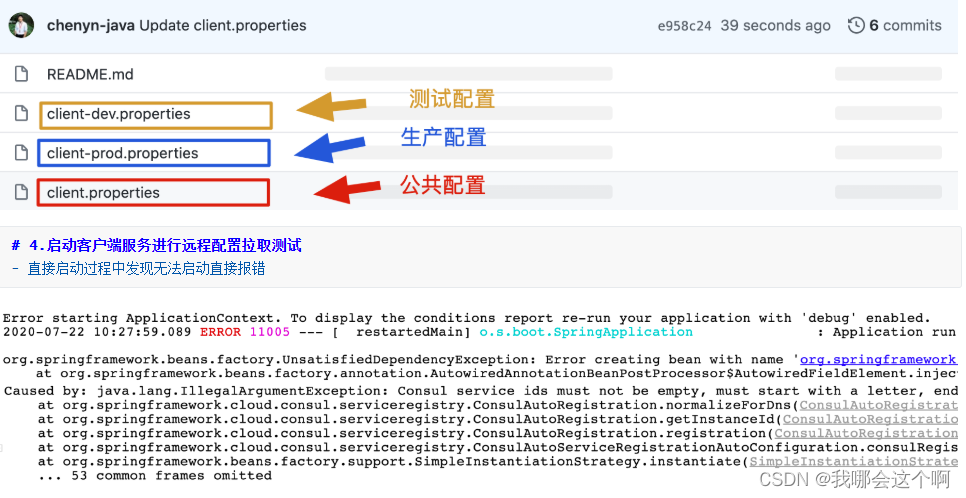
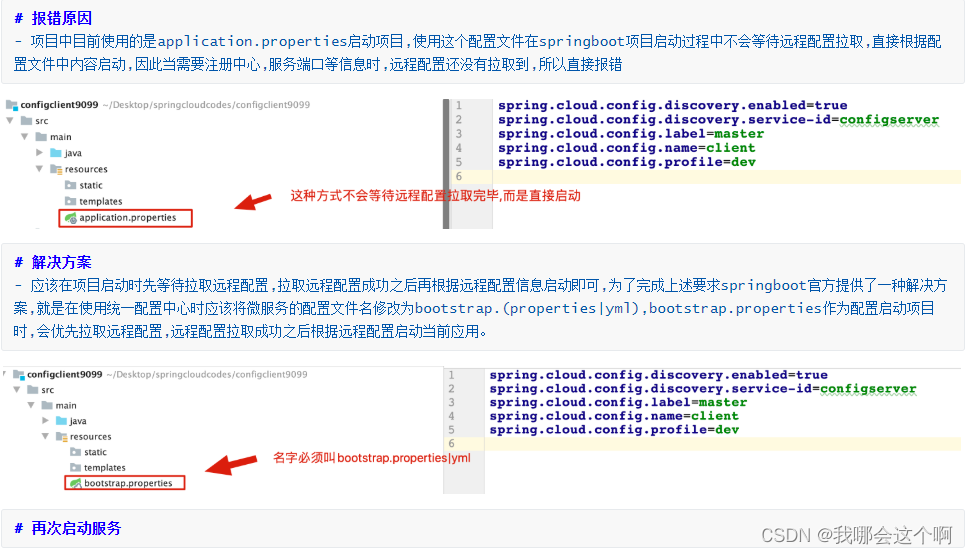
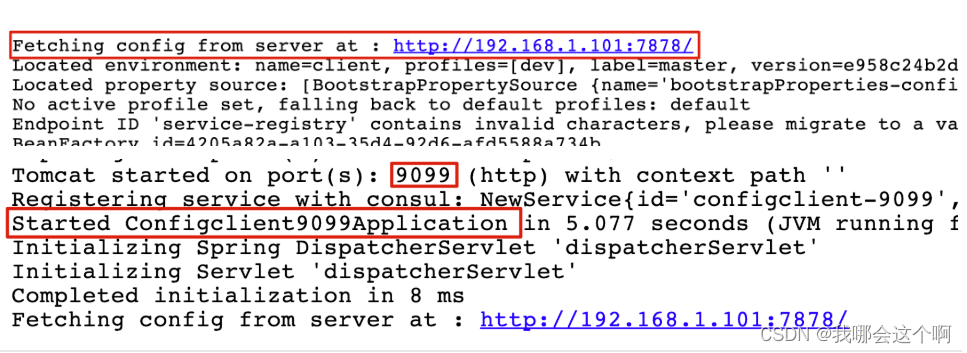
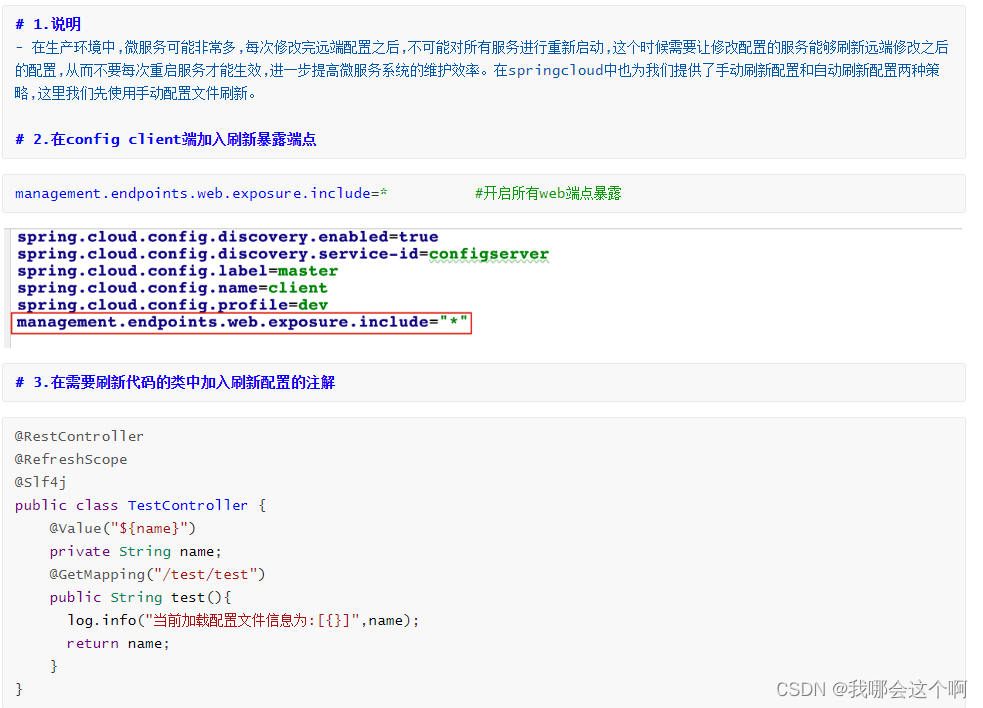
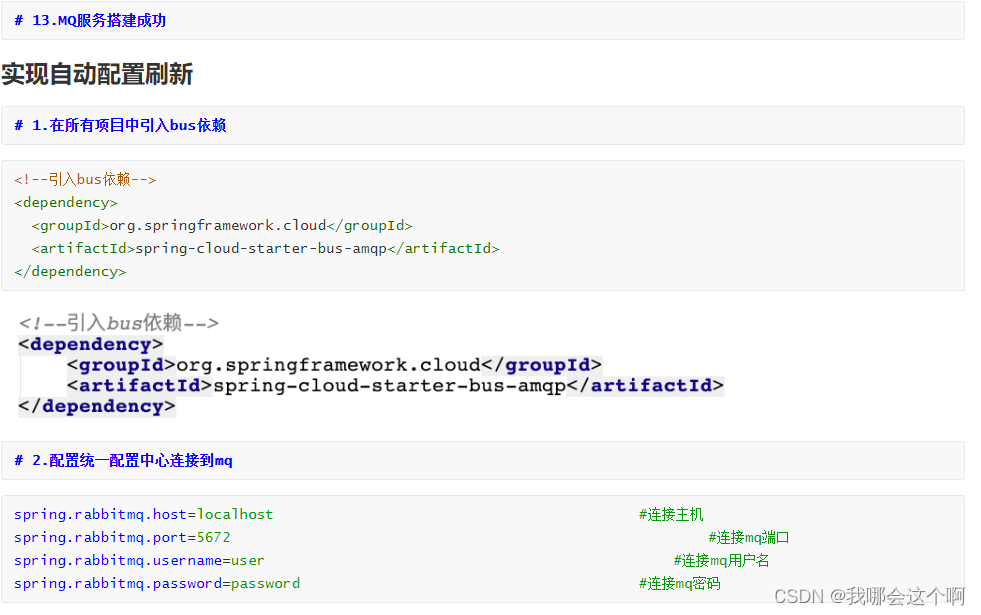
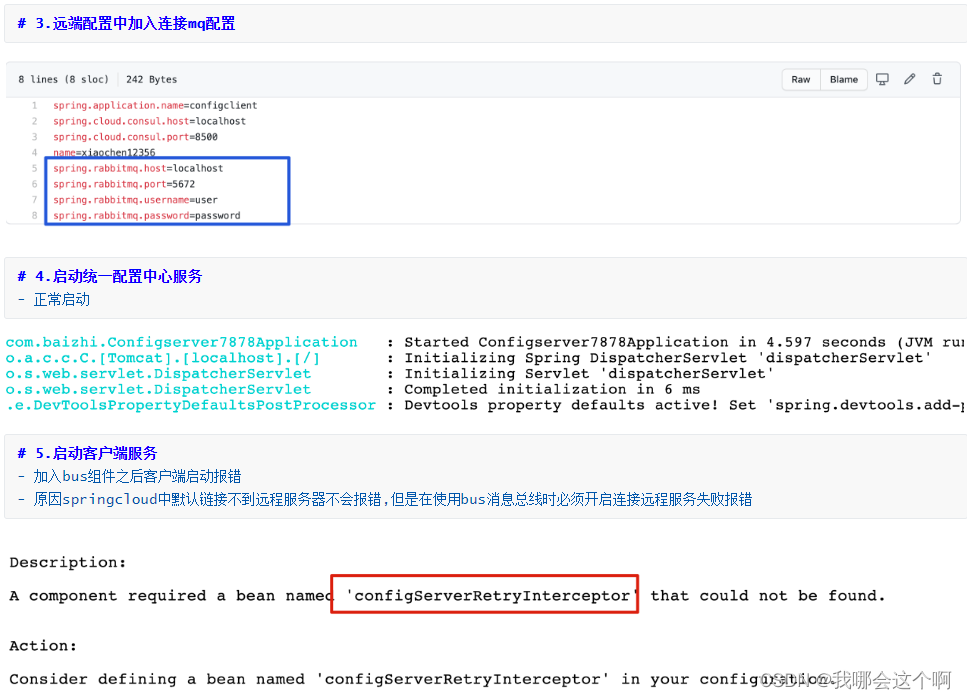
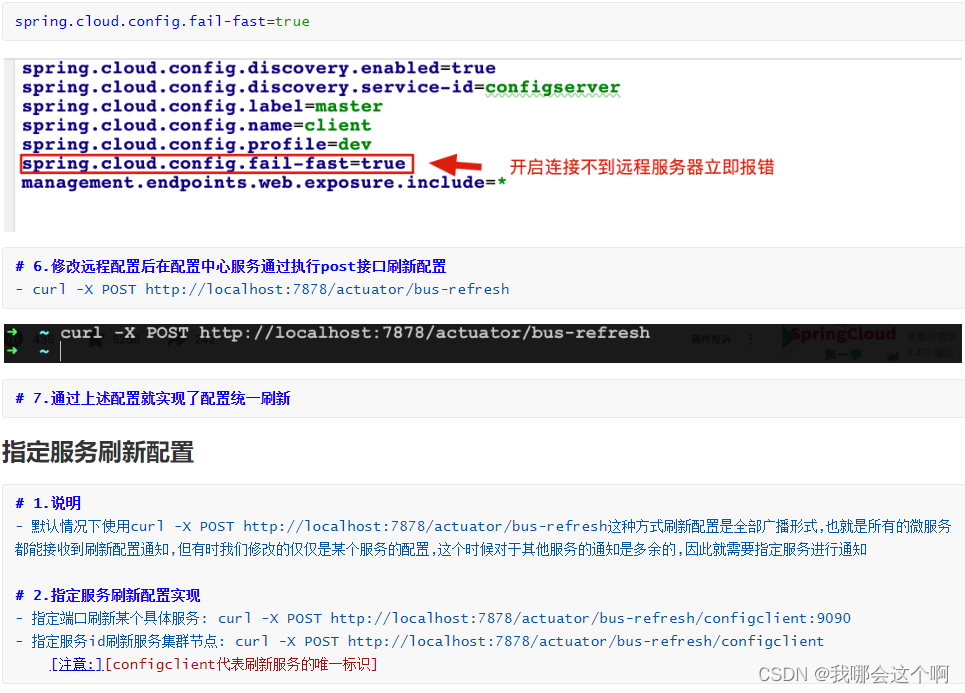
手动配置刷新
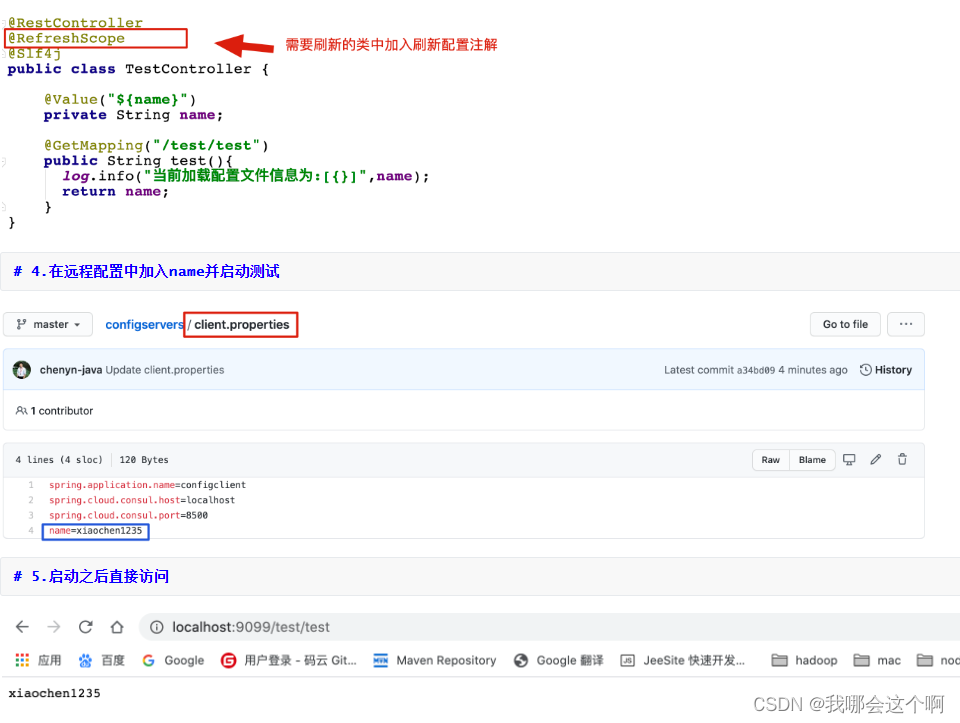

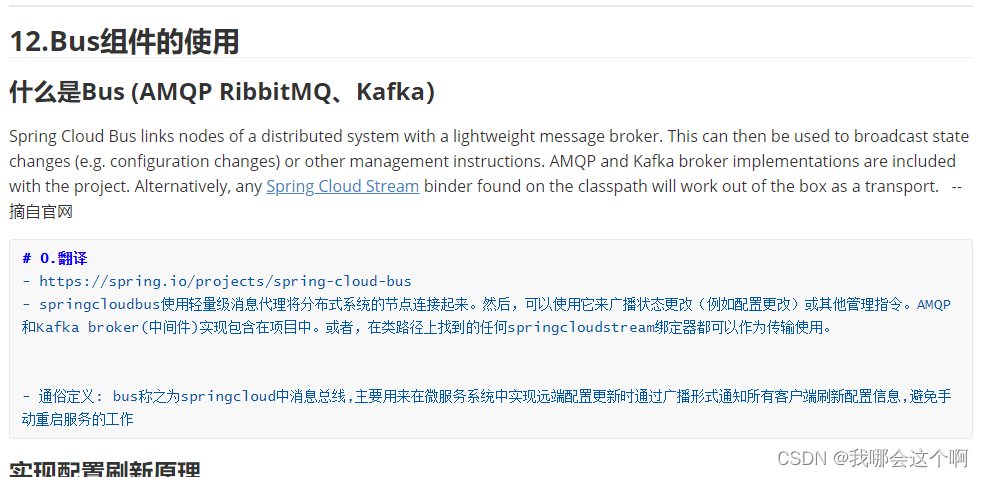
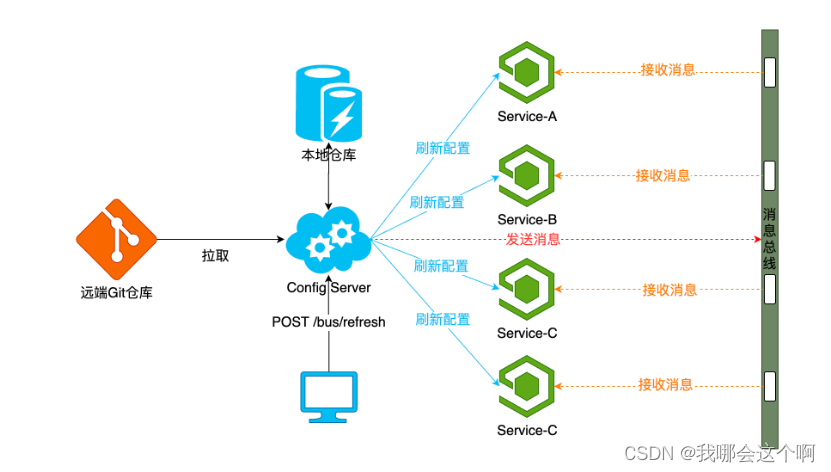

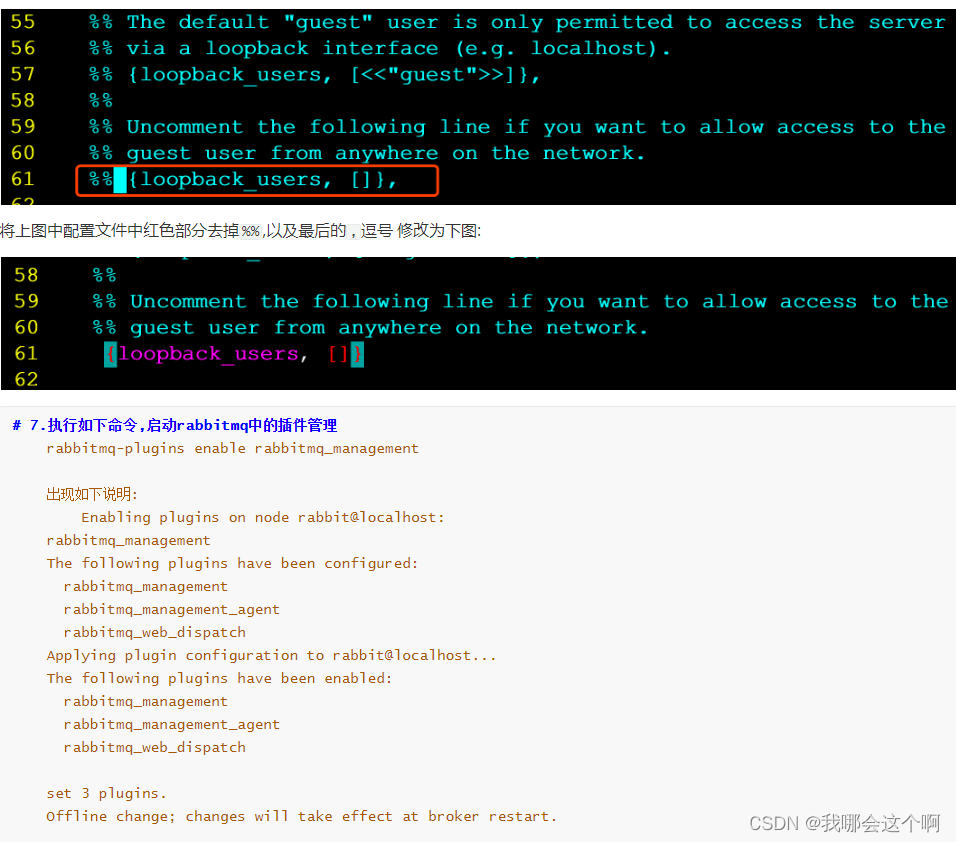


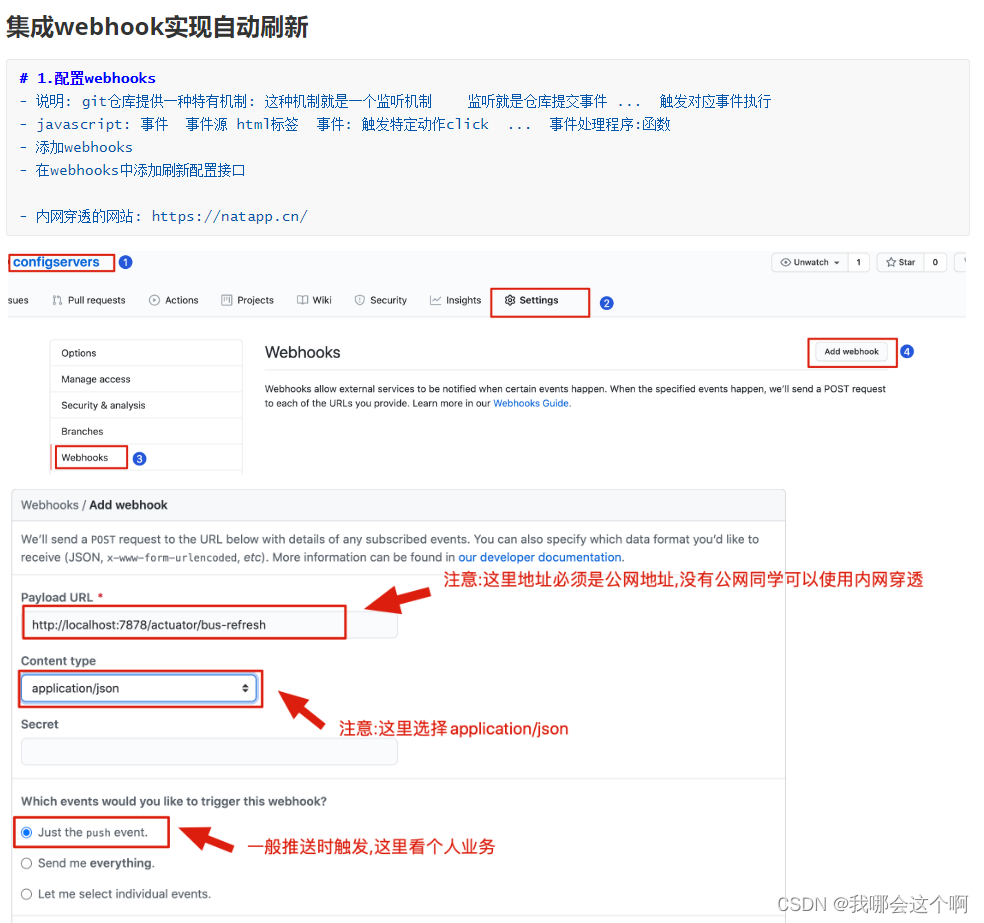
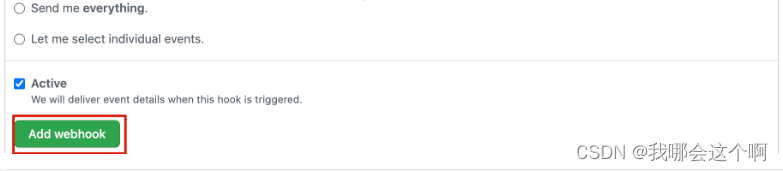
2.解决400错误问题
- 在配置中心服务端加入过滤器进行解决(springcloud中一个坑)
@Component
public class UrlFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
HttpServletRequest httpServletRequest = (HttpServletRequest)request;
HttpServletResponse httpServletResponse = (HttpServletResponse)response;
String url = new String(httpServletRequest.getRequestURI());
//只过滤/actuator/bus-refresh请求
if (!url.endsWith("/bus-refresh")) {
chain.doFilter(request, response);
return;
}
//获取原始的body
String body = readAsChars(httpServletRequest);
System.out.println("original body: "+ body);
//使用HttpServletRequest包装原始请求达到修改post请求中body内容的目的
CustometRequestWrapper requestWrapper = new CustometRequestWrapper(httpServletRequest);
chain.doFilter(requestWrapper, response);
}
@Override
public void destroy() {
}
private class CustometRequestWrapper extends HttpServletRequestWrapper {
public CustometRequestWrapper(HttpServletRequest request) {
super(request);
}
@Override
public ServletInputStream getInputStream() throws IOException {
byte[] bytes = new byte[0];
ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(bytes);
return new ServletInputStream() {
@Override
public boolean isFinished() {
return byteArrayInputStream.read() == -1 ? true:false;
}
@Override
public boolean isReady() {
return false;
}
@Override
public void setReadListener(ReadListener readListener) {
}
@Override
public int read() throws IOException {
return byteArrayInputStream.read();
}
};
}
}
public static String readAsChars(HttpServletRequest request)
{
BufferedReader br = null;
StringBuilder sb = new StringBuilder("");
try
{
br = request.getReader();
String str;
while ((str = br.readLine()) != null)
{
sb.append(str);
}
br.close();
}
catch (IOException e)
{
e.printStackTrace();
}
finally
{
if (null != br)
{
try
{
br.close();
}
catch (IOException e)
{
e.printStackTrace();
}
}
}
return sb.toString();
}
}