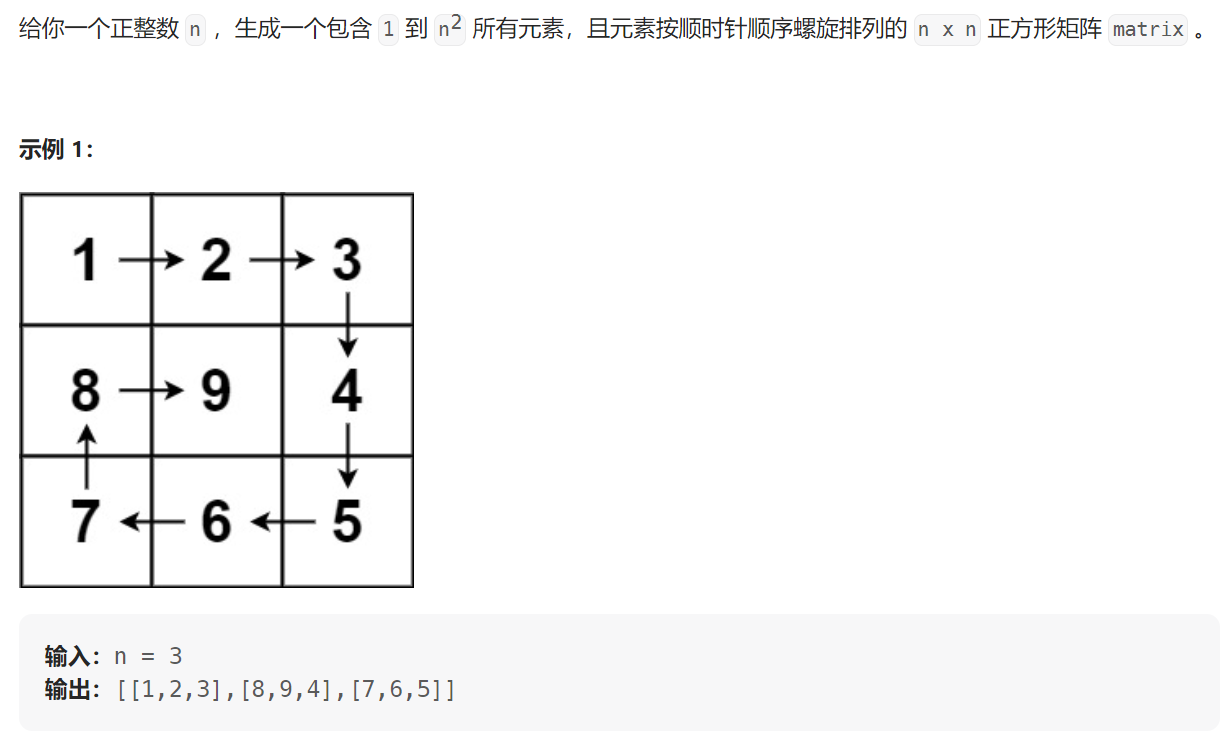
来源:投稿 作者:xin
编辑:学姐

Motivation
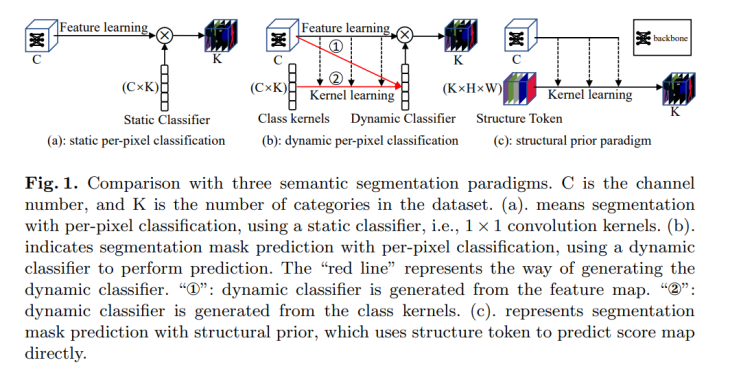
本文将当前语义分割的方法分为两类,一类是静态逐像素分类方法(static per-pixel classification),另一类为动态逐像素分类方法(dynamic per-pixel classification)。目前基于静态逐像素分类的方法,仅通过探索像素表示的信息融合,扩大每个像素的接受域,使尾部的卷积网络可以更精细的逐像素分类,生成更精细的得分图。然而这类工作侧重于提高逐像素的表示能力,并没有考虑图像中的结构信息。基于动态分类的方法虽然可以通过分类器与特征映射的交互更新可学习标记,提升模型性能。虽然此类方法分类器是动态的,但它仍然作用于每个像素,逐像素分类的性质不会改变,依旧破坏了图像中的结构信息。故本文跳出原有的语义分割框架,从更拟人化的角度考虑语义分割任务。提出了带有结构先验的StructToken。与静态逐像素分类和动态逐像素分类方法不同的是,本文的方法根据结构先验为每个类生成一个粗略的掩码,然后再逐步细化该掩码。(图1展示了三种语义分割方式)
Method

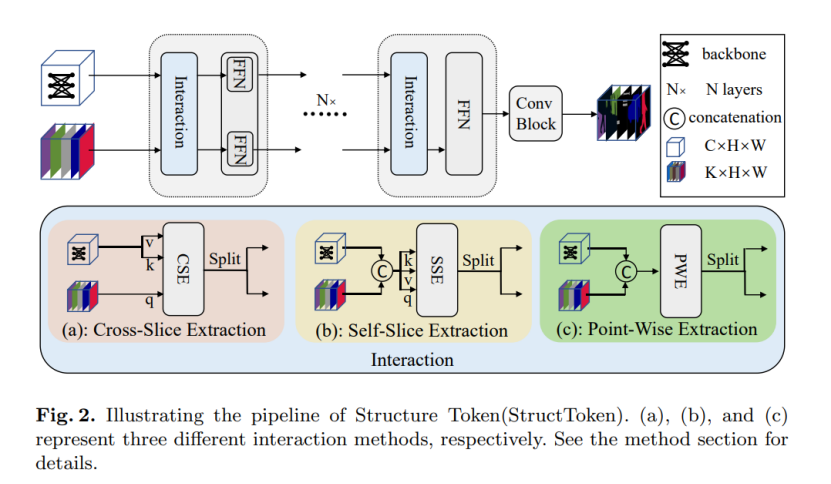
下面介绍本文提出的三种Interaction方法。
Cross-Slice Extraction: 本方法是自注意力的一种拓展,将backbone提取的特征F映射为v、k,将可学习结构Token S映射为q。通过交叉注意力机制学习新的结构化Token 。计算公式如下:
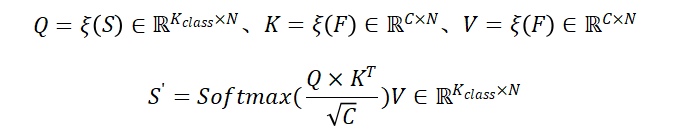

Self-Slice Extraction:本方法与Cross-Slice Extraction类似,只不过先将特征与结构Token S在通道维度上进行拼接,然后采用自注意力机制学习新的结构化Token 。
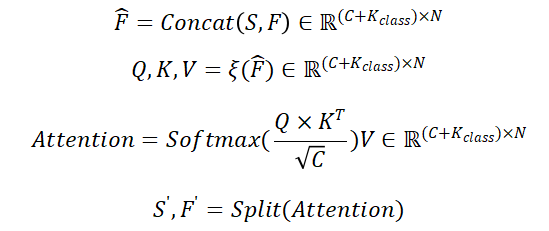


Result:
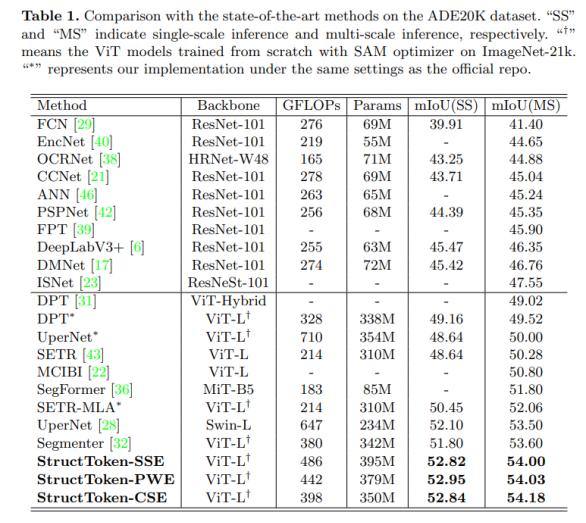
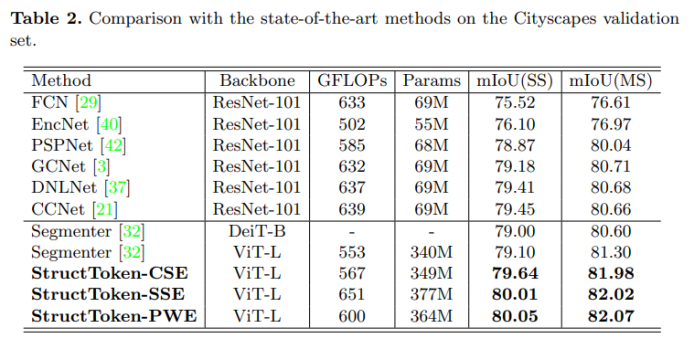
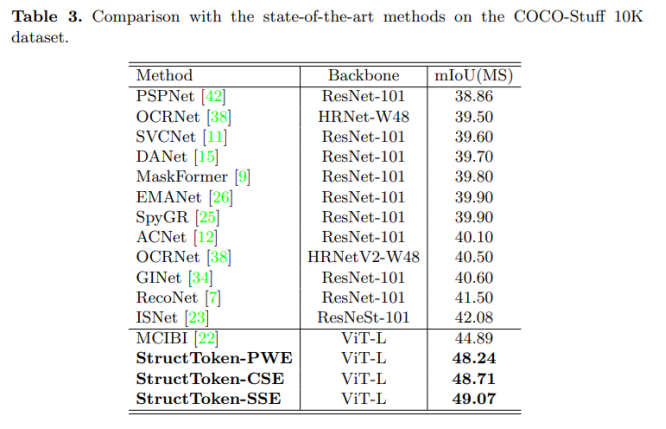
表1、表2、表3展示了提出模型在3个数据集上的结果,可以看出,在3个数据集上都达到了SOTA的结果。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“500”获取AI必读高分论文合集
(包含语义分割等多个细分方向)
码字不易,欢迎大家点赞评论收藏!