MySQL笔记2
- 一、CRUD操作
- 1.修改数据:update
- 2.删除数据:delete
- 二、数据库中表的约束
- 1.非空约束 not null
- 2.唯一性约束 unique
- 3.主键约束 primary key
- 4.外键约束
- 三、索引
- 1**什么是索引**?
- 2**MySQL中最经典的两种存储引擎**
- 3**为何需要索引**?
- 案例
- 4设置索引
- @不普通的索引有哪些?
- 5查看、删除索引
- 6索引背后的数据结构
- B-树
- B-树的特点
- 聚簇索引和非聚簇索引
- B+树
- 四、事务
- 1.什么是事务
- 2.事务的四大特性
- ps.并发与并行
- 问题
- 事务的三个操作
- 3.MySQL事务的四种隔离级别
- 级别
- 举例
- 演示
一、CRUD操作
MySQL数据库中包含四种操作:
Create(增) Retrieve(检索) Update(修改) Delete(删除)
1.修改数据:update
这也是一行一行的更新的
update 表名 set 字段1=1,字段2=值2... where 条件;
注意:没有条件整张表数据全部更新。
select * from t_xueke;
alter table t_xueke add 学科类型 varchar(255);
select * from t_xueke;
+-----+---------+----------+
| xno | subject | 学科类型 |
+-----+---------+----------+
| 1 | 数学 | NULL |
| 2 | 英语 | NULL |
| 3 | 语文 | NULL |
| 4 | 武术 | NULL |
| 5 | 唱歌 | NULL |
| 6 | 舞蹈 | NULL |
| 7 | 篮球 | NULL |
| 8 | NULL | NULL |
+-----+---------+----------+
将科目为数学英语语文的学科类型修改为默认
不管等于号(=)后面跟的是英文或是中文,都必须加单引号
update t_xueke set 学科类型='默认' where subject in('语文', '数学', '英语');
select * from t_xueke;
+-----+---------+----------+
| xno | subject | 学科类型 |
+-----+---------+----------+
| 1 | 数学 | 默认 |
| 2 | 英语 | 默认 |
| 3 | 语文 | 默认 |
| 4 | 武术 | NULL |
| 5 | 唱歌 | NULL |
| 6 | 舞蹈 | NULL |
| 7 | 篮球 | NULL |
| 8 | NULL | NULL |
+-----+---------+----------+
更新所有记录
create table xueke (select * from t_xueke);
select * from xueke;
+-----+---------+----------+
| xno | subject | 学科类型 |
+-----+---------+----------+
| 1 | 数学 | 默认 |
| 2 | 英语 | 默认 |
| 3 | 语文 | 默认 |
| 4 | 武术 | NULL |
| 5 | 唱歌 | NULL |
| 6 | 舞蹈 | NULL |
| 7 | 篮球 | NULL |
| 8 | NULL | NULL |
+-----+---------+----------+
update xueke set subject = 'x', 学科类型='y';
select * from xueke;
+-----+---------+----------+
| xno | subject | 学科类型 |
+-----+---------+----------+
| 1 | x | y |
| 2 | x | y |
| 3 | x | y |
| 4 | x | y |
| 5 | x | y |
| 6 | x | y |
| 7 | x | y |
| 8 | x | y |
+-----+---------+----------+
2.删除数据:delete
这是一行一行的删除的
delete from 表名 where 条件;
注意:没有条件时全部删除。
drop table xueke;
create table xueke (select * from t_xueke);
+-----+---------+----------+
| xno | subject | 学科类型 |
+-----+---------+----------+
| 1 | 数学 | 默认 |
| 2 | 英语 | 默认 |
| 3 | 语文 | 默认 |
| 4 | 武术 | NULL |
| 5 | 唱歌 | NULL |
| 6 | 舞蹈 | NULL |
| 7 | 篮球 | NULL |
| 8 | NULL | NULL |
+-----+---------+----------+
删除数学学科数据?
delete from xueke where subject='数学';
+-----+---------+----------+
| xno | subject | 学科类型 |
+-----+---------+----------+
| 2 | 英语 | 默认 |
| 3 | 语文 | 默认 |
| 4 | 武术 | NULL |
| 5 | 唱歌 | NULL |
| 6 | 舞蹈 | NULL |
| 7 | 篮球 | NULL |
| 8 | NULL | NULL |
+-----+---------+----------+
删除所有数据?
delete from xueke;
Empty set (0.00 sec)
怎么删除大表中的数据?(重点)
truncate table 表名;
// 表被截断,不可回滚。永久丢失。
create table xueke2(select * from t_xueke);
truncate table xueke2;
mysql> show tables;
+-----------------+
| Tables_in_study |
+-----------------+
| t_indentity |
| t_student |
| t_xueke |
| xueke |
| xueke2 |
+-----------------+
5 rows in set (0.01 sec)
mysql> select * from xueke2;
Empty set (0.00 sec)
删除表?
drop table 表名; // 这个通用。
drop table if exists 表名; // oracle不支持这种写法。
二、数据库中表的约束
在
创建表的时候,可以给表的字段添加相应的约束,添加约束的目的是为了保证表中数据的
合法性、有效性、完整性。
常见的约束有哪些呢?
非空约束(
not null):约束的字段不能为NULL唯一约束(
unique):约束的字段不能重复主键约束(
primary key):约束的字段既不能为NULL,也不能重复(简称PK)外键约束(
foreign key):…(简称FK)检查约束(
check):注意Oracle数据库有check约束,但是mysql没有,目前mysql不支持该约束。
1.非空约束 not null
drop table if exists t_user;
create table t_user(
id int,
username varchar(255) not null,
password varchar(255)
);
insert into t_user(id,password) values(1,'123');
ERROR 1364 (HY000): Field 'username' doesn't have a default value
insert into t_user(id,username,password) values(1,'lisi','123');
2.唯一性约束 unique
唯一约束修饰的字段具有唯一性,不能重复。但可以为NULL。
也就是说可以不设置这个字段的值,默认值为NULL,
此时不会认为是重复数据,都是空而已
(1)给某一列增加unique约束
drop table if exists t_user;
create table t_user(
id int,
username varchar(255) unique
);
insert into t_user values(1,'zhangsan');
insert into t_user values(2,'zhangsan');
ERROR 1062 (23000): Duplicate entry 'zhangsan' for key 'username'
insert into t_user(id)
values
(2),(3),(4);
select * from t_user;
+------+----------+
| id | username |
+------+----------+
| 1 | zhangsan |
| 2 | NULL |
| 3 | NULL |
| 4 | NULL |
+------+----------+
(2)给两个列或多个列增加unique约束
drop table if exists t_user;
create table t_user(
id int,
usercode varchar(255),
username varchar(255),
unique(usercode,username)
);
insert into t_user values(1,'111','zs');
insert into t_user values(2,'111','ls');
insert into t_user values(3,'222','zs');
select * from t_user;
+------+----------+----------+
| id | usercode | username |
+------+----------+----------+
| 1 | 111 | zs |
| 2 | 111 | ls |
| 3 | 222 | zs |
+------+----------+----------+
insert into t_user values(4,'111','zs');
ERROR 1062 (23000): Duplicate entry '111-zs' for key 'usercode'
-- 列级约束:包含在列定义中,直接跟在该列的其它定义之后 ,用空格分隔,不必指定列名
-- 表级约束:与列定义相互独立,不包含在列定义中;与定义用‘,’分隔;必须指出要约束的列的名称
注意:只有主键、外键、唯一、检查 四种约束可以定义表级约束
列级约束:只能应用于一列上。
表级约束:可以应用于一列上,也可以应用在一个表中的多个列上。
即:如果你创建的约束涉及到该表的多个属性列,则必须创建的是表级约束(必须定义在表级上);
否则既可以定义在列级上也可以定义在表级上此时只是SQL语句格式不同而已
3.主键约束 primary key
主键的特点:不能为NULL,也不能重复。
主键相关的术语 主键约束 : primary key 主键字段 : id字段添加primary key之后,id叫做主键字段 主键值 : id字段中的每一个值都是主键值。主键有什么作用?
表的设计
三范式中有要求,第一范式就要求任何一张表都应该有主键。
主键的作用:主键值是这行记录在这张表当中的唯一标识。(就像一个人的身份证号码一样。)
主键的分类?
1.根据主键字段的字段数量来划分:
单一主键(推荐的,常用的。)
复合主键(多个字段联合起来添加一个主键约束)(复合主键不建议使用,因为复合主键违背三范式。)
2.根据主键性质来划分:
自然主键:主键值最好就是一个和业务没有任何关系的自然数。(这种方式是推荐的)
业务主键:主键值和系统的业务挂钩,例如:拿着银行卡的卡号做主键,拿着身份证号码作为主键。(不推荐用)
最好不要拿着和业务挂钩的字段作为主键。因为以后的业务一旦发生改变的时候,主键值可能也需要随着发生变化,但有的时候没有办法变化,因为变化可能会导致主键值重复。一张表的主键约束只能有1个。
使用
表级约束方式定义主键:```sql drop table if exists t_user; create table t_user( id int, username varchar(255), primary key(id) ); insert into t_user(id,username) values(1,'zs'); insert into t_user(id,username) values(2,'ls'); insert into t_user(id,username) values(3,'ws'); insert into t_user(id,username) values(4,'cs'); select * from t_user; +----+----------+ | id | username | +----+----------+ | 1 | zs | | 2 | ls | | 3 | ws | | 4 | cs | +----+----------+ insert into t_user(id,username) values(4,'cx'); ERROR 1062 (23000): Duplicate entry '4' for key 'PRIMARY' ```
mysql提供主键值自增:(非常重要。)
drop table if exists t_user;
create table t_user(
id int primary key auto_increment, // id字段自动维护一个自增的数字,从1开始,以1递增。
username varchar(255)
);
4.外键约束
关于外键约束的相关术语:
外键约束:
foreign key 外键字段:添加有外键约束的字段
外键值:外键字段中的每一个值。
业务背景:
请设计数据库表,用来维护学生和班级的信息?
第一种方案:一张表存储所有数据
no(pk) name classno classname
-------------------------------------------------------------------------------------------
1 zs1 101 北京大兴区经济技术开发区亦庄二中高三1班
2 zs2 101 北京大兴区经济技术开发区亦庄二中高三1班
3 zs3 102 北京大兴区经济技术开发区亦庄二中高三2班
4 zs4 102 北京大兴区经济技术开发区亦庄二中高三2班
5 zs5 102 北京大兴区经济技术开发区亦庄二中高三2班
缺点:冗余。【不推荐】
第二种方案:两张表(班级表和学生表)
t_class 班级表
cno(pk) cname
--------------------------------------------------------
101 北京大兴区经济技术开发区亦庄二中高三1班
102 北京大兴区经济技术开发区亦庄二中高三2班
t_student 学生表
sno(pk) sname classno(该字段添加外键约束fk)
------------------------------------------------------------
1 zs1 101
2 zs2 101
3 zs3 102
4 zs4 102
5 zs5 102
t_student中的
classno字段引用t_class表中的cno字段此时t_student表叫做子表。t_class表叫做父表。
顺序要求:
删除数据的时候,先删除子表,再删除父表。
添加数据的时候,先添加父表,在添加子表。
创建表的时候,先创建父表,再创建子表。
删除表的时候,先删除子表,在删除父表。
建表:
drop table if exists t_student;
drop table if exists t_class;
create table t_class(
cno int,
cname varchar(255),
primary key(cno)
);
create table t_student(
sno int,
sname varchar(255),
classno int,
primary key(sno),
foreign key(classno) references t_class(cno)
);
insert into t_class values(101,‘xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx’);
insert into t_class values(102,‘yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy’);
insert into t_student values(1,‘zs1’,101);
insert into t_student values(2,‘zs2’,101);
insert into t_student values(3,‘zs3’,102);
insert into t_student values(4,‘zs4’,102);
insert into t_student values(5,‘zs5’,102);
insert into t_student values(6,‘zs6’,102);
select * from t_class;
+-----+-----------------------------------------------+
| cno | cname |
+-----+-----------------------------------------------+
| 101 | xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx |
| 102 | yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy |
+-----+-----------------------------------------------+
select * from t_student;
+-----+-------+---------+
| sno | sname | classno |
+-----+-------+---------+
| 1 | zs1 | 101 |
| 2 | zs2 | 101 |
| 3 | zs3 | 102 |
| 4 | zs4 | 102 |
| 5 | zs5 | 102 |
| 6 | zs6 | 102 |
+-----+-------+---------+
insert into t_student values(7,'lisi',103);
ERROR 1452 (23000): Cannot add or update a child row: a foreign key constraint fails (`study`.`t_student`, CONSTRAINT `t_student_ibfk_1` FOREIGN KEY (`classno`) REFERENCES `t_class` (`cno`))
ps:
1.外键值可以为NULL吗?外键值可以为NULL。
2.外键字段引用其他表的某个字段的时候,被引用的字段必须是主键吗?
注意:被引用的字段不一定是主键,但至少具有unique约束。
三、索引
1什么是索引?
MySQL中的索引和事务(比较复杂的场景和比较庞大的数据量),面试必考,现阶段还没有合适场景去体会用法。
=>背诵
索引是一种特殊的文件,包含数据库中所有记录的引用,类似于数组的引用下标,通过这个下标就能拿到数组中的数据。
和数组中下标一样,通过下标寻找数组数据很快捷、准确
通过索引去查找数据库中的数据也是很快的~~
MySQL数据库采用插件式设计,每种索引在不同的存储引擎中的实现都有可能不同。
-- 存储引擎:就是MySQL到底如何对数据进行增删查改的不同实现方案 ~~
例:同一种汽车品牌可能有多种车型。
汽车品牌相当于MySQL、多种车型就相当于存储引擎
2MySQL中最经典的两种存储引擎
MyISAM:MySQL5.5之前的默认存储引擎,不支持事务
InnoDB:MySQL5.5之后的存储引擎,支持事务,性能不如MyISAM
接下来关于索引和事务的实现都是基于InnoDB引擎
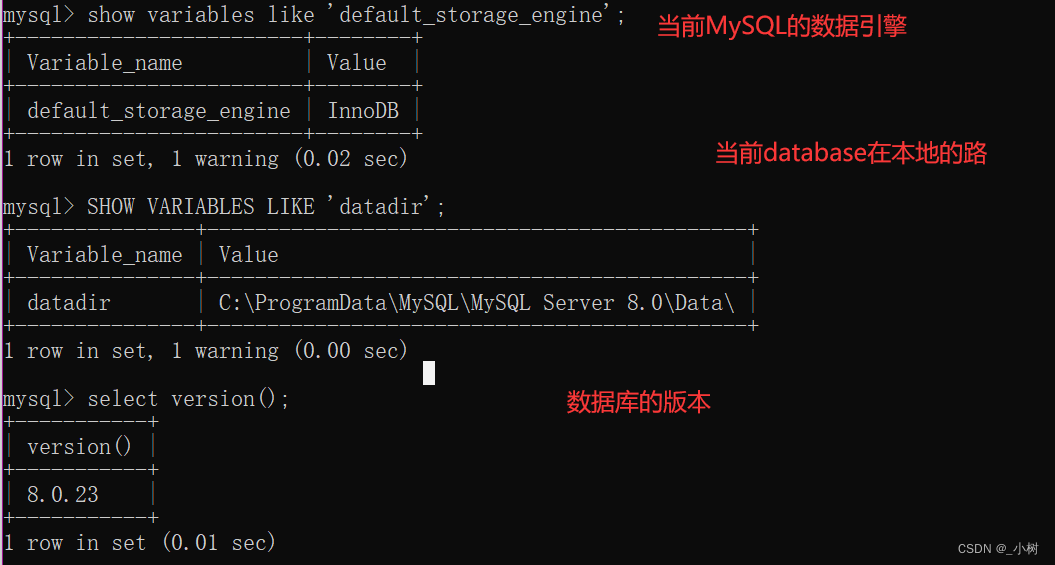
查询当前存储引擎
show variables like 'default_storage_engine';
+------------------------+--------+
| Variable_name | Value |
+------------------------+--------+
| default_storage_engine | InnoDB |
+------------------------+--------+
1 row in set, 1 warning (0.02 sec)
3为何需要索引?
(
查多改少的情况)引入索引是为了提高查询数据的效率,但是会拖慢增、删、改的效率
创建索引也需要时间和空间的开销
-- 例:索引和原数据表的关系,就相当于书的目录和书本内容之间的关系
-- 根据书本的目录去查找特定章节的特定内容,远比你拿一本书瞎翻快得多~ ~
涉及到书本内容的修改,现在还需要改目录
案例
1.创建一个表test_user,存放着800w条用户信息
-- 创建用户表
DROP TABLE IF EXISTS test_user;
CREATE TABLE test_user (
id_number INT,
name VARCHAR(20) comment '姓名',
age INT comment '年龄',
create_time timestamp comment '创建日期'
);
sql语句:(复制运行即可)
-- 构建一个8000000条记录的数据
-- 构建的海量表数据需要有差异性,所以使用存储过程来创建, 拷贝下面代码就可以了,暂时不用理解
-- 产生名字
set global log_bin_trust_function_creators=TRUE;
drop function if exists rand_name;
delimiter $$
create function rand_name(n INT, l INT)
returns varchar(255)
begin
declare return_str varchar(255) default '';
declare i int default 0;
while i < n do
if i=0 then
set return_str = rand_string(l);
else
set return_str =concat(return_str,concat(' ', rand_string(l)));
end if;
set i = i + 1;
end while;
return return_str;
end $$
delimiter ;
-- 产生随机字符串
drop function if exists rand_string;
delimiter $$
create function rand_string(n INT)
returns varchar(255)
begin
declare lower_str varchar(100) default
'abcdefghijklmnopqrstuvwxyz';
declare upper_str varchar(100) default
'ABCDEFJHIJKLMNOPQRSTUVWXYZ';
declare return_str varchar(255) default '';
declare i int default 0;
declare tmp int default 5+rand_num(n);
while i < tmp do
if i=0 then
set return_str =concat(return_str,substring(upper_str,floor(1+rand()*26),1));
else
set return_str =concat(return_str,substring(lower_str,floor(1+rand()*26),1));
end if;
set i = i + 1;
end while;
return return_str;
end $$
delimiter ;
-- 产生随机数字
drop function if exists rand_num;
delimiter $$
create function rand_num(n int)
returns int(5)
begin
declare i int default 0;
set i = floor(rand()*n);
return i;
end $$
delimiter ;
-- 向用户表批量添加数据
drop procedure if exists insert_user;
delimiter $$
create procedure insert_user(in start int(10),in max_num int(10))
begin
declare i int default 0;
set autocommit = 0;
repeat
set i = i + 1;
insert into test_user values ((start+i) ,rand_name(2, 5),rand_num(120),CURRENT_TIMESTAMP);
until i = max_num
end repeat;
commit;
end $$
delimiter ;
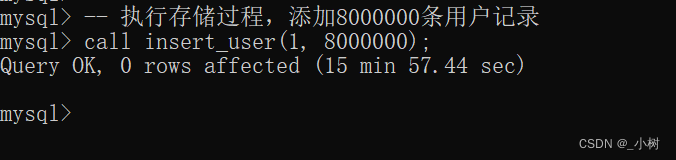
-- 执行存储过程,添加8000000条用户记录
call insert_user(1, 8000000);
800万条数据,足足运行15min O。o ?
2.查询某个人基本信息,id_number = 556677
desc test_user;
+-------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------------+-------------+------+-----+---------+-------+
| id_number | int | YES | | NULL | |
| name | varchar(20) | YES | | NULL | |
| age | int | YES | | NULL | |
| create_time | timestamp | YES | | NULL | |
+-------------+-------------+------+-----+---------+-------+
Key这一列没有东西,说明没有设置索引
千万不能select * from test_user;!!!800w条数据,电脑要炸
select name,age from test_user where id_number = 556677;
-- 全表扫描,在800w条记录上查询id_number为556677的信息
-- 一行行扫描,直到找到id = 556677的为止
+-----------------+------+
| name | age |
+-----------------+------+
| Qpala Ejiovjjri | 75 |
+-----------------+------+
1 row in set (4.11 sec)
因为数据量庞大,花了4s才找到这条数据
3.分析
explain sql语句;
MySQL的引擎会分析这个sql语句可能会用到的索引等信息,包括扫描的行数等等
explain select name,age from test_user where id_number = 556677;

Key这一列为NULL,说明就是id_number属性没有设置索引
rows这一列显示为7789744,说明可能扫描的行数为700多w条
4设置索引
应该为经常查询的属性设置索引
(查多改少的情况,提高查找效率)
创建索引需要时间和空间的开销
1.创建索引的语句
对于非主键、非唯一约束、非外键的字段,可以创建普通索引
create index 索引名称 on 表名(属性名);
2.在test_user表中为id_number属性创建索引 id_inx
create index id_idx on test_user(id_number);

创建一个索引就花时间12.9s,索引创建是需要时间的
3.创建索引之后,再查询,看看能快多少
select name,age from test_user where id_number = 556677;
+-----------------+------+
| name | age |
+-----------------+------+
| Qpala Ejiovjjri | 75 |
+-----------------+------+
1 row in set (0.00 sec)
假如每个查询优化4s
假设一个中等规模的网站日活10w,每个用户每天的平均查询操作10次
每天查询100w次,每个查询优化4s
一共优化:100w*4s = 400ws = 1111h = 46天
优化了这么多时间,真的相当恐怖!四十多天
这只是一个普通的索引优化
4.explain 再分析一下
explain select name,age from test_user where id_number = 556677;

发现,在很少的常数时间内就可以查询到数据
而且可能扫描的行数也只有一行
@不普通的索引有哪些?
主键约束 => 主键索引
外键约束 => 外键索引
唯一约束 => 唯一键索引
他们三个都是索引
5查看、删除索引
show index from 表名;
查看这个表中有哪些索引
索引的数据结构是BTREE
即B+树
drop index 索引名称 on 表名;
从表中删除指定索引
6索引背后的数据结构
我们都知道,高效查找数据的数据结构有:
BST二分搜索树 => RBTree,查找的时间复杂度为logN。当数据量非常大时,由于二叉树每个节点最多有两个子树,RBTree的高度很高,数据库的数据都在磁盘上存储,每当访问一个二叉树的节点都得读写一次磁盘,这样就非常慢。
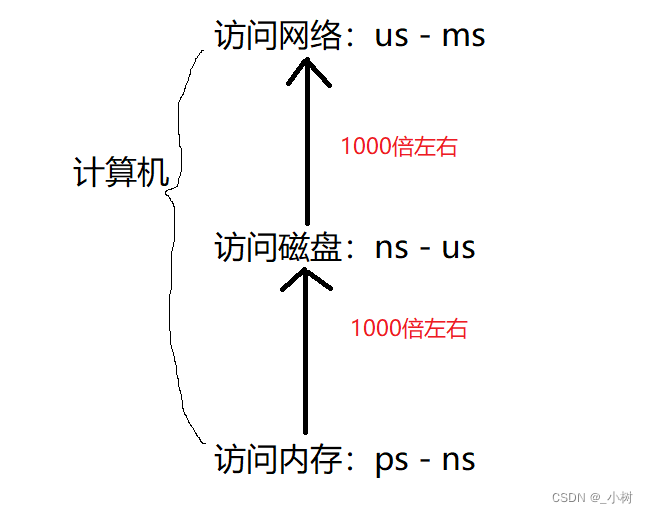
(磁盘)普通机械硬盘的读写速度大约几百M/s
内存的读写速度大约是几百G/s
而CPU的运行速度大概又是内存的1000倍
当一个程序有大量的磁盘读写操作,文件IO,这个程序效率是非常低的。
如果使用磁盘进行存储,会导致CPU一直在等待磁盘的读写,导致效率很低。
哈希表:理论上O(1)找到数据,常数时间。但是哈希表无法处理范围查询操作
哈希表是查找数据是否等于指定数据,区间查找他就不行了~~
between I and r
B-树
因此在MySQL的索引上基于B+树的设计(N叉搜索树)
引入N叉搜索树后可以大大降低树的高度(相较于BST来说)
首先了解B-树
B-树,又叫N叉搜索树,即
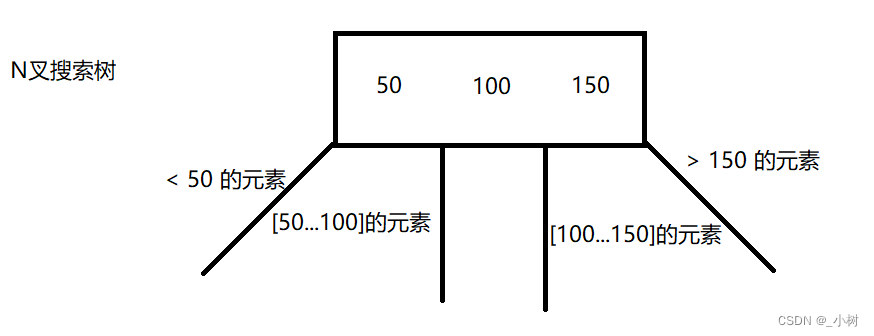
B-树的特点
1.每个树节点上都有多个值
2.每个节点上的(分叉树)子树的个数就是当前节点值的个数 + 1
当前树的节点有3个值,就有4个分叉,即4个子树
3.保证子树中的节点值一定要处在父节点的范围之内
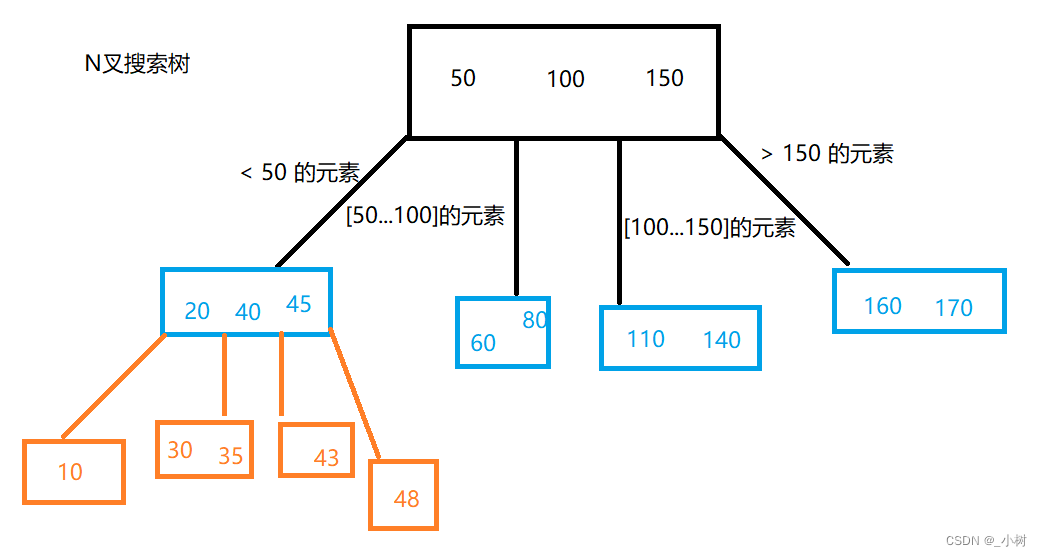
查询48:先查询在<50,[50,100],[100,150],>150的哪个范围内,发现在<50范围内,继续向下找,发现又在>45范围内,找到了~ ~
其实B-树中的每个值其实是一个复合值
以学生表(id, name, class_id)为例
以id创建索引id_idx
假如在某个节点中保存了某个学生的id_idx = 100,那么这个节点不止存储了这一个数据,同时也会存储他的name和class_id(晓明,3)
聚簇索引和非聚簇索引
聚簇索引(主键索引,一个表只有一个聚簇索引):
构建聚簇索引树上的每个节点时,需要保存索引列的信息,还需要保存这条记录的完整内容。
非聚簇索引(普通索引,唯一索引,index创建的都是非聚簇索引,一张表中可以有多个非聚簇索引):
构建非聚簇索引树上的每个节点时,除了保存索引列的信息之外,还需要保存该记录的行号(对应的主键id)。
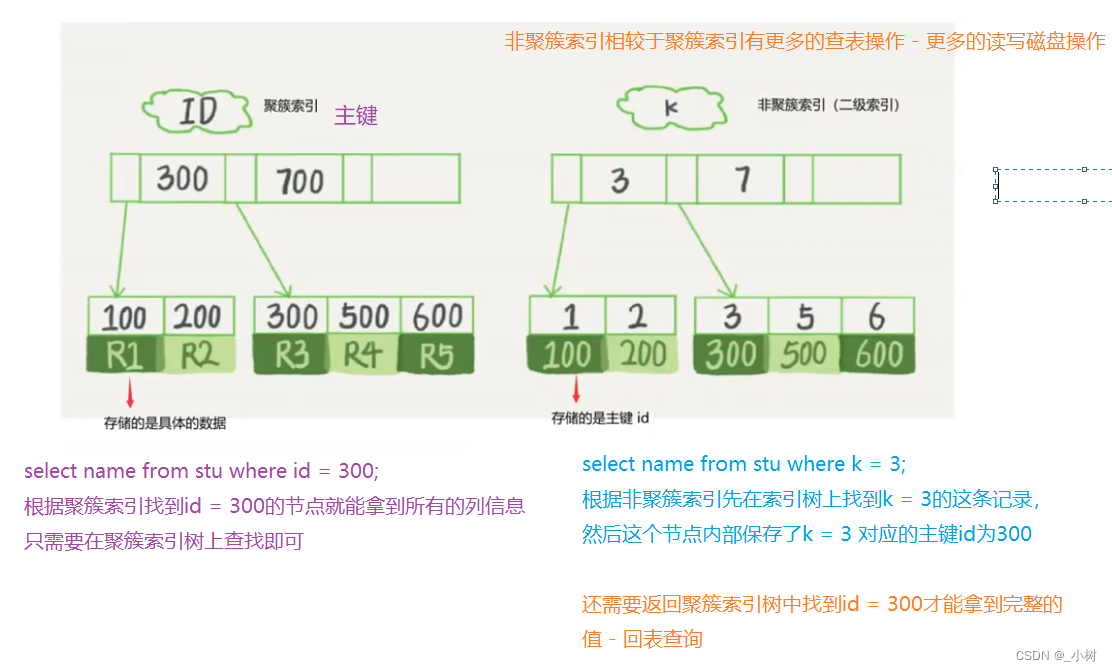
聚簇索引:查询速度快,一个表只有一个聚簇索引,保存的信息多,占用空间大;
非聚簇索引:查询速度慢,只能找到主键信息,需要回表查询,一个表可以有多个非聚簇索引,保存的信息少,占用空间小。
B+树
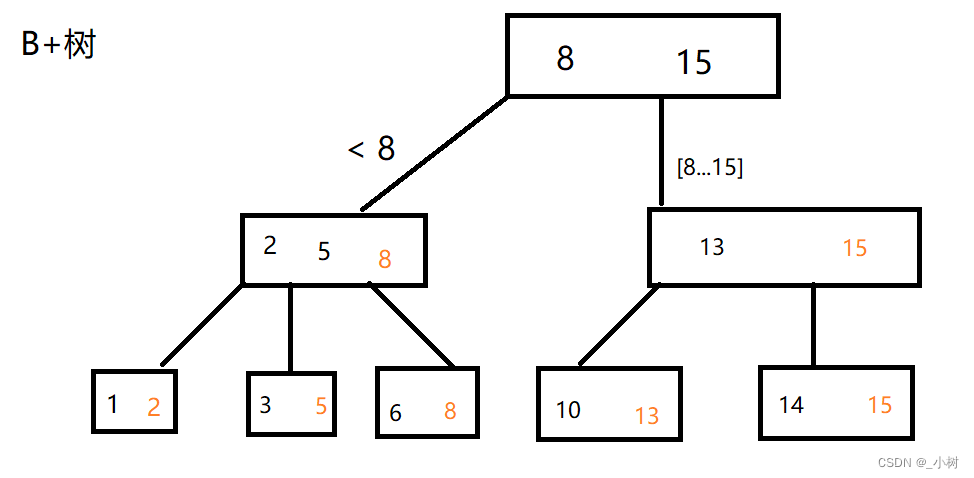
B+树和B-树最大的区别就是:
每个子节点的最大值都是当前父节点的值。
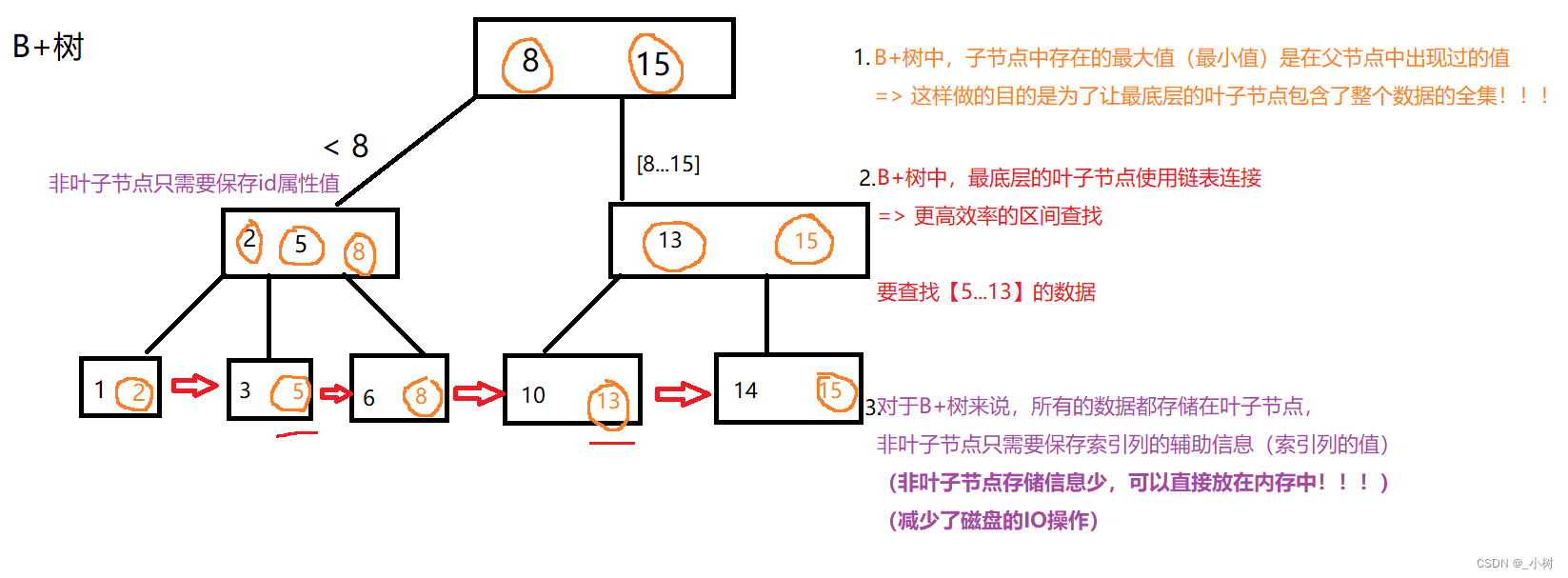
为什么右边没有数据和节点呢?
其实B-树家族是严格平衡树,左右子树的高度差为0,左树和右树的高度完全相等。
怎么考?数据库索引的底层数据结构?
请给我纸和笔,我来作图B+树的结构
四、事务
1.什么是事务
一个事务是一个完整的业务逻辑单元,不可再分。
事务的应用场景 - 银行转账的场景,从A账户向B账户转账1w,至少需要执行两条语句:
update t_act set balance = balance - 10000 where actno = 'A';
update t_act set balance = balabce + 10000 where actno = 'B';
-- 如果在实际生活中,A账户扣款成功但是B账户没有收到钱,则是灾难性的错误!!
-- 因此,这两条语句必须同时成功或者同时失败,不允许一条成功、一条失败。
-- 想要保证这样的效果,就需要数据库的事务机制。
所谓的事务:把若干个SQL操作打包为一个整体,实际执行的时候,这个整体要么全部执行,要么都不执行。
若执行的过程中出现了突发情况,某些操作执行不下去了,MySQL可以保证突发情况恢复之后,数据没有遭受破坏。
=> 通过事务的“回滚” - roll back操作进行数据的还原~~(MySQL中的binlog文件实现,记录了所有表数据的修改动作)
2.事务的四大特性
事务的ACID(原子性、持久性、隔离性、一致性)特性
原子性:(事务中最核心的操作)
一个事务中的所有操作,要么全部执行成功,要么全部执行失败。
(执行失败之后,数据的恢复就通过rollback回滚)
持久性:一个事务执行完成之后,这个事务对数据库的所有修改都是永久的(持久化,保存到磁盘上),不会丢失
一致性:一个事务执行前后的数据都是一种合法性的状态。
事务永远都是从一个一致性状态到另一个一致性状态。
在执行事务前后,数据库的数据都是合理的~~
假设执行更新操作之前,B账户余额1,A账户余额500w
没有事务,就有可能出现,B账户余额1,A账户余额499w => 不合理的状态
不管怎么操作,这两个账户余额总和应该是500w零一块,才是合理的
隔离性:多个并发事务访问数据库时,事务之间是相互隔离的,一个事务不应该被其他事务干扰,不同事务之间相互隔离。
普通SQL:
一个SQL语句执行的操作,MySQL自身可以保证数据并发时的正确性(通过读写锁)。事务:多个SQL语句执行的操作,并发执行就会存在相应的问题。
ps.并发与并行
-- 并发:多个任务不一定是在同时执行的,也不一定就是在不同的CPU上执行,单核处理器上的任务调度都属于并发执行。
在QQ中给鹏哥发个爱心的表情 - 任务1
给鹏哥把信息发出去了 a
鹏哥给我回了个信息“恋爱中” b
在微信中问我媳妇还需要干啥家务 - 任务2
我把信息发出去了 c
我媳妇给我回了个微信“把碗洗了,然后把地拖了,再把娃的衣服洗了,你就能去看书了” d
每一个任务有两个子任务,实际上执行顺序为acbd,但是用户却觉得这两个任务是同时发生的,其实在不同时间段执行了不同的任务。并发,即在某一时间段内同时进行,有先后顺序。
-- 并行:多个任务一定是在不同的CPU上同时执行
并行,即在同一时间同时发生。
问题
当鹏哥和铭哥同时操作同一个数据库和数据表可能引发的问题
(模拟多个并发事务访问数据库时,可能存在的问题)
问题1:脏读
事务A在修改数据,事务B读取到了事务A修改后的数据。接着事务A进行了“回滚”,此时事务A前面的修改不作数了~~
此时事务B读到的数据是修改后的数据,就是“脏”数据~~这种情况称为脏读。
问题二:不可重复读
同一个事务在多次相同查询后得到的数据不同。
在不同的查询时,其他事务的修改对于本事务来说是可见的。
-- 事务A: select name from stu; -- 其他操作 select name from stu; 结果不同了!
事务的三个操作
开启事务
start transaction;
-- 后面的多个sql语句是一个整体!!
START TRANSACTION 立即启动一个事务,而不管当前的提交模式设置如何。 无论当前的提交模式设置如何,以 START transaction 开始的事务必须通过发出显式 COMMIT 或 ROLLBACK 来结束。
回滚操作
rollback;
-- rollback回滚了上次对数据库的修改(即回滚了此次事务的所有操作)
提交事务
commit;
-- 把开启事务之后的所有sql语句统一在数据库上进行持久化(回滚也没用,不会撤销)
在commit之前,事务中所有的操作都是临时的。只有提交之后的事务,才把这些数据真正写入磁盘,对于其他事务也可见这个数据。
3.MySQL事务的四种隔离级别
级别
1.读未提交:处在该隔离界别的事务
可以看到其他还没提交的事务,对数据库数据的修改~~ RU(Read Uncommitted)脏读、不可重复读、环读都有可能出现
2.读已提交:处在该隔离级别的事务可以看到其他已经提交的事务,对数据库的修改~~ RC(Read Committed)
3.
可重复读:InnoDB引擎默认的隔离级别(Repeatable Read)一个事务一旦开启,在该隔离级别下,该事务提交之前,多次查询看到的结果是相同的~~
无论其他事务如何修改数据库,在当前这个事务下都是不可见的~~
4.串行化:(Serializable)事务最高隔离级别,所有事务都串行访问数据库,不会发生冲突,不会产生任何错误~~就没有并发了,并发度为0
举例

演示
演示一下在MySQL数据库中,可重复读这一隔离级别下的情况:
1.打开两个shell终端,开启两个事务
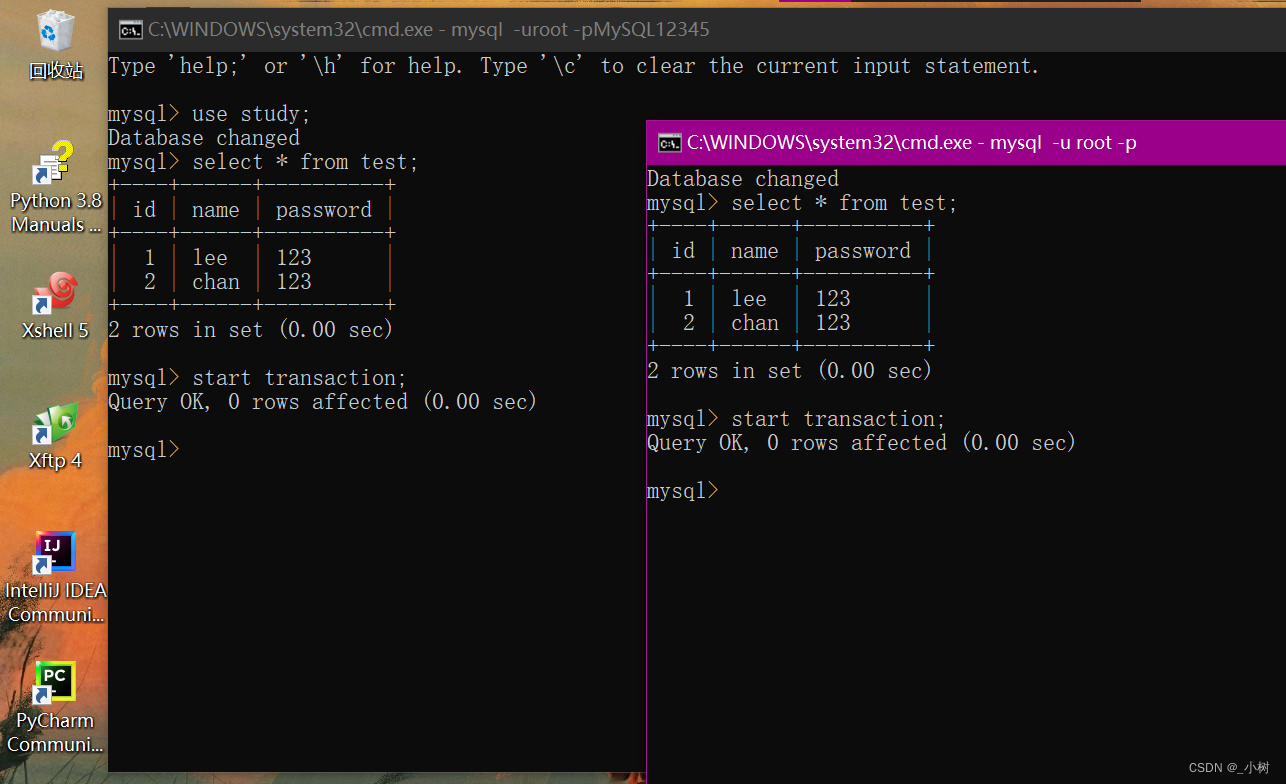
2.在左边的事务中执行插入语句,可以看到右边事务读到的还是之前的数据
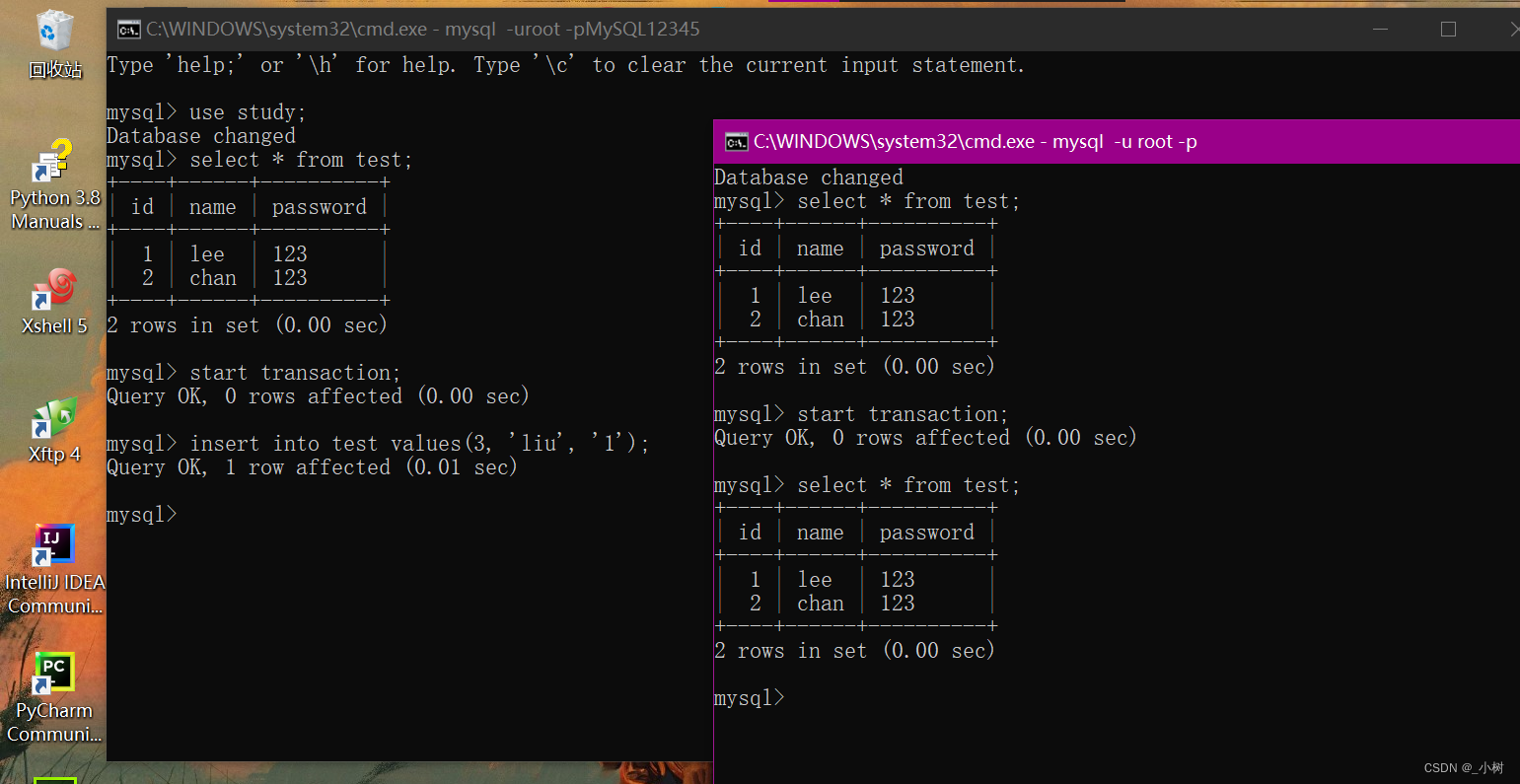
3.将左边的事务提交,右边的事务继续读test表,结果还是相同的
这就是MySQL5.5之后,支持事务的版本,使用InnoDB引擎的存储结构,默认的事务隔离级别
可重复读(Repeatable Read) RR只要本事务没有提交,查询的所有值保证都是相同的,和其他事务隔离,其他事务的修改对于本事务是不可见的~~
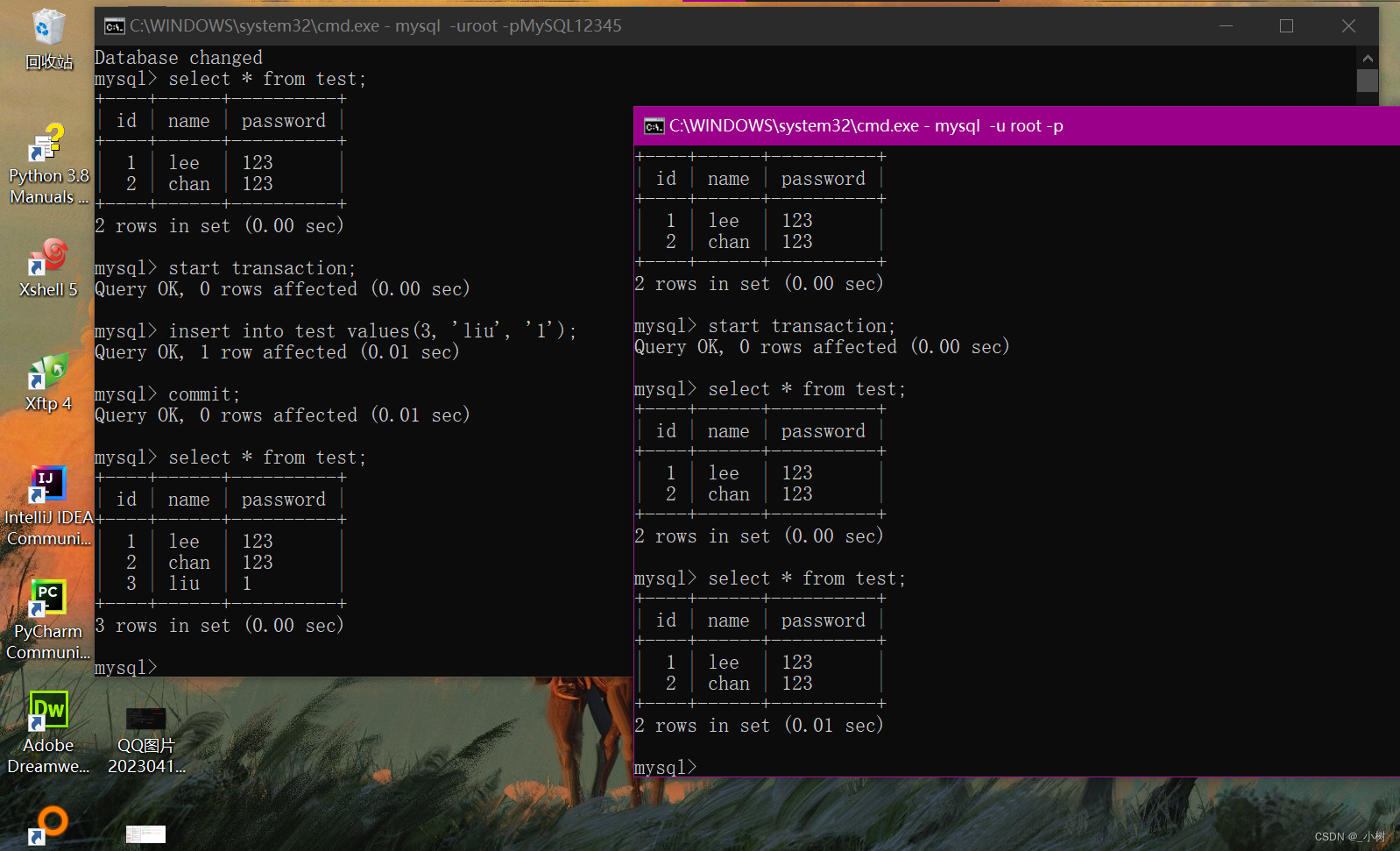
4.在左边的事务中插入id为3的行
ps:此时左边的事务(暂称为事务x),已经提交了,也就是在磁盘上永久进行持久化存储了。
但是,此时右边的事务(暂称为事务y)并没有提交,以事务y的视角,并不明白这一点。
那么可以在事务y中,继续添加id=3的数据吗?
当然不可以!因为在磁盘中已经实实在在的有那个数据了
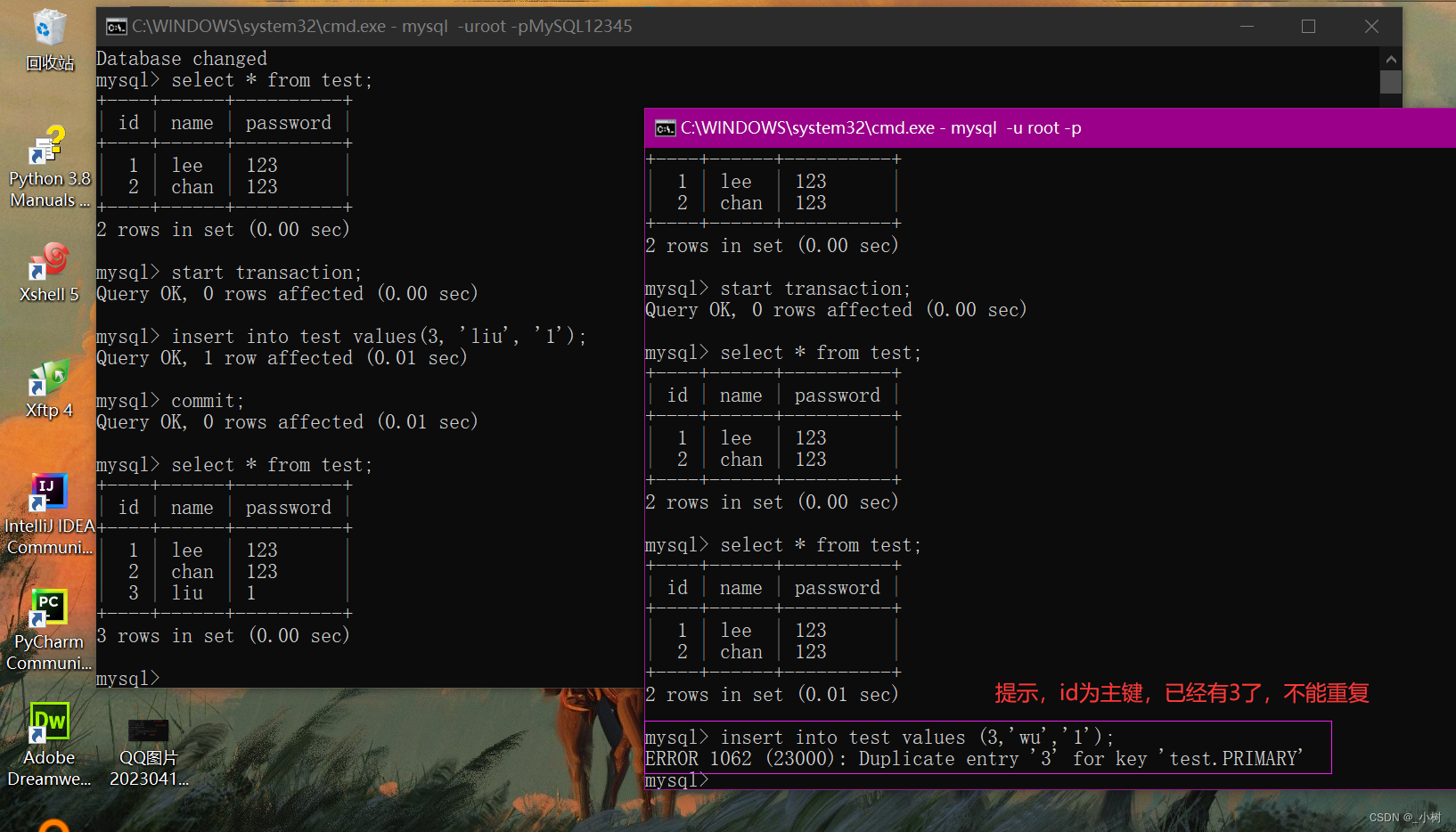
5.将事务y提交,并查询
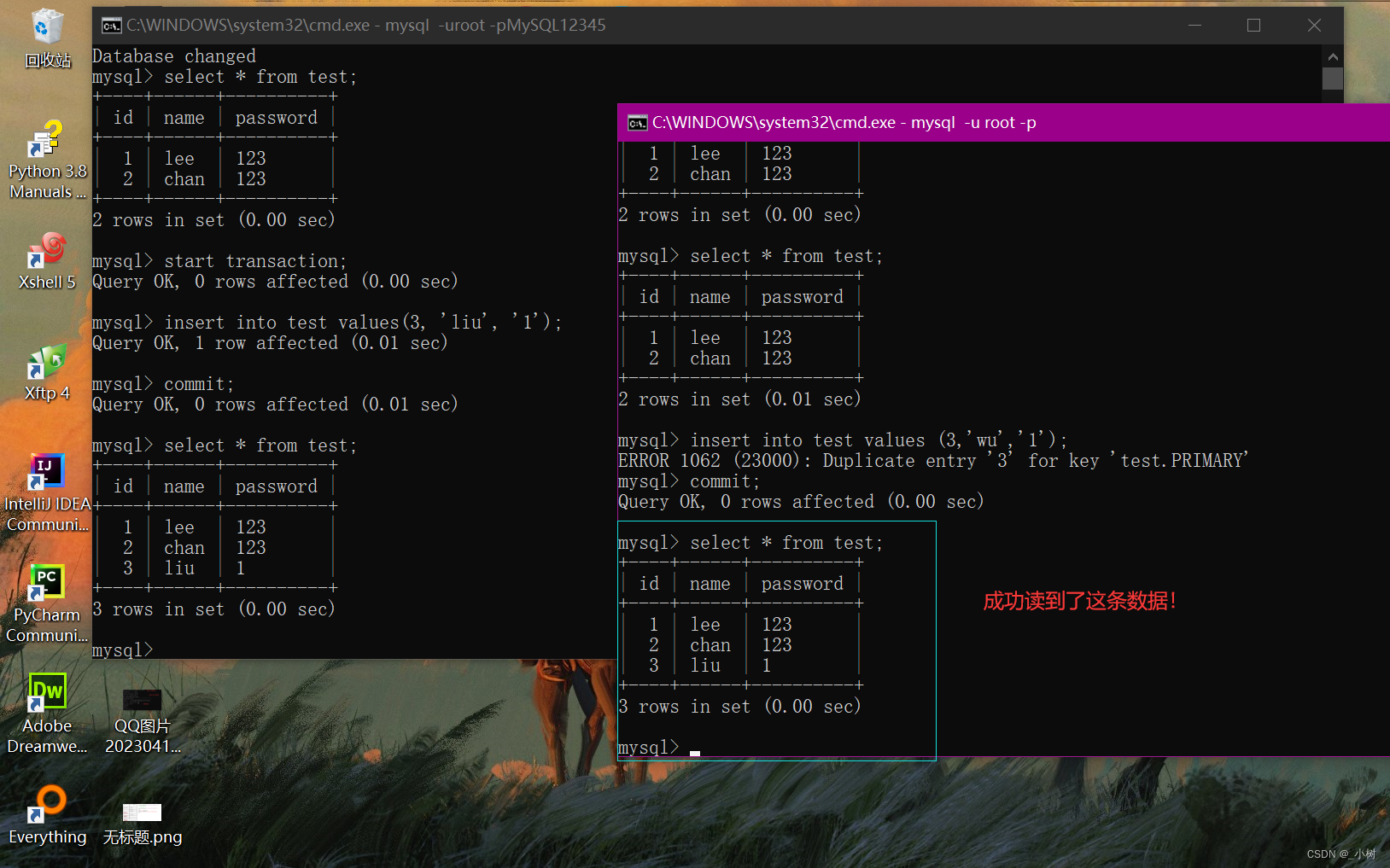
幻读:
事务y查询id为3的行,查询不到,插入又不成功,(3,‘liu’,1)这条数据就像 幻觉 一样出现。这就是所谓的“幻读”
事务中,注意:
四种隔离级别
脏读
不可重复读
幻读