目录
前提条件
数据准备
探讨HQL是否转为MapReduce程序执行
1.设置hive.fetch.task.conversion=none
2.设置hive.fetch.task.conversion=minimal
3.设置hive.fetch.task.conversion=more
前提条件
Linux环境下安装好Hive,这里测试使用版本为:Hive2.3.6,Hive安装配置可参考:Hive安装配置
数据准备
创建hive表
hive> create table employee_3(
name STRING,
salary FLOAT,
subordinates ARRAY<STRING> ,
deductions MAP<STRING,FLOAT>,
address STRUCT<street : STRING, city : STRING, state : STRING, zip : INT>)
row format delimited fields terminated by '\t' collection items terminated by ',' map keys terminated by ':';本地数据
[hadoop@node1 ~]$ vim emp3.txt
Zhangsan 3000 li1,li2,li3 cd:30,zt:50,sw:100 huayanlu,Guiyang,China,550025
Lisi 4000 w1,w2,w3 cd:10,zt:40,sw:33 changlingjiedao,Guiyang,China,550081
Zhangsan 3000 li1,li2,li3 cd:30,zt:50,sw:100 huayanlu,Guiyang,China,550025
Lisi 4000 w1,w2,w3 cd:10,zt:40,sw:33 changlingjiedao,Guiyang,China,550081加载数据
hive> load data local inpath 'emp3.txt' into table employee_3;查看数据
hive> select * from employee_3;
OK
Zhangsan 3000.0 ["li1","li2","li3"] {"cd":30.0,"zt":50.0,"sw":100.0} {"street":"huayanlu","city":"Guiyang","state":"China","zip":550025}
Lisi 4000.0 ["w1","w2","w3"] {"cd":10.0,"zt":40.0,"sw":33.0} {"street":"changlingjiedao","city":"Guiyang","state":"China","zip":550081}
Zhangsan 3000.0 ["li1","li2","li3"] {"cd":30.0,"zt":50.0,"sw":100.0} {"street":"huayanlu","city":"Guiyang","state":"China","zip":550025}
Lisi 4000.0 ["w1","w2","w3"] {"cd":10.0,"zt":40.0,"sw":33.0} {"street":"changlingjiedao","city":"Guiyang","state":"China","zip":550081}
Time taken: 0.194 seconds, Fetched: 4 row(s)我们会发现,select * 操作是直接出结果的,没有转为MapReduce程序执行。
那什么情况下能触发MapReduce操作呢?依据是什么?
探讨HQL是否转为MapReduce程序执行
查看hive-default.xml.template文件
[hadoop@node1 ~]$ cd $HIVE_HOME/conf
[hadoop@node1 conf]$ ls
beeline-log4j2.properties.template hive-site.xml
hive-default.xml.template ivysettings.xml
hive-env.sh.template llap-cli-log4j2.properties.template
hive-exec-log4j2.properties.template llap-daemon-log4j2.properties.template
hive-log4j2.properties.template parquet-logging.properties
[hadoop@node1 conf]$ vim hive-default.xml.template 按/task.conversion搜索task.conversion相关配置
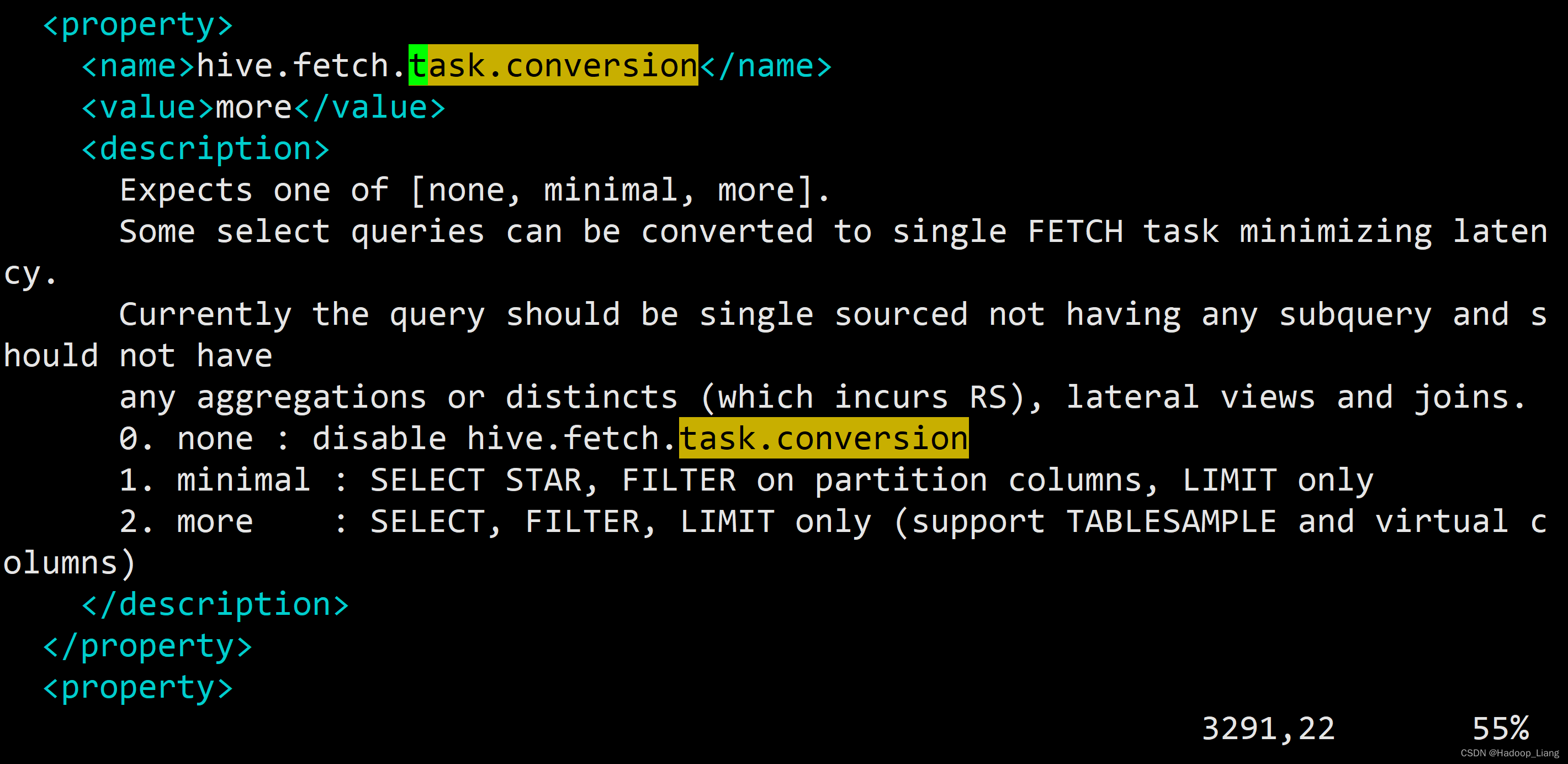
<property>
<name>hive.fetch.task.conversion</name>
<value>more</value>
<description>
Expects one of [none, minimal, more].
Some select queries can be converted to single FETCH task minimizing latency.
Currently the query should be single sourced not having any subquery and should not have
any aggregations or distincts (which incurs RS), lateral views and joins.
0. none : disable hive.fetch.task.conversion
1. minimal : SELECT STAR, FILTER on partition columns, LIMIT only
2. more : SELECT, FILTER, LIMIT only (support TABLESAMPLE and virtual columns)
</description>
</property>可以看到配置项hive.fetch.task.conversion默认配置为more, 配置值除了more之外,还可以配置为none和minimal.
fetch 翻译为"抓取"。fetch是指某些HQL操作可以不必使用 MapReduce 计算,直接到表对应的数据存储目录抓取到相应的数据,直接通过Fatch task返回给客户端。
启用 MapReduce Job 是会消耗系统开销的。对于这个问题,从 Hive0.10.0 版本开始,对于简单的不需要聚合的类似
select <col> from <table> limit n语句,不需要起 MapReduce job,直接通过 Fetch task 获取数据。
比如:select * from user_table;在这种情况下,Hive 可以简单地抓取 user_table 对应的存储目录下的文件,然后输出查询结果到控制台。
1.设置hive.fetch.task.conversion=none
官方解释:
none : disable hive.fetch.task.conversion
禁用fetch操作
fetch.task为none的意思是,不直接抓取表对应的存储数据,返回的数据都需要通过执行MapReduce得到,这时候,只有desc操作不走MapReduce程序。
设置hive.fetch.task.conversion=none
hive> set hive.fetch.task.conversion=none;测试desc,没有走MapReduce程序
hive> desc employee_3;
OK
name string
salary float
subordinates array<string>
deductions map<string,float>
address struct<street:string,city:string,state:string,zip:int>
Time taken: 0.187 seconds, Fetched: 5 row(s)测试其他操作,例如:select * 操作,从执行日志中看到,这个操作需要走MapReduce程序(有Map,没有Reduce)
hive> select * from employee_3;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = hadoop_20230416115907_93e4dc77-02cb-4caf-a16b-24749a747bde
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1681614461744_0002, Tracking URL = http://node1:8088/proxy/application_1681614461744_0002/
Kill Command = /home/hadoop/soft/hadoop/bin/hadoop job -kill job_1681614461744_0002
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2023-04-16 11:59:17,681 Stage-1 map = 0%, reduce = 0%
2023-04-16 11:59:26,347 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 4.18 sec
MapReduce Total cumulative CPU time: 4 seconds 180 msec
Ended Job = job_1681614461744_0002
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 4.18 sec HDFS Read: 5579 HDFS Write: 459 SUCCESS
Total MapReduce CPU Time Spent: 4 seconds 180 msec
OK
Zhangsan 3000.0 ["li1","li2","li3"] {"cd":30.0,"zt":50.0,"sw":100.0} {"street":"huayanlu","city":"Guiyang","state":"China","zip":550025}
Lisi 4000.0 ["w1","w2","w3"] {"cd":10.0,"zt":40.0,"sw":33.0} {"street":"changlingjiedao","city":"Guiyang","state":"China","zip":550081}
Zhangsan 3000.0 ["li1","li2","li3"] {"cd":30.0,"zt":50.0,"sw":100.0} {"street":"huayanlu","city":"Guiyang","state":"China","zip":550025}
Lisi 4000.0 ["w1","w2","w3"] {"cd":10.0,"zt":40.0,"sw":33.0} {"street":"changlingjiedao","city":"Guiyang","state":"China","zip":550081}
Time taken: 20.959 seconds, Fetched: 4 row(s)浏览器查看8088端口
2.设置hive.fetch.task.conversion=minimal
官方解释:
minimal : SELECT STAR, FILTER on partition columns, LIMIT only
仅仅 Select * 操作、过滤数据(从某个分区拿到的列数据)、limit操作 可以使用fetch操作。
设置fetch.task为minimal,最少使用fetch操作,desc和select * 、limit 操作 不走MapReduce,其余都要走MapReduce程序。
hive> set hive.fetch.task.conversion=minimal;测试 desc 和 select * 操作,是直接返回结果的,不走MapReduce程序
hive> desc employee_3;
OK
name string
salary float
subordinates array<string>
deductions map<string,float>
address struct<street:string,city:string,state:string,zip:int>
Time taken: 0.044 seconds, Fetched: 5 row(s)
hive> select * from employee_3;
OK
Zhangsan 3000.0 ["li1","li2","li3"] {"cd":30.0,"zt":50.0,"sw":100.0} {"street":"huayanlu","city":"Guiyang","state":"China","zip":550025}
Lisi 4000.0 ["w1","w2","w3"] {"cd":10.0,"zt":40.0,"sw":33.0} {"street":"changlingjiedao","city":"Guiyang","state":"China","zip":550081}
Zhangsan 3000.0 ["li1","li2","li3"] {"cd":30.0,"zt":50.0,"sw":100.0} {"street":"huayanlu","city":"Guiyang","state":"China","zip":550025}
Lisi 4000.0 ["w1","w2","w3"] {"cd":10.0,"zt":40.0,"sw":33.0} {"street":"changlingjiedao","city":"Guiyang","state":"China","zip":550081}
Time taken: 0.215 seconds, Fetched: 4 row(s)
hive> select * from employee_3 limit 1;
OK
Zhangsan 3000.0 ["li1","li2","li3"] {"cd":30.0,"zt":50.0,"sw":100.0} {"street":"huayanlu","city":"Guiyang","state":"China","zip":550025}
Time taken: 0.168 seconds, Fetched: 1 row(s)
测试其他情况,走MapReduce
hive> select salary from employee_3 where name in ("Lisi");
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = hadoop_20230416120829_de5cc03b-6736-45ce-98e4-aa2bc0446313
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1681614461744_0003, Tracking URL = http://node1:8088/proxy/application_1681614461744_0003/
Kill Command = /home/hadoop/soft/hadoop/bin/hadoop job -kill job_1681614461744_0003
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2023-04-16 12:08:41,741 Stage-1 map = 0%, reduce = 0%
2023-04-16 12:08:52,660 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 5.68 sec
MapReduce Total cumulative CPU time: 5 seconds 680 msec
Ended Job = job_1681614461744_0003
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 5.68 sec HDFS Read: 5404 HDFS Write: 125 SUCCESS
Total MapReduce CPU Time Spent: 5 seconds 680 msec
OK
4000.0
4000.0
Time taken: 23.937 seconds, Fetched: 2 row(s)3.设置hive.fetch.task.conversion=more
官方解释:
more : SELECT, FILTER, LIMIT only (support TABLESAMPLE and virtual columns)
仅仅 Select * 操作、过滤操作、limit操作(支持表提供的列和虚拟列) 可以使用fetch操作。
设置fetch.task为more,最多使用fetch操作,desc、select * 、select * from user_table where column_n in (“a”, “b”)过滤、limit操作,不走MapReduce操作。
测试,不走MapReduce的操作
hive> set hive.fetch.task.conversion=more;
hive> select salary from employee_3 where name in ("Lisi");
OK
4000.0
4000.0
Time taken: 0.425 seconds, Fetched: 2 row(s)
hive> desc employee_3;
OK
name string
salary float
subordinates array<string>
deductions map<string,float>
address struct<street:string,city:string,state:string,zip:int>
Time taken: 0.067 seconds, Fetched: 5 row(s)
hive> select * from employee_3;
OK
zhangsan 3000.0 ["li1","li2","li3"] {"cd":30.0,"zt":50.0,"sw":100.0} {"street":"huayanlu","city":"Guiyang","state":"China","zip":550025}
Lisi 4000.0 ["w1","w2","w3"] {"cd":10.0,"zt":40.0,"sw":33.0} {"street":"changlingjiedao","city":"Guiyang","state":"China","zip":550081}
zhangsan 3000.0 ["li1","li2","li3"] {"cd":30.0,"zt":50.0,"sw":100.0} {"street":"huayanlu","city":"Guiyang","state":"China","zip":550025}
Lisi 4000.0 ["w1","w2","w3"] {"cd":10.0,"zt":40.0,"sw":33.0} {"street":"changlingjiedao","city":"Guiyang","state":"China","zip":550081}
Time taken: 0.194 seconds, Fetched: 4 row(s)
hive> select * from employee_3 limit 1;
OK
Zhangsan 3000.0 ["li1","li2","li3"] {"cd":30.0,"zt":50.0,"sw":100.0} {"street":"huayanlu","city":"Guiyang","state":"China","zip":550025}
Time taken: 0.168 seconds, Fetched: 1 row(s)
测试需要走MapReduce程序的操作,例如:统计操作,从输出日志得知,需要执行MapReduce操作(包括Map操作和Reduce操作)
hive> select count(1) from employee_3;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = hadoop_20230416134802_ac41c52d-be35-4515-a678-70e43dec35fc
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1681614461744_0006, Tracking URL = http://node1:8088/proxy/application_1681614461744_0006/
Kill Command = /home/hadoop/soft/hadoop/bin/hadoop job -kill job_1681614461744_0006
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2023-04-16 13:48:12,085 Stage-1 map = 0%, reduce = 0%
2023-04-16 13:48:19,440 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.39 sec
2023-04-16 13:48:26,852 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 6.39 sec
MapReduce Total cumulative CPU time: 6 seconds 390 msec
Ended Job = job_1681614461744_0006
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 6.39 sec HDFS Read: 9446 HDFS Write: 101 SUCCESS
Total MapReduce CPU Time Spent: 6 seconds 390 msec
OK
4
Time taken: 26.934 seconds, Fetched: 1 row(s)参考链接:
HIVE 调优—— hive.fetch.task.conversion - 简书
Hive SQL触发MR的情况_hive中什么哪些语句会执行mr_AAcoding的博客-CSDN博客
完成!enjoy it!