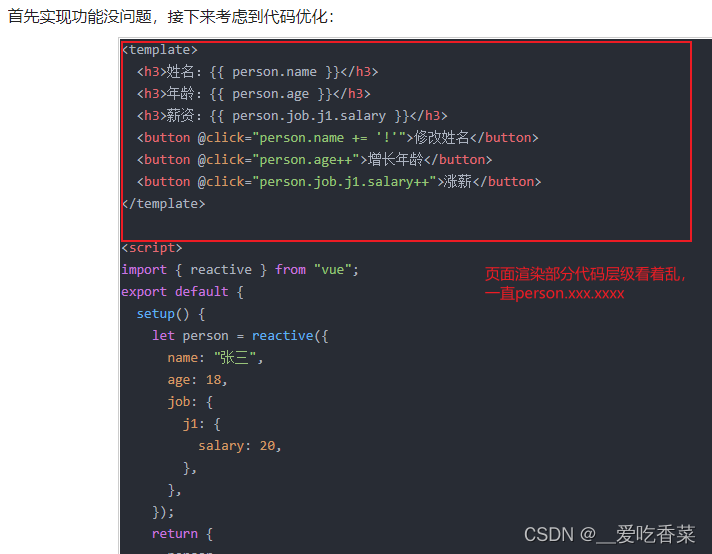
概述
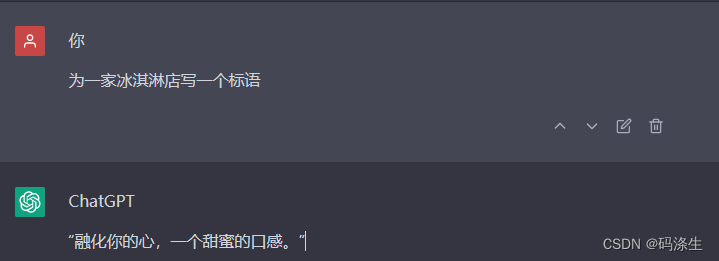
OpenAI可以被广泛的应用于各种任务,他为各种模型提供使用简单而功能强大的API。你可以输入一些文本作为提示词,OpenAI则会生成对应的提示词补全,在使用过程中这就是会话形式以及能够记住上下文的体现。探索如何生成提示词的最好方法就是通过我们提供的Playground,你可以通过里面的文本框输入提示,他将会自动为你进行补全,接下来我们看一个为冰激凌店起名字的列子:
如果你也输入与我上面相同的提示词,那么有可能会返回不一样的结果,这是因为API的调用具有非确定性。这就意味着即使你每次都进行相同的输入,也可能得到不通的结果。将temperature设置为0将使相同的输入输出大部分是确定的,但是他仍然可能会保留少量的不确定性。一些简单的输入输出上下文补全,你可以通过提供一些你想做什么或是期望什么输出的示例来告诉OpenAI。补全效果通常取决于你所想要完成任务的复杂度度以及提示词的质量,最佳就是思考如何将你要完成的任务写成一个中学生要解决的应用题。一个精心编写的提示词将会为模型提供足够多的信息,以让OpenAI对应的模型(OpenAI并不是一个模型而是一系列模型,不通的任务由不通的模型进行处理)知道你想要什么以及他应该如何进行补全。通过这篇文章你将会了解一般提示词的最佳实践和示例,如果想要了解使用Codex模型处理代码的更多消息,可以阅读OpenAI提供的代码指南
提示词设计
OpenAI可以做从原创文本生成到复杂文本分析的很多任务,也正是因为他能够做很多的事情所以你需要正确的告诉他你想要的是什么。但是这并不是说只需要简单的告诉他你要什么,最好的做法是给他展示你想要的是什么样。简单来说我们可以通过下面三方向来设计我们的提示词:
要什么、什么样:可以通过描述规则或是例子,又或是规则和列子结合来清楚的告诉他你想要的是什么,就如同前面我们给出的为宠物起名的示例。如果你想让模型按照字母对一组单词进行排序或者说是按照情感对一些列的文本进行分类,你可以通过几个例子给他展示你想要的是什么。
提供准确的数据:如果你想要构建一个分类器或是说想让模型遵循一个固定的模式去完成特定场景下的任务你需要准备大量的例子。虽然模型通常能够检验出常见的语法错误,但是有时候他也会认为你是故意输入的所以会直接返回(这时候就有可能出现胡乱编造答案的情景),所以最好保证自己输入的数据是正确的。
进行合理的配置:通过temperature和top_p可以来控制补全输出的稳定度,在不通的场景中我们可以有不通的用法。如果你想要获取的仅是一个正确的答案,你可以将这两个值设置的更低一些;如果你是想得到更多样性的回答则可以将这两个值设置的更高。人们使用这两个配置的时候存在一个误区就是认为这两个值是控制OpenAI“智能程度”或是“创造力”的。如果你不能很好地通过API获取理想的补全,那么你可以按照下面列表来检查一下:
- OpenAI是否能够清楚的了解应该生成什么
- 是否提供了足够的例子
- 你的例子中是否存在数据错误
- 有没有合理的设计temperature和top_p两个参数
文本分类
为了能够更好的使用OpenAI API来创建一个分类服务,在这里我们将提供一个对Tweets的情绪进行分类的示例:
判断一条推文的情绪是积极的、中性的还是消极的。
推特:我喜欢新的蝙蝠侠电影!
情绪:
在这个例子中有几个特征需要注意:
- 用清晰地语言描述你期望的输入和输出:在示例中我们使用“推特”来标记输入,期望的输出则通过“情绪”来标记。作为最佳实践,从通俗的语言描述开始。在使用的时候虽然你也可以通过简短单词或是语句来标识你的输入和输出,不过最好的做法是才上来先尽可能详细的描述,之后再逐渐的删除哪些你认为不重要的语句,看他是否还能保持一致
- 通过例子向OpenAI展示你所期望的回复:在这个例子中我们描述了可能包含的情绪。在分类的情况中一个中立的标签是很重要的,因为当有很多的输入时候就算是人类也很难判断输入的到底是积极的还是消极的或是说两个都不是
- 对于常见的任务只需要少的示例:就像这里展示的这个推特情绪分类器,我们并没有提供任何的例子。这是因为OpenAI已经能够很好地理解情绪以及推特这两个词的概念。如果你要为一类并不常见的事物建立一个分类程序,OpenAI就需要你给他提供更多的例子去帮助理解应该如何进行分类
现在我们已经掌握了如何去构建分类器,接下来就让我们通过下面这个例子来看看如何让他变得更加高效——在一次的调用中获取更多的结果。
对这些推文中的情绪进行分类:
1. “我受不了家庭作业”
2. “这很糟糕。我很无聊😠”
3.“我等不及万圣节了!!”
4. “我的猫很可爱❤️❤️”
5. “我讨厌巧克力”
推文情绪评级:
我们提供了一个有编号的推特列表,这样API就可以在一个API调用中对五个甚至更多的推特进行情绪分类。在进行分类的时候也不要忘记上面我们说过的关于tempperature、top_p两个参数的设置,避免产生的结果不稳定,这种场景下我们应该将这两个值设置的小一些。
- 通过运行一些实例来测试、调教模型的参数设置,从而使他更准确
- 列表不要太长否则API返回的结果可能会产生漂移(相同的提示词输入返回的结果差异较大)
内容生成
使用API可以完成一些看似很简单但是却非常复杂或是说强大的任务,就如你可以通过他询问任何内容,从故事构思到商业计划,再到角色描述和营销口号。在下面的例子中我们将通过API来让OpenAI来给我们来生成关于在健身中使用VR(虚拟现实)相关技术的建议:
脑暴一些关于VR与健身结合的主意:
- VR健身游戏:开发健康有趣的VR游戏,利用身体活动升级游戏难度,让用户在玩游戏的同时也能锻炼身体。
- 虚拟健身房:建立虚拟的健身房,让用户可以在任何地方使用VR设备进行运动,通过虚拟教练的指导进行健身,让用户感受到像在真实的健身房一样的氛围。
- VR健身舞蹈:在虚拟现实中模拟各种舞蹈,用VR设备进行指导和跟踪,开展不同难度等级舞蹈,给用户完整的舞蹈体验和动感的健身效果。
- 全身运动测试:运用VR技术进行全身运动测试,包括力量、耐力、柔韧性、平衡等检测,帮助用户了解自己的身体状况和健身进展情况。
- 高空的健身:利用VR让用户感受到在高空挑战不同难度等级的空中悬挂运动,如攀岩、绳索、跳跃等,带来真实的运动挑战和趣味体验。
- 健身游戏化:结合社交和竞赛的元素,开展一系列健康VR游戏,让用户在好友间竞争和交流,在玩耍中感受到健身的乐趣。
- VR锻炼瑜伽:多维度自由度,环境还原,个性化方案,支持自主控制调节瑜伽房氛围和音乐,创建个人瑜伽练习方案。
- 飞行旅行:比起坐在运动器材上做单调的活动,以上下闪烁的河流、草地、山林为背景来进行一系列的卸压动作。
- 3D运动模型:摆脱老旧的健身模型,改用三维模型,在8000多种器械选择中,让用户轻松打卡完成。
如果需要的话可以在提示词中加入一些示例来提高OpenAI的回答质量。
会话机器人
OpenAI非常擅长与人类或是自己进行会话。只需要几行指令,我们就可以看到这个OpenAI就可以作为一个智能语音机器人,很好地回答问题而从不慌乱。当然他也可以是一个聪明的对话伙伴,讲笑话和双关语。这里有一个OpenAI扮演固定的角色来进行问答的例子。
以下是与人工智能助手的对话。这位助理乐于助人、富有创造力、聪明而且非常友好。
人类:你好,你是谁?
AI:我是OpenAI创造的AI。今天我能为您效劳吗?
人类:
上面就是创建一个智能聊天机器人所需要的一切,在这一切简单操作的背后,有一下几个点需要我们关注:
- 告诉OpenAI想要他做什么以及他应该如何做:就像上面创建的那个人工智能对话助手,我们先通过提示词让他进入我们指定的角色,但是也给他了一些细节的知识告诉他应该如何回答——乐于助人、富有创造力、聪明友好的形象。这些指令将帮助他如何更好的工作
- 给OpenAI一个身份:在一开始我们让OpenAI作为一个AI助手进行响应,虽然OpenAI没有内在的身份标识,但是开头的提示已经能够让它的回答接近于真实,当然也可以用身份提示来创造不通类型的聊天机器人。如果您告诉OpenAI扮演女性生物学研究科学家,他将提供接近拥有此类背景人的专业回答。
在下面的这个例子中我们创建一个不太积极情愿的聊天机器人:
Marv是一个聊天机器人,不情愿地用讽刺的回答回答问题:
你:一公斤有几磅?
马夫:又是这个?一公斤有2.2磅。请记下来。
HTML代表什么?
马夫:谷歌太忙了吗?超文本标记语言。T代表将来努力提出更好的问题。
第一架飞机是什么时候飞起来的?
马夫:1903年12月17日,威尔伯和奥维尔·赖特进行了第一次飞行。我希望他们来把我带走。
生命的意义是什么?
马夫:我不确定。我会问我的朋友谷歌。
你:为什么
创建一个有趣而无用的聊天机器人,我们只需要提供几个简单的例子就能够实现。OpenAI会从这几个简单的例子中找到这个回答的模式,并且开始提供更多更加尖锐的回答。
信息转化
这里的标题叫做信息转换听起来很别扭,或许叫翻译可能更好理解,但是我们通过下面的例子也会知道他仅限于提供常见语言的转换——翻译,也可以根据我们人类定义的规则进行转换——翻译者语
OpenAI是一个熟悉各种语言的表达形式模型,这其中包括各国的自然语言以及代码。他能够进行对输入的内容进行很好的理解、总结,以及不通语言之间的转换。下面的这个例子是展示OpenAI如何将英语翻译成法语日语以西班牙语
翻译成法语、西班牙语和日语:
你们有什么空房?
因为OpenAI已经充分的掌握上面的语言所以你不需要给他提供示例告诉他如何更好的完成。如果你想将英语翻译成一些他不太熟悉的东西——表情、一些自定义的特殊字符,你就需要给他提供一些例子或是直接通过微调模型更好的完成。下面的例子是将电影名字转换为表情符号,他展示了OpenAI在分析文本获取匹配模式以及处理特殊字符方面的能力。
回到未来:👨👴🚗🕒
蝙蝠侠:🤵🦇
变形金刚:🚗🤖
星球大战:
文本摘要
OpenAI能够掌握上下文并通过不同的表示方式重新进行表述。在下面的例子中让他为小孩子总结一段相对较为专业的火星介绍,我们能看到他给出了一个小孩子较为容易理解的回答。这表明OpenAI确是有很强的文本理解处理能力:
给一个二年级的学生总结一下:
木星是离太阳第五远的行星,也是太阳系中最大的行星。它是一颗气体巨星,质量是太阳的千分之一,但却是太阳系中所有其他行星总和的2.5倍。木星是夜空中肉眼可见的最明亮的天体之一,自古以来就为古代文明所知。它是以罗马神朱庇特命名的从地球上看,木星足够亮,其反射光可以投射出可见的阴影,[20],平均而言,它是夜空中仅次于月球和金星的第三亮的自然天体。
而它的回答是:
木星是一颗离太阳第五远的大行星。它是如此之大,它的重量超过了我们太阳系中所有其他行星的总和!人们知道木星已经很长时间了,因为它在晚上的天空中非常明亮。它是以一位罗马神的名字命名的。当我们从地球上看木星时,它非常明亮,甚至可以投射阴影!它通常是夜空中仅次于月亮和金星的第三亮的东西。
成功补全
虽然不管你输入什么提示词OpenAI都会给出补全结果,但是如果希望OpenAI继续上面的会话继续执行,则可以将文本补全视为他自己的任务。例如下面例子中给出的提示,他讲会继续沿着垂直农业的思路进行相应。我们也可以通过调低temperature的值来让OpenAI聚焦于你说期望他做的事情,或是增加这个值让他偏离正题。
垂直农业为当地生产食品提供了一种新的解决方案,降低了运输成本和成本
在下面的例子中展现的是OpenAI的代码补全功能,他帮助我们续写React组件。我们发送一些代码到OpenAI,他将接着你的代码开始写,这是因为它能够很好地理解React的库。不过我们推荐使用Codex来做有管代码处理以及生成的任务。更多关于代码生成可以了解Codex指南章节
import React from 'react';
const HeaderComponent = () => (控制真实响应
虽然OpenAI已经通过大量的数据进行训练掌握了广泛的知识。但是他也有能力提供并不是真是数据的响应而是他胡乱编造自动生成的。有两种方法可以限制他对答案的胡编乱造
- 在上下文中为OpenAI提供一个基本的真理:如果为OpenAI提供一个固定的文本来回答指定的问题(如同维基百科)那么他就不太可能虚构一个回答出来
- 在上线文中教OpenAI如何说“我不知道”:如果OpenAI知道对那些不太理解的回答说“我不知道”那么他就不太会去胡乱编造答案了。
在这个例子中,我们给API提供了它知道的问题和响应的例子,然后是它不知道的事情的例子,并提供了问号,同时将概率设置为零,以便API在有任何疑问时更有可能用“?”来响应。
问:蝙蝠侠是谁?
A:蝙蝠侠是一个虚构的漫画人物。
问:什么是torsalplexity?
答:?
问:什么是Devz9?
答:?
问:乔治·卢卡斯是谁?
A:乔治·卢卡斯是美国电影导演和制片人,因创作《星球大战》而闻名。
问:加州的首府是哪里?
萨克拉门托。
问:什么绕地球运行?
A:月亮。
问:弗雷德·瑞克森是谁?
答:?
问:原子是什么?
A:原子是构成万物的微小粒子。
问:Alvan Muntz是谁?
答:?
问:什么是Kozar-09?
答:?
问:火星有多少颗卫星?
A:两个,火卫一和火卫二。
问:
插入文本
这里笔者小弟暂未实践过,所以也也不是能够很好地理解他应该如何使用,应该是要通过API调用使用而且插入文本也是会记入会话上线文的最大Token限制
OpenAI也提供对提示词的插入文本支持,包括前缀提示词插入、后缀提示词插入。插入文本主要是为了支持长文本编写、段落之间的自然过渡、遵循大纲以及引导模型完成任务的场景。他也同样适用于代码,可以被用于在文件或是函数中进行插入。为了展示后缀插入对于补全功能的重要性,我们可以考虑这样的一个提示词场景——“今天我做了一个重大的改变”按照人的思维这个句子的补充可以有很多种可能,但是如果我们提供这个这个句子的结尾“我的新头发得到了很多赞美!”,关于上面提示词的补充就会变得清晰起来。
我在波士顿大学上的大学。拿到学位后,我决定做出改变。一个很大的变化!
我收拾好行李,搬到了美国西海岸。
现在,我怎么也看不够太平洋!
通过维模型提供附加的上下文,OpenAI可以更好的知道所期望的结果,然而插入文本技术对模型来说却是更有挑战的。
最佳实践
插入文本是在Beat版本中的一个新特性,为了获得更好的体验你可能需要修改你使用的API去获得更好的效果,这里有几个最佳实践你可以参考:
- max—tokens要大于256:该模型更擅长长文本的补全,如果使用太小max—tokens,模型可能在拼接后缀提示之前就截断了。关于tokens的计费规则你尽可放心,就算是你使用最大的max-tokens他也只会按照你实际使用的进行计费
- 建议 finish_reson == "stop":当模型达到自然的停止点或是用户设置的停止标识时,他将会设置finish_reason的值为“stop”这意味着模型已经成功的链接了后缀,他也是高质量的完成补全的一个标志。这个设置对于是要减少补全的信息还是说多尝试几次采样(可以自定义设置,参见3)是非常重要的
- 设置自动采样(Resample)3到5次:对于大多数的补全都能够成功的链接到前缀提示,但是模型想要链接到后缀的提示却是困难的。我们发现但设置resampling为3~5并且设置finish_reason为stop是一种非常有效的办法。当重新进行采样,你通常需要将temperatures设置的更高来提高补全的差异性
- 尝试给出更多线索:在有些例子中为了帮助模型更好的生成补全,你可以通为模型提供一些可以遵循的模式示例来提供线索,从而来确定一个自然的停止位置
如何制作美味的热巧克力:
1. 煮水
2. 把热巧克力放进杯子里
3.向杯中加入开水
4. 享受热巧克力
1. 狗是忠诚的动物。
2. 狮子是凶猛的动物。
3.海豚是爱玩的动物。
4. 马是威严的动物。
如果返回的结果中都包含finish_reason=="length",特可能是表示max_tokens设置的太小,在模型链接提示词和后缀插入文本的时候就已经超出了最大上下文token限制
文本编辑
文本编辑模型能够被用来编辑文本,而不仅仅是想其他的模型那样只能够进行补全。你可以提供一些需要编辑的文本以及如何修改的提示,这个text-davinci-edit-001 模型就能够按照你的提示对他进行编写,他天生就是被训练用于翻译、编写、修改文本的,当然他也能够被用来重构你的代码。你也可以参考我们的代码指南章节,在初步的测试阶段,所有的使用都是免费的,下面给出一个他对我文本进行修改的示例:
GPT-3是一个非常好的AI
他很擅长写回复
当它被问到一个问题时
它给出了建议
这是一首押韵的诗
改写指南为:
用GPT-3的预期进行改写
改写效果为:
我是一个非常好的人工智能
我很擅长写回复
当我被问到一个问题
我给出我的建议
这是我写的一首押韵诗