全局有序
在RocketMQ中,如果使消息全局有序,可以为Topic设置一个消息队列,使用一个生产者单线程发送数据,消费者端也使用单线程进行消费,从而保证消息的全局有序,但是这种方式效率低,一般不使用。
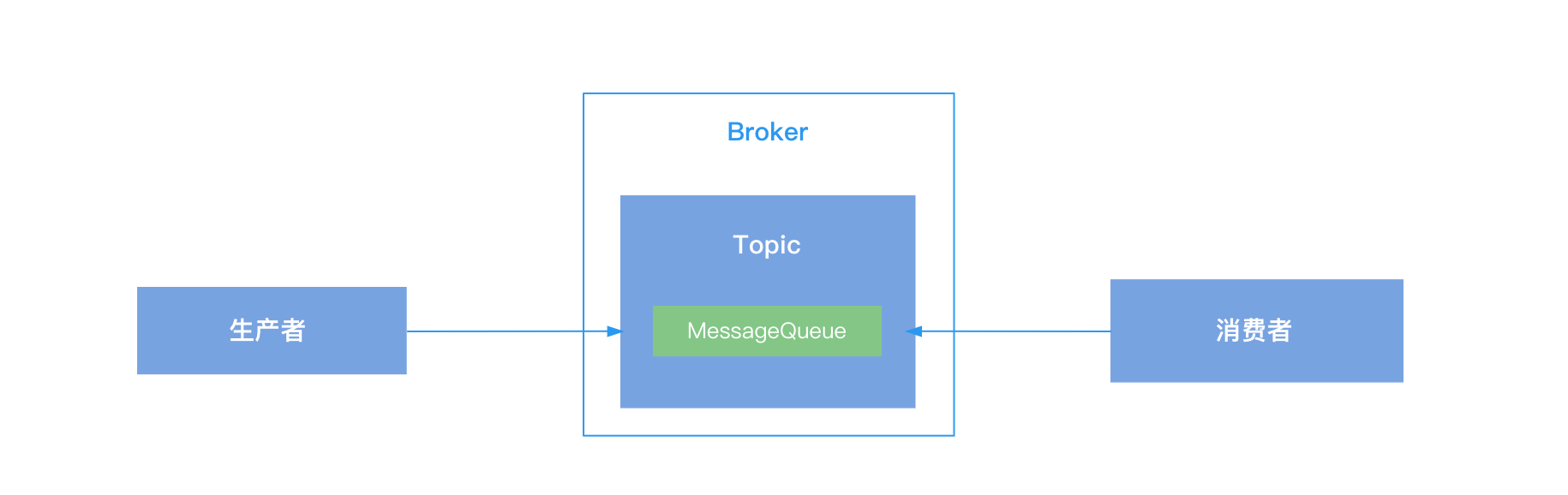
局部有序
假设一个Topic分配了两个消息队列,生产者在发送消息的时候,可以对消息设置一个路由ID,比如想保证一个订单的相关消息有序,那么就使用订单ID当做路由ID,在发送消息的时候,通过订单ID对消息队列的个数取余,根据取余结果选择消息队列,这样同一个订单的数据就可以保证发送到一个消息队列中,消费者端使用MessageListenerOrderly处理有序消息,这就是RocketMQ的局部有序,保证消息在某个消息队列中有序。
接下来看RoceketMQ源码中提供的顺序消息例子(稍微做了一些修改):
生产者
public class Producer {
public static void main(String[] args) throws UnsupportedEncodingException {
try {
// 创建生产者
DefaultMQProducer producer = new DefaultMQProducer("生产者组");
// 启动
producer.start();
// 创建TAG
String[] tags = new String[] {"TagA", "TagB", "TagC", "TagD", "TagE"};
for (int i = 0; i < 100; i++) {
// 生成订单ID
int orderId = i % 10;
// 创建消息
Message msg =
new Message("TopicTest", tags[i % tags.length], "KEY" + i,
("Hello RocketMQ " + i).getBytes(RemotingHelper.DEFAULT_CHARSET));
SendResult sendResult = producer.send(msg, new MessageQueueSelector() {
@Override
public MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {
// 获取订单ID
Integer id = (Integer) arg;
// 对消息队列个数取余
int index = id % mqs.size();
// 根据取余结果选择消息要发送给哪个消息队列
return mqs.get(index);
}
}, orderId); // 这里传入了订单ID
System.out.printf("%s%n", sendResult);
}
producer.shutdown();
} catch (MQClientException | RemotingException | MQBrokerException | InterruptedException e) {
e.printStackTrace();
}
}
}
消费者
public class Consumer {
public static void main(String[] args) throws MQClientException {
// 创建消费者
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("消费者组");
consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_FIRST_OFFSET);
// 订阅主题
consumer.subscribe("TopicTest", "TagA || TagC || TagD");
// 注册消息监听器,使用的是MessageListenerOrderly
consumer.registerMessageListener(new MessageListenerOrderly() {
@Override
public ConsumeOrderlyStatus consumeMessage(List<MessageExt> msgs, ConsumeOrderlyContext context) {
context.setAutoCommit(true);
// 打印消息
System.out.printf("%s Receive New Messages: %s %n", Thread.currentThread().getName(), msgs);
return ConsumeOrderlyStatus.SUCCESS;
}
});
consumer.start();
System.out.printf("Consumer Started.%n");
}
}
从例子中可以看出生产者在发送消息的时候,通过订单ID作为路由信息,将同一个订单ID的消息发送到了同一个消息队列中,保证同一个订单ID的消息有序,那么消费者端是如何保证消息的顺序读取呢?接下来就去看下源码。
顺序消息实现原理
在【RocketMQ】消息的拉取一文中讲到,消费者在启动时会调用DefaultMQPushConsumerImpl的start方法:
public class DefaultMQPushConsumer extends ClientConfig implements MQPushConsumer {
/**
* 默认的消息推送实现类
*/
protected final transient DefaultMQPushConsumerImpl defaultMQPushConsumerImpl;
/**
* 启动
*/
@Override
public void start() throws MQClientException {
setConsumerGroup(NamespaceUtil.wrapNamespace(this.getNamespace(), this.consumerGroup));
// 启动消费者
this.defaultMQPushConsumerImpl.start();
// ...
}
}
在DefaultMQPushConsumerImpl的start方法中,对消息监听器类型进行了判断,如果类型是MessageListenerOrderly表示要进行顺序消费,此时使用ConsumeMessageOrderlyService对ConsumeMessageService进行实例化,然后调用它的start方法进行启动:
public class DefaultMQPushConsumerImpl implements MQConsumerInner {
// 消息消费service
private ConsumeMessageService consumeMessageService;
public synchronized void start() throws MQClientException {
switch (this.serviceState) {
case CREATE_JUST:
// ...
// 如果是顺序消费
if (this.getMessageListenerInner() instanceof MessageListenerOrderly) {
// 设置顺序消费标记
this.consumeOrderly = true;
// 创建consumeMessageService,使用的是ConsumeMessageOrderlyService
this.consumeMessageService =
new ConsumeMessageOrderlyService(this, (MessageListenerOrderly) this.getMessageListenerInner());
} else if (this.getMessageListenerInner() instanceof MessageListenerConcurrently) {
this.consumeOrderly = false;
// 并发消费使用ConsumeMessageConcurrentlyService
this.consumeMessageService =
new ConsumeMessageConcurrentlyService(this, (MessageListenerConcurrently) this.getMessageListenerInner());
}
// 启动ConsumeMessageService
this.consumeMessageService.start();
// ...
break;
// ...
}
// ...
}
}
加锁定时任务
进入到ConsumeMessageOrderlyService的start方法中,可以看到,如果是集群模式,会启动一个定时加锁的任务,周期性的对订阅的消息队列进行加锁,具体是通过调用RebalanceImpl的lockAll方法实现的:
public class ConsumeMessageOrderlyService implements ConsumeMessageService {
public void start() {
// 如果是集群模式
if (MessageModel.CLUSTERING.equals(ConsumeMessageOrderlyService.this.defaultMQPushConsumerImpl.messageModel())) {
this.scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
try {
// 周期性的执行加锁方法
ConsumeMessageOrderlyService.this.lockMQPeriodically();
} catch (Throwable e) {
log.error("scheduleAtFixedRate lockMQPeriodically exception", e);
}
}
}, 1000 * 1, ProcessQueue.REBALANCE_LOCK_INTERVAL, TimeUnit.MILLISECONDS);
}
}
public synchronized void lockMQPeriodically() {
if (!this.stopped) {
// 进行加锁
this.defaultMQPushConsumerImpl.getRebalanceImpl().lockAll();
}
}
}
为什么集群模式下需要加锁?
因为广播模式下,消息队列会分配给消费者下的每一个消费者,而在集群模式下,一个消息队列同一时刻只能被同一个消费组下的某一个消费者进行,所以在广播模式下不存在竞争关系,也就不需要对消息队列进行加锁,而在集群模式下,有可能因为负载均衡等原因将某一个消息队列分配到了另外一个消费者中,因此在集群模式下就要加锁,当某个消息队列被锁定时,其他的消费者不能进行消费。
消息队列加锁
在RebalanceImpl的lockAll方法中,首先从处理队列表中获取当前消费者订阅的所有消息队列MessageQueue信息,返回数据是一个MAP,key为broker名称,value为broker下的消息队列,接着对MAP进行遍历,处理每一个broker下的消息队列:
- 获取broker名称,根据broker名称查找broker的相关信息;
- 构建加锁请求,在请求中设置要加锁的消息队列,然后将请求发送给broker,表示要对这些消息队列进行加锁;
- 加锁请求返回的响应结果中包含了加锁成功的消息队列,此时遍历加锁成功的消息队列,将消息队列对应的
ProcessQueue中的locked属性置为true表示该消息队列已加锁成功; - 处理加锁失败的消息队列,如果响应中未包含某个消息队列的信息,表示此消息队列加锁失败,需要将其对应的
ProcessQueue对象中的locked属性置为false表示加锁失败;
public abstract class RebalanceImpl {
public void lockAll() {
// 从处理队列表中获取broker对应的消息队列,key为broker名称,value为broker下的消息队列
HashMap<String, Set<MessageQueue>> brokerMqs = this.buildProcessQueueTableByBrokerName();
// 遍历订阅的消息队列
Iterator<Entry<String, Set<MessageQueue>>> it = brokerMqs.entrySet().iterator();
while (it.hasNext()) {
Entry<String, Set<MessageQueue>> entry = it.next();
// broker名称
final String brokerName = entry.getKey();
// 获取消息队列
final Set<MessageQueue> mqs = entry.getValue();
if (mqs.isEmpty())
continue;
// 根据broker名称获取broker信息
FindBrokerResult findBrokerResult = this.mQClientFactory.findBrokerAddressInSubscribe(brokerName, MixAll.MASTER_ID, true);
if (findBrokerResult != null) {
// 构建加锁请求
LockBatchRequestBody requestBody = new LockBatchRequestBody();
// 设置消费者组
requestBody.setConsumerGroup(this.consumerGroup);
// 设置ID
requestBody.setClientId(this.mQClientFactory.getClientId());
// 设置要加锁的消息队列
requestBody.setMqSet(mqs);
try {
// 批量进行加锁,返回加锁成功的消息队列
Set<MessageQueue> lockOKMQSet =
this.mQClientFactory.getMQClientAPIImpl().lockBatchMQ(findBrokerResult.getBrokerAddr(), requestBody, 1000);
// 遍历加锁成功的队列
for (MessageQueue mq : lockOKMQSet) {
// 从处理队列表中获取对应的处理队列对象
ProcessQueue processQueue = this.processQueueTable.get(mq);
// 如果不为空,设置locked为true表示加锁成功
if (processQueue != null) {
if (!processQueue.isLocked()) {
log.info("the message queue locked OK, Group: {} {}", this.consumerGroup, mq);
}
// 设置加锁成功标记
processQueue.setLocked(true);
processQueue.setLastLockTimestamp(System.currentTimeMillis());
}
}
// 处理加锁失败的消息队列
for (MessageQueue mq : mqs) {
if (!lockOKMQSet.contains(mq)) {
ProcessQueue processQueue = this.processQueueTable.get(mq);
if (processQueue != null) {
// 设置加锁失败标记
processQueue.setLocked(false);
log.warn("the message queue locked Failed, Group: {} {}", this.consumerGroup, mq);
}
}
}
} catch (Exception e) {
log.error("lockBatchMQ exception, " + mqs, e);
}
}
}
}
}
在【RocketMQ】消息的拉取一文中讲到,消费者需要先向Broker发送拉取消息请求,从Broker中拉取消息,拉取消息请求构建在RebalanceImpl的updateProcessQueueTableInRebalance方法中,拉取消息的响应结果处理在PullCallback的onSuccess方法中,接下来看下顺序消费时在这两个过程中是如何处理的。
拉取消息
上面已经知道,在使用顺序消息时,会周期性的对订阅的消息队列进行加锁,不过由于负载均衡等原因,有可能给当前消费者分配新的消息队列,此时可能还未来得及通过定时任务加锁,所以消费者在构建消息拉取请求前会再次进行判断,如果processQueueTable中之前未包含某个消息队列,会先调用lock方法进行加锁,lock方法的实现逻辑与lockAll基本一致,如果加锁成功构建拉取请求进行消息拉取,如果加锁失败,则跳过继续处理下一个消息队列:
public abstract class RebalanceImpl {
private boolean updateProcessQueueTableInRebalance(final String topic, final Set<MessageQueue> mqSet,
final boolean isOrder) {
// ...
List<PullRequest> pullRequestList = new ArrayList<PullRequest>();
// 遍历队列集合
for (MessageQueue mq : mqSet) {
// 如果processQueueTable之前不包含当前的消息队列
if (!this.processQueueTable.containsKey(mq)) {
// 如果是顺序消费,调用lock方法进行加锁,如果加锁失败不往下执行,继续处理下一个消息队列
if (isOrder && !this.lock(mq)) {
log.warn("doRebalance, {}, add a new mq failed, {}, because lock failed", consumerGroup, mq);
continue;
}
// ...
// 如果偏移量大于等于0
if (nextOffset >= 0) {
// 放入处理队列表中
ProcessQueue pre = this.processQueueTable.putIfAbsent(mq, pq);
if (pre != null) {
log.info("doRebalance, {}, mq already exists, {}", consumerGroup, mq);
} else {
// 如果之前不存在,构建PullRequest,之后对请求进行处理,进行消息拉取
log.info("doRebalance, {}, add a new mq, {}", consumerGroup, mq);
PullRequest pullRequest = new PullRequest();
pullRequest.setConsumerGroup(consumerGroup);
pullRequest.setNextOffset(nextOffset);
pullRequest.setMessageQueue(mq);
pullRequest.setProcessQueue(pq);
pullRequestList.add(pullRequest);
changed = true;
}
} else {
log.warn("doRebalance, {}, add new mq failed, {}", consumerGroup, mq);
}
}
}
// 添加消息拉取请求
this.dispatchPullRequest(pullRequestList);
return changed;
}
public boolean lock(final MessageQueue mq) {
// 获取broker信息
FindBrokerResult findBrokerResult = this.mQClientFactory.findBrokerAddressInSubscribe(mq.getBrokerName(), MixAll.MASTER_ID, true);
if (findBrokerResult != null) {
// 构建加锁请求
LockBatchRequestBody requestBody = new LockBatchRequestBody();
requestBody.setConsumerGroup(this.consumerGroup);
requestBody.setClientId(this.mQClientFactory.getClientId());
// 设置要加锁的消息队列
requestBody.getMqSet().add(mq);
try {
// 发送加锁请求
Set<MessageQueue> lockedMq =
this.mQClientFactory.getMQClientAPIImpl().lockBatchMQ(findBrokerResult.getBrokerAddr(), requestBody, 1000);
for (MessageQueue mmqq : lockedMq) {
ProcessQueue processQueue = this.processQueueTable.get(mmqq);
// 如果加锁成功设置成功标记
if (processQueue != null) {
processQueue.setLocked(true);
processQueue.setLastLockTimestamp(System.currentTimeMillis());
}
}
boolean lockOK = lockedMq.contains(mq);
log.info("the message queue lock {}, {} {}",
lockOK ? "OK" : "Failed",
this.consumerGroup,
mq);
return lockOK;
} catch (Exception e) {
log.error("lockBatchMQ exception, " + mq, e);
}
}
return false;
}
}
顺序消息消费
在PullCallback的onSuccess方法中可以看到,如果从Broker拉取到消息,会调用ConsumeMessageService的submitConsumeRequest方法将消息提交到ConsumeMessageService中进行消费:
public class DefaultMQPushConsumerImpl implements MQConsumerInner {
public void pullMessage(final PullRequest pullRequest) {
// ...
// 拉取消息回调函数
PullCallback pullCallback = new PullCallback() {
@Override
public void onSuccess(PullResult pullResult) {
if (pullResult != null) {
// 处理拉取结果
pullResult = DefaultMQPushConsumerImpl.this.pullAPIWrapper.processPullResult(pullRequest.getMessageQueue(), pullResult,
subscriptionData);
// 判断拉取结果
switch (pullResult.getPullStatus()) {
case FOUND:
// ...
// 如果未拉取到消息
if (pullResult.getMsgFoundList() == null || pullResult.getMsgFoundList().isEmpty()) {
// 将拉取请求放入到阻塞队列中再进行一次拉取
DefaultMQPushConsumerImpl.this.executePullRequestImmediately(pullRequest);
} else {
// ...
// 如果拉取到消息,将消息提交到ConsumeMessageService中进行消费
DefaultMQPushConsumerImpl.this.consumeMessageService.submitConsumeRequest(
pullResult.getMsgFoundList(),
processQueue,
pullRequest.getMessageQueue(),
dispatchToConsume);
// ...
}
// ...
}
}
}
};
}
}
前面知道顺序消费时使用的是ConsumeMessageOrderlyService,首先在ConsumeMessageOrderlyService的构造函数中可以看到
初始化了一个消息消费线程池,也就是说顺序消费时也是开启多线程进行消费的:
public class ConsumeMessageOrderlyService implements ConsumeMessageService {
public ConsumeMessageOrderlyService(DefaultMQPushConsumerImpl defaultMQPushConsumerImpl,
MessageListenerOrderly messageListener) {
// ...
// 设置消息消费线程池
this.consumeExecutor = new ThreadPoolExecutor(
this.defaultMQPushConsumer.getConsumeThreadMin(),
this.defaultMQPushConsumer.getConsumeThreadMax(),
1000 * 60,
TimeUnit.MILLISECONDS,
this.consumeRequestQueue,
new ThreadFactoryImpl(consumeThreadPrefix));
this.scheduledExecutorService = Executors.newSingleThreadScheduledExecutor(new ThreadFactoryImpl("ConsumeMessageScheduledThread_"));
}
}
接下来看submitConsumeRequest方法,可以看到构建了ConsumeRequest对象,将拉取的消息提交到了消息消费线程池中进行消费:
public class ConsumeMessageOrderlyService implements ConsumeMessageService {
@Override
public void submitConsumeRequest(
final List<MessageExt> msgs,
final ProcessQueue processQueue,
final MessageQueue messageQueue,
final boolean dispathToConsume) {
if (dispathToConsume) {
// 构建ConsumeRequest
ConsumeRequest consumeRequest = new ConsumeRequest(processQueue, messageQueue);
this.consumeExecutor.submit(consumeRequest);
}
}
}
消费时的消息队列锁
ConsumeRequest是ConsumeMessageOrderlyService的内部类,它有两个成员变量,分别为MessageQueue消息队列和它对应的处理队列ProcessQueue对象。
在run方法中,对消息进行消费,处理逻辑如下:
- 判断
ProcessQueue是否被删除,如果被删除终止处理; - 调用messageQueueLock的ftchLockObject方法获取消息队列的对象锁,然后使用synchronized进行加锁,这里加锁的原因是因为顺序消费使用的是线程池,可以设置多个线程同时进行消费,所以某个线程在进行消息消费的时候要对消息队列加锁,防止其他线程并发消费,破坏消息的顺序性;
- 如果是广播模式、或者当前的消息队列已经加锁成功(Locked置为true)并且加锁时间未过期,开始对拉取的消息进行遍历:
- 如果是集群模式并且消息队列加锁失败,调用tryLockLaterAndReconsume稍后重新进行加锁;
- 如果是集群模式并且消息队列加锁时间已经过期,调用tryLockLaterAndReconsume稍后重新进行加锁;
- 如果当前时间距离开始处理的时间超过了最大消费时间,调用submitConsumeRequestLater稍后重新进行处理;
- 获取批量消费消息个数,从ProcessQueue获取消息内容,如果消息获取不为空,添加消息消费锁,然后调用messageListener的consumeMessage方法进行消息消费;
public class ConsumeMessageOrderlyService implements ConsumeMessageService {
class ConsumeRequest implements Runnable {
private final ProcessQueue processQueue; // 消息队列对应的处理队列
private final MessageQueue messageQueue; // 消息队列
public ConsumeRequest(ProcessQueue processQueue, MessageQueue messageQueue) {
this.processQueue = processQueue;
this.messageQueue = messageQueue;
}
@Override
public void run() {
// 处理队列如果已经被置为删除状态,跳过不进行处理
if (this.processQueue.isDropped()) {
log.warn("run, the message queue not be able to consume, because it's dropped. {}", this.messageQueue);
return;
}
// 获取消息队列的对象锁
final Object objLock = messageQueueLock.fetchLockObject(this.messageQueue);
// 对象消息队列的对象锁加锁
synchronized (objLock) {
// 如果是广播模式、或者当前的消息队列已经加锁成功并且加锁时间未过期
if (MessageModel.BROADCASTING.equals(ConsumeMessageOrderlyService.this.defaultMQPushConsumerImpl.messageModel())
|| (this.processQueue.isLocked() && !this.processQueue.isLockExpired())) {
final long beginTime = System.currentTimeMillis();
for (boolean continueConsume = true; continueConsume; ) {
// 判断processQueue是否删除
if (this.processQueue.isDropped()) {
log.warn("the message queue not be able to consume, because it's dropped. {}", this.messageQueue);
break;
}
// 如果是集群模式并且processQueue的加锁失败
if (MessageModel.CLUSTERING.equals(ConsumeMessageOrderlyService.this.defaultMQPushConsumerImpl.messageModel())
&& !this.processQueue.isLocked()) {
log.warn("the message queue not locked, so consume later, {}", this.messageQueue);
// 稍后进行加锁
ConsumeMessageOrderlyService.this.tryLockLaterAndReconsume(this.messageQueue, this.processQueue, 10);
break;
}
// 如果是集群模式并且消息队列加锁时间已经过期
if (MessageModel.CLUSTERING.equals(ConsumeMessageOrderlyService.this.defaultMQPushConsumerImpl.messageModel())
&& this.processQueue.isLockExpired()) {
log.warn("the message queue lock expired, so consume later, {}", this.messageQueue);
// 稍后进行加锁
ConsumeMessageOrderlyService.this.tryLockLaterAndReconsume(this.messageQueue, this.processQueue, 10);
break;
}
long interval = System.currentTimeMillis() - beginTime;
// 如果当前时间距离开始处理的时间超过了最大消费时间
if (interval > MAX_TIME_CONSUME_CONTINUOUSLY) {
// 稍后重新进行处理
ConsumeMessageOrderlyService.this.submitConsumeRequestLater(processQueue, messageQueue, 10);
break;
}
// 批量消费消息个数
final int consumeBatchSize =
ConsumeMessageOrderlyService.this.defaultMQPushConsumer.getConsumeMessageBatchMaxSize();
// 获取消息内容
List<MessageExt> msgs = this.processQueue.takeMessages(consumeBatchSize);
defaultMQPushConsumerImpl.resetRetryAndNamespace(msgs, defaultMQPushConsumer.getConsumerGroup());
if (!msgs.isEmpty()) {
// ...
try {
// 加消费锁
this.processQueue.getConsumeLock().lock();
if (this.processQueue.isDropped()) {
log.warn("consumeMessage, the message queue not be able to consume, because it's dropped. {}",
this.messageQueue);
break;
}
// 消费消息
status = messageListener.consumeMessage(Collections.unmodifiableList(msgs), context);
} catch (Throwable e) {
log.warn(String.format("consumeMessage exception: %s Group: %s Msgs: %s MQ: %s",
RemotingHelper.exceptionSimpleDesc(e),
ConsumeMessageOrderlyService.this.consumerGroup,
msgs,
messageQueue), e);
hasException = true;
} finally {
// 释放消息消费锁
this.processQueue.getConsumeLock().unlock();
}
// ...
ConsumeMessageOrderlyService.this.getConsumerStatsManager()
.incConsumeRT(ConsumeMessageOrderlyService.this.consumerGroup, messageQueue.getTopic(), consumeRT);
continueConsume = ConsumeMessageOrderlyService.this.processConsumeResult(msgs, status, context, this);
} else {
continueConsume = false;
}
}
} else {
if (this.processQueue.isDropped()) {
log.warn("the message queue not be able to consume, because it's dropped. {}", this.messageQueue);
return;
}
ConsumeMessageOrderlyService.this.tryLockLaterAndReconsume(this.messageQueue, this.processQueue, 100);
}
}
}
}
}
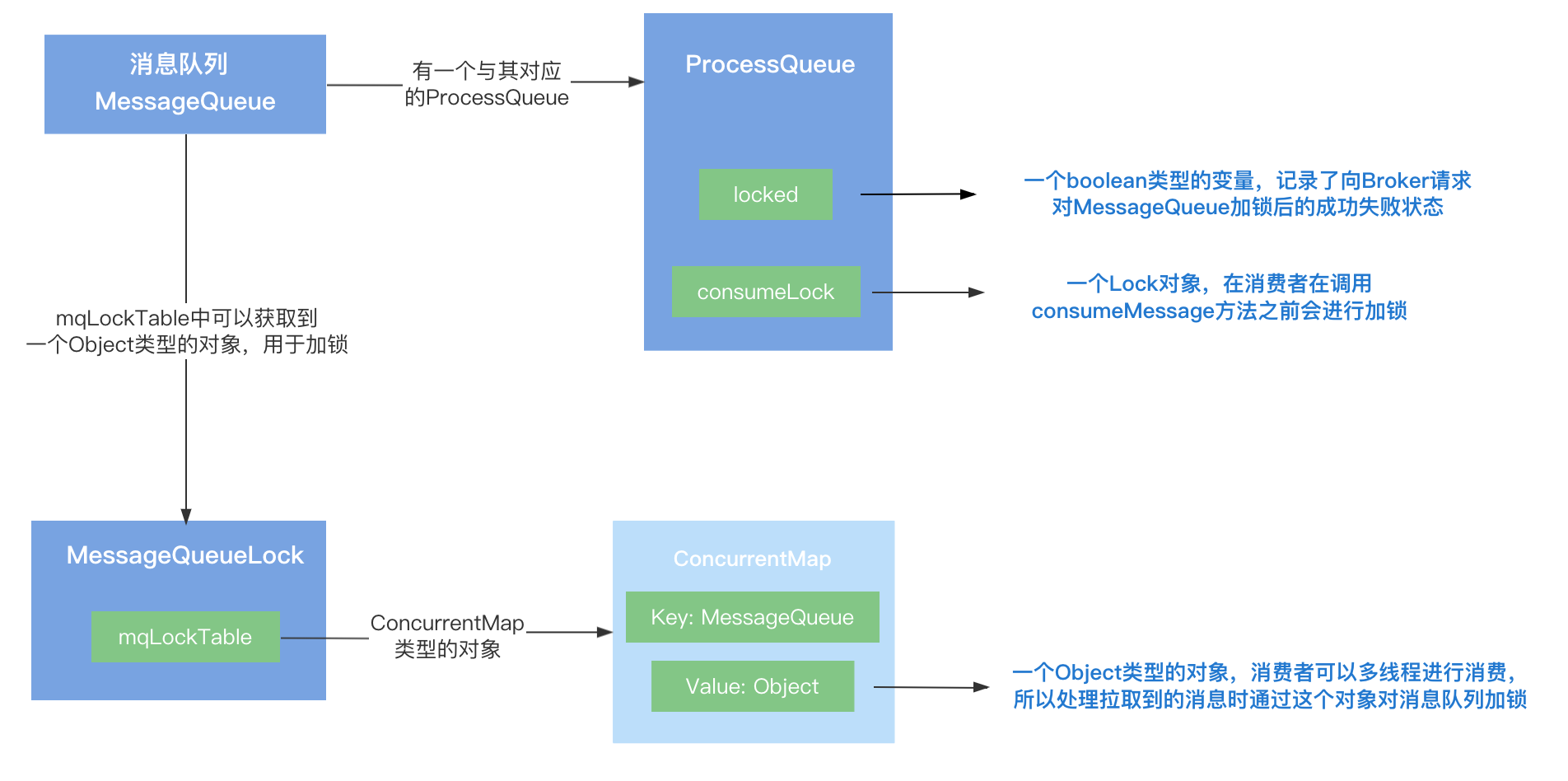
MessageQueueLock中使用了ConcurrentHashMap存储每个消息队列对应的对象锁,对象锁实际上是一个Object类的对象,从Map中获取消息队列的对象锁时,如果对象锁不存在,则新建一个Object对象,并放入Map集合中:
public class MessageQueueLock {
private ConcurrentMap<MessageQueue, Object> mqLockTable =
new ConcurrentHashMap<MessageQueue, Object>();
public Object fetchLockObject(final MessageQueue mq) {
// 获取消息队列对应的对象锁,也就是一个Object类型的对象
Object objLock = this.mqLockTable.get(mq);
// 如果获取尾款
if (null == objLock) {
// 创建对象
objLock = new Object();
// 加入到Map中
Object prevLock = this.mqLockTable.putIfAbsent(mq, objLock);
if (prevLock != null) {
objLock = prevLock;
}
}
return objLock;
}
}
消息消费锁
ProcessQueue中持有一个消息消费锁,消费者调用consumeMessage进行消息前,会添加消费锁,上面已经知道在处理拉取到的消息时就已经调用messageQueueLock的fetchLockObject方法获取消息队列的对象锁然后使用syncronized对其加锁,那么为什么在消费之前还要再加一个消费锁呢?
public class ProcessQueue {
// 消息消费锁
private final Lock consumeLock = new ReentrantLock();
public Lock getConsumeLock() {
return consumeLock;
}
}
这里讲一个小技巧,如果在查看源码的时候对某个方法有疑问,可以查看一下这个方法在哪里被调用了,结合调用处的代码处理逻辑进行猜测。
那么就来看下getConsumeLock在哪里被调用了,可以看到除了C的run方法中调用了之外,RebalancePushImpl中的removeUnnecessaryMessageQueue方法也调用了getConsumeLock方法:
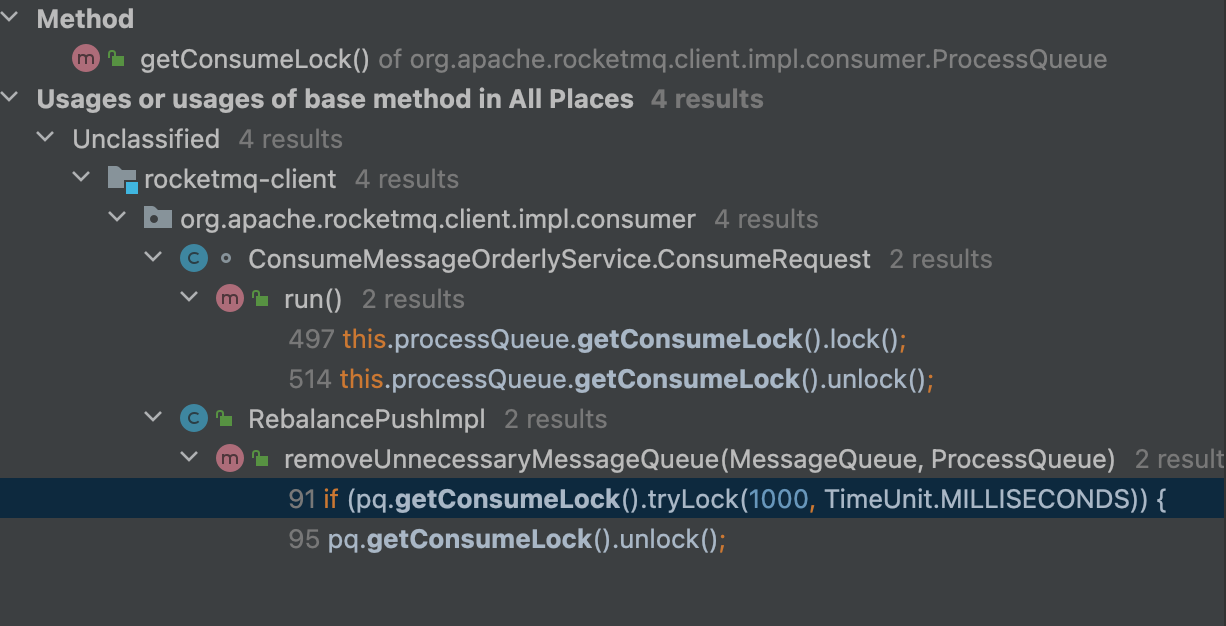
removeUnnecessaryMessageQueue方法从名字上可以看出,是移除不需要的消息队列,RebalancePushImpl是与负载均衡相关的类,所以猜测有可能在负载均衡时,需要移除某个消息队列,那么消费者在进行消费的时候就要获取ProcessQueue的consumeLock进行加锁,防止正在消费的过程中,消费队列被移除:
public class RebalancePushImpl extends RebalanceImpl {
@Override
public boolean removeUnnecessaryMessageQueue(MessageQueue mq, ProcessQueue pq) {
this.defaultMQPushConsumerImpl.getOffsetStore().persist(mq);
this.defaultMQPushConsumerImpl.getOffsetStore().removeOffset(mq);
// 如果是顺序消费并且是集模式
if (this.defaultMQPushConsumerImpl.isConsumeOrderly()
&& MessageModel.CLUSTERING.equals(this.defaultMQPushConsumerImpl.messageModel())) {
try {
// 进行加锁
if (pq.getConsumeLock().tryLock(1000, TimeUnit.MILLISECONDS)) {
try {
return this.unlockDelay(mq, pq);
} finally {
pq.getConsumeLock().unlock();
}
} else {
log.warn("[WRONG]mq is consuming, so can not unlock it, {}. maybe hanged for a while, {}",
mq,
pq.getTryUnlockTimes());
pq.incTryUnlockTimes();
}
} catch (Exception e) {
log.error("removeUnnecessaryMessageQueue Exception", e);
}
return false;
}
return true;
}
}
不过在消费者在消费消息前已经对队列进行了加锁,负载均衡的时候为什么不使用队列锁而要使用消费锁?
这里应该是为了减小锁的粒度,因为消费者在对消息队列加锁后,还进行了一系列的判断,校验都成功之后从处理队列中获取消息内容,之后才开始消费消息,如果负载均衡使用消息队列锁就要等待整个过程完成才有可能加锁成功,这样显然会降低性能,而如果使用消息消费锁,就可以减少等待的时间,并且消费者在进行消息消费前也会判断ProcessQueue是否被移除,所以只要保证consumeMessage方法在执行的过程中,ProcessQueue不被移除即可。
总结
目前一共涉及了三把锁,它们分别对应不同的情况:
向Broker申请的消息队列锁
集群模式下一个消息队列同一时刻只能被同一个消费组下的某一个消费者进行,为了避免负载均衡等原因引起的变动,消费者会向Broker发送请求对消息队列进行加锁,如果加锁成功,记录到消息队列对应的ProcessQueue中的locked变量中,它是boolean类型的:
public class ProcessQueue {
private volatile boolean locked = false;
}
消费者处理拉取消息时的消息队列锁
消费者在处理拉取到的消息时,由于可以开启多线程进行处理,所以处理消息前通过MessageQueueLock中的mqLockTable获取到了消息队列对应的锁,锁住要处理的消息队列,这里加消息队列锁主要是处理多线程之间的竞争:
public class MessageQueueLock {
private ConcurrentMap<MessageQueue, Object> mqLockTable =
new ConcurrentHashMap<MessageQueue, Object>();
消息消费锁
消费者在调用consumeMessage方法之前会加消费锁,主要是为了避免在消费消息时,由于负载均衡等原因,ProcessQueue被删除:
public class ProcessQueue {
private final Lock consumeLock = new ReentrantLock();
}
参考
丁威、周继锋《RocketMQ技术内幕》
RocketMQ版本:4.9.3