项目
redis
安装以及启动
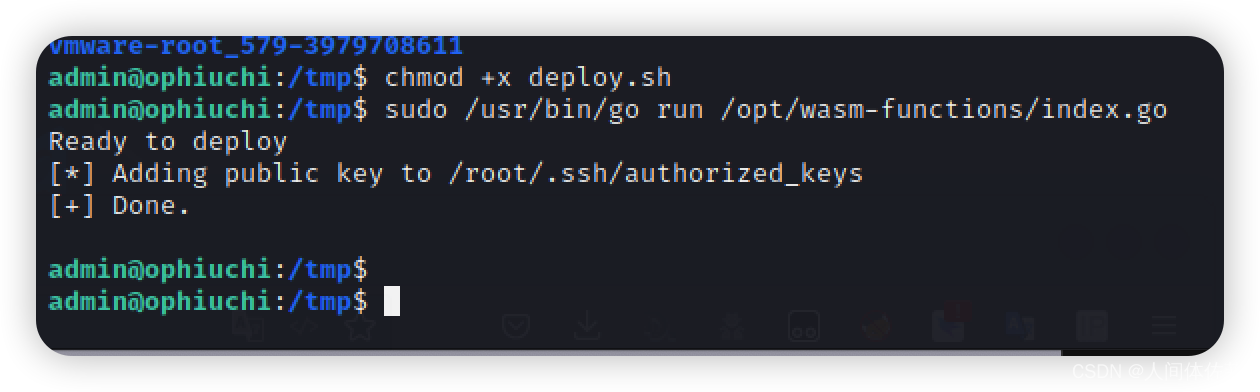
- 切换到redis根目录运行cmd,先启动服务端
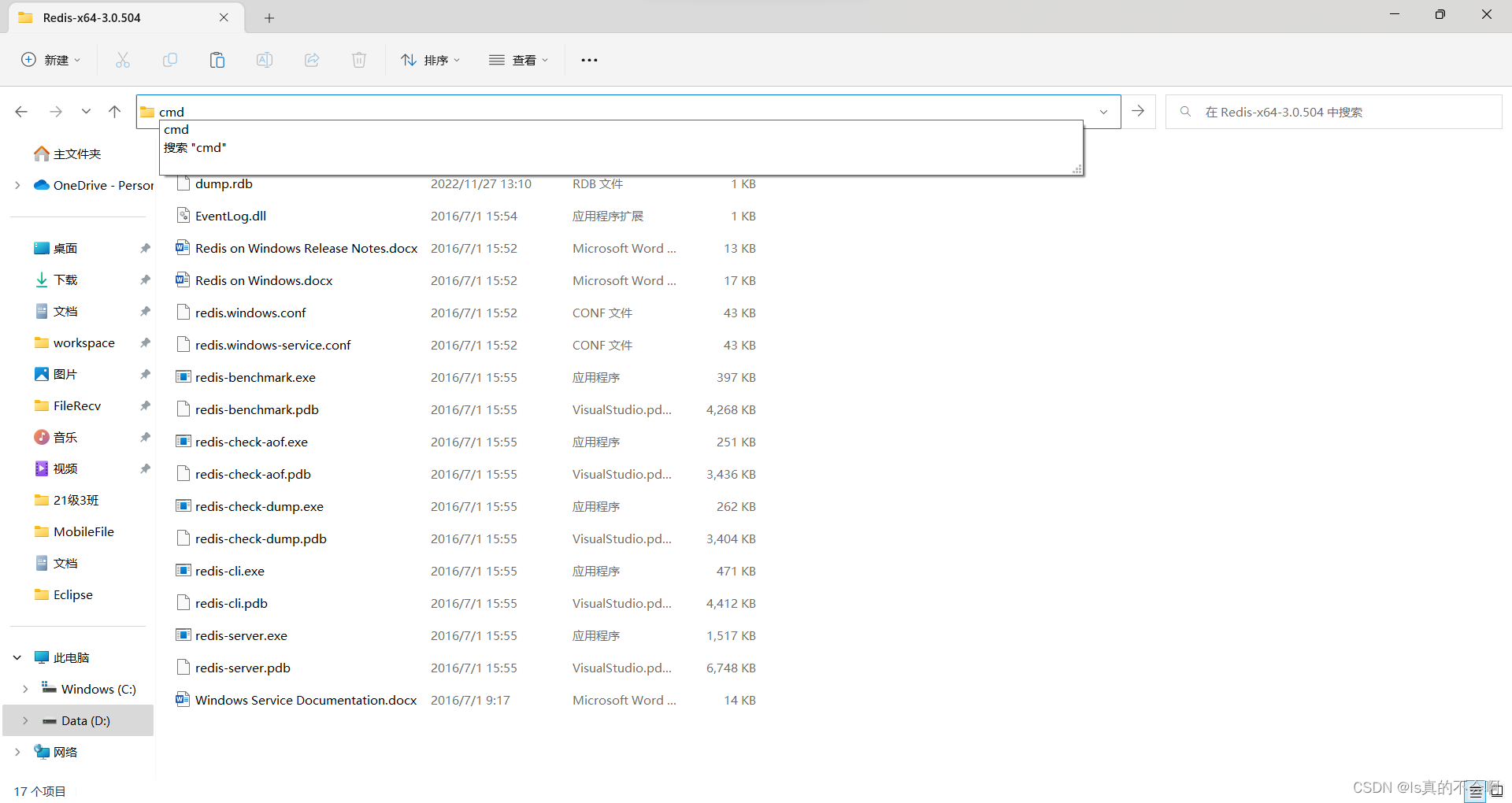
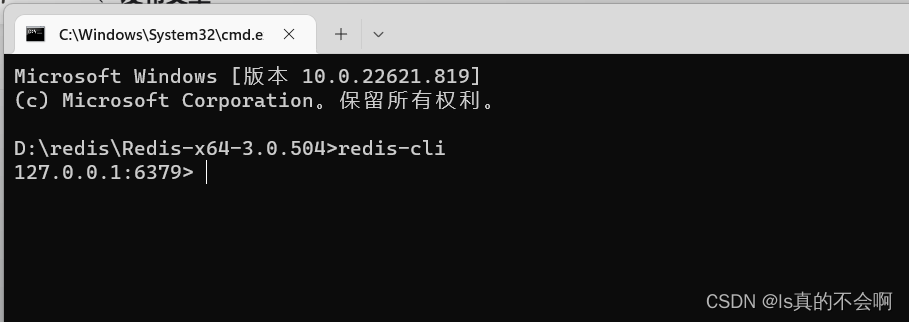
redis-server.exe 2.输入redis-cli并回车(redis-cli是客户端程序)如图正常提示进入,并显示正确端口号,则表示服务已经启动。
基本知识
数据类型
- String: 字符串
- Hash: 散列
- List: 列表
- Set: 集合
- Sorted Set: 有序集合
每种数据类型,分别有对应的操作。
缓存
缓存:数据交换的缓冲区,cache,临时存储数据的地方,性能较高。它有好处,但是要付出一定的成本。
缓存更新策略
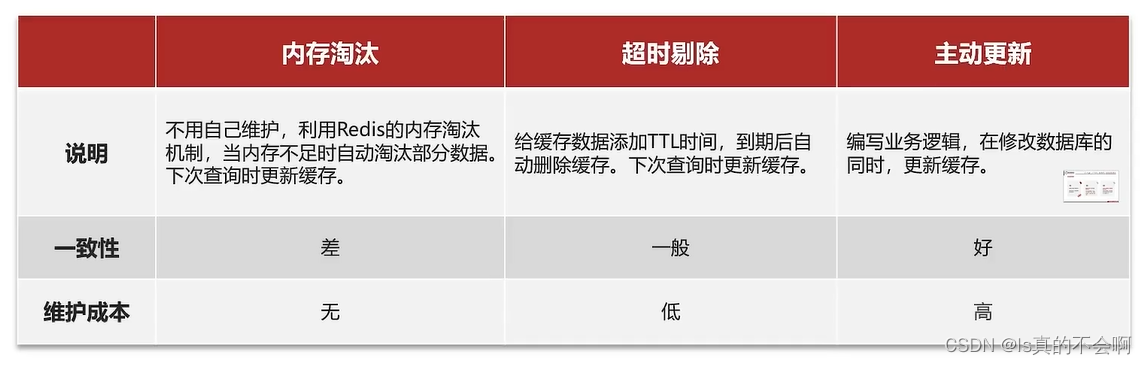 主动更新策略
主动更新策略
- 由缓存的调用者,在更新数据库的同时更新缓存
- 缓存和数据库整合为一个服务,由服务来维护一致性。调用者调用该服务,无需关心缓存一致性的问题
- 调用者只操作缓存,由其他线程异步的将数据持久化到数据库,保持最终一致
删除缓存
缓存穿透:客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库

缓存穿透解决方案:
- 缓存空对象

优点:实现简单,维护方便
缺点:消耗内存,原因:一直往redis存储null,解决:设置null的TTL
可能会造成不一致,原因:当刚往redis存入null时,该值有一个值存入到数据库,解决:缩短TTL时间
- 布隆过滤
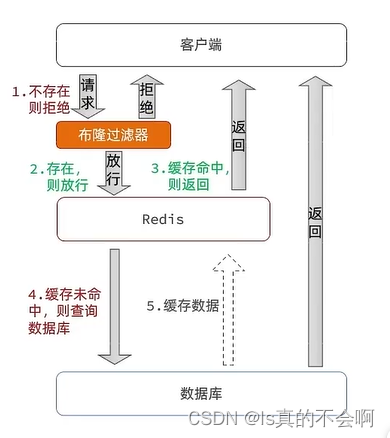
原理:它实际上是一个很长的二进制向量和一系列随机映射函数。主要通过0 1判断一个元素是否在一个集合中。
优点:节省空间
缺点:判断不一定准确
缓存雪崩:同一时段大量的缓存key同时失效或者redis服务器宕机,导致大量请求达到数据库
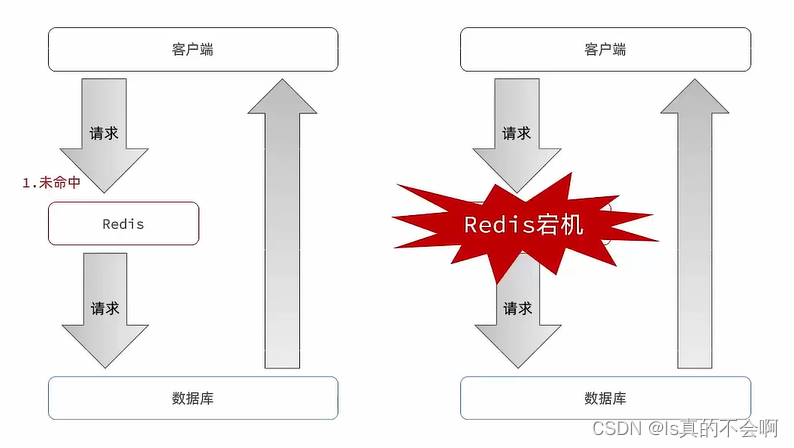
缓存雪崩解决方案:
- 缩短TTL时间
- redis集群
缓存击穿(热点key问题):一个被高并发访问并且缓存重建业务较复杂的key失效了,给数据库带来很大压力。
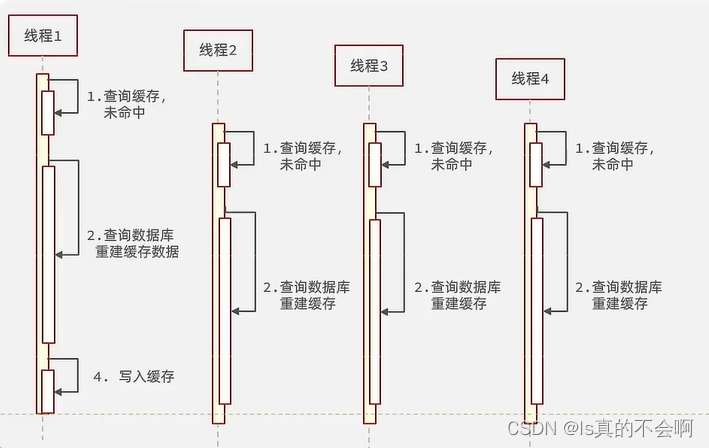
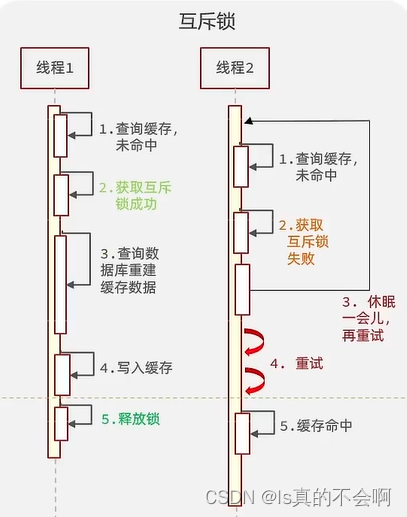
缓存击穿解决方案:
- 互斥锁(性能比较差)
- 逻辑过期(性能较好)

前后端响应的代码进行统一
前面对于每种请求都设置了对应的响应码,现在改成了基本的一个成功、一个失败,如果有业务需要多个的话,就根据业务再进行增加。
public interface ResultCode {
Integer SUCCESS = 20000; //成功
Integer ERROR = 20001; //失败
Integer ERROR_SEND_CODE = 20002;//发生验证码失败
}响应拦截器
axios.interceptors.response.use(success=>{
if(success.status&&success.status==200){
if(success.data.code==2000){
ElMessage.error({message:success.data.message});
return;
}
if(success.data.message){
ElMessage.success({message:success.data.message});
}
}
return success.data;
}, error=>{//接口访问不到
if(error.response.code==504||error.response.code==404){
ElMessage.error({message:'网络忙'})
}else if(error.message.code==403){
ElMessage.error({message:'权限不足'})
}else if(error.message.code==401){
ElMessage.error({message:'尚未登录,请登录'})
router.replace('/login');
}else{
if(error.response.data.message){
ElMessage.error({message:error.response.data.message})
}else{
ElMessage.error({message:'未知错误'})
}
}
return;
})封装发送axios请求的方法
export const postRequest=(url,params)=>{
return axios({
method:'post',
url:url,
data:params
})
}登录注册功能
花了比较长的时间解决报500错误,一开始以为是前端路由问题,最后发现是后端数据库的一个字段类型设置错误。
刷题
11.27
题目来源于2022年蓝桥杯JavaB组,测一下自己用C和Java写题目的差别,事实证明还是C熟悉一点,后面得多练习Java写题目,还有注意格式。
格式:
- 不要使用package语句
- 主类名称为Main
[蓝桥杯2022初赛Java B组] 字符统计
题目描述
给定一个只包含大写字母的字符串S ,请你输出其中出现次数最多的字母。
如果有多个字母均出现了最多次,按字母表顺序依次输出所有这些字母。输入格式
一个只包含大写字母的字符串S。
对于100% 的评测用例,1≤|S|≤10^6。输出格式
若干个大写字母,代表答案。
输入样例
BABBACAC输出样例
AB
思路
遍历字符串,将每个字符串的次数存到数组中,i=s[i]-'A',题目说了只有大写字母,这样的话,比用hashmap做输出更方便,要按字典序输出
代码实现
import java.util.Scanner;
// [蓝桥杯2022初赛] 字符统计
// 样例 BABBACAC
public class CharacterCount {
public static void main(String[] args) {
int[] count=new int[26];//共26个大写字母
for(int i=0;i<26;i++) {//初始化
count[i]=0;
}
Scanner scanner=new Scanner(System.in);
String s=scanner.next();
int max=0;
for(int i=0;i<s.length();i++) {
char t=s.charAt(i);
count[t-'A']++;
if(count[t-'A']>max) {
max=count[t-'A'];
}
}
for(int i=0;i<26;i++) {
if(count[i]==max) {
System.out.print((char)(i + (int)'A'));
}
}
}
}平均播放进度大于60%的视频类别_牛客题霸_牛客网
思路
按标签tag分组,降序排列
难点在于用到多个函数,所以就讲一下这些函数的用处
- concat函数用于将两个字符串连接为一个字符串
-
在mysql中可使用SUBSTRING_INDEX()函数来截取指定字符或字符串的内容;
语法:SUBSTRING_INDEX(str,delim,count)
str是要进行截取的字符串;delim是指定的分割字符或字符串;count是delim在对应str内容中出现的次数,count为正数表示从左至右截取n次之前的所有内容,为负数表示从右至左截取n次之前的内容;
-
round函数就是保留小数的位数
-
avg函数就是求平均值
-
TIMESTAMPDIFF函数,语法 TIMESTAMPDIFF(unit,begin,end);
-
unit参数是确定(end-begin)的结果的单位,表示为整数。 以下是有效单位:MICROSECOND、SECOND、MINUTE、HOUR、DAY、WEEK、MONTH、QUARTER、YEAR
代码实现
select tag,
concat(round(avg(if(TIMESTAMPDIFF(SECOND, start_time, end_time)<duration,TIMESTAMPDIFF(SECOND, start_time, end_time)/duration,1)*100),2),'%') avg_play_progress
from tb_user_video_log a
inner join tb_video_info b
on a.video_id=b.video_id
group by tag
having substring_index(avg_play_progress,'%',1) > 60
order by avg_play_progress desc各个视频的平均完播率_牛客题霸_牛客网
思路
和上面一题一样,也是用到了多个函数,但是相较于上题还是比较简单。
sum(if(表达式,1,0)这样可以计算表达式成立的记录有多少条。
year(时间)获得时间的年份。
代码实现
select a.video_id,
round(sum(if(timestampdiff(second.start_time,end_time)>=duration,1,0))/count(*),3) avg_comp_play_rate
from tb_user_video_log a
inner join tb_video_info b
on a.video_id=b.video_id
where year(start_time)='2021'
group by b.video_id
order by avg_comp_play_rate desc近一个月发布的视频中热度最高的top3视频_牛客题霸_牛客网
思路
难点在于计算热度,也就是计算近一个月无播放的天数。
over()函数又叫做开窗函数,是指在对一些明细数据进行聚合操作时,通过over()函数,对明细数据再次进行分组,然后聚合。
DATE_SUB() 函数从日期减去指定的时间间隔。语法DATE_SUB(date,INTERVAL expr type),
date 参数是合法的日期表达式。expr 参数是要添加的时间间隔,type 参数有很多种类。
代码实现
select a.video_id,
round((100*sum(if(timestampdiff(second,start_time,end_time)>=duration,1,0))/count(*)+5*sum(if_like)
+3*sum(if(comment_id is null,0,1))
+2*sum(if_retweet))/(datediff(max(max(end_time)) over(), max(end_time))+1),0) hot_index
from tb_user_video_log a
inner join tb_video_info b
on a.video_id=b.video_id
where release_time >= date_sub((select max(end_time) from tb_user_video_log), interval 29 day)
group by b.video_id
order by hot_index desc
limit 3