其实在这之前我想了很久,这个线索化二叉树我个人感觉是比实现二叉链表要难,很抽象的一个东西。好了,话先不多说,老规矩,先上代码:
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
typedef int type;
typedef struct leadtree
{
type val;
int ltag;
int rtag;
struct leadtree* left;
struct leadtree* right;
}leadtree;
void creat(leadtree** root);
void leadfront(leadtree** root);
void leadmid(leadtree** root);
void leadback(leadtree** root);
void traversefront(leadtree** root);
void traversemid(leadtree** root);
void traverseback(leadtree** root);#define _CRT_SECURE_NO_WARNINGS 1
#include "leadh.h"
leadtree* pre = NULL;
void creat(leadtree** root)
{
//这里强调一下,这个断言指的传进来的指向根节点的指针,如果都没有指向根节点的指针,就报错
assert(root);
printf("是否要继续生成左孩子还是右孩子->0,1\n");
int ret = 0;
scanf("%d", &ret);
if (0 == ret)
{
*root = NULL;
return;
}
else
{
leadtree* tem = (leadtree*)calloc(1, sizeof(leadtree));
assert(tem);
*root = tem;
printf("请输入你要保存的值->\n");
scanf("%d", &(*root)->val);
creat(&(*root)->left);
creat(&(*root)->right);
}
}
static void visit(leadtree** root)
{
if ((*root)->left == NULL)
{
(*root)->left = pre;
(*root)->ltag = 1;
}
if (pre != NULL && pre->right == NULL)
{
pre->right = *root;
pre->rtag = 1;
}
pre = *root;
}
static void front(leadtree** root)
{
if (*root == NULL)
return;
else
{
visit(root);
if ((*root)->ltag == 0)
front(&(*root)->left);
if ((*root)->rtag == 0)
front(&(*root)->right);
}
}
static void mid(leadtree** root)
{
if (*root == NULL)
return;
else
{
mid(&(*root)->left);
visit(root);
mid(&(*root)->right);
}
}
static void back(leadtree** root)
{
if (*root == NULL)
return;
else
{
back(&(*root)->left);
back(&(*root)->right);
visit(root);
}
}
//前序线索化二叉树
void leadfront(leadtree** root)
{
assert(root);
if (*root == NULL)
return;
else
{
front(root);
pre->rtag = 1;
}
}
//中序线索化二叉树
void leadmid(leadtree** root)
{
assert(root);
if (*root == NULL)
return;
else
{
mid(root);
pre->rtag = 1;
}
}
//后序线索化二叉树
void leadback(leadtree** root)
{
assert(root);
if (*root == NULL)
return;
else
back(root);
}
//前序线索化找后继
static leadtree* next(leadtree** root)
{
if (*root == NULL)
return NULL;
else if ((*root)->rtag == 1)
return (*root)->right;
else
{
if ((*root)->ltag != 1)
{
*root = (*root)->left;
return *root;
}
else
{
*root = (*root)->right;
return *root;
}
}
}
//遍历前序线索化
void traversefront(leadtree** root)
{
if (*root == NULL)
return;
else
{
for (leadtree* tem = *root; tem != NULL; tem = next(&tem))
printf("%d->", tem->val);
}
}
//中序线索化找后继
static leadtree* nextmid(leadtree** root)
{
if (*root == NULL)
return NULL;
else if ((*root)->rtag == 1)
return (*root)->right;
else
{
if ((*root)->rtag != 1)
{
*root = (*root)->right;
while ((*root)->ltag == 0)
*root = (*root)->left;
return *root;
}
}
}
static leadtree* first(leadtree** root)
{
if (*root == NULL)
return NULL;
else
{
if ((*root)->ltag != 1)
{
while ((*root)->ltag == 0)
*root = (*root)->left;
return *root;
}
else
return *root;
}
}
//遍历中序线索化二叉树
void traversemid(leadtree** root)
{
if (*root == NULL)
return;
else
{
for (leadtree* tem = first(root); tem != NULL; tem = nextmid(&tem))
printf("%d->", tem->val);
}
}
//后序线索化二叉树找前驱
static leadtree* prev(leadtree** root)
{
if (*root == NULL)
return NULL;
else if ((*root)->ltag == 1)
return (*root)->left;
else
{
if ((*root)->rtag != 1)
{
*root = (*root)->right;
while ((*root)->rtag == 0)
*root = (*root)->right;
return *root;
}
else
{
*root = (*root)->left;
while ((*root)->rtag == 0)
*root = (*root)->right;
return *root;
}
}
}
//遍历后序线索二叉树
void traverseback(leadtree** root)
{
if (*root == NULL)
return;
else
{
for (leadtree* tem = *root; tem != NULL; tem = prev(&tem))
printf("%d->", tem->val);
}
}#define _CRT_SECURE_NO_WARNINGS 1
#include "leadh.h"
void test1()
{
leadtree* root;
creat(&root);
leadfront(&root);
//leadmid(&root);
//leadback(&root);
traversefront(&root);
//traversemid(&root);
//traverseback(&root);
}
int main()
{
test1();
return 0;
}还是老样子,三个文件,就不一一说了。
我们可以看到的是,线索化二叉树的一个节点比二叉树的一个节点要多两个域,这两个域其实就是标记,线索化二叉树其实说起来很简单,就是利用它的前中后序遍历来边线索化,边边历,听起来也很简单,感觉没什么,但是这个在我们用代码实现的时候就不是这么简单了,因为你一不小心就很造成死循环。
先来看看下面的图:

这个就是手画的线索化完之后的二叉树,手画很简单,就是指针指向他的遍历序列的前驱,后指针指向遍历序列的后继。
现在我们说一下代码实现的思路以及注意事项:
首先,就是头文件,我相信没有什么要说的了。大家应该都是懂的。
其次,就是写函数的那个文件了,我先写的是前序线索化二叉树,但是在这里我先给大家说一下中序线索化二叉树,因为前序线索化二叉树有坑,先说中序线索化二叉树。其实也很简单,就是先遍历左子树,在线索化,线索化完当前的节点之后,在遍历右子树,就是这样。而具体的线索化过程在visit这个函数里面,具体不说了,(左指针一般都是指向前驱,右指针一般都是指向后继) 但是大家仔细的想一下,当我们用前序线索化二叉树的时候就会出现问题。什么问题呢?就是要在遍历他的左右子树之前,要判断一下,是否指向的是自己的子树。如果是,则遍历,如果不是,就不遍历,要不然会造成死循环(下面会详细讲)。
其次就是前序和中序线索化完之后,因为pre这个指针一定在树的最右面的那个节点,所以此时pre->right一定会是NULL,这个是因为我们在创建二叉树的时候,停止生成左右孩子的时候,我们就把这个节点赋值成了NULL,但是在线索化二叉树中,空指针就应该是指向的线索,所以此时我们不要多此一举,直接在他线索化完之后,直接就把他的右标记域改成1就好。
然后很多小伙伴可能有些疑惑,就是为什么这次创建二叉树的时候,为什么开辟空间不用malloc,而用了calloc,这个是因为有了两个标记域,所以一定要把标记与给初始化为0,可能又有些人说,就算不初始化,就算他是“垃圾值”,我们最后线索化的时候就把他改成1了,不影响,但是你仔细想一下,他只能改的是空指针域,那些没有空的指针域怎么办?是不是还是“垃圾值”,这样在遍历线索二叉树的时候怎么办?怎么找他的后继节点?所以,我们就用了calloc来开辟空间,开辟好空间直接就把左右标记赋值为0。
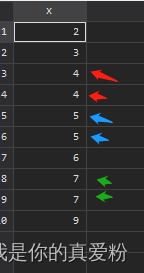
其次就是前序线索化的时候,很多人会疑惑,为什么形成死循环,但是我们用再用他遍历普通的二叉树的时候,为什么就不会形成死循环,来看看下面这幅图:

根据上面的图,我们可以看到,4的直接前驱是2,但是如果在线索化的时候,不根据他的左右标记来判断,就很在4的这里形成死循环,因为此时4指向了2,线索化完4,访问他的左指针域,就直接到了2,所以这样形成了死循环。所以一定要注意这个。中序和后序就没有此问题。
再就是在寻找前驱和后继的时候,前序线索化不好找前驱,后线索化不好找后继,此时就需要重新比那里二叉树来找他的前驱和后继。
以上就是这篇文章的内容,如果对你有用的话,就点一下赞吧!!!!谢谢支持!!