文章目录
- 架构
- 实现
- 默认构造函数
- 构造函数
- 拷贝构造
- 为什么不能使用memcpy()进行拷贝(浅拷贝问题)
- 析构函数
- 赋值重载
- =
- []
- 迭代器
- begin && end
- 操作函数
- size() && capacity()
- push_back()
- reserve()
- resize()
- insert()
- erase()
- 完整代码
架构
首先由于自定义类不能和已有类重名,所以在自定义命名空间中进行vector类的模拟
namespace aiyimu
{
template<class T>//类模板
class vector
{
public:
//迭代器
typedef T* iterator;
typedef const T* const_iterator;
//成员函数
private:
//成员变量
iterator _start;//起始位置
iterator _finish;//所含元素末尾
iterator _endofstorage;//开辟的空间末尾位置
};
}
实现
默认构造函数
构造函数
无参构造函数
无参构造进行成员函数的初始化即可
vector()
:_start(nullptr)
,_finish(nullptr)
,_endofstorage(nullptr)
{}
迭代器构造函数
- 定义模板参数:为了使任意类型的迭代器都能使用
- 将成员变量初始化
- 用while循环遍历迭代器范围[first, last),将范围内的元素逐个插入到vector中,这里使用的
push_back()(尾插函数)后面会进行实现
template <class InputIterator>//定义一个模板参数
vector(InputIterator first, InputIterator last)
:_start(nullptr)
,_finish(nullptr)
,_endofstorage(nullptr)
{
//从first到last构造
while (first != last)
{
push_back(*first);
++first;
}
}
拷贝构造
传统写法*
- new一个大小为
v.capacity()的连续内存空间,将_start指向该空间起始位置,起始位置设置完成,同理更新_finish, _endofstorage (capacity()是返回vector空间大小的函数,后面实现)
vector(const vector<T>& v)
{
_start = new T[v.capacity()];
_finish = _start + v.size();
_endofstorage = _start + capacity();
//memcpy(_start, v._start, v.size() * sizeof(T));
//同reserve()一样,memcpy是浅拷贝,会出现问题
for (size_t i = 0; i < sz; i++)
{
tmp[i] = _start[i];
}
}
现代写法*
- 现代方法 创建了一个临时的vector对象tmp,利用该对象的构造函数和迭代器传入源vector对象v的起始地址和结束地址,构造出一个与v完全相同的新的vector对象tmp。
- 同时利用自定义的
swap()函数进行拷贝操作(将tmp的元素给*this) - 同样避免了浅拷贝问题
void swap(vector<T>& v)
{
std::swap(_start, v._start);
std::swap(_finish, v._finish);
std::swap(_endofstorage, v._endofstorage);
}
vector(const vector<T>& v)
:_start(nullptr)
,_finish(nullptr)
,_endofstorage(nullptr)
{
vector<T> tmp(v.begin(), v.end());;//利用构造函数直接将v构造到临时vector中
swap(tmp);//和this->swap(tmp)相同
}
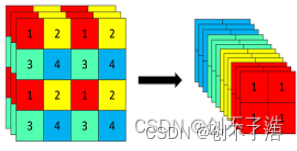
为什么不能使用memcpy()进行拷贝(浅拷贝问题)
为什么不能使用memcpy()?
如果拷贝的是内置类型的元素,memcpy即高效又不会出错;
但如果拷贝的是自定义类型元素,并且自定义类型元素中涉及到资源管理时,就会出错,因为memcpy的拷贝实际是浅拷贝。
具体过程如下图:
当使用memcpy()拷贝后,_start指向v._start所指向的空间,拷贝完后释放原空间,此时_start就变为了野指针。

析构函数
- 如果_start本来为空,不需要进行操作
- 不为空进行:释放_start指向的空间,将成员变量指针置空
~vector()
{
//如果_start不为空,释放空间并置空指针
if (_start)
{
delete[] _start;
_start = _finish = _endofstorage = nullptr;
}
}
赋值重载
- 赋值重载恰好使用拷贝构造函数中的
swap函数直接交换即完成赋值
=
vector<T>& operator=(vector<T> v)
{
swap(v);
return *this;
}
[]
- 访问下标实现const和非const两种,前者不允许用户通过引用修改vector的内容,后者允许。
- 首先用assert断言pos不能越界,然后返回下标即可
const T& operator[](size_t pos) const
{
assert(pos < size());//防止越界
return _start[pos];
}
T& operator[](size_t pos)
{
assert(pos < size());//防止越界
return _start[pos];
}
迭代器
首先我们在类进行了如下操作:分别typedef了两种迭代器(const和非const)
public:
typedef T* iterator;
typedef const T* const_iterator;
begin && end
- 使用迭代器时需要使用头尾位置,所以这里定义const/非const的两种函数,直接返回位置即可
const iterator begin() const
{
return _start;
}
const iterator end() const
{
return _finish;
}
iterator begin()
{
return _start;
}
iterator end()
{
return _finish;
}
操作函数
size() && capacity()
size()和capacity()前面已经进行了使用,是为了访问vector的 大小 和 容量 的- 同样进行const和非const 的实现
//返回此时vector的大小
size_t size()
{
return _finish - _start;
}
//返回此时vector的容量
size_t capacity()
{
return _endofstorage - _start;
}
const size_t size() const
{
return _finish - _start;
}
const size_t capacity() const
{
return _endofstorage - _start;
}
push_back()
法一
- 首先判断增容和进行增容:用 tmp 临时存储大小为 newCapacity 的内存空间,用for循环完成拷贝操作 (第一次增容不需要拷贝,所以有
if(_start)) - 完毕后更新三个指针(_start _finish _endofstorage)
- 但更新时需要注意,_start应该在_finish后更改,因为_start的改变会使size()改变,从而使_finish出问题
- 在尾部插入x,更新_finish
void push_back(const t& x)
{
//判断扩容
if (_finish == _endofstorage)
{
size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;//扩容
t* tmp = new t[newcapacity];
if (_start)//当_start不为空进来(第一次增容不用进)
{
memcpy(tmp, _start, sizeof(t) * size());//将原本存储的数据拷贝到tmp中
delete[] _start;
}
_finish = _start + size();
_start = tmp;//这两行顺序不能变:先赋值_start会改变size()的返回值
_endofstorage = _start + newcapacity;
}
*_finish = x;
++_finish;
}
法二
- 法二在法一的基础上,用sz临时存储size()的值,最后更新_finish直接用sz即可,这样_start的更改顺序不会影响_finish的值
- 其余部分和法一思路一致
void push_back(const T& x)
{
//判断扩容
if (_finish == _endofstorage)
{
size_t newCapacity = capacity() == 0 ? 4 : capacity() * 2;//扩容
T* tmp = new T[newCapacity];
size_t sz = size();
if (_start)//当_start不为空进来(第一次增容不用进)
{
memcpy(tmp, _start, sizeof(T) * size());//将原本存储的数据拷贝到tmp中
delete[] _start;
}
_start = tmp;
_finish = _start + sz;
_endofstorage = _start + newCapacity;
}
*_finish = x;
++_finish;
}
法三
- 当实现了
reserve()(扩容函数)后,直接调用reserve(),再进行插入即可 reserve()下面实现
void push_back(const T& x)
{
//判断扩容
if (_finish == _endofstorage)
{
reserve(capacity() == 0 ? 4 : capacity() * 2);
}
*_finish = x;
++_finish;
}
reserve()
reserve()函数只在 vector 对象中没有足够的内存空间时才会进行内存分配操作,以便预留一定的内存空间,避免频繁的内存分配操作影响程序性能。- 用 tmp 临时存储大小为 n 的内存空间。然后记录目前vector的所有元素个数,用for循环完成拷贝操作 (第一次增容不需要拷贝,所以有
if(_start)) - 最后释放掉原本_start指向的空间并更新_start,_finish,_endofstorage
void reserve(size_t n)
{
//当_finish == _endofstorage时,此时没有多余内存空间,进行增容
if (_finish == _endofstorage)
{
T* tmp = new T[n];
size_t sz = size();
if (_start)//当_start不为空进来(第一次增容不用进)
{
//memcpy是浅拷贝,在一些使用场景中会出现问题
//memcpy(tmp, _start, sizeof(T) * size());//将原本存储的数据拷贝到tmp中
for (size_t i = 0; i < sz; i++)
{
//T是int,一个个拷贝没有问题
//T是string,每次调用=也是深拷贝
tmp[i] = _start[i];
}
delete[] _start;
}
_start = tmp;
_finish = _start + sz;
_endofstorage = _start + n;
}
}
resize()
resize()允许增容+缩容,当 (n<当前大小)时进行缩容,反之扩容- 缩容 直接将_finish指向n的位置即可
- 扩容 首先进行判断,然后将多出的空间全部赋值val (
resize()此时为扩容+初始化)
void resize(size_t n, const T& val = T())
{
//缩小size
if (n < size())
{
_finish = _start + n;
}
//扩大
else
{
//判断增容
if (n > capacity())
{
reserve(n);
}
while (_finish != _start + n)//将多出的空间赋值val
{
*_finish = val;
++_finish;
}
}
}
insert()
insert()- 向任意位置插入字符- 首先断言pos不能越界,随后判断是否需要扩容
- 执行插入步骤:将pos位后的所有元素后移一位,插入pos,++_finish(多一个元素,需要更新大小)
- 返回值类型是 iterator:因为
insert()需要返回一个指向插入的元素的迭代器。最后返回迭代器pos。
iterator insert(iterator pos, const T& x)
{
//防止pos越界
assert(pos >= _start);
assert(pos <= _finish);
//判读扩容
if (_finish == _endofstorage)
{
//扩容后pos会失效,所以在扩容后更新pos
size_t len = pos - _start;
reserve(capacity() == 0 ? 4 : capacity() * 2);
//扩容后更新pos
pos = _start + len;
}
iterator end = _finish - 1;
//将插入位置后面的元素后移
while (end >= pos)
{
*(end + 1) = *end;
--end;
}
*pos = x;//插入元素
++_finish;
return pos;
}
erase()
- erase()和insert()思路相似
- 首先断言防止pos越界,将pos后的所有元素前移一位,最后更新大小(_finish指针的位置)
iterator erase(iterator pos)
{
assert(pos >= _start);
assert(pos <= _finish);
iterator begin = pos + 1;
//将pos位后面的元素前移
while (begin < _finish)
{
*(begin - 1) = *(begin);
++begin;
}
--_finish;
return pos;
}
完整代码
vector的模拟实现