目录
一、摘要
二、介绍
三、相关工作
卷积网络Convolutional networks:
网络中注意力机制Attention mechanisms in networks:
四、方法
1. 图像的自注意力Self-attention over images:
二维位置嵌入Two-dimensional Positional Encodings:
相对位置嵌入Relative positional embeddings:
2. 注意力增强卷积Attention Augmented Convolution:
连接卷积和注意力特征图Concatenating convolutional and attentional feature maps:
参数数量影响Effect on number of parameters:
注意力增强卷积架构Attention Augmented Convolutional Architectures:
五、实验
六、讨论
一、摘要
核心内容:We propose to augment convolutional operators with this self-attention mechanism by concatenating convolutional feature maps with a set of feature maps produced via self-attention.我们提出用这种自注意机制来增强卷积算子,方法是将卷积特征映射与通过自注意产生的一组特征映射连接起来。
卷积操作具有显着的弱点,因为它仅在局部邻域上操作,因此缺少全局信息。Self-attention已经成为捕获远程交互的技术,但主要应用于序列建模和生成建模任务。在本文中,我们考虑将Self-attention用于判别性视觉任务作为卷积的替代。我们引入了一种新颖的二维相对自注意力机制,证明在取代卷积作为独立的图像分类计算原语方面具有竞争力。我们在对照实验中发现,当结合卷积和自注意力时,获得了最好的结果。因此,我们建议通过将卷积特征映射与通过自注意力产生的一组特征映射相结合来增强卷积算子的自注意力机制。
二、介绍
首先了解卷积操作本身两点特性:
局部性:locality via a limited receptive field
等变性:translation equivariance via weight sharing
CNN中的卷积操作中的参数共享使得它对平移操作有等变性,而一些池化操作对平移有近似不变性。
来源:CNN中的translation equivariant和translation invariant_muyuu的博客-CSDN博客
尽管这些属性被证明了是设计在图像上操作的模型时至关重要的归纳偏置(inductive biase)。但是卷积的局部性质(the local nature of the convolutional kernel)阻碍了其捕获全局的上下文信息(global context),而这些信息对于图像识别是很必要的,这是卷积的重要的弱点。(convolution operator is limited by its locality and lack of understandingof global contexts)
归纳偏置:其实就是一种先验知识,一种提前做好的假设。归纳偏置可以理解为,从现实生活中观察到的现象中归纳出一定的规则 (heuristics),然后对模型做一定的约束,从而可以起到 “模型选择” 的作用,类似贝叶斯学习中的 “先验”。例如,深度神经网络就偏好性地认为,层次化处理信息有更好效果;卷积神经网络认为信息具有空间局部性 (Locality),可用滑动卷积共享权重的方式降低参数空间;循环神经网络则将时序信息考虑进来,强调顺序重要性。
来源:归纳偏置 (Inductive Bias) - 知乎 (zhihu.com)
而在捕获长距离交互关系(long range interaction)上,最近的Self-attention表现的很不错(has emerged as a recent advance)。自注意力背后的关键思想是生成从隐藏单元计算的值的加权平均值。不同于卷积操作或者池化操作,这些权重是动态的根据输入特征,通过隐藏单元之间的相似性函数产生的(produced dynamically via a similarity function between hidden units)。因此输入信号之间的交互依赖于信号本身,而不是像在卷积中,被预先由他们的相对位置而决定。
所以本文尝试将自注意力计算应用到卷积操作中,来实现长距离交互。在判别性视觉任务(discriminative visual tasks)中,考虑使用自注意力替换普通的卷积。 引入a novel two-dimensional relative self-attention mechanism, 其在注入(being infused with)相对位置信息的同时可以保持translation equivariance,使其非常适合图像。
在取代卷积作为独立计算单元方面被证明是有竞争力的。但是需要注意的是,在控制实验中发现,将自注意力和卷积组合起来的情况可以获得最好的结果。因此并没有完全抛弃卷积,而是提出使用self-attention mechanism来增强卷积(augment convolutions),即将强调局部性的卷积特征图和基于self-attention产生的能够建模更长距离依赖(capable of modeling longer range dependencies)的特征图拼接来获得最终结果。
在多个实验中,注意力增强卷积都实现了一致的提升,另外对于完全的自注意模型(不用卷积那部分),这可以看作是注意力增强模型的一种特殊情况,在ImageNet上仅比它们的完全卷积结构略差,这表明自注意机制是一种用于图像分类的强大独立的计算原语(a powerful standalone computational primitive)。
相对于现有的方法,这里要提出的结构不依赖于对应的(counterparts)完全卷积模型的预训练,而是整个网络都使用了self-attention mechanism。另外multi-head attention的使用使得模型同时关注空间子空间和特征子空间。 (多头注意力就是将特征划沿着通道划分为不同的组,不同组内进行单独的变换,可以获得更加多样化的特征表达)
另外,为了增强图像上的自注意力的表达能力,这里扩展[Self attention with relative position representations, Music transformer]中的相对自注意力到二维形式, 这使得可以以有原则(in a principled way)地模拟平移等变性(translation equivariance)。
这样的结构可以直接产生额外的特征图,而不是通过加法(可能是乘法)[Non-local neural networks, Self-attention generative adversarial networks]或门控[Squeeze-and-excitation networks, Gather-excite: Exploiting feature context in convolutional neural networks, Bam: bottleneck attention module, Cbam: Convolutional block attention module]重新校准卷积特征。这一特性允许灵活地调整注意力通道的比例,考虑从完全卷积到完全注意模型的一系列架构(a spectrum of architectures, ranging from fully convolutional to fully attentional models)。
 H, W, Fin:输入特征图的height, weight, 通道数 Nh, dv, dk:heads的数量, values的深度(也就是特征图通道数), queries和keys的深度(这几个参数都是MHA, multi-head attention的一些参数), 这里有要求, dv和dk必须可以被Nh整除, 这里使用dhv和dhk来作为每个head中值的深度和查询/键的深度
H, W, Fin:输入特征图的height, weight, 通道数 Nh, dv, dk:heads的数量, values的深度(也就是特征图通道数), queries和keys的深度(这几个参数都是MHA, multi-head attention的一些参数), 这里有要求, dv和dk必须可以被Nh整除, 这里使用dhv和dhk来作为每个head中值的深度和查询/键的深度
三、相关工作
卷积网络Convolutional networks:
现代计算机视觉建立在图像分类任务(如CIFAR-10和imageNet)上学习的强大图像特征上。这些数据集已被用作基准,用于描述更广泛的任务中更好的图像特征和网络架构。例如,改进“骨架”网络通常会导致对象检测和图像分割的改进。这些观察结果激发了新架构的研究和设计,这些架构通常来自跨空间尺度和跳过连接的卷积运算的组合。
网络中注意力机制Attention mechanisms in networks:
作为用于建模序列的计算模块,Attention已被广泛采用,因为其能够捕获长距离交互。self-attention的Transformer架构在机器翻译中实现了最先进的结果。与卷积合作使用self-attention是最近自然语言处理领域工作所共有的主题。
四、方法
1. 图像的自注意力Self-attention over images:
输出tensor的形状为(H,W,Fin),将其展平为(HW,Fin),在最经典的《attention is all you need》文章中,提到了multihead-attention,其中的single head如下:
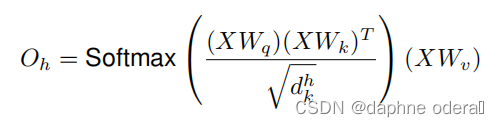
将多个single head结果进行拼接,然后进行线性变换得到最终结果:
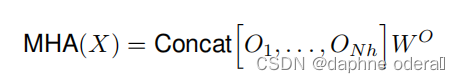
二维位置嵌入Two-dimensional Positional Encodings:
这里的"二维"实际上是相对于原始针对语言的一维信息的结构而言,这里输入的是二维图像数据。
由于没有显式的位置信息的利用,所以自注意力满足交换律:

这里的表示对于像素位置的任意置换。这反映出来self-attention具有 permutation equivariant(置换等变性)。这样的性质使得对于模拟高度结构化的数据(例如图像)而言,不是很有效。
排列不变性(permutation invariance):指输入的顺序改变不会影响输出的值。
排列等变性(permutation equivariant):指输入序列的顺序变化时结果也不同。
多个使用显式的空间信息来增强激活图的位置编码已经被提出来处理相关的问题:
一为Image Transformer,将原始Transformer中引入的正弦波扩展到二维输入;二为CoordConv,将位置通道与激活映射连接到一起。在文章的实验中发现, 在图像分类和目标检测上, 这些编码方法并不好用, 作者们将其归因于虽然这些策略可以打破置换等变性(permutation equivariant), 但是却不能保证图像任务需要的平移等变性(translation equivariance)。为此,作者们提出将[Self attention with relative position representations]扩展到二维中,并提出了一种基于Music Transformer 的高效内存实现方法。
相对位置嵌入Relative positional embeddings:
relative self-attention通过relative position encodings增强了self-attention,并且能够在满足非排列等变的情况下实现平移等变,通过独立添加相关高度信息与相关宽度信息实现二维relative self-attention。

单个头h的输出变成了:

这里的两个都是的矩阵, 表示沿着宽高维度的相对位置logits。

2. 注意力增强卷积Attention Augmented Convolution:
多个先前提出的关于图像的注意力机制表明卷积算子受其局部性和对全局上下文缺乏理解的限制。这些方法通过重新校准卷积特征映射来捕获远程依赖性。特别是,Squeeze-and-Excitation(SE)和GatherExcite(GE)执行通道重新加权,而BAM和CBAM 独立地重新加权通道和空间位置。
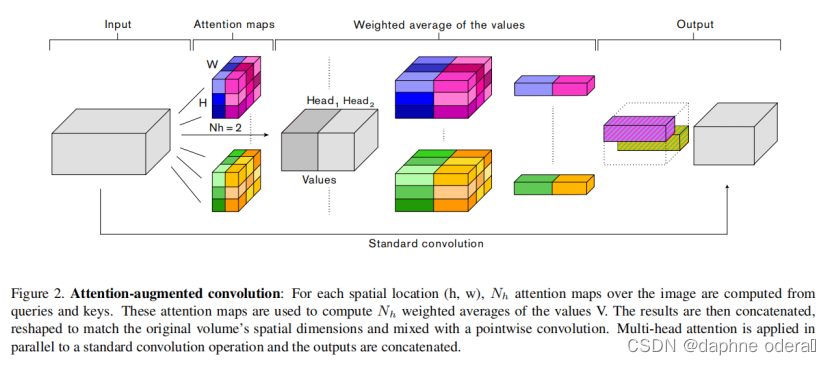
与这些方法相反,我们1)使用注意力机制共同关注空间和特征子空间(每个head对应一个特征子空间)和2)引入额外的特征映射(feature maps)而不是细化精炼它们。图2总结了我们提出的增强卷积。

连接卷积和注意力特征图Concatenating convolutional and attentional feature maps:
将卷积特征映射与self-attention特征映射concat到一起:

与卷积类似,所提出的注意力增强卷积1)对平移是等变的,2)可以很容易地对不同空间维度的输入进行操作。我们在附录A.3中包含了用于提出的注意力增强卷积的Tensorflow代码。
参数数量影响Effect on number of parameters:
为了简单起见,我们忽略了相对位置嵌入引入的参数,因为这些参数可以忽略不计。在实践中,这导致替换3x3卷积时参数略有减少,替换1x1卷积时参数略有增加。有趣的是,我们在实验中发现,注意力增强网络在使用更少参数的情况下,仍然显著优于完全卷积网络。
注意力增强卷积架构Attention Augmented Convolutional Architectures:
所有实验中,AAConv后都会跟着BN来放缩卷积层和注意力层特征图的共享。每个残差块使用一次AAConv。由于QK的结果具有较大的内存占用,所以是按照从深到浅的顺序使用,直到达到内存上限。
五、实验
实验结果总结参考:
用自注意力增强卷积:这是新老两代神经网络的对话(附实现) | 机器之心 (jiqizhixin.com)
六、讨论
在这项工作中,我们考虑使用视觉模型的自我注意作为卷积的替代方案。我们引入了一种新的图像二维相对自注意机制,首次实现了对图像分类的竞争性全自注意视觉模型的训练。我们提出用这种自注意机制来增强卷积算子,并验证了这种方法相对于其他注意方案的优越性。大量的实验表明,注意力增强可以在广泛的架构和计算设置上对图像分类和对象检测任务进行系统改进。
这项工作还有几个悬而未决的问题。在未来的工作中,我们将专注于完全注意机制,并探索不同的注意机制如何在计算效率与表征能力之间进行权衡。例如,确定一个本地注意机制可能会导致一个有效和可扩展的计算机制,可以防止使用平均池的下采样[34]。此外,在完全依赖卷积时非常适合的架构设计选择在使用自注意机制时是次优的,这是合理的。因此,如果在自动架构搜索过程中使用注意力增强(AttentionAugmentation)作为原始元素,可以发现比以前在图像分类[55]、对象检测[12]、图像分割[6]和其他领域[5,1,35,8]中发现的更好的模型,这将是很有趣的。最后,人们可能会问,完全注意力模型在多大程度上可以取代卷积网络来完成视觉任务。
PyTorch 实现地址:
GitHub - leaderj1001/Attention-Augmented-Conv2d: Implementing Attention Augmented Convolutional Networks using Pytorch
笔记参考:
(7条消息) 【阅读笔记】《Attention augmented convolutional networks》-CSDN博客
(7条消息) Attention Augmented Convolutional Networks_风吴痕的博客-CSDN博客
注意力机制之Attention Augmented Convolutional Networks_51CTO博客_注意力机制详解