目录
- 一维张量定义
- 一维实例操作
- 二维张量操作
- 张量拼接-注意需要拼接的维度一定要相同
- 广播机制
- 更高维的演示
- 总结
- YOLOv5 Focus样例
- 参考
梳理一下Pytorch的张量切片操作
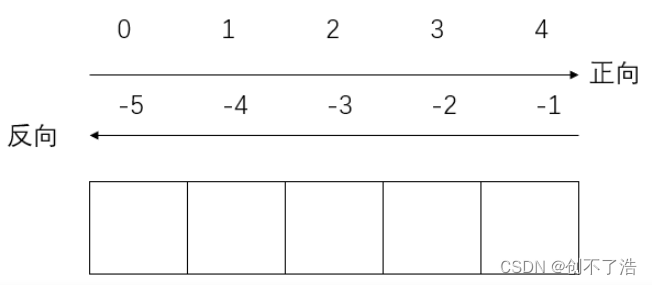
一维张量定义
一维向量的操作其实很像numpy一维数组,基本定义如下:
1.默认步长为1
2.起始索引:结束索引 是一个**左闭右开区[)**间,即结束索引的值不取
3.有反向索引,具体如下:
[起始索引:结束索引:步长]
一维实例操作
import torch
# 创建一个行向量
x=torch.arange(12)
x
#tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
x[-1]
#tensor(11)
x[0]
#tensor(0)
x[0:11:2]
# [起始0:末尾12:步长2](左闭右开)
x[:12:2]
#Out[23]: tensor([ 0, 2, 4, 6, 8, 10])
x[1:12:2]
#Out[24]: tensor([ 1, 3, 5, 7, 9, 11])
x[-4:-1]
#Out[25]: tensor([ 8, 9, 10])
# 取倒数第4-倒数第1(左闭右开)
x[-4:]
#Out[26]: tensor([ 8, 9, 10, 11])
# 5.(注意)pytorch不支持反向获取序列
#注意理解前面的反向索引,反向索引也要正向读取,比如x[-1:-3]也是不行的
# 默认区间
x[:]
x[::]
x[::1]
#以上三种输出都一样: tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
二维张量操作
对于一维向量而言,操作使用冒号:,而对于多维张量,维度与维度之间区分使用逗号,比如对二维张量,x[ , ]。为避免混乱,以下用二维张量演示,可以理解为矩阵。
x=torch.arange(12)
x=x.reshape(3,4)
x=x.reshape(3,-1)#-1 表示自动调整 类似未知数x 3 * x=12 x=4
#tensor([[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11]])
# 获得张量中元素的总数
x.numel()
#Out[7]: 12
x[0]
#tensor([0, 1, 2, 3])
x[1:2] #[左闭右开] 相当于x[1]
#tensor([[4, 5, 6, 7]])
x[1]
#tensor([[4, 5, 6, 7]])
# 没有逗号,在第一维度dim=0操作
x[1:3]
#tensor([[ 4, 5, 6, 7],
# [ 8, 9, 10, 11]])
# 将[1:3)行的元素全部换成5
x[1:3]=5
#tensor([[0, 1, 2, 3],
# [5, 5, 5, 5],
# [5, 5, 5, 5]])
# 有逗号,在dim=0和dim=1上分别操作
# 先取[0:2)行,列上默认(即全选)
x[0:2,:]
#tensor([[0, 1, 2, 3],
# [4, 5, 6, 7]])
#有逗号,按照逗号区分维度间的操作
x[1]
#Out[13]: tensor([4, 5, 6, 7])
x[1,3] #先取第一个维度 再取第一个维度中编号为3的
#Out[15]: tensor(7)
# 有逗号,在dim=0和dim=1上分别操作
x[1:3]
#tensor([[ 4, 5, 6, 7],
# [ 8, 9, 10, 11]])
# 先取[1:3)行,在此基础上取[2:4)列
x[1:3,2:4]
#tensor([[ 6, 7],
# [10, 11]])
# 有逗号,在dim=0和dim=1上分别操作
# 先取[0:2)行,列上默认(即全选)
x[0:2,:]
tensor([[0, 1, 2, 3],
[4, 5, 6, 7]])
# 有逗号,在dim=0和dim=1上分别操作
# 行上默认,列取[-3,-1)列
x
# tensor([[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11]])
x[:,-3:-1]
#tensor([[ 1, 2],
# [ 5, 6],
# [ 9, 10]])
#...的用法:相当于这一维度默认
x[1:...]
#tensor([4, 5, 6, 7])
张量拼接-注意需要拼接的维度一定要相同
# 张量连结
X=torch.arange(12,dtype=torch.float32).reshape((3,4))
#tensor([[ 0., 1., 2., 3.],
# [ 4., 5., 6., 7.],
# [ 8., 9., 10., 11.]])
Y=torch.tensor([[2.0,1,4,3],[1,2,3,4],[4,3,2,1]])
Y.shape
#torch.Size([3, 4])
torch.cat((X,Y),dim=0)#按行拼接
#tensor([[ 0., 1., 2., 3.],
# [ 4., 5., 6., 7.],
# [ 8., 9., 10., 11.],
# [ 2., 1., 4., 3.],
# [ 1., 2., 3., 4.],
# [ 4., 3., 2., 1.]])
torch.cat((X,Y),dim=1)#按列拼接
#tensor([[ 0., 1., 2., 3., 2., 1., 4., 3.],
# [ 4., 5., 6., 7., 1., 2., 3., 4.],
# [ 8., 9., 10., 11., 4., 3., 2., 1.]])
广播机制
a=torch.arange(3).reshape((3,1))
b=torch.arange(2).reshape((1,2))
a,b
#(tensor([[0],
# [1],
# [2]]),
# tensor([[0, 1]]))
# a,b都会先变成3×2矩阵再相加
a变成
# tensor([[0],[0]
# [1],[1]
# [2],[2]])
b变成
# tensor([[0, 1]
# [0, 1]
# [0, 1]])
a+b
#tensor([[0, 1],
# [1, 2],
# [2, 3]])
更高维的演示
# 先随机生成一个三维张量
x=torch.rand(4,3,5)
x
tensor([[[0.3699, 0.1947, 0.6766, 0.5857, 0.2937],
[0.2248, 0.6221, 0.1842, 0.2236, 0.4396],
[0.2535, 0.6115, 0.8398, 0.5736, 0.2702]],
[[0.6308, 0.1010, 0.0042, 0.5904, 0.2101],
[0.7639, 0.8016, 0.8733, 0.4037, 0.7373],
[0.1602, 0.9687, 0.0013, 0.2576, 0.6159]],
[[0.2155, 0.2485, 0.9657, 0.4890, 0.0394],
[0.8007, 0.6122, 0.2834, 0.7095, 0.9711],
[0.5180, 0.8917, 0.0647, 0.6129, 0.7661]],
[[0.9430, 0.1931, 0.3349, 0.0188, 0.1079],
[0.1710, 0.2816, 0.2003, 0.3089, 0.1025],
[0.1610, 0.9168, 0.7699, 0.4525, 0.4716]]])
x[:2,:,2:]
# 取第一维度[0:2),第二维度默认(全取),第三维度[2:]
tensor([[[0.6766, 0.5857, 0.2937],
[0.1842, 0.2236, 0.4396],
[0.8398, 0.5736, 0.2702]],
[[0.0042, 0.5904, 0.2101],
[0.8733, 0.4037, 0.7373],
[0.0013, 0.2576, 0.6159]]])
x[:-2,:,:2]
# 取第一维度[:-2),第二维度默认(全取),第三维度【:2)
x[:-2,:,:2] # 正数最后一行表示-1 ,x[:-2]表示取第一行到倒数第三行
tensor([[[0.3699, 0.1947],
[0.2248, 0.6221],
[0.2535, 0.6115]],
[[0.6308, 0.1010],
[0.7639, 0.8016],
[0.1602, 0.9687]]])
x[:2,:,0:5:2]
# 取第一维度[:2),第二维度默认(全取),第三维度【0:5:2】
x[:2,:,0:5:2]
tensor([[[0.3699, 0.6766, 0.2937],
[0.2248, 0.1842, 0.4396],
[0.2535, 0.8398, 0.2702]],
[[0.6308, 0.0042, 0.2101],
[0.7639, 0.8733, 0.7373],
[0.1602, 0.0013, 0.6159]]])
总结
根据逗号,来区分在哪一维度操作,根据冒号:来看这一维度的切片操作
把握这一句话,然后记住如果是默认那这一维全选就可以了。一般深度学习不会用到五维及以上,所以重点把握三维的各类变换就可以了。
YOLOv5 Focus样例
以yolov5s为例,原始的640 × 640 × 3的图像输入Focus结构,采用切片操作,先变成320 × 320 × 12的特征图,再经过一次卷积操作,最终变成320 × 320 × 32的特征图。切片操作如下:
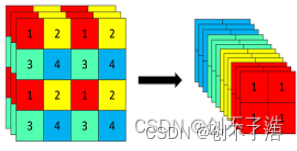
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Focus, self).__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act) # 这里输入通道变成了4倍
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
还不能理解的可以看看这个例子,使用三维的向量,batch维度省略。
x[…, ::2, ::2]这个省略号包括了batch和c两个维度的信息。
x=torch.rand(3,4,4)
x
tensor([[[0.2714, 0.7606, 0.6511, 0.8788],
[0.6301, 0.5507, 0.7287, 0.5045],
[0.6113, 0.1180, 0.6528, 0.0742],
[0.6379, 0.2739, 0.9225, 0.1339]],
[[0.9664, 0.0526, 0.2381, 0.2231],
[0.6880, 0.0968, 0.8737, 0.8241],
[0.8350, 0.7764, 0.9478, 0.2668],
[0.8064, 0.5715, 0.4565, 0.1793]],
[[0.1113, 0.9371, 0.3895, 0.4529],
[0.7409, 0.0787, 0.0074, 0.7480],
[0.7354, 0.7157, 0.3509, 0.5387],
[0.2367, 0.2797, 0.8791, 0.9865]]])
x[…, ::2, ::2] #取每个维度的13行 ,再取13列
tensor([[[0.2714, 0.6511],
[0.6113, 0.6528]],
[[0.9664, 0.2381],
[0.8350, 0.9478]],
[[0.1113, 0.3895],
[0.7354, 0.3509]]])
x[…, ::2, 1::2]#取每个维度的13行,再取24列
tensor([[[0.7606, 0.8788],
[0.1180, 0.0742]],
[[0.0526, 0.2231],
[0.7764, 0.2668]],
[[0.9371, 0.4529],
[0.7157, 0.5387]]])
x[…, 1::2, ::2] #取每个维度的24行再取每个维度的13列
tensor([[[0.6301, 0.7287],
[0.6379, 0.9225]],
[[0.6880, 0.8737],
[0.8064, 0.4565]],
[[0.7409, 0.0074],
[0.2367, 0.8791]]])
x[…, 1::2,1 ::2] #取每个维度的24行再取每个维度的24列
tensor([[[0.5507, 0.5045],
[0.2739, 0.1339]],
[[0.0968, 0.8241],
[0.5715, 0.1793]],
[[0.0787, 0.7480],
[0.2797, 0.9865]]])
参考
Pytorch张量基本、切片操作总结
https://blog.csdn.net/weixin_53111016/article/details/124866683