系列文章目录
作者:i阿极
作者简介:Python领域新星作者:博主个人首页
😊😊😊如果觉得文章不错或能帮助到你学习,可以点赞👍收藏📁评论📒+关注哦!👍👍👍
📜📜📜如果有小伙伴需要数据集和学习交流,文章下方有交流学习区!一起学习进步!💪
| 订阅专栏案例:机器学习 |
|---|
| 机器学习:基于逻辑回归对某银行客户违约预测分析 |
| 机器学习:学习k-近邻(KNN)模型建立、使用和评价 |
| 机器学习:基于支持向量机(SVM)进行人脸识别预测 |
| 决策树算法分析天气、周末和促销活动对销量的影响 |
| 机器学习:线性回归分析女性身高与体重之间的关系 |
| 机器学习:基于主成分分析(PCA)对数据降维 |
| 机器学习:基于朴素贝叶斯对花瓣花萼的宽度和长度分类预测 |
| 机器学习:学习KMeans算法,了解模型创建、使用模型及模型评价 |
| 机器学习:基于神经网络对用户评论情感分析预测 |
| 机器学习:朴素贝叶斯模型算法原理(含实战案例) |
| 机器学习:逻辑回归模型算法原理(附案例实战) |
| 机器学习:基于逻辑回归对优惠券使用情况预测分析 |
文章目录
- 系列文章目录
- 1、实验背景
- 2、实验数据说明
- 3、实验环境
- 4、实验内容
- 5、实验步骤
- 5.1导入数据
- 5.2数据探索
- 5.3处理非数值型变量
- 5.4构造模型
1、实验背景
一家超级市场正在计划年终促销。他们想推出一个新的优惠——黄金会员资格,所有购买的产品都有20%的折扣,只需499美元,其他日子里是999美元。该优惠政策将只对现有客户有效,目前他们正计划通过电话进行宣传。
管理层认为,降低活动成本的最好方法是建立一个预测模型,首先将可能购买该优惠的客户进行分类。
2、实验数据说明
数据信息是在去年的活动中收集的,以下为数据描述:
| 字段 | 说明 |
|---|---|
| Id | 每个客户的独特ID |
| Year_Birth | 客户的年龄 |
| Education | 顾客的教育水平 |
| Marital_Status | 客户的婚姻状况 |
| Income | 客户的家庭年收入 |
| Kidhome | 客户家庭中小孩的数量 |
| Teenhome | 客户家庭中的青少年人数 |
| Dt_Customer | 客户在公司注册的日期 |
| Recency | 自上次购买以来的天数 |
| MntWines | 在过去的两年中,购买葡萄酒产品的金额 |
| MntFruits | 在过去的2年里,购买水果产品的消费金额 |
| MntMeatProducts | 在过去的两年中,花在肉类产品上的金额 |
| MntFishProducts | 在过去的两年中,花在鱼类产品上的金额 |
| MntSweetProducts | 在过去两年中,花在甜食产品上的金额 |
| MntGoldProds | 在过去的两年中,购买黄金产品的消费金额 |
| NumDealsPurchases | 使用折扣购买的数量 |
| NumWebPurchases | 通过公司网站购买的数量 |
| NumCatalogPurchases | 使用目录购买的数量(购买货物通过邮件发送)。 |
| NumStorePurchases | 直接在商店购买的数量 |
| NumWebVisitsMonth | 上个月访问公司网站的次数 |
| Response | 目标变量 - 如果客户在上一次活动中接受了报价,则为1,否则为0 |
| Complain | 如果客户在过去两年中投诉,则为1 |
3、实验环境
Python 3.9
Anaconda
Jupyter Notebook
4、实验内容
使用逻辑回归对超市销售活动预测分析
5、实验步骤
5.1导入数据
import pandas as pd
import numpy as np
data = pd.read_csv("/home/mw/superstore_data.csv")
data.head()

5.2数据探索
查看数据数量
data.shape
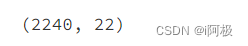
有2240行,22个特征值
查看基本信息
data.info()
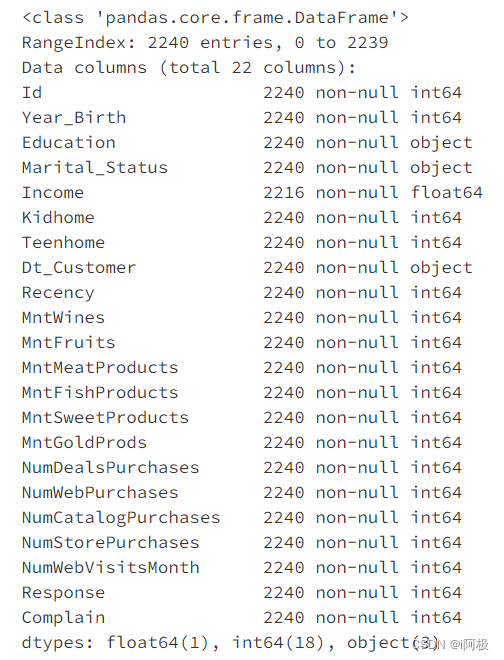
发现Income列有缺失值,接下来需要对缺失值进行处理
观察Income列缺失的行
income_missing = data[data.Income.isnull()]
income_missing
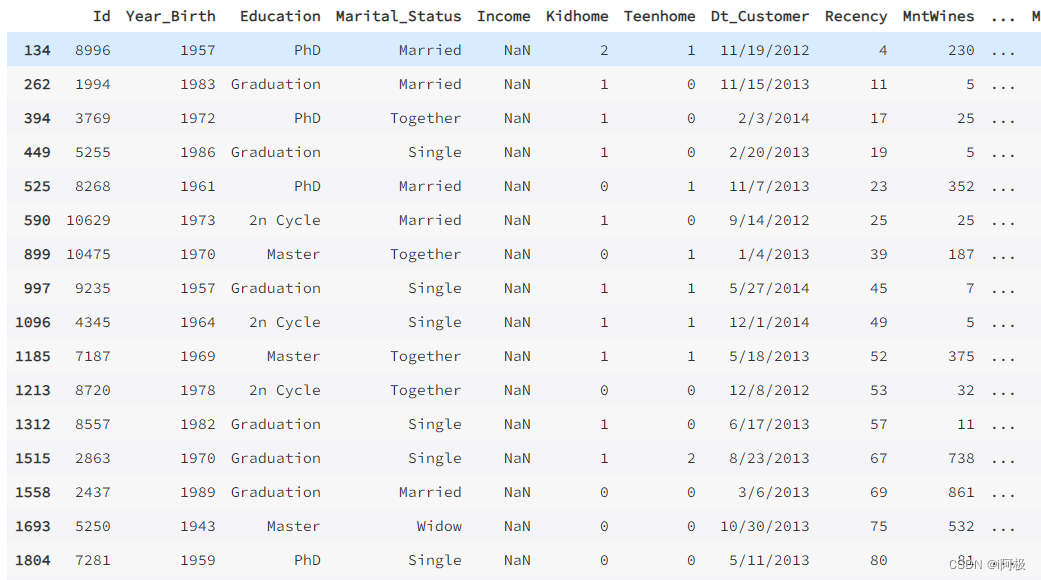
从他们的Year_Birth中发现,很多都是1960年之前的人,很有可能退休了(2023-65=1958)
before = income_missing[income_missing.Year_Birth < 1961]
after = income_missing[income_missing.Year_Birth > 1961]
import matplotlib.pyplot as plt
plt.bar(['before 1961','after 1961'],[len(before),len(after)])
plt.show()
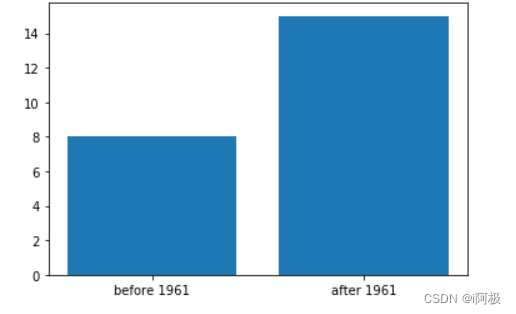
对于可能退休的人(小于1961)我们用0填充,其他的用平均值
data.loc[(data['Year_Birth'] < 1961) & (data['Income'].isnull())] =data.loc[(data['Year_Birth'] < 1961) & (data['Income'].isnull())].fillna(0)
data.Income = data.Income.fillna(data.Income.mean())
data.isnull().sum()
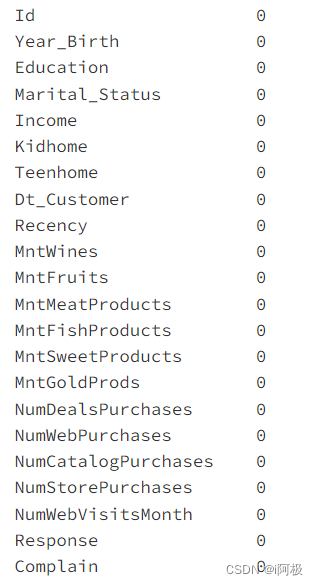
对于可能退休的人(小于1961)我们用0填充,其他的用平均值,已经没有缺失值。
5.3处理非数值型变量
查看类型为object的列
non_num_cols = [cols for cols in data.columns if data[cols].dtype == 'object']
non_num_cols

首先我们将Dt_Customer转化为日期格式
data['Dt_Customer'] = pd.to_datetime(data['Dt_Customer'])
处理类别变量,先来看看有几种类别
data.Education.value_counts()

data.Marital_Status.value_counts()
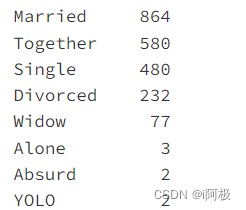
因为alone、YOLO、Abusurd样本数很少,所以本次分析将 alone、YOLO、Abusurd 统一归为 Single。
data.Marital_Status = data.Marital_Status.replace(['Alone','YOLO','Absurd'],'Single')
data.Marital_Status.value_counts()

Marital_Status = pd.get_dummies(data.Marital_Status,prefix='Marital_Status')
data = data.drop('Marital_Status',axis=1).join(Marital_Status)
同理应用于教育状况
Education = pd.get_dummies(data.Education,prefix='Education')
data = data.drop('Education',axis=1).join(Education)
data
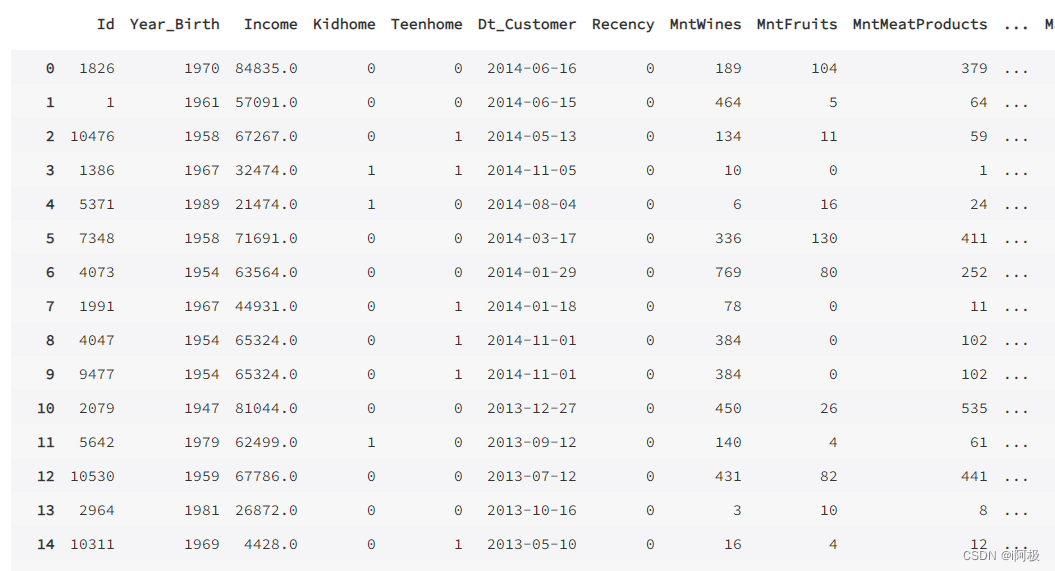
再来看看处理之后的特征值
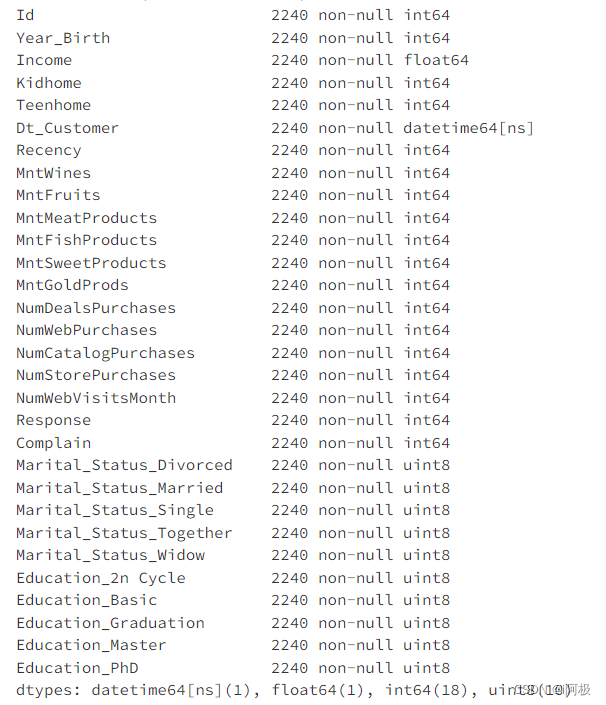
data.info()
5.4构造模型
划分训练集和测试集
from sklearn.model_selection import train_test_split
y = data.Response #目标变量
X = data.drop('Response',axis=1)
train_x,val_x,train_y,val_y = train_test_split(X,y,train_size=0.8,test_size=0.2,random_state=0)
用统计的方法看看相关性
cor = data.corr()
features = cor[(cor['Response'] < -0.1) | (cor['Response'] > 0.1)] .index.drop('Response')
模型搭建
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(train_x[features],train_y)
验证
prey = lr.predict(val_x[features])
from sklearn.metrics import accuracy_score
accuracy_score(val_y,prey)
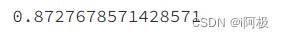
开始预测
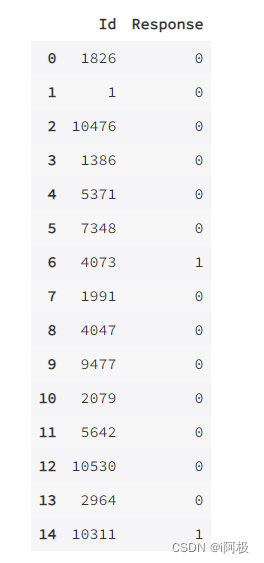
predictions = lr.predict(data[features])
results = pd.DataFrame(data={'Id':data.Id,'Response':predictions})
results[:15]
📢文章下方有交流学习区!一起学习进步!💪💪💪
📢创作不易,如果觉得文章不错,可以点赞👍收藏📁评论📒
📢你的支持和鼓励是我创作的动力❗❗❗