分享嘉宾 | 刘焕勇
文稿整理 | William
1、从大规模语言模型看ChatGPT的起源与本质
ChatGPT可以拆开分为Chat和GPT去理解,前一个表示一种应用形式,后一个是生成式的模型。在百度百科里面定义为ChatGPT是人工智能技术驱动的自然语言处理工具,它能通过学习和理解人类的语言来进行对话,还能根据聊天的上下文进行互动,真正像人类一样来聊天和交流,甚至能写一些邮件、视频脚本、文案、翻译、代码、写论文等一些任务。目前大家都是在做解读和一些猜测,并没有官方的报告或论文等。这里的一些关键名词需要先理解一下:

图1 关键名词
ChatGPT的本质上是一个在GPT基础上的自然语言处理模型,使用transformer去预测下一个单词的概率分布,然后在大规模的文本语料库上去学习这样的模式。从GPT1到GPT3的智能化是不断的在提升,当时GPT1只有1.17亿参数,然后GPT2就变成15亿参数,到GPT3就到了1750亿,一直到后面开始去做指令的微调,因为生成的质量有时并不是特别好,让它尽量符合600H的一个准则,即去学更多的技能,通过反馈学习去提升它的结果。
整个ChatGPT的发展变化,整个上是transformer系列的变化。从1950年开始做NLP任务时是基于规则的少量数据处理,然后是机器学习去根据一定范围的数据进行参数分类,在后面就是用CNN这种模型去做编码来表示特征,再后来发现多头注意力的编码能力明显是强于神经网络,然后分裂成三条路线:一是GPT系列,基本上是一年一个迭代,二是T5,第三则是BERT。目前两个主流的如图2所示,两个架构不一样的只在于输入层,每一个只跟前面有关系,这样可以完全的捕获到上下文信息,更容易去做理解方面。
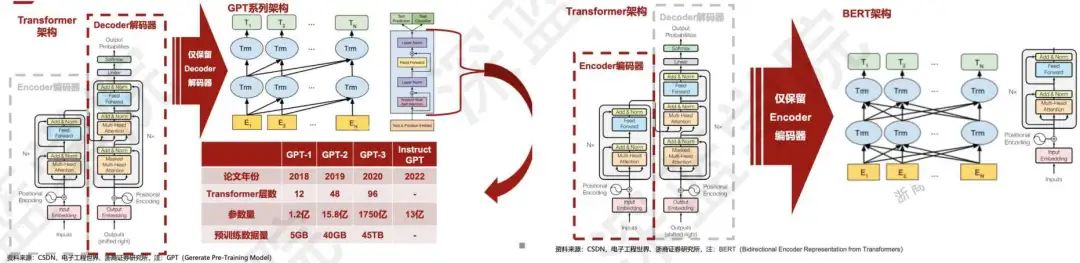
图2 两种主流架构
当大家去体验ChatGPT的时候,它内部的工作原理是一个比较的方式,比如让ChatGPT写篇文章,它本质上是重复对于当前文本下一个单词应该是什么并计算概率最大的一个的方式,最终去完成任务。所以这其实是一个概率在控制,但这个概率本质是个语言模型在控制,
根本就不知道自己写的是什么,只是很自信的认为后面接的那个词跟前面的概率是最大的,
所以这就导致了可以看到现在的ChatGPT一本正经的胡说八道。
先看一下GPT系列的GPT1,它其实是通用多任务预训练去开创了一个微调的范式。相比于transformer是做了显著的变化,第一方面是仅训练了一个12层的decoder解码器,第二是相比于google的BERT,它其实只用了上文的预测,不会看到上下文信息。所以仅仅使用了decoder部分,其结构足够简单,能够较好的进行语言理解,适用于文本生成领域,但是在通用语言和会话交流方面存在较大的缺陷。
GPT2在GPT1的基础上做了很多的改进,第一个是信息来源更多了,把整个数据流的数据扩成了40G,第二个是层数增加到48层,隐藏层的维度升到1600,实现了15亿的参数量,第三是不再针对不同的任务建模去做微调,只建模成一个分类任务。但是也会存在一些问题,首先是从实用角度上来说,每一项新任务都需要标记的大数据,这会限制住了语言模型的适用性,第二个方面是在预训练和微调的方式中,泛化能力会比较差,第三个是因为人类学习当中不需要大型监督数据集,所以目前在这个概念上其实有一定的局限性。
GPT3为了解决这些问题,利用了in-context learning的思想,让模型能够取得更好的效果,然后做了更多的数据,直接把参数拉到了175B的规模。
2、ChatGPT的若干关键技术问题、开源项目和实现挑战
2.1 ChatGPT的核心算法与核心数据
在Instruct-GPT的里面加入了人的反馈去引导,那为什么需要添加这个反馈?因为目前GPT3是存在一些问题,包括生成的质量参差不齐、容易产生一些语言通顺但是无用甚至有害的结果以及zero-shot的理解能力不佳。但是单纯增大语言模型的规模并不能解决这些问题,因此需要人类反馈的强化学习去进行微调。
微调包括这些步骤:首先给定一些微调的数据,然后训练奖励模型,再增强学习优化STF并迭代。不过人的反馈有很多的方式,第一个是标注要的prompt,另外一个是让模型去给生成结果的质量排序,然后用增强学习的方式引导模型向更好的方向。
Instruct-GPT是基于人类反馈的强化学习进行训练,图3十分清楚的展示了整个过程,这里主要有三个阶段:第一阶段是冷启动的策略模型,随机抽取用户提交的指令或问题(即prompt),然后做人工标注,用这些指定的prompt和高质量回答共同微调GPT3模型,使之尽可能去拟合生成一个模型;第二阶段是训练奖励阶段,对模型预训练的输出结果进行评分,分值越高,回答质量越好;第三个阶段是采用强化学习进行增强预训练模型能力,相当于是根据得分反馈给原先的STF里,让模型生成更高质量的回答。
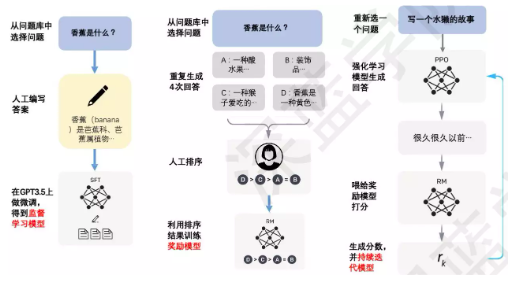
图3 Instruct-GPT流程
SFT监督学习作为GPT里面的一个核心算法,主要是收集人工编写的期望模型如何输出的数据集,使其来训练一个生成模型。所使用的数据是一对prompt和answer,这个数据集的收集一部分是来自使用openAI的用户,另外一方面会来自于openAI内部的一些工程师自己写以及雇佣的标注者。其实如果大家去做这个事情,有几条路可选,首先是可以收集百度知道或论坛里面的数据,但是需要你去仔细筛选,第二是公司内部的一些人针对代码的一些知识和要求,第三个最不最不经济的方式就是去雇佣一些人去弄数据集。,
另外一个核心算法是奖励模型,其实是收集人工标注的模型多个输出之间的排序数据集。使用微调模型SFT进行预测,对输出得到N个结果,将排序后的数据用来训练奖励模型,其损失函数也是根据人工选择的结果进行计算pair-wise loss。具体的步骤:第一步先生成一个SFT模型,为每一个prompt随机生成K个候选,第二步是任选两个候选并与prompt组成元组,对一个prompt的K个candidates,进行C(K,2)拓展,产生更多标注数据;第三步是根据质量对两个候选进行排序打分;第四步是把生成的C(K,2)组训练数据作为一个batch送入RM模型进行pair- wise训练。由于损失函数输入是元组,输出是两个候选奖励的差值得sigmoid再去log,所以可看为是一个回归模型。
后面一个核心算法是PPO强化学习,即使用奖励模型作为奖励函数,以PPO的方式进行微调监督学习生成的模型,其每一步都计算和第一步训练出来的生成模型之间的KL散度,目标是希望不用强化学习来偏离最开始的生成模型,损失函数如下:
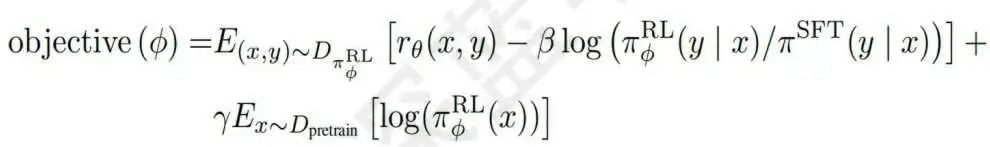
其具体步骤有:第一步是由微调后得SFT模型来初始化PPO策略模型,由生成得RM模型初始化价值函数。第二步是从PPO数据集中随机采样一个prompt,并通过第一步的PPO策略模型生成输出结果;第三步是对prompt和结果,带入RM模型计算奖励值reward;第四步是利用reward来更新PPO策略模型参数。最后是重复第2到第4步,直至PPO策略模型收敛
接下来讲讲训练数据中的一些问题,GPT3是在共计300B的token上进行训练的,其中60%来源于common crawl,其他包括webtext2,books1,books2和维基百科。但并不是数据上的东西越多越好,它更倾向于数据的质量,质量比较高的话,效果也会不错。所以去做GPT3训练数据的时候,有一套数据工程方面的工作,包括分类数据,怎么洗数据,怎么去取数据三个阶段。另外一个是数据集进行去重,去重有助于避免预训练模型多次面对相同的数据后记住它们或者在其上过拟合,因此有助于提高模型的泛化能力。还有另外是在多样性上,包括领域多样性、格式多样性和语言多样性,尽可能的包含各种数据。
GPT3训练数据有一个加工清洗的过程,第一个是去根据与一系列高质量参考语料库的相似度比较,从而过滤出的爬虫数据,另外一个是通过对数据集内部和跨数据集的文档上执行重复数据的删除,最终是将已知的高质量参考语料库添加到训练组合中,以增强数据集的多样性。
清洗完之后的分布如图4所示。

图4 训练GPT3的数据集分布
既然中文在GPT3语调的占比并不怎么高的情况下,为什么在中文上表现出来的效果会比国内的一些大模型要好?由此引出来的问题是GPT的跨语种能力是如何习得?从官方公布的PPT数据可以看到,中文只在文档数量上占了0.12%,对于整个的词来说,就占了0.1%,所以说是不是意味着英文里边的很多东西已经记录的比较好了,然后在训练的时候这个模型内部已经自动的做翻译上的对齐操作,当然这只是一个猜想。
第二个是它的表格绘制能力,去用GPT的时候,通过debug可以发现底下的东西是用markdown来编写,如果用这个code的话,从源码可以发现他会用一些官方的注释或者函数的一些定义来作为一个question,这个answer可能就是一个个的函数题,然后这样可以生成大量的数据集,再去做训练。
另外一个比较核心的在于RLFH数据构建,第一个是严控标注人群的质量,第二个是标注数据来源,这个数据包括三种类型的数据,首先是人工撰写,包含随便想一些prompts,同时尽可能地保证任务的多样性,其次是它不仅仅需要写一些prompts,还需要写对应的answer;第三个是要根据一个use case进行设计。然后标注的标准上有三个:有用、真实和无害。在标注时是标了三个数据集,一个是SFT数据集,只有13K左右,另一个是RM数据,主要是真实地prompt,有33K左右,最后一个是PPO数据集,完全都是真实地prompt,根据不同用户提供的10种不同种类的生成任务而来,总共有31K。
2.2 ChatGPT的算力、团队与技术若干思考
可能大家都会去想ChatGPT到底要花多少钱?之前国盛证券发了个报告,ChatGPT训练一次的成本大约是140万美元,对于一些更大的模型的话,可能就需要200万美元到1200万美元之间。以 ChatGPT 在 1 月的独立访客平均数 1300 万计算,其对应芯片需求为 3 万多片英伟达 A100 GPU,初始投入成本约为 8 亿美元,每日电费在 5 万美元左右。如果将当前的 ChatGPT 部署到谷歌进行的每次搜索中,需要 512820.51 台 A100 HGX 服务器和总共4102568 个A100 GPU,这些服务器和网络的总成本仅资本支出就超过 1000 亿美元。数据侧的数据整理、清洗、人工标注等一系列工程化过程也需要极大投入。
其背后的openAI团队是全球AI的领军企业,还在其他一些多模态的任务上也有产品。OpenAI成立于 2015年底,组织目标是通过与其他机构和研究者 的“自由合作”,向公众开放专利和研究成果。2019年,OpenAI从非营利机构转型为“有上限” 的营利性机构,利润上限为任何投资的100倍。
再看看ChatGPT为什么有效?首先是指令微调的价值,它不会为模型注入新的能力,即模型质量如何直接就决定了ChatGPT的结果,第二个点是会分化成不同的技能树,比如上下文学习,对话等。然后响应人类指令的能力也是指令微调的一个产物。再说模型的溯源,包括语言生成能力,基础世界知识和上下文学习都来自于预训练模型。 另外会遵循指令和泛化到新任务的能力来自于扩大指令学习中指令的数量,此外模型执行复杂推理的能力很可能来自于代码训练。
为啥不是Chat-BERT? BERT的这种AE(Auto Encoder)配合Mask LM的预训练任务,虽然能够更好的看到上文和下文,但是同样有train和inference时的差距,由于AR架构非常符合人类的思考和回复的过程,符合“第一性原理,且能够回答的问题很丰富。
InstructGPT带来了一些增益,首先是它的效果会更加真实,然后无害性上会有些提升,同时具有很强大的coding能力。当然也存在一些缺点,首先是会降低模型在通用NLP任务上的效果,第二是会给出一些荒谬的输出,因为影响模型效果最大的还是有监督的语言模型任务,人类只是起到了纠正作用,所以很有可能受限于纠正数据的有限,导致生成内容的不真实。第三个是对指标非常敏感,这个主要归结为labeler标注的数据量不够。第四个是对简单概念的过分解读,可能是因为labeler在进行生成内容的比较时,倾向于给更长的输出内容更高的奖励。最后一点是对有害的指示可能会输出有害的答复。
Chat-GPT后期改进的方向主要有三个:首先是人工标注的降本增效,如何让人类能够提供更有效的反馈方式,将人类表现和模型表现有机和巧妙的结合起来是非常重要的。第二点是模型对指示的泛化、纠错等能力,如何提升模型对指示的泛化能力以及对错误指示的纠错能力是提升模型体验的一个非常重要的工作。第三点是避免通用任务性能下降,这里可能需要设计一个更合理的人类反馈的使用方式,或是更前沿的模型结构。
其实刚才除开提到的这些问题,现在最不满意的是时效性和准确性,直接就导致了胡说八道,Bing随后出来在一定程度上解决了这个问题,他怎么去解决?第一个点,它会融合必应的搜索,拿到所有相关的答案后进行聚合,做一些摘要和排序;第二种方式是解决时效性,快速搜索到当前发布的问题。
2.3 ChatGPT实现、分析、检测、应用相关开源项目
首先一个低成本的实现框架是ColossIAI,提出了一个开源低成本的ChatGPT等效实施过程,提供开箱即用的ChatGPT训练代码。地址在https://github.com/hpcaitech/ColossalAI。还包括RLHF的开源实现,去感受这里边的一些在数据上应该怎么标,应该标成什么样。还有PaLM-rlhf-pytorch,该项目是在 PaLM 架构之上实施 RLHF(人类反馈强化学习),基本上等同于 ChatGPT,区别是使用了 PaLM,项目地址:https://github.com/lucidrains/PaLM-rlhf-pytorch。
这里还有一个ChatGPT-Comparison-Detection 项目,通过收集数万个来自人类专家和ChatGPT的对比问答数据HumanChatGPT对比语料库,研究了ChatGPT的回答特点,以及与人工回答在风格和语言学特征上的差异和差距,并给出了ChatGPT检测器,项目地址在项目地址:https://github.com/Hello-SimpleAI/chatgpt-comparison-detection。然后有了一些惊喜的发现:首先,ChatGPT的回答一般都严格集中在给定的问题上,而人工的回答则是发散性的,容易转向其他话题。第二,ChatGPT提供客观的答案,而人工更喜欢主观的表达。第三,ChatGPT的回答通常是正式的,而人类的回答则更口语化。人类也喜欢运用幽默、讽刺、隐喻和例子,而ChatGPT从不使用反语。最后,ChatGPT在其回应中表达的情感较少,而人类在上下文中选择了许多标点和语法特征来传达他们的感受。
还有一些应用型的开源项目,直接去做一些NLP方面的任务。第一个是unlocking-the-power-of-llms,项目地址在https://github.com/howl-anderson/unlocking-the-power-of-llms。该项目主要涉及是语料扩充的数据增强操作,还能够进行语料清洗,可以进行纠正数据错误,并给出每个修正的说明。还有一些prompt应用类项目,由于同一个任务,不同的prompt会带来不同的效果,因此如何找到一个针对特定任务的prompt很重要,项目地址在项目地址:https://github.com/f/awesome-chatgpt-prompts。还有一些其他的应用端开源项目如图5所示。

图5 其他应用端相关开源项目
3、ChatGPT与NLP、KG的关系和结合方向
3.1 ChatGPT与NLP:预训练模型基本概述
预训练模型其实是一个从迁移学习过来的概念,利用大模型和大算力来利用量无标注或弱标注数据,同时有少样本和零样本的学习能力,还可进行多模态交互。NLP的语言架构如图6所示。
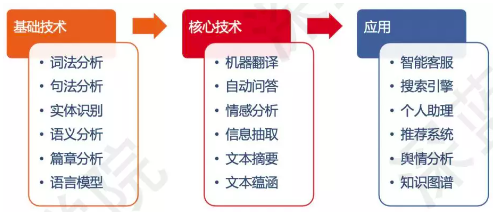
图6 NLP自然语言处理的架构
预训练语言模型基于大规模无标注数据,自动学习通用语言模型是,泛化能力强,可用于多种下游任务,迁移学习采用“预训练-微调”框架实现“知识获取-知识迁移,包括特征表示迁移和参数迁移两种,然后包括从图像里边去做自监督学习。
语言模型本身解决的是语言表示的问题,开始用one-hot去做表示,后面用大模型替换中间的特征编码层去做个分布式表示,然后再去做一些下游的任务,演变如图7所示。

图7 自然语言处理语言表示的演变
语言模型的核心是整个概率的最大化,即估计文本的中下一个词生成的概率。但存在一个很大的问题,超出量大且上下文特别多,会出现未获取的状态,所以会想能不能用模型的方式去学习上下文模型。一开始是基于符号表示的,后面开始做统计语言模型,通过矩阵文字做分解,可以得到词袋模型去做。在后面采用嵌入的方式,直接使用一个低维、连续、稠密的向量表示词。还有一个是NNLM模型,可以通过建模语言模型去生成一些模型。ELMO就可以得到一个解决动态词向量的问题,分别训练前向语言模型和反向语言模型,解决一字多义的形式。
目前,预训练语言模型已经成为NLP处理的新范式,首先构造一些标志任务,然后再用标志数据做反衬。目前比较火的是prompt tuning,可以针对不同的任务去可以选择不同的prompt,
在一定程度上去解决NLP统一的问题,但里面有一个很大的问题是模板的构造,模板构造的不一样,生成的结果也会不一样,预训练语言模型的核心还是自监督学习任务,
3.2 ChatGPT与KG:融合知识图谱的预训练语言模型
知识图谱:基于二元关系的知识库,用以描述现实世界中的实体或概念及其相互关系,基本组成单位是【实体-关系-实体】三元组。从根本上讲,知识图谱本质上是一种知识表示方式,其通过定义领域本体,对某一业务领域的知识结构(概念、实体属性、实体关系、事件属性、事件之间的关系)进行了精确表示,使之成为某个特定领域的知识规范表示。实体知识和事件知识图谱对比如下:
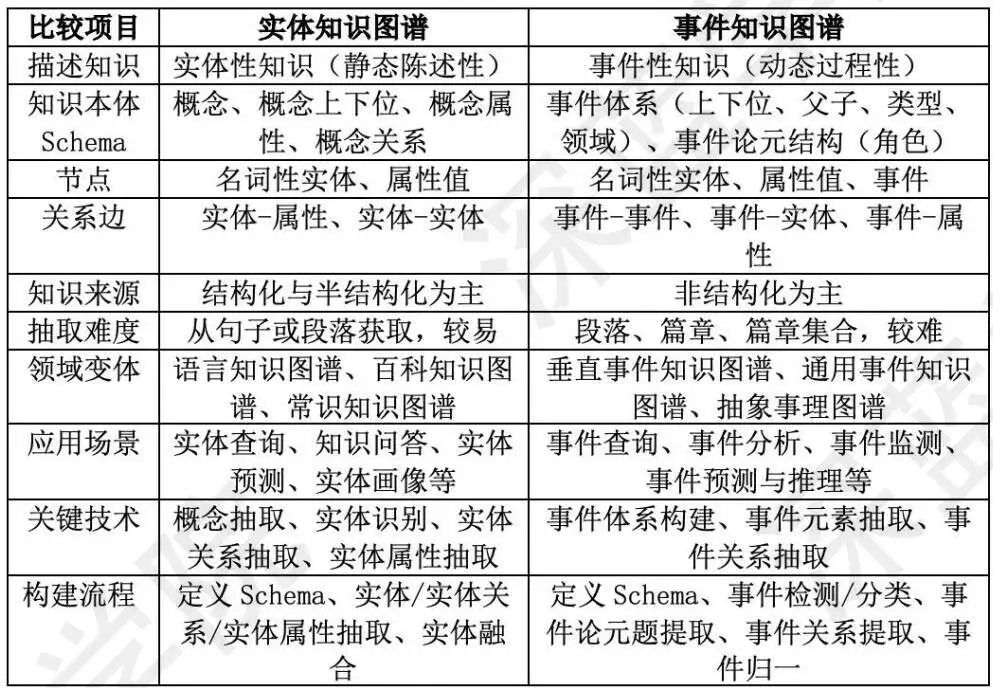
图8 实体知识和事件知识图谱对比
那知识图谱和ChatGPT有什么不同点和结合点?不同点在于本身他们俩并不是取代的关系,而是并行的关系,本质在于知识图谱是一种知识的形式化表示方式,ChatGPT是语言模型,其本身是是参数化的知识, KG的优势就在于可解释,其实后面也可以用来解释ChatGPT为什么有效。结合点首先包括推理上的交换,其次是各种图谱任务的映射,还有是深度学习的实现。
另外一个是数据计算比较在行,在推理上的一些挑战,所以目前用知识图谱去解决推理问题。通常,结构化知识很难构建,但易于推理,非结构化知识易于构建(直接存起来就行),但很难用于推理。然而,语言模型提供了一种新的方法可以轻松地从非结构化文本中提取知识,并在不需要预定义模式的情况下有效地根据知识进行推理。
还有一个是融合外部知识的系统能力,要从根本上解决 ChatGPT 的短板可能要耗费大量精力,不如将其与自己的 Wolfram | Alpha 知识引擎结合起来用,因为后者本就具有强大的结构化计算能力,而且也能理解自然语言。
将知识图谱融合到ChatGPT中可以通过多种方式实现。给它足够正确的知识,再引入知识图谱这类知识管理和信息注入技术,还要限定它的数据范围和应用场景,使得它生成的内容更为可靠。
首先有知识图谱的嵌入表示,可以将知识图谱中的实体和关系表示为嵌入向量,将其作为额外的特征融入到模型中,以提高模型的性能。其次是基于知识图谱的上下文理解,知识图谱可以帮助模型理解对话的上下文,为回答问题提供更准确的信息。还有是基于知识图谱的自动问题生成,通过结合知识图谱的信息,可以自动生成问题,从而帮助用户更好地理解实体和关系之间的语义和上下文。目前主要融合知识的预训练语言模型如图9所示。

图9 融合知识的预训练语言模型
4、ChatGPT的落地可能性与应用展望
ChatGPT具有持续多轮对话的能力,还有支持多种任务。应用落地首先看公司,openAI的商业模式是会员收费、开放API以及与微软的战略合作。
ChatGPT本身是一个预训模型,可以借鉴目前预模型的一些落地模式,去年人工智能研究院发布了一份报告,把超大规模智能产业落地分成三块,一块是上游,主要是包括一些底层的训练架构;一个中游,包括技术研发、管理和运维发展;一个是下游,提高大模型重点落地的场景。
还有一种落地模式是开源,可以采用注册制或是会员制等等去做。第三种是PaaS模式,融合一些特定的软件。
应用落地之后,用户到底想要干嘛,那具体分布如图10所示。
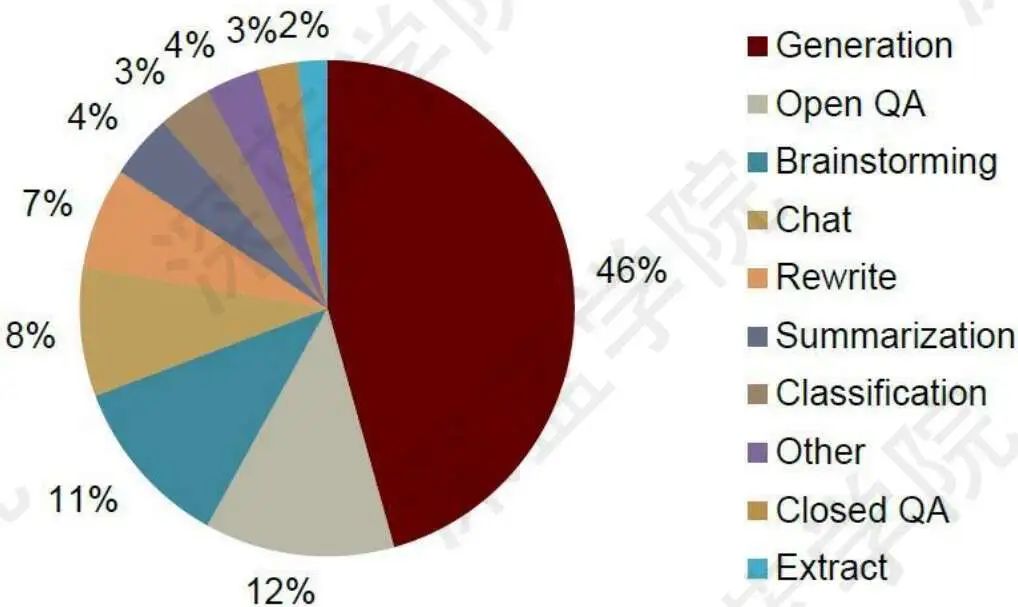
图10 用户的使用功能和频率
当然一些公司要去集成在文档里面,去做回复邮件、提出报价等等。那还可以去结合搜索引擎,通过ChatGPT回答一些搜索查询,革新性地提升搜索引擎效率。
还有一些学习类的,通过检索已发表的论文,从大量研究论文中查找最相关的摘要,以及能够进行语法纠正;还有创作类的,通过搜索关键字分析该主题在Google里最受欢迎的内容,基于获取的数据进行生成内容来获得更高的阅读量,还能够进行AI自动写作。
在娱乐类可以通过AI自动生成故事,给予全新的事件反馈和游戏体验,还能够和用户进行对话。在生活类上有比如税务助手,能采用不同模型提取文本信息并分类交易类型。
目前,与ChatGPT的竞品如图11所示,当然这这也促进了大家对ChatGPT的发展。
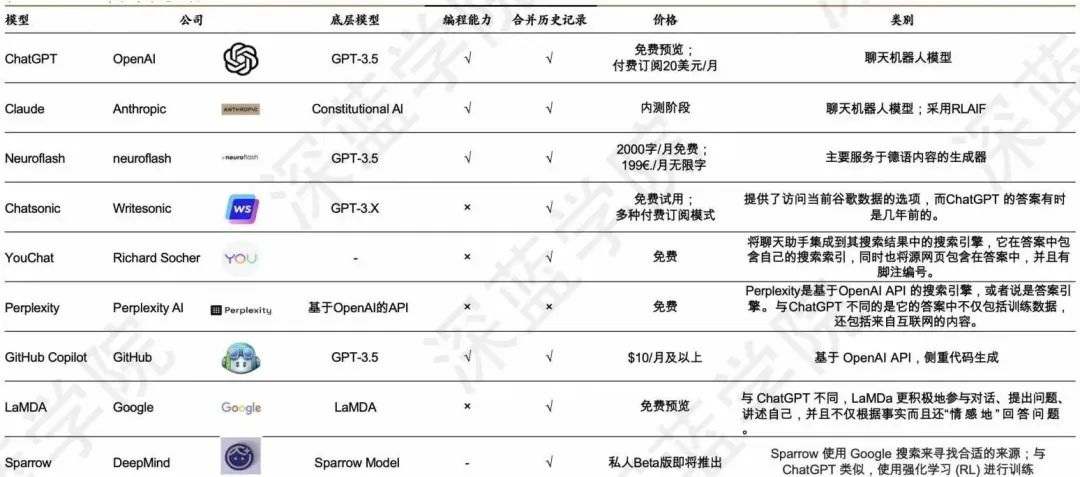
图11 ChatGPT的竞品