目录
- 前言
- tcmalloc
- PageHeap
- CentralCache
- ThreadCache
- 小对象分配
- 中对象和大对象
- 总结
- 堆内存分配
- 概念
- mheap
- heaparena
- mspan
- mcentral
- mcache
- 微对象分配 tiny allocator
- 小对象分配
- 大对象分配
- 栈内存分配
- 分段栈
- 连续栈
- 栈在go中
- stackpool
- stackLarge
- 栈分配
- 栈缩容
前言
golang的内存分配,思想来自tcmalloc。它是google的一个内存分配库。性能比glibc要快很多。所以在理解golang的内存分配前,我们先看一下tomalloc的原理。
tcmalloc
说明:https://github.com/google/tcmalloc/blob/master/docs/design.md
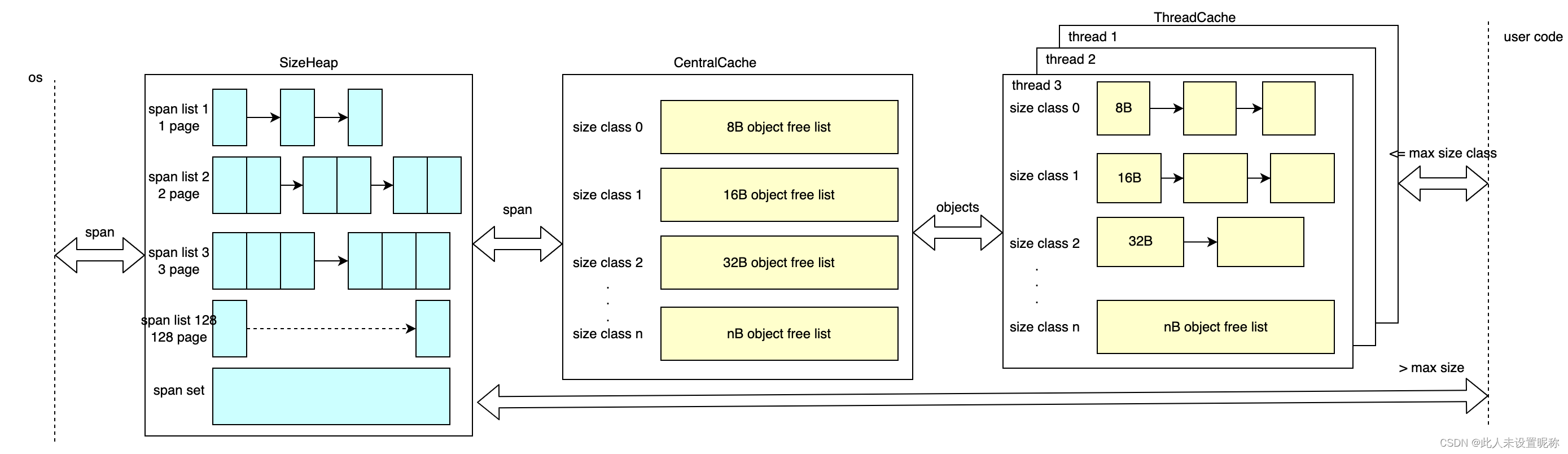
上图说明了tomalloc内部的大致结构,由三个部分组成
PageHeap
pageheap直接跟操作系统申请和释放内存。并且以page(默认8k)为单位,一次性申请或释放若干个page,这若干个page称为span。并将page个数相同的span 组成一个span list。直到pages超过128个,则放入到一个有序集合中。如上图。
CentralCache
- tomalloc 中并不存在CentralCache,这是一个抽象概念,可以理解为全局缓存。
- centralcache总是从pageheap中拿取释放内存,同样以page为单位,一次拿取若干个。
- centralcache会将内存按照8B到256KB分85个类别(8B 16B 32B … 256KB),称作size class,并且同样按照大小组成一个个CentralFreeList链表。而CentralCache则可以看做是CentralFreeList类型的数组。
- 具体的细分参考:https://github.com/google/tcmalloc/blob/master/tcmalloc/size_classes.cc
如上图
ThreadCache
每个线程都会有一个类似CentralCache的结构。按照大小分类形成FreeList。
用于在当前线程申请和释放内存。tcmalloc中的tc就是指ThreadCache。
因为每份线程都一个缓存,所以线程的freelist是不需要加锁的。
小对象分配
<= 256KB,我们称为小对象。他的内存申请过程如下:
- 首先基于所需内存的大小,按照size class向上取值。比如需12B,则取值16B的size class。
- 应用程序首先从当前ThreadCache的freelist中申请,当前线程有缓存,则从对应的链表中取出第一个值使用。
- 如果ThreadCache没有缓存,则从CentralCache中取值。如果CentralCache中存在缓存,则一次性取多个到线程中。再将其中一个返回给应用程序。
- 如果CentralCache中也没有,则需要从pageheap中取一个span,拆分成size class对应大小的空闲对象,放入CentralFreeList中。
- 如果pageheap中也没有,则需要向操作系统申请。
中对象和大对象
tcmalloc中 没有中对象和大对象的概念,超过256KB都无法从ThreadCache和CentralCache中取值。需要直接从pageheap中申请内存。pageheap的span list的大小最多到128个page,因为每个page默认大小8k,所以大于256KB小于1MB(128*8)的对象可以从span list中取缓存,所有叫做中对象。超过1MB称为大对象,直接从span set中取缓存。不管中对象还是大对象他们申请内存的方式都是差不多的。
- 中对象和大对象的申请,都按照page向上取整,得到要取的span大小x。
- 中对象会先从对应x大小的span list中查找,如果存在则取出。
- 如果未取到,则中对象和大对象都会尝试从span set中取一个大于x的span,并假设它的大小是n。并按照x切分。其中0-x的部分取出使用,x-n 的部分按照大小优先放入对应的span list中,如果x-n>128,则重新放入span set中。
- 如果未能在span中取到值,则向操作系统申请。
总结
从tomalloc的工作原理中可以看出,tomalloc有以下特点
- 减少系统调用,避免上线文切换
- 每个线程有缓存,避免了锁竞争
- 复杂的设计让内存碎片化,并让内存利用率降低,tomalloc虽然做了一些优化,但这些问题依然存在。
堆内存分配
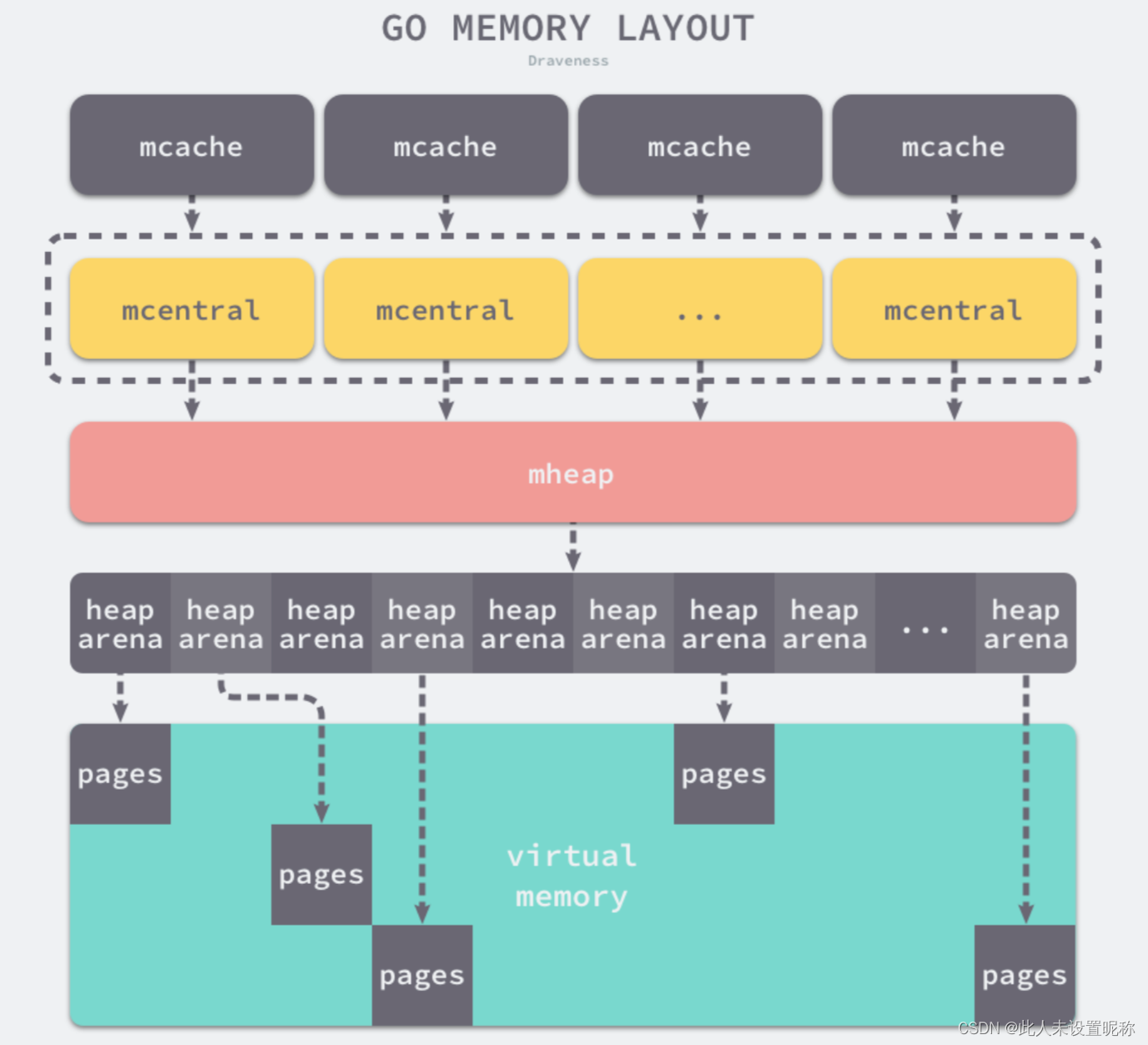
golang的内存分配和tcmalloc几乎一模一样,只是概念和参数不一样。我这里使用1.18.4版本,主要还是因为18版加入泛型,内存管理这块所有变动。大概结构如下盗的图
概念
mheap
对应tcmalloc中的PageHeap,同样是从操作系统中申请和释放内存,存取需要加锁。
mheap总是以arean为单位向操作系统申请内存,默认arean为64mb,并通过heap arena对应一个arean。详见heaparena
同样的若干page连在一起称为span。默认page大小为8kb。
- mheap 通过
go:notinheap标记,这个标签的意思是不从自身堆内存中分配,直接从操作系统中申请,理想的大小是系统页的倍数
mheap在golang源码中是一个全局唯一变量,位置$GOROOT/src/runtime/mheap.go/mheap_
其加载顺序在 schedinit->mallocinit->mheap_.init()
里面有两个很重要的结构体mcentral和heaparena
来看一下它的源码中的结构 源码位置:$GOROOT/src/runtime/mheap.go
// Main malloc heap.
//go:notinheap
//全局堆分配器,但是栈不够的时候也会从这里取
type mheap struct {
sweepgen uint32 // 扫描计数值,在gcSweep函数(gc扫描)中每次 +2
allspans []*mspan // 所有span都在这里
pagesInUse atomic.Uint64 // 有多少页正在被使用
pagesSwept atomic.Uint64 // 扫描的页面数量
pagesSweptBasis atomic.Uint64 // 用做扫描比例的初始基点
sweepHeapLiveBasis uint64 // 用做扫描比例的初始处于存活状态的初始基点
sweepPagesPerByte float64 // 扫描比
// 保留堆内存的数量,每次gc的时候(算法见gcPaceScavenger函数)都会计算这个值,这个值>=rss(常驻内存集)就会进行内存回收
scavengeGoal uint64
//指回收的下一页在allAreans中的索引
reclaimIndex atomic.Uint64
// 多归还的pages,是回收对象在heapArena释放的
reclaimCredit atomic.Uintptr
// heapArena二维数组,是arena的元数据,后面会着重说明
arenas [1 << arenaL1Bits]*[1 << arenaL2Bits]*heapArena
//是为分配heapArena对象而预先保留的空间。仅仅用于32位系统
heapArenaAlloc linearAlloc
// 试图添加更多堆 arenas 的地址列表。它最初由一组通用少许地址填充,并随实 heaparena 的界限而增长。
arenaHints *arenaHint
//arena预留空间,同样只适用于32为系统
arena linearAlloc
// 是每个映射arena的arenaIndex 索引。可以用以遍历地址空间。
allArenas []arenaIdx
// 指在清扫周期开始时保留的 allArenas 快照
sweepArenas []arenaIdx
// 指在标记周期开始时保留的 allArenas 快照
markArenas []arenaIdx
// 指heap当前增长时的 arena,它总是与physPageSize对齐
curArena struct {
base, end uintptr
}
// 每种跨度大小的块对应一个 mcentral 下面会说明。pad 是一个字节填充,用来避免伪共享(false sharing)
// numSpanClasses = 136
central [numSpanClasses]struct {
mcentral mcentral
pad [cpu.CacheLinePadSize - unsafe.Sizeof(mcentral{})%cpu.CacheLinePadSize]byte
}
// 数据类型 fixalloc 是 free-list,用来分配特定大小的块。比如 cachealloc 分配 mcache 大小的块
spanalloc fixalloc // allocator for span*
cachealloc fixalloc // allocator for mcache*
specialfinalizeralloc fixalloc // allocator for specialfinalizer*
specialprofilealloc fixalloc // allocator for specialprofile*
specialReachableAlloc fixalloc // allocator for specialReachable
speciallock mutex // lock for special record allocators.
arenaHintAlloc fixalloc // allocator for arenaHints
unused *specialfinalizer // never set, just here to force the specialfinalizer type into DWARF
}
heaparena
heapArena 对象存储了一个 heap arena的元数据,heapArena也标记notinheap,表示对象自身存储在Go heap之外。其通过mheap_.arenas index 来访问。heapArena对象也直接从操作系统分配的,所以理想情况下应该是系统页面大小的倍数。
heaparena在mheap是一个二维数组,在64位linux下,这个二维数组的一维大小是1,二维大小是4,194,304. 由于每个指针占8字节的内存空间,所以原信息一共占据32MB(4194304 * 8),而每一个heapArena可以管理64MB的数据,所以在1.11版本以后,Go语言可以管理最大256TB(4194304 * 64MB)的数据.
这里既要说一下
在go的早期版本里 <= 1.10 ,内存是线性分配的,就是先申请一块大内存,然后再划分各种小内存,如下图:
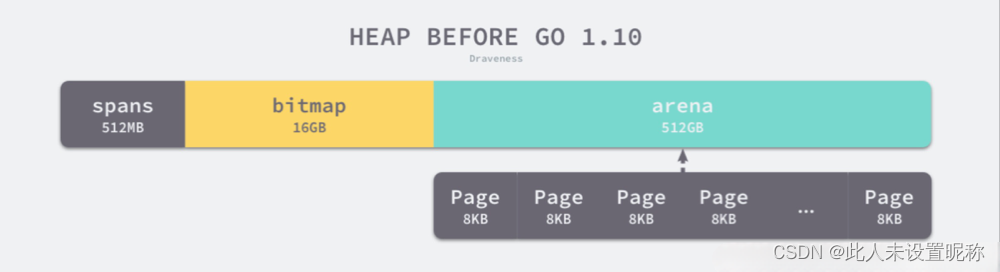
线性内存被放弃使用是因为在cgo使用上有两个问题
- 在C,Go混用时,分配的内存地址会发生冲突,导致堆得初始化和扩容失败.
- 没有被预留的大块内存可能会被分配给 C 语言,导致扩容后的堆不连续
在>=1.11版本中,golang使用稀疏(分段)内存,如下图
- 但是使用稀疏内存管理也是有代价的,在进行垃圾回收时,会造成额外百分1的开销.
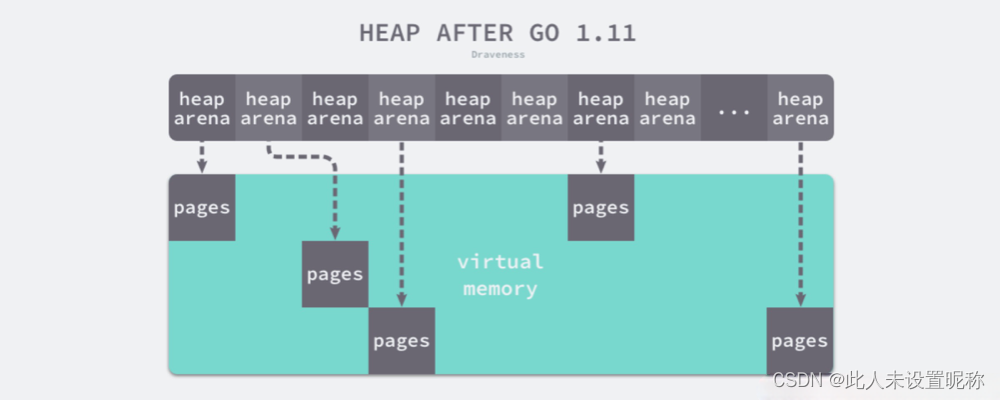
在64为linux下,每段64MB,也就是说每个heaparena对应64MB的空间,且起始地址与 arena 的大小对齐,其每段内存分配对应操作系统关系如下如下:
// Platform Addr bits Arena size L1 entries L2 entries
// -------------- --------- ---------- ---------- -----------
// */64-bit 48 64MB 1 4M (32MB)
// windows/64-bit 48 4MB 64 1M (8MB)
// ios/arm64 33 4MB 1 2048 (8KB)
// */32-bit 32 4MB 1 1024 (4KB)
// */mips(le) 31 4MB 1 512 (2KB)
我们来看一下他的源码 位置:$GOROOT/src/runtime/mheap.go
- pagesPerArena 每个arena中含有的page数 = 64mb/8kb = 8192
- heapArenaBitmapBytes arean对应的位图大小 64mb/8/8 * 2 = 2mb
type heapArena struct {
// 位图,详见下文
bitmap [heapArenaBitmapBytes]byte
//是一个8192(pagesPerArena)大小的指针数组,每个mspan对应8KB
//这是只是表示有这么多mspan,并不是指一个mspan只有一个page
//在mheap分配内存的时候可能n个page对应一个mspan,会在mheap_.alloc.allocSpan.setSpans中将这个mspan的指针,对应到heapArena.spans的n个位置
spans [pagesPerArena]*mspan
//表示page是否被使用 = 8192 / 8 = 1024
pageInUse [pagesPerArena / 8]uint8
//页是否被标记,gc使用
pageMarks [pagesPerArena / 8]uint8
//又是一个与pageInUse类似的位图,只不过标记的是哪些span包含特殊设置,目前主要指的是包含finalizers,或者runtime内部用来存储heap profile数据的bucket。
pageSpecials [pagesPerArena / 8]uint8
//一个大小为1MB的位图,其中每个二进制位对应arena中一个指针大小的内存单元。当开启调试debug.gccheckmark的时候,checkmarks位图用来存储GC标记的数据。该调试模式会在STW 的状态下遍历对象图,用来校验并发回收器能够正确地标记所有存活的对象。
checkmarks *checkmarksMap
// 记录的是当前arena中下个还未被使用的页面的位置,相对于arena起始地址的偏移量。页面分配器会按照地址顺序分配页面,所以zeroedBase之后的页面都还没有被用到,因此还都保持着清零的状态。通过它可以快速判断分配的内存是否还需要进行清零
zeroedBase uintptr
}
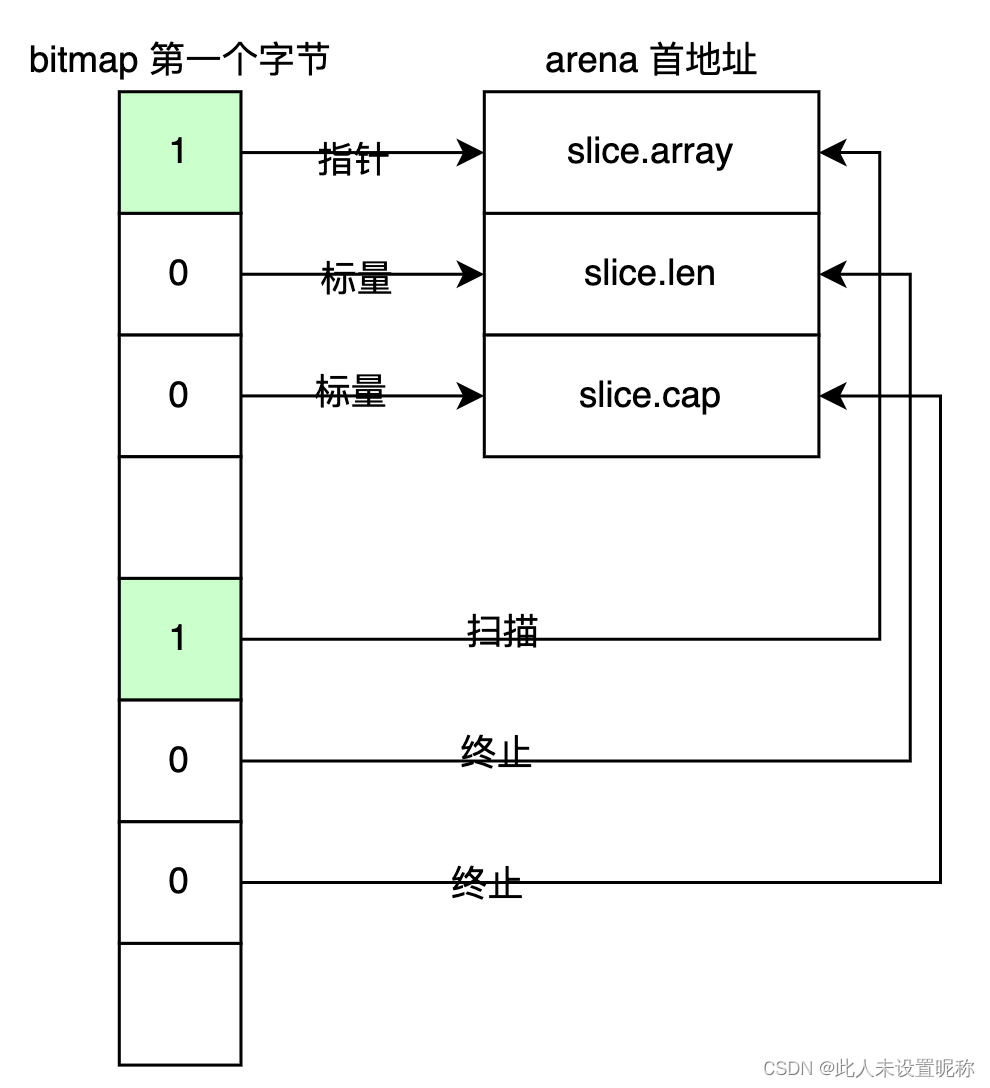
heapArena中的bitmap 位图,中的一字节指示arena中四个指针位的状态。
- 其中低四位表示指针还是标量,
- 高四位表示需要扫描还是终止
比如切片可以表示为下图
mspan
mspan表示一个连续多个page的结构,对应tcmalloc中的span,并且mspan也分成很多个规格。
这里的规格是指tcmalloc中的 size class ,对应到go里就是span class
先看一下span class的定义:
type spanClass uint8
const (
// _NumSizeClasses = 68 ,左移即乘2,分表代表有无指针
numSpanClasses = _NumSizeClasses << 1
// 微对象的span classs【0,2,4,8】,tinySizeClass = 2
tinySpanClass = spanClass(tinySizeClass<<1 | 1)
)
// 前七位用于登记类型,最后一位用于记录有无指针
func makeSpanClass(sizeclass uint8, noscan bool) spanClass {
return spanClass(sizeclass<<1) | spanClass(bool2int(noscan))
}
// 获取前七位,也就是得到对应的spanClass类型
func (sc spanClass) sizeclass() int8 {
return int8(sc >> 1)
}
// 判断最后一位是否为1, 1为无指针,0为有指针
func (sc spanClass) noscan() bool {
return sc&1 != 0
}
spanclass 将span从8B到32KB一共分了68个规格,可在$GOROOT/src/runtime/sizeclasses.go中查询具体分割情况
// class bytes/obj bytes/span objects tail waste max waste min align
// 1 8 8192 1024 0 87.50% 8
// 2 16 8192 512 0 43.75% 16
// 3 24 8192 341 8 29.24% 8
// 4 32 8192 256 0 21.88% 32
// 5 48 8192 170 32 31.52% 16
// 6 64 8192 128 0 23.44% 64
...
所以每个mspan是将若干个连续page 按照其对应的spanclass分割成若干空间。
比如按照序号为1的spanClass分配, 那么管理1个Page的mspan会被分割为1024份。
mspan结构如下:
//go:notinheap
type mspan struct {
// 前后指针,分别指向了前后的Span
next *mspan
prev *mspan
// 当前Span的第一个page的首地址
startAddr uintptr
// 代表当前Span是由多少Page构成的 startAddr*npages*pgae size(8KB)就是当前span分配空间的大小
npages uintptr
manualFreeList gclinkptr // 空闲对象列表
// freeindex是0~nelems的位置索引, 标记当前span中下一个空对象索引
freeindex uintptr
nelems uintptr // 当前span中管理的对象数
allocCache uint64 // 从freeindex开始的位标记
allocBits *gcBits // 该mspan中对象的位图
gcmarkBits *gcBits // 该mspan中标记的位图,用于垃圾回收
spanclass spanClass // 当前span 对应的spanclass
...
}
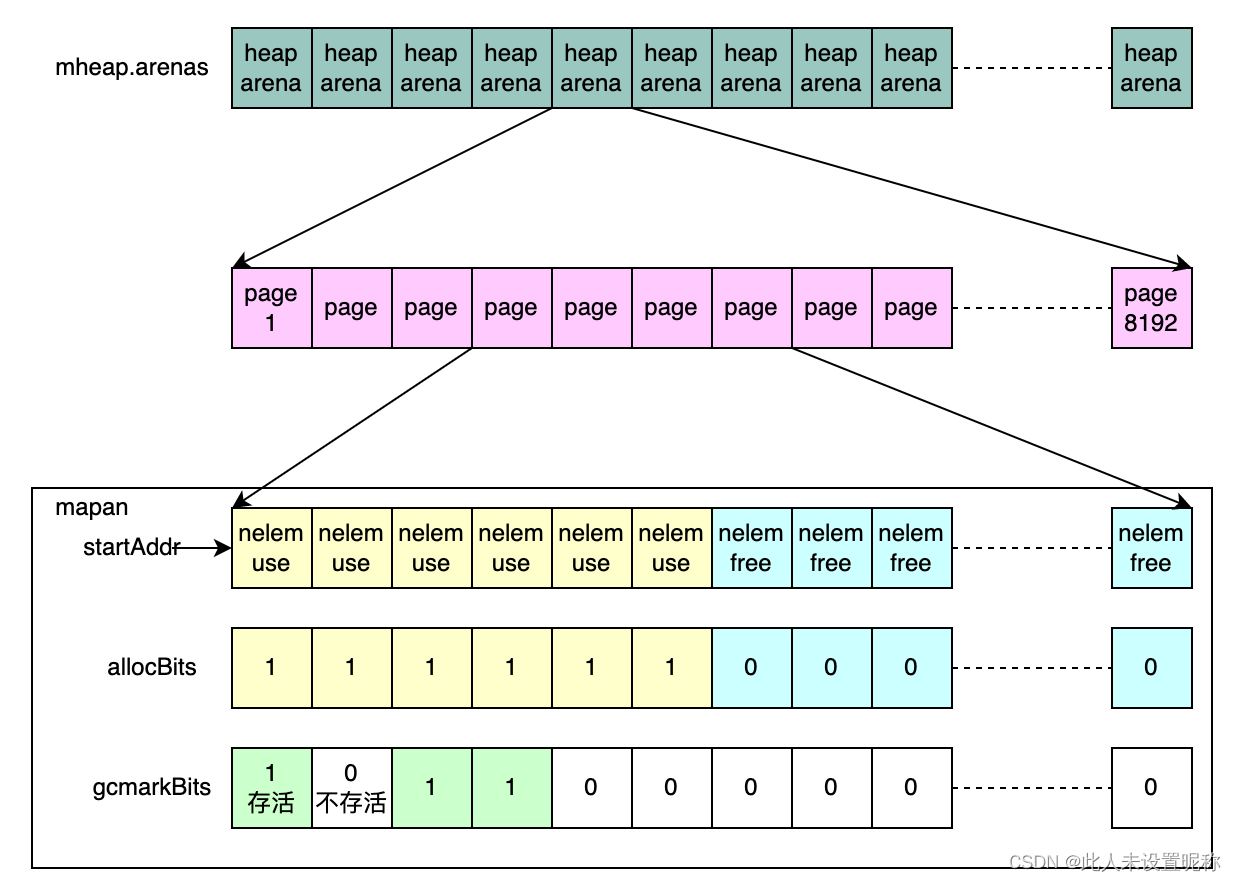
mspan结构体和arean,page的对照关系 可以看下图:
mcentral
mcentral对应tcmalloc中的CentralCache,是一个全局的内存分配器。
上面我们已知 mcentral也是存放在全局变量mheap中mheap_.central 并且在64位linux下有136 个 = 68 * 2
- 也就是说每个规格(spanclass)的mcentral都存在两份,其中一个用了存放需要扫描的对象(scan spanClass),另一个存放没有指针的不需要扫描的对象(noscan spanClass)
其代码结构十分简单,和tcmalloc不同的是,每个级别的Span有2个链表, 其中一个是已扫描的,另一个是未扫描的,用来支持gc的。
位置:$GOROOT/src/runtime/mcentral.go
//go:notinheap
type mcentral struct {
spanclass spanClass //当前mcentral是哪一种spanclass
partial [2]spanSet // 有可用空间的span集合
full [2]spanSet // 没可用空间的span集合 或者当前链表里的Span已经交给mcache
}
mcache
mcache对应tcmalloc中的threadcache,是一种缓存在线程中的span list数组。
- go为mpg中的每个p分配一个mcache,在创建p的时候,通过
allocmcache 调起 mheap_.cachealloc创建 - mcache初始化的时候为空,并不预先分配,在需要的时候才申请。
看一下代码结构 位置 $GOROOT/src/runtime/mcache.go
//go:notinheap
type mcache struct {
nextSample uintptr // 堆分析的下一个采样
scanAlloc uintptr // 用来指示已分配堆的扫描情况
// 微对象分配相关,详见微对象分配
tiny uintptr
tinyoffset uintptr
tinyAllocs uintptr
alloc [numSpanClasses]*mspan // 136个span链表
stackcache [_NumStackOrders]stackfreelist //栈相关
flushGen uint32
}
微对象分配 tiny allocator
这里是不同于tcmalloc的方式,如果只需要一个字节的对象,即便申请最小的规格也需要8B,会产生7B的浪费,所以go使用tiny allocator分配微对象(<16B && noscan)。
- tiny 默认大小是16B
- 在释放时,要全部都标记成垃圾才能回收,整块内存回收回去

如上图我们来假设一下分配过程:
- 如果需要申请一个小于等于4B的对象,则直接从tiny中分配,并返回
- 如果申请对象>4B,则不使用微对象分配器,使用小对象分配过程
- 如果一开始tiny为空,则使用小对象分配过程,但是申请到的空间会作为微对象分配器的空间,剩下的空间可以用于分配另外的微对象
来看下精简代码
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
// size : 申请内存大小
// maxSmallSize: 最大spanclass 32KB
// maxTinySize : 最大微对象大小 16KB
// c :p中的mcache
// 这里可以看到 小于32kb 先用macache分配
if size <= maxSmallSize {
// 不需要扫描 并且小于16B 则是微对象
if noscan && size < maxTinySize {
// c.tinyoffset : 当前mcache的ting分配到哪里了
off := c.tinyoffset
// 省略向上取整过程(比如需要3字节 取四字节),并重新计算off
if off+size <= maxTinySize && c.tiny != 0 {
// ... 如果tiny能够分配则分配,然后返回
return x
}
// 如果微对象分配器中的内存不足时,使用span进行分配.
span = c.alloc[tinySpanClass]
v := nextFreeFast(span)
if v == 0 {
// 同样是获取mcache中的缓存,但是更加耗时
// 如果mcache中没获取到则获取mcentral中的mspan用于分配(调用refill方法)
// 如果mcentral也没有则去找mheap.
// 这里的tinySpanClass,是序号为2的spanClass,即大小为16字节.同时也等于macTinySize
v, span, shouldhelpgc = c.nextFree(tinySpanClass)
}
// 返回对应内存的指针
x = unsafe.Pointer(v)
(*[2]uint64)(x)[0] = 0
(*[2]uint64)(x)[1] = 0
// 如果微对象分配器没有初始化,则将当前对象申请的空间作为微对象分配器的空间
if !raceenabled && (size < c.tinyoffset || c.tiny == 0) {
// Note: disabled when race detector is on, see comment near end of this function.
c.tiny = uintptr(x)
c.tinyoffset = size
}
size = maxTinySize
}
。。。
}
- mallocgc是全局方法,它如何找到mcache的哪?
首先调用getg找到g,然后通过g找到m,然后通过m找到p,然后找到p的mcache
小对象分配
小对象:>=16B && <= 32KB 的对象或者 小于 16 字节的指针类型的对象
分配过程如下: 类似tcmalloc
- 根据对象大小,向上计算所需最小spanClass
- 首先从p的mcache中取对应spanClass的span链表,如果有空闲的内存单元,则返回
- 如果没有,则向mcentral申请,如果还没有则向mheap申请。
- 最后清理空闲内存
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
...
if size <= maxSmallSize {
if noscan && size < maxTinySize {
//微对象分配
...
} else {
//小对象分配
var sizeclass uint8
// smallSizeMax = 1024
// size_to_class8与size_to_class128都是用于将内存向上对齐到spanClass类型的序号
if size <= smallSizeMax-8 {
sizeclass = size_to_class8[(size+smallSizeDiv-1)/smallSizeDiv]
} else {
sizeclass = size_to_class128[(size-smallSizeMax+largeSizeDiv-1)/largeSizeDiv]
}
// 通过对应的spanClass类型再反向获取内存大小
size = uintptr(class_to_size[sizeclass])
// 通过对应大小以及有无指针获取到spanClass
spc := makeSpanClass(sizeclass, noscan)
// 最后通过spanClass获取mcache中缓存的mspan
span := c.alloc[spc]
// 调用mcache中缓存的mspan获取内存.
v := nextFreeFast(span)
if v == 0 {
// 同样是获取mcache中的缓存,但是更加耗时
// 如果mcache中没获取到则获取mcentral中的mspan用于分配(调用refill方法)
// 如果mcentral也没有则去找mheap.
v, span, _ = c.nextFree(spc)
}
// 转为指针返回
x = unsafe.Pointer(v)
if needzero && span.needzero != 0 {
// 清空空闲内存中的所有数据;
memclrNoHeapPointers(unsafe.Pointer(v), size)
}
}
} else {
// 大对象分配
...
}
...
return x
}
- nextFreeFast : 从mcache的缓存中申请内存单元
- nextFree :通过
mcache.refill->mheap_.central[spc].mcentral.cacheSpan()->mcentral.grow()-mheap_.alloc最终申请到一个span
大对象分配
运行时对于大于 32KB 的大对象会单独处理,我们不会从线程缓存或者中心缓存中获取内存管理单元,而是直接调用 allocLarge 分配大片内存
...
if size <= maxSmallSize {
if noscan && size < maxTinySize {
//微对象分配
...
} else {
//小对象分配
...
}
} else {
// 大对象分配
var s *mspan
span = c.allocLarge(size, needzero, noscan)
span.freeindex = 1
span.allocCount = 1
x = unsafe.Pointer(span.base())
size = span.elemsize
}
...
return x
}
大对象的分配会调用allocLarge方法分配内存,而在allocLarge中会调用mheap直接进行分配,并生成一个spanClass为0的对象
func (c *mcache) allocLarge(size uintptr, needzero bool, noscan bool) *mspan {
//通过大小获取需要分配的Page数量
npages := size >> _PageShift
if size&_PageMask != 0 {
npages++
}
...
//直接调用mheap进行分配.
spc := makeSpanClass(0, noscan)
s := mheap_.alloc(npages, spc, needzero)
...
mheap_.central[spc].mcentral.fullSwept(mheap_.sweepgen).push(s)
s.limit = s.base() + size
heapBitsForAddr(s.base()).initSpan(s)
return s
}
栈内存分配
栈区的内存由go的编译器自己管理,进行分配和释放,栈区中存储着函数的参数以及局部变量,它们会随着函数的创建而创建,函数的返回而销毁。
go的早期版本用的是分段栈,就是不连续的栈空间,然后通过链表串起来。
后来采用连续栈,变更记录如下:
- v1.0~v1.1:最小栈内存空间为4KB。
- v1.2:将最小栈内存提升到了8KB。
- v1.3: 使用连续栈替换之前版本的分段栈。
- v1.4~v1.19:将最小栈内存降低到了2KB。
go的栈检查是通过在调用函数时,会运行时检查runtime.morestack,它会在几乎所有的函数调用之前检查当前goroutine的栈内存是否充足,不充足就runtime.newstack创建新栈扩容。
分段栈
在栈空间不够的时候,会申请新的空间,然后和之前的空间通过链表连起来。这种方式能够很好的根据需要申请和释放内存。
但是这种方式会导致热分裂问题(Hot split)。就是当一个栈已经满了时,调用函数会导致栈扩容,释放函数会导致栈缩容。频繁地扩缩容会造成巨大开销。
连续栈
其核心原理就是每当程序的栈空间不足时,初始化一片比旧栈大两倍的新栈并将原栈中的所有值都迁移到新的栈中,新的局部变量或者函数调用就有了充足的内存空间。其扩容过程如下:
- 调用runtime.newstack用在内存空间中分配更大的栈内存空间。
- 使用runtime.copystack将旧栈中的所有内容复制到新的栈中。
- 将指向旧栈对应变量的指针重新指向新栈。
- 调用runtime.stackfree销毁并回收旧栈的内存空间。
在goroutine运行的过程中,如果栈区的空间使用率不超过1/4,那么在垃圾回收的时候使用runtime.shrinkstack进行栈缩容,当然进行缩容前会执行一堆前置检查,都通过了才会进行缩容。
栈在go中
go是自己来管理栈,在runtime中有两个全局变量分别是runtime.stackpool和runtime.stackLarge 用作栈分配器
stackpool
用于分配小于32KB的内存
- 同样也是用mspan来管理内存,如果
mspan.state为mSpanInUse则表示用作栈空间,如果为mSpanManual则为堆空间。
stackpool是一个4长度数组,表示四种规格的mspan list,在linux下,分为 2KB,4KB,8KB 16KB
其规格如下$GOROOT/src/runtime/malloc.go
// OS | FixedStack | NumStackOrders
// -----------------+------------+---------------
// linux/darwin/bsd | 2KB | 4
// windows/32 | 4KB | 3
// windows/64 | 8KB | 2
// plan9 | 4KB | 3
stackpool全局变量在代码中声明如下,$GOROOT/src/runtime/stack.go
var stackpool [_NumStackOrders]struct {
item stackpoolItem
_ [cpu.CacheLinePadSize - unsafe.Sizeof(stackpoolItem{})%cpu.CacheLinePadSize]byte
}
//go:notinheap
type stackpoolItem struct {
mu mutex
span mSpanList
}
stackLarge
大于等于32KB的栈,由stackLarge来分配,这也是个mSpan链表的数组,长度为25。mSpan规格从8KB开始,之后每个链表的mSpan规格都是前一个的两倍。
// Global pool of large stack spans.
var stackLarge struct {
lock mutex
free [heapAddrBits - pageShift]mSpanList // free lists by log_2(s.npages)
}
因为stackpool存在所有 8KB和16KB这两个链表,实际上会一直是空的,放在这里只是方便计算。
栈分配
栈的分配同样受到tcmalloc思想的影响,每个p的mcache都会缓存一份栈空间 其结构mcache.stackcache。并且同样具有和stackpool相同的四种规格。
栈分配过程如下
- 计算所需栈大小(2的倍数),如果小于32KB,则从p的
mcache.stackcache中取空闲栈。 - 如果没有从mcache中取到,则从全局stackpool中取。
- 如果所需栈大小 >=32KB 则直接从全局stackLarge中取
- stackpool和stackLarge都有可能取不到,则两者都从堆内存分配取一个合适大小的span,stackpool一般会取32KB大小,stackLarge则根据2的倍数计算。
- 如果都在mheap中取不到合适的内存单元,则直接向系统申请一块内存。
看一下具体的分配代码 $GOROOT/src/runtime/stack.go
//go:systemstack
func stackalloc(n uint32) stack {
...
// n是所需栈大小,
if n < _FixedStack<<_NumStackOrders && n < _StackCacheSize {
//小于 _StackCacheSize(32KB) 则使用stackpool分配
// 然后根据n计算order(以2倍向上取整),也就是stackpool的下标
if stackNoCache != 0 || thisg.m.p == 0 || thisg.m.preemptoff != "" {
//没空闲栈 则从加锁从stackpool中取
lock(&stackpool[order].item.mu)
x = stackpoolalloc(order)
unlock(&stackpool[order].item.mu)
} else {
//有空闲则从mcache.stackcache中取
x = c.stackcache[order].list
if x.ptr() == nil {
//mcache没有,则从stackpool中取,这里实际还是调用stackpoolalloc
stackcacherefill(c, order)
}
}
} else {
// >=32KB 从stacklarge中分配
var s *mspan
npage := uintptr(n) >> _PageShift
//以2为底求对数,log2npage就是stackLarge数组索引
log2npage := stacklog2(npage)
//加锁,在stackLarge空闲栈列表中取
lock(&stackLarge.lock)
if !stackLarge.free[log2npage].isEmpty() {
s = stackLarge.free[log2npage].first
stackLarge.free[log2npage].remove(s)
}
unlock(&stackLarge.lock)
lockWithRankMayAcquire(&mheap_.lock, lockRankMheap)
if s == nil {
//在stackLarge中没取到,则从堆分配器中取一个span
s = mheap_.allocManual(npage, spanAllocStack)
if s == nil {
throw("out of memory")
}
//堆里也没有,只能从系统中申请一个span
osStackAlloc(s)
s.elemsize = uintptr(n)
}
v = unsafe.Pointer(s.base())
}
...
return stack{uintptr(v), uintptr(v) + uintptr(n)}
}
上面代码中,大栈的分配过程很清楚,stackpool,其实也是一样的分配方式 见函数stackpoolalloc。
func stackpoolalloc(order uint8) gclinkptr {
...
if s == nil {
// 没有空闲,则先从堆分配器mheap_中分配
s = mheap_.allocManual(_StackCacheSize>>_PageShift, spanAllocStack)
...
// 堆不中用,取不到,则直接从系统中申请
osStackAlloc(s)
...
//插入到span list中
list.insert(s)
}
//... 从span list中取一个返回
return x
}
栈缩容
- 如果要触发栈的缩容,新栈的大小会是原始栈的一半,如果新栈的大小低于程序的最低限制2KB,那么缩容的过程就会停止。
- 缩容也会调用扩容时使用的runtime.copystack函数开辟新的栈空间,将旧栈的数据拷贝到新栈以及调整原来指针的指向。
唯一发起栈收缩的地方就是GC。GC通过scanstack函数寻找标记root节点时,如果发现可以安全的收缩栈,就会执行栈收缩,不能马上执行时,就设置栈收缩标识(g.preemptShrink=true),等到协程检测到抢占标识(stackPreempt)。在让出CPU之前会检查这个栈收缩标识,为true的话就会先进行栈收缩,再让出CPU。
未完待续…
参考:
https://www.zhihu.com/tardis/sogou/art/564746175
https://blog.csdn.net/qq_43188744/article/details/115433514