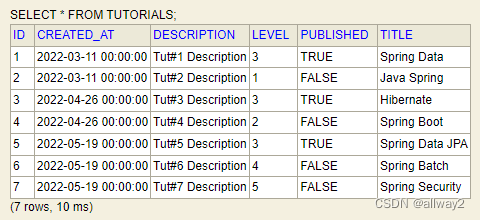
SVM,英文全称为 Support Vector Machine,中文名为支持向量机
SVM也是一种分类算法,它的核心思想用我自己的话来讲就是先找到两个类别中距离最近的几个点作为支持向量,然后计算超平面,超平面需要间隔最大化。然后用超平面作为分类的依据。如果数据线性不可分,可以利用核函数拓展成高维然后计算。
-
SVM 的中心思想
-
线性函数
-
具有分类功能,是一种二值分类
-
注重公平原则
-
-
支持向量:离分类超平面(Hyper plane)最近的样本点
-
超平面:超过三维的划分的东西。
-
分类超平面就是SVM分类器
二维空间(平面坐标),直线的函数表达式为:y=ax+b
高维空间中,超平面的函数表达式为:
自我感觉第一次看在间隔之前都超级容易理解,强推
补充上述链接函数间隔和几何间隔的前缀知识,方便理解

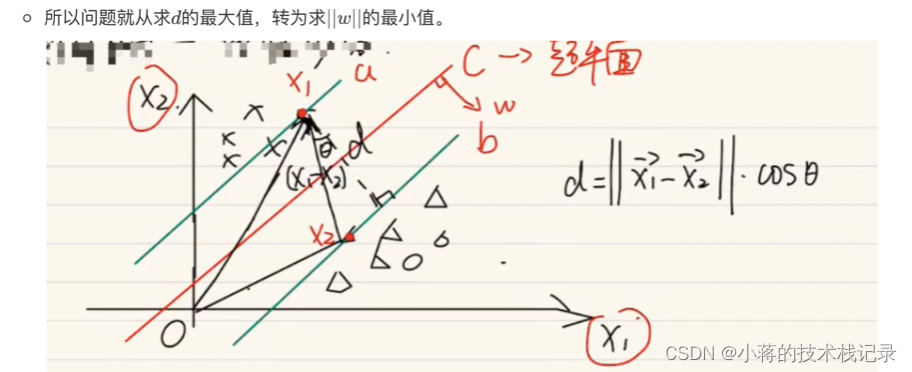
截取另外一篇博客的内容接着上面的推导过程理解

补充:s.t. 表示约束条件,对决策方案加以约束,常以不等式或方程式形式出现
之后还有一部分推到我就没继续研究了,等之后有用到再学吧
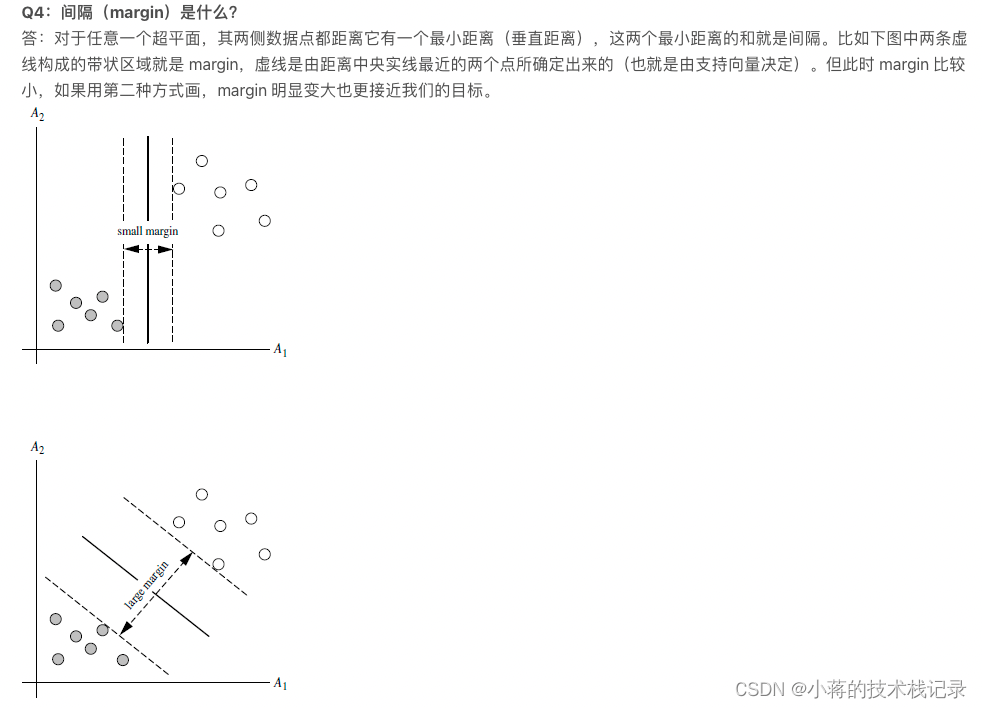
让margin尽可能大的直观理解,很明显越大分类效果越好
如果数据线性不可分,可以利用核函数把他们拓展成更高维,然后在更高维里划分
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5PJyJ3bf-1669543808014)(SVM.assets/image-20221127175418195.png)]](https://img-blog.csdnimg.cn/1ff9569378e549deb4c7031af6c54aca.png)
核函数有很多种,根据不同数据情况来选选择
sklearn库实现SVM
# sklearn 库中导入 svm 模块
from sklearn import svm
# 定义三个点和标签
X = [[2, 0], [1, 1], [2,3]]
y = [0, 0, 1]
# 定义分类器,clf 意为 classifier,是分类器的传统命名
clf = svm.SVC(kernel = 'linear') # .SVC()就是 SVM 的方程,参数 kernel 为线性核函数
# 训练分类器
clf.fit(X, y) # 调用分类器的 fit 函数建立模型(即计算出划分超平面,且所有相关属性都保存在了分类器 cls 里)
# 打印分类器 clf 的一系列参数
print(clf)
# 支持向量
print(clf.support_vectors_)
# 属于支持向量的点的 index
print(clf.support_)
# 在每一个类中有多少个点属于支持向量
print(clf.n_support_)
# 预测一个新的点
print(clf.predict([[2,0]]))
注释很详细
# 导入相关的包
import numpy as np
import pylab as pl # 绘图功能
from sklearn import svm
# 创建 40 个点
np.random.seed(0) # 让每次运行程序生成的随机样本点不变
# 生成训练实例并保证是线性可分的
# np._r表示将矩阵在行方向上进行相连
# random.randn(a,b)表示生成 a 行 b 列的矩阵,且随机数服从标准正态分布
# array(20,2) - [2,2] 相当于给每一行的两个数都减去 2
X = np.r_[np.random.randn(20, 2) - [2, 2], np.random.randn(20, 2) + [2, 2]]
# 两个类别 每类有 20 个点,Y 为 40 行 1 列的列向量
Y = [0] * 20 + [1] * 20
# 建立 svm 模型
clf = svm.SVC(kernel='linear')
clf.fit(X, Y)
# 获得划分超平面
# 划分超平面原方程:w0x0 + w1x1 + b = 0
# 将其转化为点斜式方程,并把 x0 看作 x,x1 看作 y,b 看作 w2
# 点斜式:y = -(w0/w1)x - (w2/w1)
w = clf.coef_[0] # w 是一个二维数据,coef 就是 w = [w0,w1]
a = -w[0] / w[1] # 斜率
xx = np.linspace(-5, 5) # 从 -5 到 5 产生一些连续的值(随机的)
# .intercept[0] 获得 bias,即 b 的值,b / w[1] 是截距
yy = a * xx - (clf.intercept_[0]) / w[1] # 带入 x 的值,获得直线方程
# 画出和划分超平面平行且经过支持向量的两条线(斜率相同,截距不同)
b = clf.support_vectors_[0] # 取出第一个支持向量点
yy_down = a * xx + (b[1] - a * b[0])
b = clf.support_vectors_[-1] # 取出最后一个支持向量点
yy_up = a * xx + (b[1] - a * b[0])
# 查看相关的参数值
print("w: ", w)
print("a: ", a)
print("support_vectors_: ", clf.support_vectors_)
print("clf.coef_: ", clf.coef_)
# 在 scikit-learin 中,coef_ 保存了线性模型中划分超平面的参数向量。形式为(n_classes, n_features)。若 n_classes > 1,则为多分类问题,(1,n_features) 为二分类问题。
# 绘制划分超平面,边际平面和样本点
pl.plot(xx, yy, 'k-')
pl.plot(xx, yy_down, 'k--')
pl.plot(xx, yy_up, 'k--')
# 圈出支持向量
pl.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1],
s=80, facecolors='none')
pl.scatter(X[:, 0], X[:, 1], c=Y, cmap=pl.cm.Paired)
pl.axis('tight')
pl.show()
结果
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9Ulqa7Zd-1669543808015)(SVM.assets/image-20221127180743657.png)]](https://img-blog.csdnimg.cn/05b92ce688c04f69bf1bb4e30e33bdba.png)