嗨,这里是清安,本章来学习学习获取精美壁纸。
视频教程:https://b23.tv/iR7bOFF
源码:https://gitee.com/qinganan_admin/reptile-case/tree/master/%E5%A3%81%E7%BA%B8
本视频还会有第二期,代码也会有第二份,第一份代码依旧保存。但是操作内容本章会全部写完。
废话不多说,先看壁纸,再看步骤。

1、抓包并定位元素
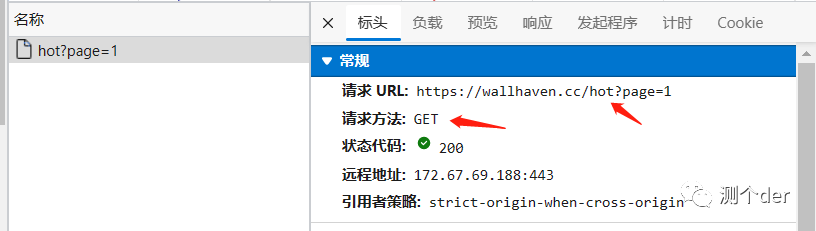
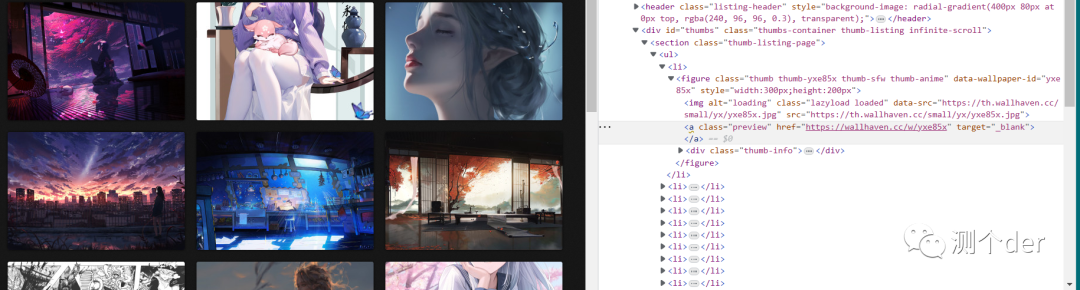
2、发起请求
「此处页数问题不大,因为不想写第二遍了,拿着视频中的代码写的。如果介意,可以把page=5改成page=1。」
url = 'https://wallhaven.cc/hot?page=5'
"""先看看能不能请求,以及内容是否正确"""
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.34"
}
res = requests.get(url=url, headers=headers)
print(res)3、初步定位元素
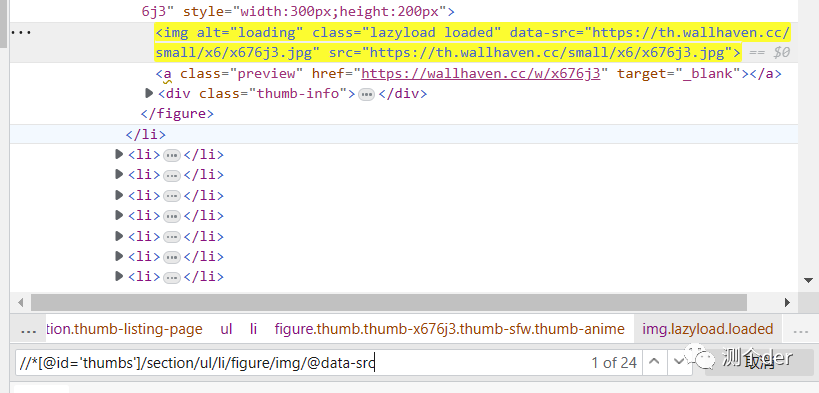
# //*[@id='thumbs']/section/ul/li/figure/img 定位元素
res_html = etree.HTML(res.text)
res_jpg = res_html.xpath("//*[@id='thumbs']/section/ul/li/figure/img/@data-src")
# print(len(res_jpg),res_jpg)4、下载本页的图片
def run(value):
value_url = requests.get(url=value, headers=headers)
with open(value[-10:],'wb') as w:
w.write(value_url.content)
print("加载成功~",value_url)5、运行
"""请求响应有点慢,导致下载有点慢(requests搞不定),只能通过其他手段提升一下速度---多线程"""
if __name__ == '__main__':
with ThreadPoolExecutor(max_workers=10) as pool:
pool.map(run, res_jpg)这里就不用单线程了,太慢了。
「以上部分爬取完后,会发现,图片模糊。并不高清,也不唯美,也不精致,那么我们重新定位一下。」
再写
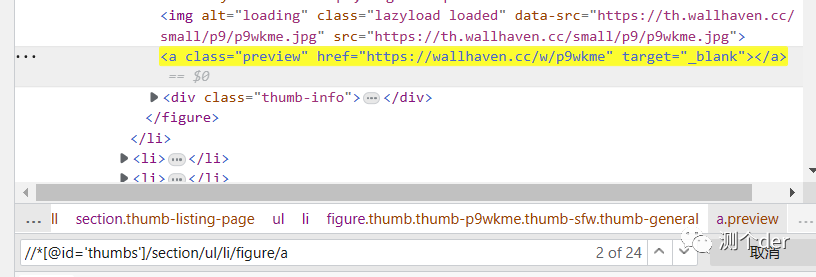
点进去:

再定位
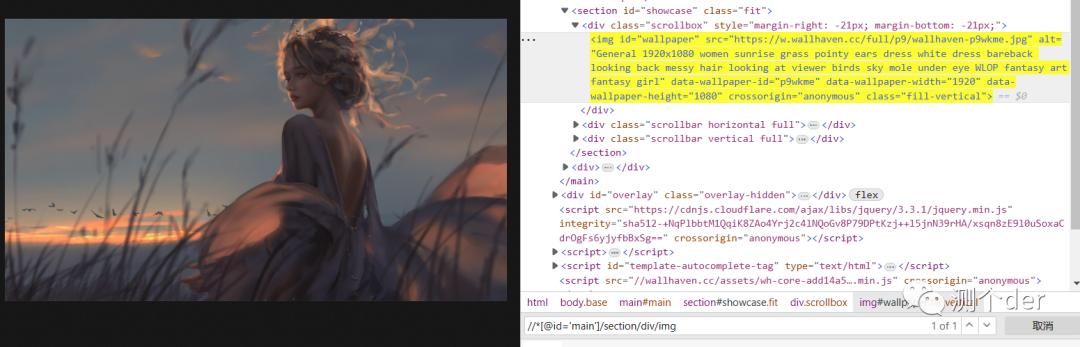
再次发起请求与获取链接
res_pic = requests.get(url=url, headers=headers)
res_pic_html = etree.HTML(res_pic.text)
res_pic_url = res_pic_html.xpath("//*[@id='main']/section/div/img/@src")下载成功-精美高清壁纸

第二部分代码只贴出了部分,具体代码请看gitee上的源码。
尽请期待第二期视频,地址还是文本开头地址中的博主(也就是我),视频中会录制出每一步的细节。
地址:壁纸/wallhaven高品质绝美壁纸下载.py · 清安无别事/爬虫案例 - Gitee.com