目录
- 一、使用 DataGen 造数据
- 1. DataStream 的 DataGenerator
- 2. SQL 的 DataGenerator
- 二、算子指定 UUID
- 三、链路延迟测量
- 四、开启对象重用
- 五、细粒度滑动窗口优化
一、使用 DataGen 造数据
开发完 Flink 作业,压测的方式很简单,先在 kafka 中积压数据,之后开启 Flink 任务,出现反压,就是处理瓶颈。相当于水库先积水,一下子泄洪。
数据可以是自己造的模拟数据,也可以是生产中的部分数据。造测试数据的工具:DataFactory、datafaker 、DBMonster、Data-Processer 、Nexmark、Jmeter 等。
Flink 从 1.11 开始提供了一个内置的 DataGen 连接器,主要是用于生成一些随机数,用于在没有数据源的时候,进行流任务的测试以及性能测试等。
1. DataStream 的 DataGenerator
import com.fancy.flink.tuning.bean.OrderInfo;
import com.fancy.flink.tuning.bean.UserInfo;
import org.apache.commons.math3.random.RandomDataGenerator;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.configuration.RestOptions;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.datagen.DataGeneratorSource;
import org.apache.flink.streaming.api.functions.source.datagen.RandomGenerator;
import org.apache.flink.streaming.api.functions.source.datagen.SequenceGenerator;
public class DataStreamDataGenDemo {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set(RestOptions.ENABLE_FLAMEGRAPH, true);
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
env.setParallelism(1);
env.disableOperatorChaining();
SingleOutputStreamOperator<OrderInfo> orderInfoDS = env
.addSource(
new DataGeneratorSource<>(new RandomGenerator<OrderInfo>() {
@Override
public OrderInfo next() {
return new OrderInfo(
random.nextInt(1, 100000),
random.nextLong(1, 1000000),
random.nextUniform(1, 1000),
System.currentTimeMillis()
);
}
})).returns(Types.POJO(OrderInfo.class));
SingleOutputStreamOperator<UserInfo> userInfoDS = env
.addSource(
new DataGeneratorSource<UserInfo>(
new SequenceGenerator<UserInfo>(1, 1000000) {
RandomDataGenerator random = new RandomDataGenerator();
@Override
public UserInfo next() {
return new UserInfo(
valuesToEmit.peek().intValue(),
valuesToEmit.poll().longValue(),
random.nextInt(1, 100),
random.nextInt(0, 1)
);
}
}
))
.returns(Types.POJO(UserInfo.class));
orderInfoDS.print("order>>");
userInfoDS.print("user>>");
env.execute();
}
}
2. SQL 的 DataGenerator
import org.apache.flink.configuration.Configuration;
import org.apache.flink.configuration.RestOptions;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
public class SQLDataGenDemo {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set(RestOptions.ENABLE_FLAMEGRAPH, true);
StreamExecutionEnvironment env =
StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
env.setParallelism(1);
env.disableOperatorChaining();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
String orderSql = "CREATE TABLE order_info (\n" +
" id INT,\n" +
" user_id BIGINT,\n" +
" total_amount DOUBLE,\n" +
" create_time AS localtimestamp,\n" +
" WATERMARK FOR create_time AS create_time\n" +
") WITH (\n" +
" 'connector' = 'datagen',\n" +
" 'rows-per-second'='20000',\n" +
" 'fields.id.kind'='sequence',\n" +
" 'fields.id.start'='1',\n" +
" 'fields.id.end'='100000000',\n" +
" 'fields.user_id.kind'='random',\n" +
" 'fields.user_id.min'='1',\n" +
" 'fields.user_id.max'='1000000',\n" +
" 'fields.total_amount.kind'='random',\n" +
" 'fields.total_amount.min'='1',\n" +
" 'fields.total_amount.max'='1000'\n" +
")";
String userSql="CREATE TABLE user_info (\n" +
" id INT,\n" +
" user_id BIGINT,\n" +
" age INT,\n" +
" sex INT\n" +
") WITH (\n" +
" 'connector' = 'datagen',\n" +
" 'rows-per-second'='20000',\n" +
" 'fields.id.kind'='sequence',\n" +
" 'fields.id.start'='1',\n" +
" 'fields.id.end'='100000000',\n" +
" 'fields.user_id.kind'='sequence',\n" +
" 'fields.user_id.start'='1',\n" +
" 'fields.user_id.end'='1000000',\n" +
" 'fields.age.kind'='random',\n" +
" 'fields.age.min'='1',\n" +
" 'fields.age.max'='100',\n" +
" 'fields.sex.kind'='random',\n" +
" 'fields.sex.min'='0',\n" +
" 'fields.sex.max'='1'\n" +
")";
tableEnv.executeSql(orderSql);
tableEnv.executeSql(userSql);
tableEnv.executeSql("select * from order_info").print();
// tableEnv.executeSql("select * from user_info").print();
}
}
二、算子指定 UUID
对于有状态的 Flink 应用,推荐给每个算子都指定唯一用户 ID(UUID)。 严格地说,仅需要给有状态的算子设置就足够了。但是因为 Flink 的某些内置算子(如 window)是有状态的,而有些是无状态的,可能用户不是很清楚哪些内置算子是有状态的,哪些不是。所以从实践经验上来说,我们建议每个算子都指定上 UUID。
默认情况下,算子 UID 是根据 JobGraph 自动生成的,JobGraph 的更改可能会导致UUID 改变。手动指定算子 UUID ,可以让 Flink 有效地将算子的状态从 savepoint 映射到作业修改后 (拓扑图可能也有改变) 的正确的算子上。比如替换原来的 Operator 实现、增加新的Operator、删除Operator等等,至少我们有可能与Savepoint中存储的Operator状态对应上。这是 savepoint 在 Flink 应用中正常工作的一个基本要素。Flink 算子的 UUID 可以通过 uid(String uid) 方法指定,通常也建议指定 name。
#算子.uid("指定 uid")
.reduce((value1, value2) -> Tuple3.of("uv", value2.f1, value1.f2 + value2.f2))
.uid("uv-reduce").name("uv-reduce")
1)提交案例:未指定 uid
bin/flink run \
-t yarn-per-job \
-d \
-p 5 \
-Drest.flamegraph.enabled=true \
-Dyarn.application.queue=test \
-Djobmanager.memory.process.size=1024mb \
-Dtaskmanager.memory.process.size=2048mb \
-Dtaskmanager.numberOfTaskSlots=2 \
-c com.fancy.flink.tuning.UvDemo \
/opt/module/flink-1.13.1/myjar/flink-tuning-1.0-SNAPSHOT.jar
触发保存点:
//直接触发
flink savepoint <jobId> [targetDirectory] [-yid yarnAppId] #on yarn 模式需要指定-yid 参数
//cancel 触发
flink cancel -s [targetDirectory] <jobId> [-yid yarnAppId] #on yarn 模式需要指定-yid 参数
bin/flink cancel -s hdfs://hadoop1:8020/flink-tuning/sp 98acff568e8f0827a67ff37648a29d7f -yid application_1640503677810_0017
修改代码,从 savepoint 恢复:
bin/flink run \
-t yarn-per-job \
-s hdfs://hadoop1:8020/flink-tuning/sp/savepoint-066c90-6edf948686f6 \
-d \
-p 5 \
-Drest.flamegraph.enabled=true \
-Dyarn.application.queue=test \
-Djobmanager.memory.process.size=1024mb \
-Dtaskmanager.memory.process.size=2048mb \
-Dtaskmanager.numberOfTaskSlots=2 \
-c com.fancy.flink.tuning.UvDemo \
/opt/module/flink-1.13.1/myjar/flink-tuning-1.0-SNAPSHOT.jar
报错如下:
Caused by: java.lang.IllegalStateException: Failed to rollback to checkpoint/savepoint
hdfs://hadoop1:8020/flink-tuning/sp/savepoint-066c90-6edf948686f6. Cannot map checkpoint/savepoint state for operator ddb598ad156ed281023ba4eebbe487e3 to the new program,
because the operator is not available in the new program. If you want to allow to skip this, you can set the --allowNonRestoredSt ate option on the CLI.
临时处理:在提交命令中添加–allowNonRestoredState (short: -n)跳过无法恢复的算子。
2)提交案例:指定 uid
bin/flink run \
-t yarn-per-job \
-d \
-p 5 \
-Drest.flamegraph.enabled=true \
-Dyarn.application.queue=test \
-Djobmanager.memory.process.size=1024mb \
-Dtaskmanager.memory.process.size=2048mb \
-Dtaskmanager.numberOfTaskSlots=2 \
-c com.fancy.flink.tuning.UidDemo \
/opt/module/flink-1.13.1/myjar/flink-tuning-1.0-SNAPSHOT.jar
触发保存点:
//cancel 触发 savepoint
bin/flink cancel -s hdfs://hadoop1:8020/flink-tuning/sp 272e5d3321c5c1481cc327f6abe8cf9c -yid application_1640268344567_0033
修改代码,从保存点恢复:
bin/flink run \
-t yarn-per-job \
-s hdfs://hadoop1:8020/flink-tuning/sp/savepoint-272e5d-d0c1097d23e0 \
-d \
-p 5 \
-Drest.flamegraph.enabled=true \
-Dyarn.application.queue=test \
-Djobmanager.memory.process.size=1024mb \
-Dtaskmanager.memory.process.size=2048mb \
-Dtaskmanager.numberOfTaskSlots=2 \
-c com.fancy.flink.tuning.UidDemo \
/opt/module/flink-1.13.1/myjar/flink-tuning-1.0-SNAPSHOT.jar
三、链路延迟测量
对于实时的流式处理系统来说,我们需要关注数据输入、计算和输出的及时性,所以处理延迟是一个比较重要的监控指标,特别是在数据量大或者软硬件条件不佳的环境下。Flink提供了开箱即用的 LatencyMarker 机制来测量链路延迟。开启如下参数:
metrics.latency.interval: 30000 #默认 0,表示禁用,单位毫秒
监控的粒度,分为以下 3 档:
➢ single:每个算子单独统计延迟;
➢ operator(默认值):每个下游算子都统计自己与 Source 算子之间的延迟;
➢ subtask:每个下游算子的 sub-task 都统计自己与 Source 算子的 sub-task 之间的延迟。
metrics.latency.granularity: operator #默认 operator
一般情况下采用默认的 operator 粒度即可,这样在 Sink 端观察到的 latency metric就是我们最想要的全链路(端到端)延迟。subtask 粒度太细,会增大所有并行度的负担,不建议使用。
LatencyMarker 不会参与到数据流的用户逻辑中的,而是直接被各算子转发并统计。
为了让它尽量精确,有两点特别需要注意:
➢ 保证 Flink 集群内所有节点的时区、时间是同步的:ProcessingTimeService 产生时间戳最终是靠 System.currentTimeMillis()方法,可以用 ntp 等工具来配置。
➢ metrics.latency.interval 的时间间隔宜大不宜小:一般配置成 30000(30 秒)左右。一是因为延迟监控的频率可以不用太频繁,二是因为 LatencyMarker 的处理也要消耗一定性能。
提交案例:
bin/flink run \
-t yarn-per-job \
-d \
-p 5 \
-Drest.flamegraph.enabled=true \
-Dyarn.application.queue=test \
-Djobmanager.memory.process.size=1024mb \
-Dtaskmanager.memory.process.size=2048mb \
-Dtaskmanager.numberOfTaskSlots=2 \
-Dmetrics.latency.interval=30000 \
-c com.fancy.flink.tuning.UidDemo \
/opt/module/flink-1.13.1/myjar/flink-tuning-1.0-SNAPSHOT.jar
可以通过下面的 metric 查看结果:
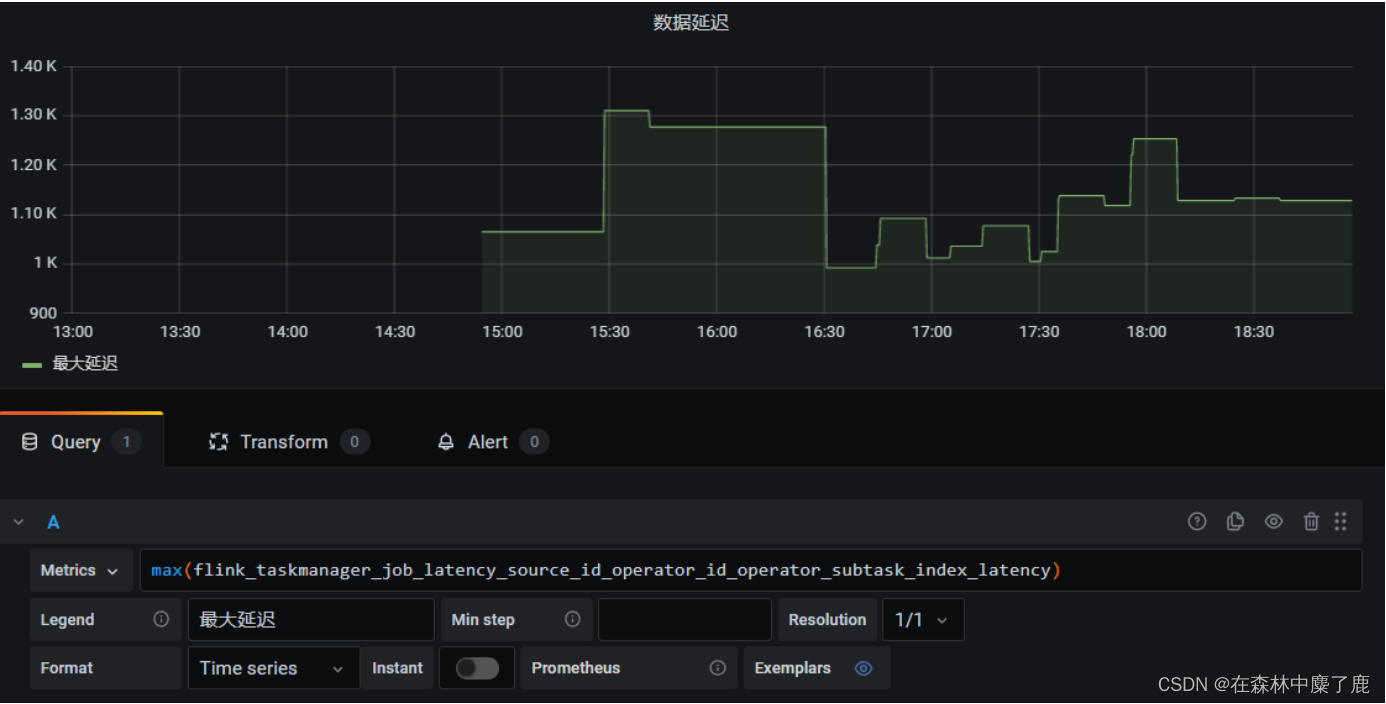
flink_taskmanager_job_latency_source_id_operator_id_operator_subtask_index_latency端到端延迟的 tag 只有 murmur hash 过的算子 ID (用 uid()方法设定的) ,并没有算子名称,(https://issues.apache.org/jira/browse/FLINK-8592) 并且官方暂时不打算解决这个问题,所以我们要么用最大值来表示,要么将作业中 Sink 算子的 ID 统一化。比如使用了 Prometheus 和 Grafana 来监控,效果如下:
四、开启对象重用
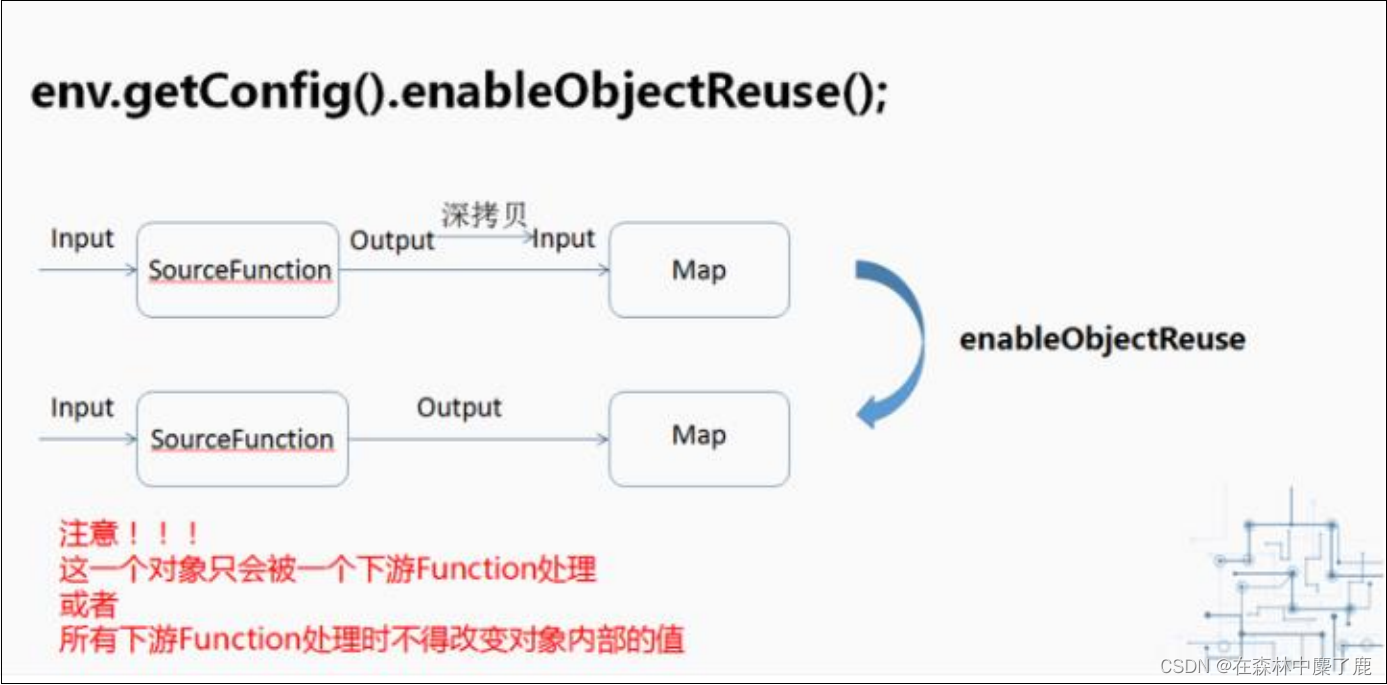
当调用了 enableObjectReuse 方法后,Flink 会把中间深拷贝的步骤都省略掉,SourceFunction 产生的数据直接作为 MapFunction 的输入,可以减少 gc 压力。但需要特别注意的是,这个方法不能随便调用,必须要确保下游 Function 只有一种,或者下游的 Function 均不会改变对象内部的值。否则可能会有线程安全的问题。
bin/flink run \
-t yarn-per-job \
-d \
-p 5 \
-Drest.flamegraph.enabled=true \
-Dyarn.application.queue=test \
-Djobmanager.memory.process.size=1024mb \
-Dtaskmanager.memory.process.size=2048mb \
-Dtaskmanager.numberOfTaskSlots=2 \
-Dpipeline.object-reuse=true \
-Dmetrics.latency.interval=30000 \
-c com.fancy.flink.tuning.UidDemo \
/opt/module/flink-1.13.1/myjar/flink-tuning-1.0-SNAPSHOT.jar
五、细粒度滑动窗口优化
1)细粒度滑动的影响
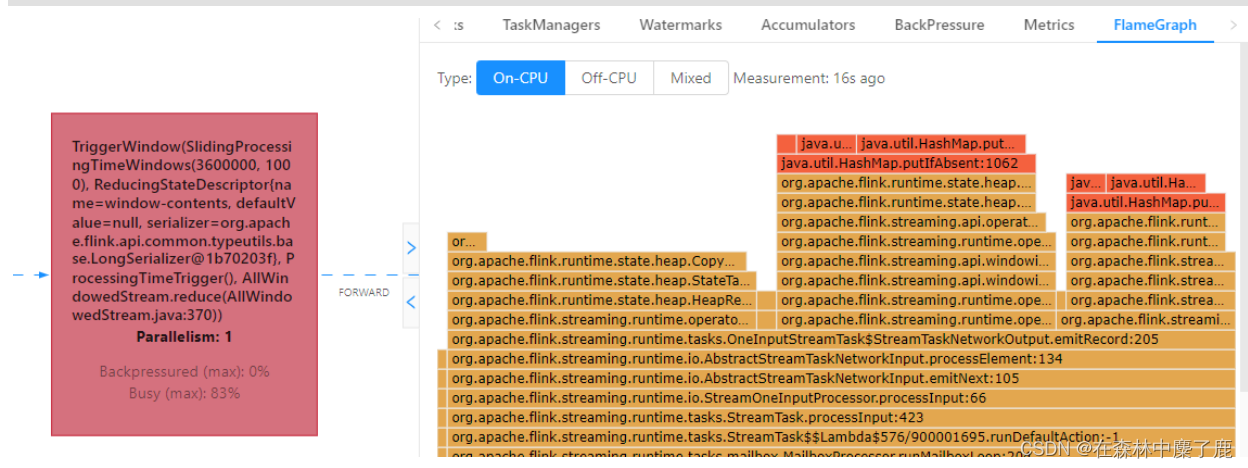
当使用细粒度的滑动窗口(窗口长度远远大于滑动步长)时,重叠的窗口过多,一个数据会属于多个窗口,性能会急剧下降。

我们经常会碰到这种需求:以 3 分钟的频率实时计算 App 内各个子模块近 24 小时的PV 和 UV。我们需要用粒度为 1440 / 3 = 480 的滑动窗口来实现它,但是细粒度的滑动窗口会带来性能问题,有两点:
➢ 状态
对于一个元素,会将其写入对应的(key, window)二元组所圈定的 windowState 状态中。如果粒度为 480,那么每个元素到来,更新 windowState 时都要遍历 480 个窗口并写入,开销是非常大的。在采用 RocksDB 作为状态后端时,checkpoint 的瓶颈也尤其明显。
➢ 定时器
每一个(key, window)二元组都需要注册两个定时器:一是触发器注册的定时器,用于决定窗口数据何时输出;二是 registerCleanupTimer()方法注册的清理定时器,用于在窗口彻底过期(如 allowedLateness 过期)之后及时清理掉窗口的内部状态。细粒度滑动窗口会造成维护的定时器增多,内存负担加重。
2)解决思路
DataStreamAPI中,自己解决(https://issues.apache.org/jira/browse/FLINK-7001)。我们一般使用滚动窗口+在线存储+读时聚合的思路作为解决方案:
(1)从业务的视角来看,往往窗口的长度是可以被步长所整除的,可以找到窗口长度和窗口步长的最小公约数作为时间分片 (一个滚动窗口的长度) ;
(2)每个滚动窗口将其周期内的数据做聚合,存到下游状态或打入外部在线存储 (内存数据库如 Redis,LSM-based NoSQL 存储如 HBase) ;
(3)扫描在线存储中对应时间区间 (可以灵活指定) 的所有行,并将计算结果返回给前端展示。
3)细粒度的滑动窗口案例
提交案例:统计最近 1 小时的 uv,1 秒更新一次(滑动窗口)
bin/flink run \
-t yarn-per-job \
-d \
-p 5 \
-Drest.flamegraph.enabled=true \
-Dyarn.application.queue=test \
-Djobmanager.memory.process.size=1024mb \
-Dtaskmanager.memory.process.size=2048mb \
-Dtaskmanager.numberOfTaskSlots=2 \
-c com.fancy.flink.tuning.SlideWindowDemo \
/opt/module/flink-1.13.1/myjar/flink-tuning-1.0-SNAPSHOT.jar \
--sliding-split false
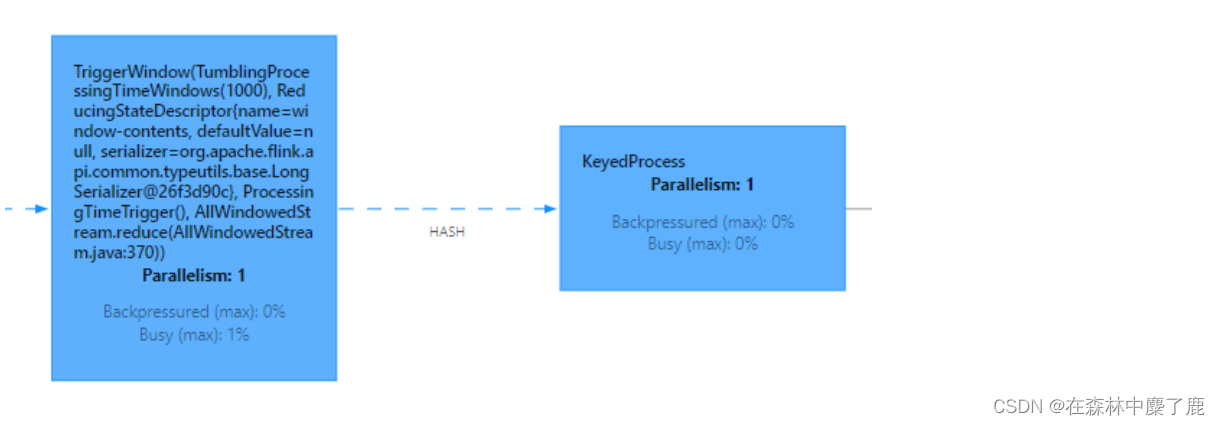
4)时间分片案例
提交案例:统计最近 1 小时的 uv,1 秒更新一次(滚动窗口+状态存储)
bin/flink run \
-t yarn-per-job \
-d \
-p 5 \
-Drest.flamegraph.enabled=true \
-Dyarn.application.queue=test \
-Djobmanager.memory.process.size=1024mb \
-Dtaskmanager.memory.process.size=2048mb \
-Dtaskmanager.numberOfTaskSlots=2 \
-c com.fancy.flink.tuning.SlideWindowDemo \
/opt/module/flink-1.13.1/myjar/flink-tuning-1.0-SNAPSHOT.jar \
--sliding-split true
Flink 1.13 对 SQL 模块的 Window TVF 进行了一系列的性能优化,可以自动对滑动窗口进行切片解决细粒度滑动问题。

https://nightlies.apache.org/flink/flink-docs-release-1.13/docs/dev/table/sql/queries/window-tvf/