进阶篇
1.1 映射专题
- Mybatis 框架之所以能够简化数据库操作,是因为他内部的映射机制,通过自动映射,进行数据的封装,我们只要符合映射规则,就可以快速高效的完成SQL操作的实现
- 既然 MybatisPlus 是基于Mybatis 的增强工具,所以也具有这样的映射规则
1.1.1 自动映射
- 表名和实体类名映射 -> 表名user 实体类名User 【类名首字母小写后和表名相同】
- 字段名和实体类属性名映射 -> 字段名name 实体类属性名name 【字段名和属性名相同】
- 字段名下划线命名方式和实体类属性小驼峰命名方式映射 -> 字段名 user_email 实体类属性名 userEmail
- MybatisPlus 支持这种映射规则,可以通过配置来设置 【在SpringBoot核心配置文件进行配置】
map-underscore-to-camel-case: true 表示支持下划线到驼峰的映射 map-underscore-to-camel-case: false 表示不支持下划线到驼峰的映射
1.1.2 表映射
- 如果我们的表名和实体类名不一致怎么办?
-
通过 @TableName() 注解指定映射的数据库表名,就会按照指定的表名进行映射
-
如:此时将数据库的表名改为powershop_user,要完成表名和实体类名的映射,需要将实体类名也要指定为 powershop_user
@Data @AllArgsConstructor @NoArgsConstructor @TableName("powershop_user") public class User { private Long id; private String name; private Integer age; private String email; } -
- 如果有很多实体类,对应到数据库中的很多表,我们不需要每个依次配置,只需要配置一个全局的设置,他都会给每个实体类名前面添加指定的前缀,这里我们演示一下全局配置的效果
mybatis-plus:
global-config:
db-config:
table-prefix: powershop_
1.1.3 字段映射
-
表映射说明了表名与实体类名不一致的解决方法,那么什么场景下会改变字段映射呢?
-
当数据库字段和表实体类的属性不一致时,我们可以使用 @TableField() 注解改变字段和属性的映射,让注解中的名称和表字段保持一致
@Data @AllArgsConstructor @NoArgsConstructor public class User { @TableField("username") private String name; } -
数据库字段和表实体类的属性一致,但是字段名为关键字,不能直接用于sql查询
@Data @AllArgsConstructor @NoArgsConstructor public class User { @TableField("`desc`") private String desc; }
1.1.4 字段失效
- 当数据库中有字段不希望被查询,我们可以通过
@TableField(select = false)来隐藏这个字段,那在拼接SQL语句的时候,就不会拼接这个字段@Data @AllArgsConstructor @NoArgsConstructor public class User { @TableField(select = false) private Integer age; }

1.1.5 视图属性
-
在实际开发中,有些字段不需要数据库存储,但是却需要展示,需要展示也就是意味着实体类中需要存在这个字段,我们称这些实体类中存在但是数据库中不存在的字段,叫做视图字段
-
根据之前的经验,框架会默认将实体类中的属性作为查询字段进行拼接,那我们来思考,像这种视图字段,能够作为查询条件么,显示是不能的。因为数据库中没有这个字段,所以查询字段如果包含这个字段,SQL语句会出现问题
-
我们通过
@TableField(exist = false)来去掉这个字段,不让他作为查询字段@Data @AllArgsConstructor @NoArgsConstructor public class User { @TableField(exist = false) private Integer online; }

1.2 条件构造器
- 什么是条件构造器?
- 条件构造器(Wrapper)是MyBatisPlus框架提供的一种方便的查询构建器,用于构建复杂的查询条件。
- 它是基于Lambda表达式的,可以使用面向对象的方式构建查询条件,不需要写复杂的SQL语句,大大简化了数据库操作代码的编写。
1️⃣ 条件构造器图谱
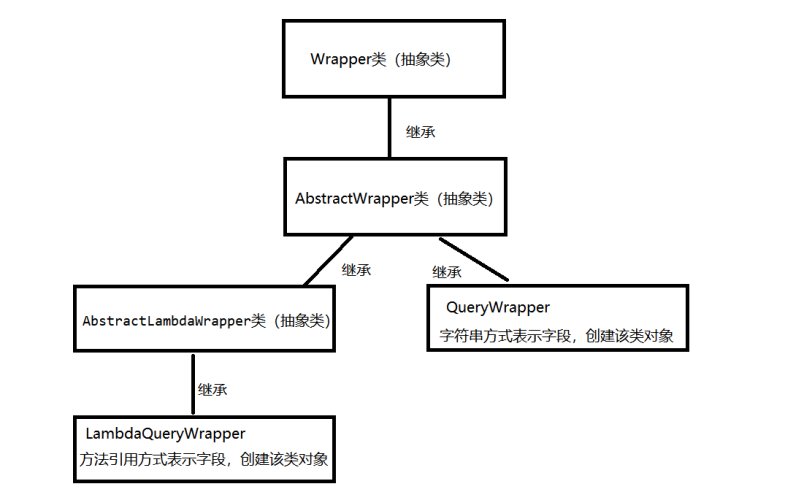
2️⃣ 展开介绍
- Wrapper 抽象类,条件类的顶层,提供了一些获取和判断相关的方法
- AbstractWrapper 抽象类,Wrapper的子类,提供了所有的条件相关方法
- AbstractLambdaWrapper 抽象类,AbstractWrapper的子类,确定字段参数为方法引用类型
- QueryWrapper 类,AbstractWrapper的子类,如果我们需要传递String类型的字段信息,创建该对象
- LambdaQueryWrapper 类,AbstractLambdaWrapper的子类,如果我们需要传递方法引用方式的字段信息,创建该对象
3️⃣ 我们在编写代码的时候,只需要关注QueryWrapper和LambdaQueryWrapper
1.3 查询专题
1.3.1 等值查询
1️⃣ eq 等值查询
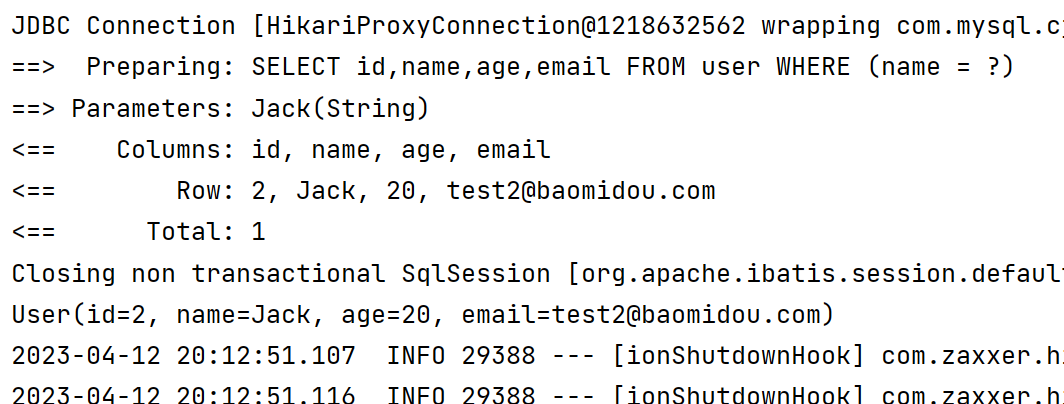
(1)使用QueryWrapper对象,构建查询条件
@Test
void eq() {
//创建我们QueryWrapper对象 [创建条件查询对象]
QueryWrapper<User> userQueryWrapper = new QueryWrapper<>();
//添加我们的查询条件 [此处演示的是等值查询] [设置查询条件,指定查询字段和匹配的值]
userQueryWrapper.eq("name", "Jack");
//调用我们的接口对象的方法 [进行条件查询]
User user = userMapper.selectOne(userQueryWrapper);
System.out.println(user);
}
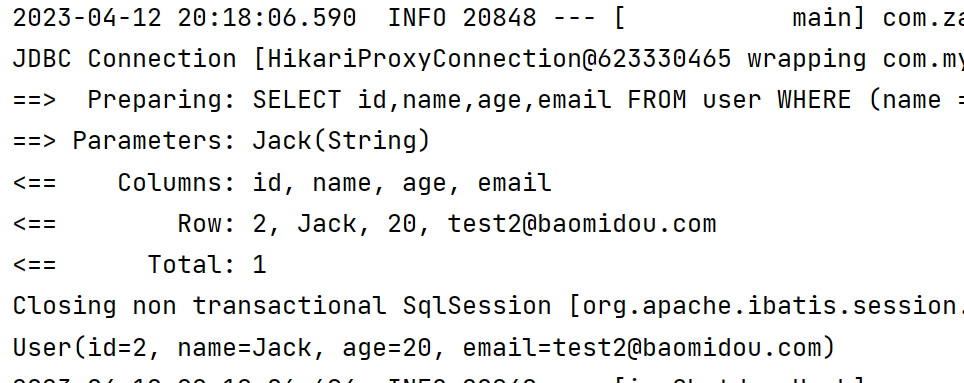
(2)使用 LambdaQueryWrapper 对象,构建查询条件
- 在构建字段时,使用方法引用的方式来选择字段,这样做可以避免字段拼写错误出现问题
@Test
void eq2() {
LambdaQueryWrapper<User> userLambdaQueryWrapper = new LambdaQueryWrapper<>();
userLambdaQueryWrapper.eq(User::getName, "Jack");
User user = userMapper.selectOne(userLambdaQueryWrapper);
System.out.println(user);
}
-
还要考虑一种情况,我们构建的条件是从哪里来的?
- 应该是从客户端通过请求发送过来的,由服务端接收的。
- 在网站中一般都会有多个条件入口,用户可以选择一个或多个条件进行查询,那这个时候在请求时,我们不能确定所有的条件都是有值的,部分条件可能用户没有传值,那该条件就为null。
- 比如在电商网站中,可以选择多个查询条件
-
那为null的条件,我们是不需要进行查询条件拼接的,否则就会出现如下情况,将为null的条件进行拼接,筛选后无法查询出结果
@Test
void isNull() {
LambdaQueryWrapper<User> userLambdaQueryWrapper = new LambdaQueryWrapper<>();
userLambdaQueryWrapper.eq(User::getName, null);
User user = userMapper.selectOne(userLambdaQueryWrapper);
System.out.println(user);
}
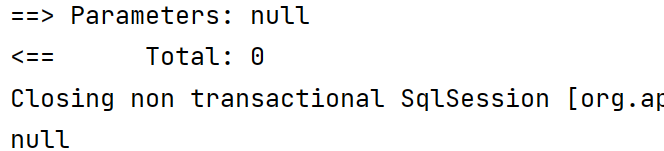
- 当然我们要解决这个问题,可以先判断是否为空,根据判断结果选择是否拼接该字段,这个功能其实不需要我们写,由MybatisPlus的方法已经提供好了。

@Test
void isNull2() {
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
String name = null;
lambdaQueryWrapper.eq(name != null, User::getName, name);
List<User> users = userMapper.selectList(lambdaQueryWrapper);
System.out.println(users);
}

2️⃣ allEq
(1)先演示一下如何通过多个eq,构建多条件查询【这部分也可以采用链式调用】
@Test
void allEq1() {
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.eq(User::getName, "Tom");
lambdaQueryWrapper.eq(User::getAge, 28);
User user = userMapper.selectOne(lambdaQueryWrapper);
System.out.println(user);
}
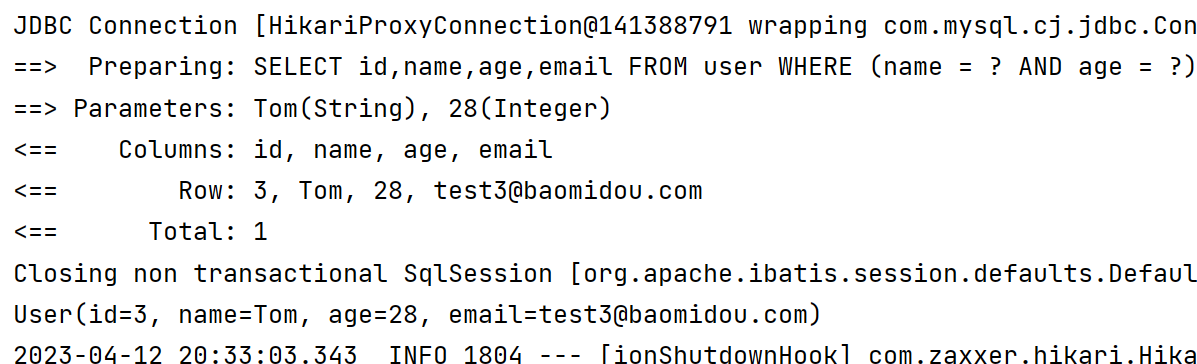
(2)如果此时有多个条件需要同时判断,我们可以将这多个条件放入到Map集合中,更加的方便
@Test
void allEq2() {
//创建一个集合来保存我们的多个查询条件
HashMap<String, Object> hashMap = new HashMap<>();
hashMap.put("name", "Tom");
//此处测试修改参数值为null
hashMap.put("age", null);
//此时不能使用我们的LambdaQueryWrapper了,只能用QueryWrapper
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.allEq(hashMap, true);
User user = userMapper.selectOne(queryWrapper);
System.out.println(user);
}
-
allEq(Map<R, V> params, boolean null2IsNull)
- 参数params:表示传递的Map集合
- 参数null2IsNull:表示对于为null的条件是否判断isNull
-
第二个参数设置为 false 的效果就是如果字段值为空,那么就不会拼接为查询条件

3️⃣ ne 不等查询
@Test
void ne() {
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.ne(User::getName, "Tom");
List<User> users = userMapper.selectList(lambdaQueryWrapper);
System.out.println(users);
}

1.3.2 范围查询
1️⃣ gt 大于
@Test
void gt() {
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.gt(User::getAge, 19);
List<User> users = userMapper.selectList(lambdaQueryWrapper);
System.out.println(users);
}

2️⃣ ge 大于等于
@Test
void ge() {
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.ge(User::getAge, 18);
List<User> users = userMapper.selectList(lambdaQueryWrapper);
System.out.println(users);
}
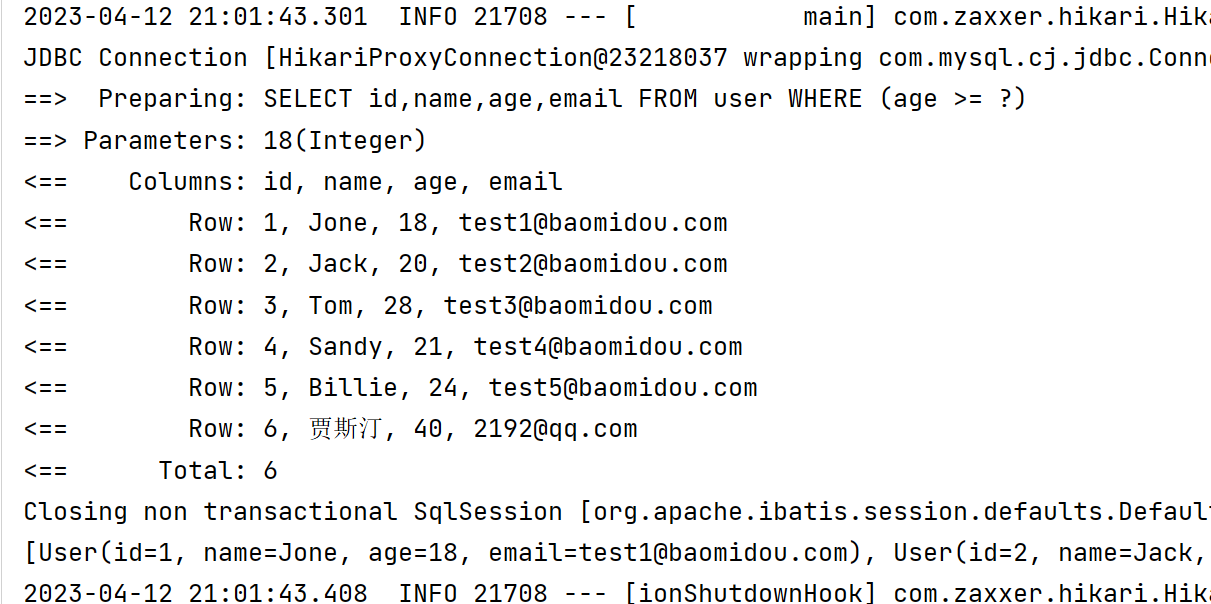
3️⃣ lt 小于
@Test
void lt() {
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.lt(User::getAge, 19);
List<User> users = userMapper.selectList(lambdaQueryWrapper);
System.out.println(users);
}
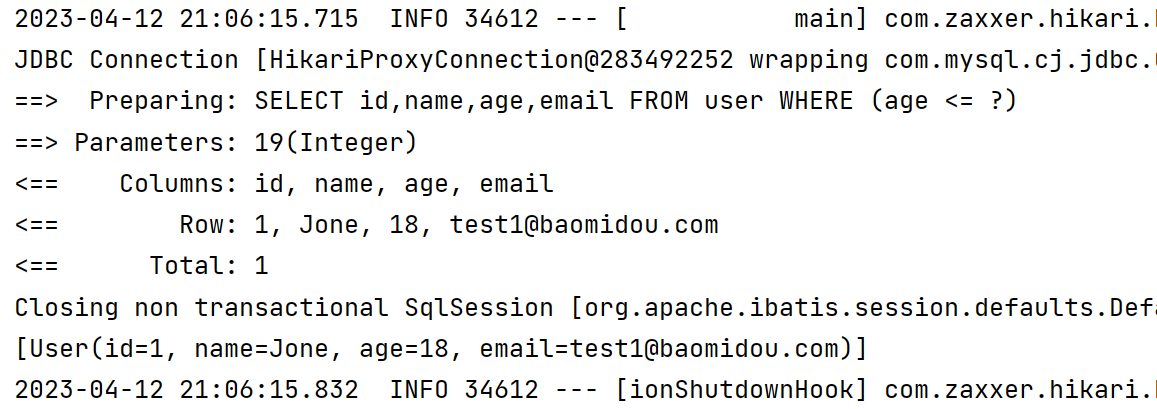
4️⃣ le 小于等于
@Test
void le() {
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.le(User::getAge, 20);
List<User> users = userMapper.selectList(lambdaQueryWrapper);
System.out.println(users);
}
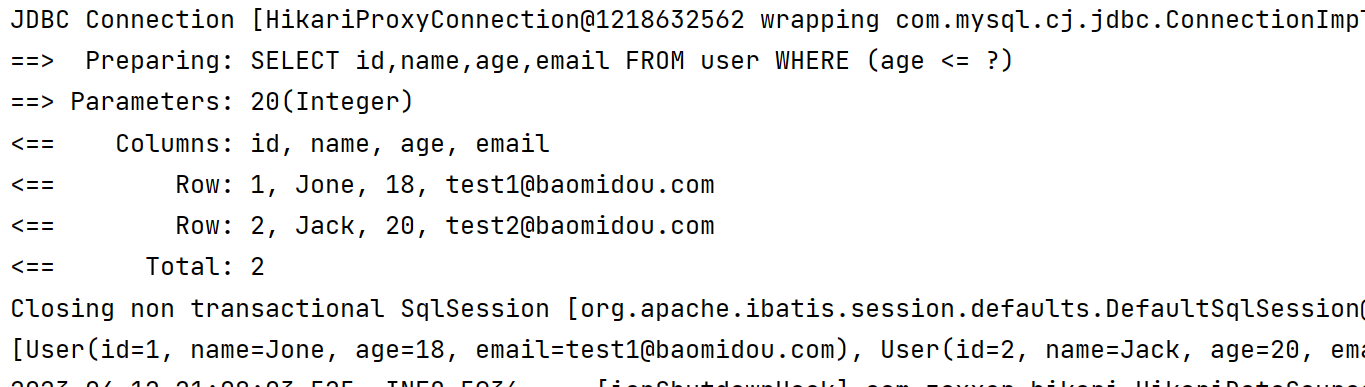
5️⃣ between 在范围内 【包括端点值】
@Test
void between() {
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.between(User::getAge, 18, 21);
List<User> users = userMapper.selectList(lambdaQueryWrapper);
System.out.println(users);
}

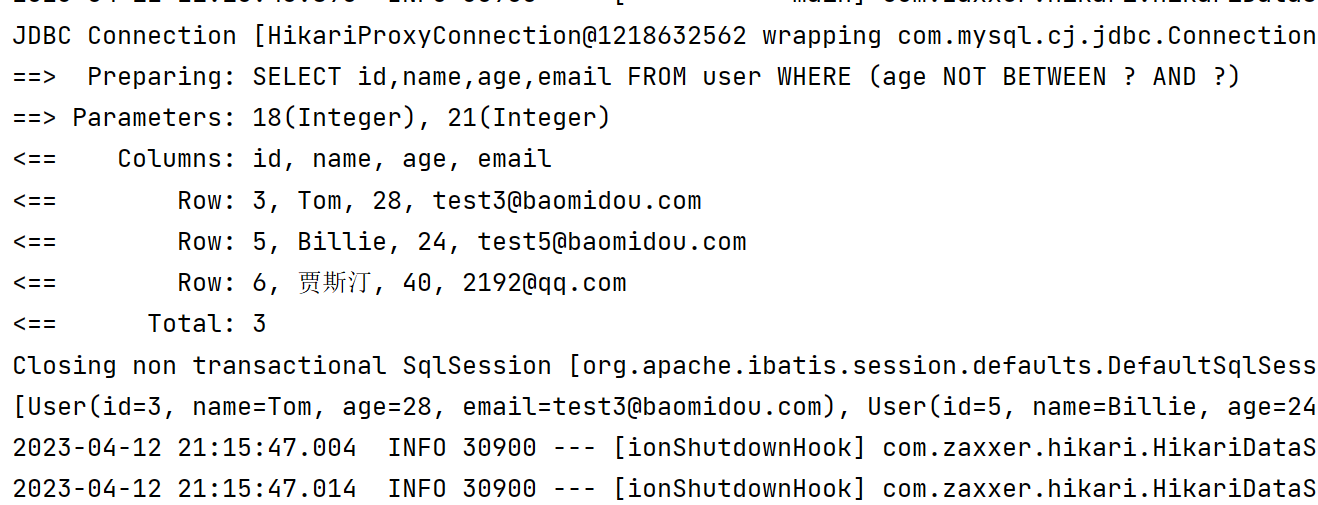
6️⃣ notBetween 不在范围内
@Test
void notBetween() {
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.notBetween(User::getAge, 18, 21);
List<User> users = userMapper.selectList(lambdaQueryWrapper);
System.out.println(users);
}
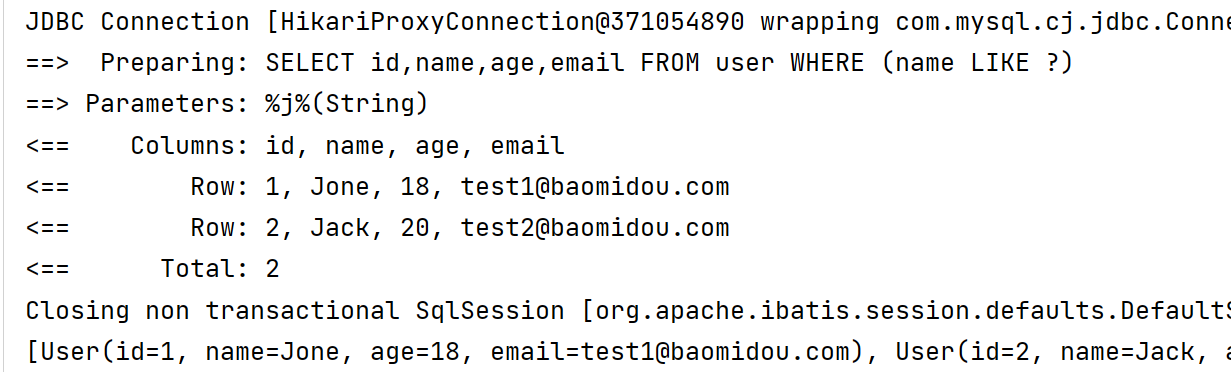
1.3.3 模糊查询
1️⃣ like 模糊查询
@Test
void like() {
LambdaQueryWrapper<User> userLambdaQueryWrapper = new LambdaQueryWrapper<>();
userLambdaQueryWrapper.like(User::getName, "j");//全模糊匹配,只要包含J
List<User> users = userMapper.selectList(userLambdaQueryWrapper);
System.out.println(users);
}
2️⃣ notLike 模糊查询
@Test
void notLike() {
LambdaQueryWrapper<User> userLambdaQueryWrapper = new LambdaQueryWrapper<>();
userLambdaQueryWrapper.notLike(User::getName, "j");//全模糊匹配,只要包含J
List<User> users = userMapper.selectList(userLambdaQueryWrapper);
System.out.println(users);
}
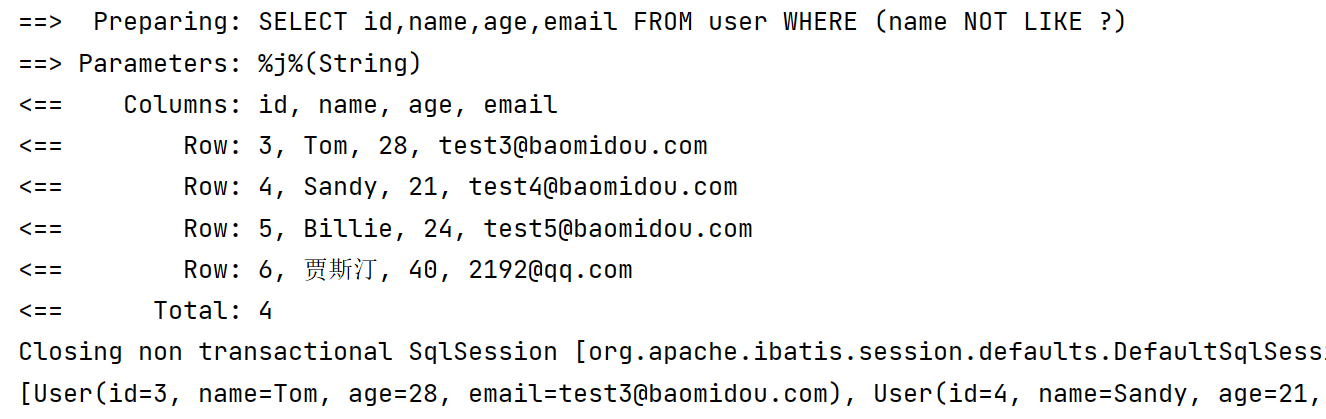
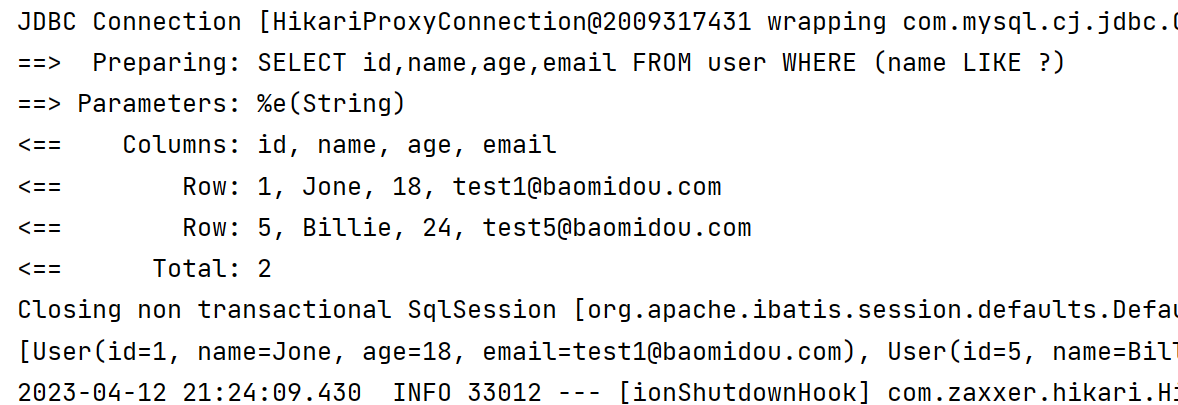
3️⃣ likeLeft 模糊查询 【以XXX结尾】
@Test
void likeLeft() {
LambdaQueryWrapper<User> userLambdaQueryWrapper = new LambdaQueryWrapper<>();
userLambdaQueryWrapper.likeLeft(User::getName, "e");//以XX结尾
List<User> users = userMapper.selectList(userLambdaQueryWrapper);
System.out.println(users);
}
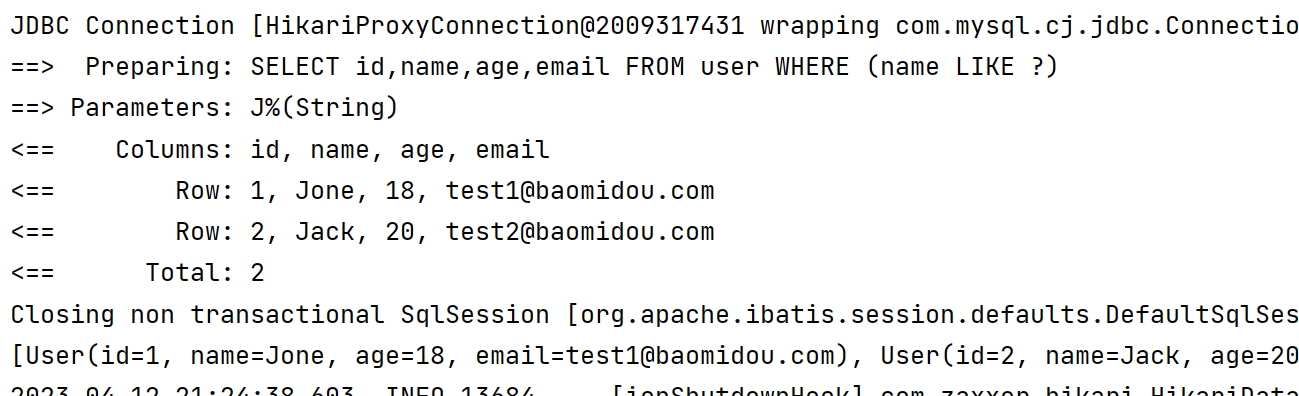
4️⃣ likeRight 模糊查询【以XXX开头】
@Test
void likeRight() {
LambdaQueryWrapper<User> userLambdaQueryWrapper = new LambdaQueryWrapper<>();
userLambdaQueryWrapper.likeRight(User::getName, "J");//以XX开头
List<User> users = userMapper.selectList(userLambdaQueryWrapper);
System.out.println(users);
}
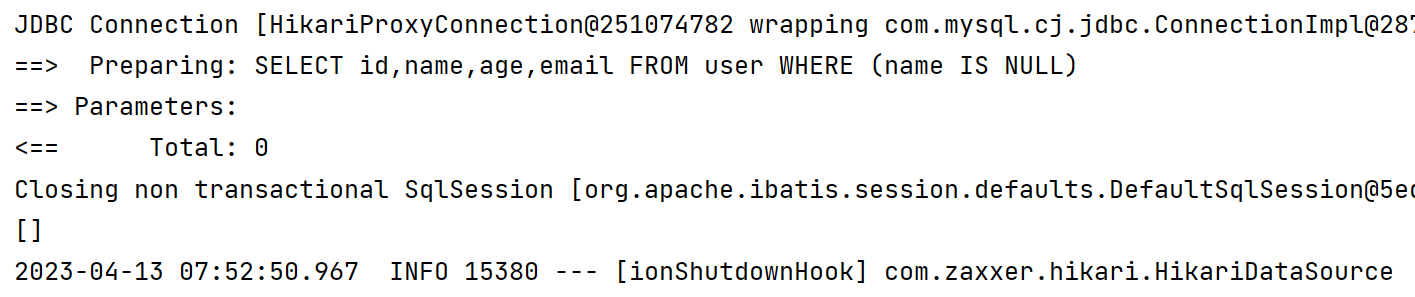
1.3.4 判空查询
1️⃣ isNull 是否为空
@Test
void isNull3() {
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.isNull(User::getName);
List<User> users = userMapper.selectList(lambdaQueryWrapper);
System.out.println(users);
}
2️⃣ isNotNull 是否不为空
@Test
void isNotNull() {
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.isNotNull(User::getName);
List<User> users = userMapper.selectList(lambdaQueryWrapper);
System.out.println(users);
}
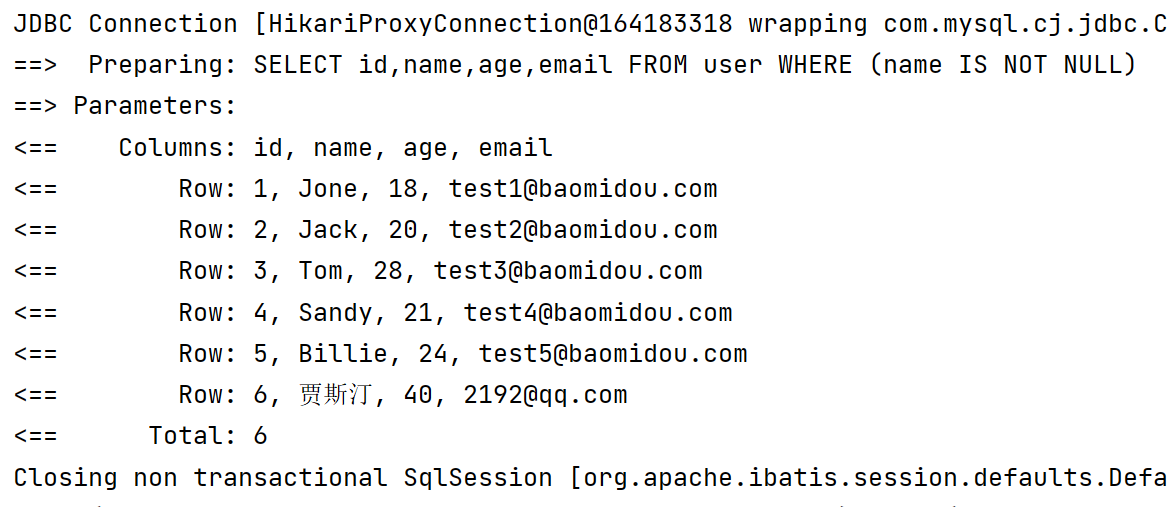
1.3.5 包含查询
1️⃣ in 包含在范围内 【也可以用or实现】
@Test
void in() {
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
ArrayList<Integer> arrayList = new ArrayList<>();
Collections.addAll(arrayList, 18, 20, 21);
lambdaQueryWrapper.in(User::getAge, arrayList);
List<User> users = userMapper.selectList(lambdaQueryWrapper);
System.out.println(users);
}
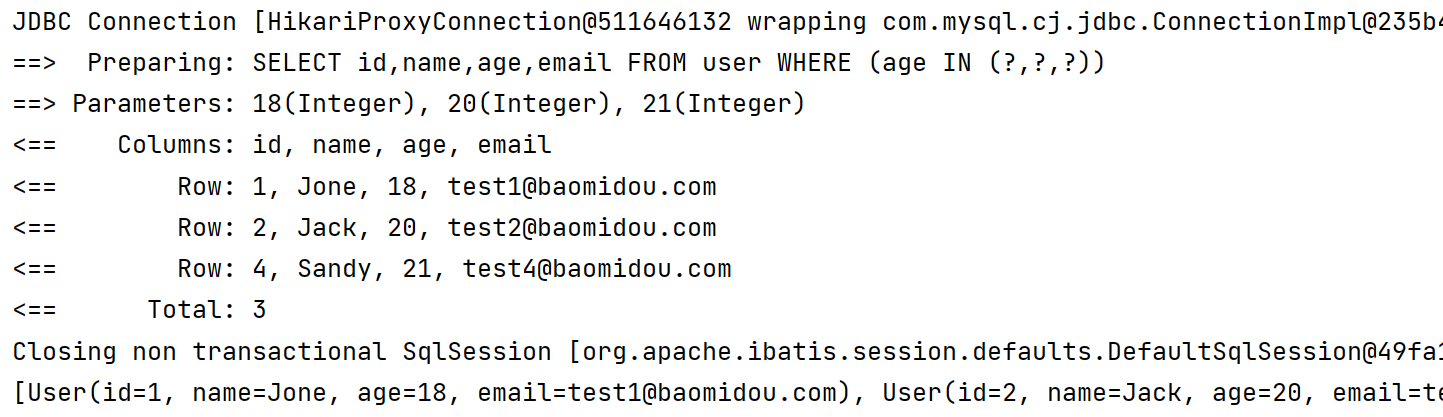
2️⃣ notIn 不包含在范围内
@Test
void notIn() {
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
ArrayList<Integer> arrayList = new ArrayList<>();
Collections.addAll(arrayList, 18, 20, 21);
lambdaQueryWrapper.notIn(User::getAge, arrayList);
List<User> users = userMapper.selectList(lambdaQueryWrapper);
System.out.println(users);
}
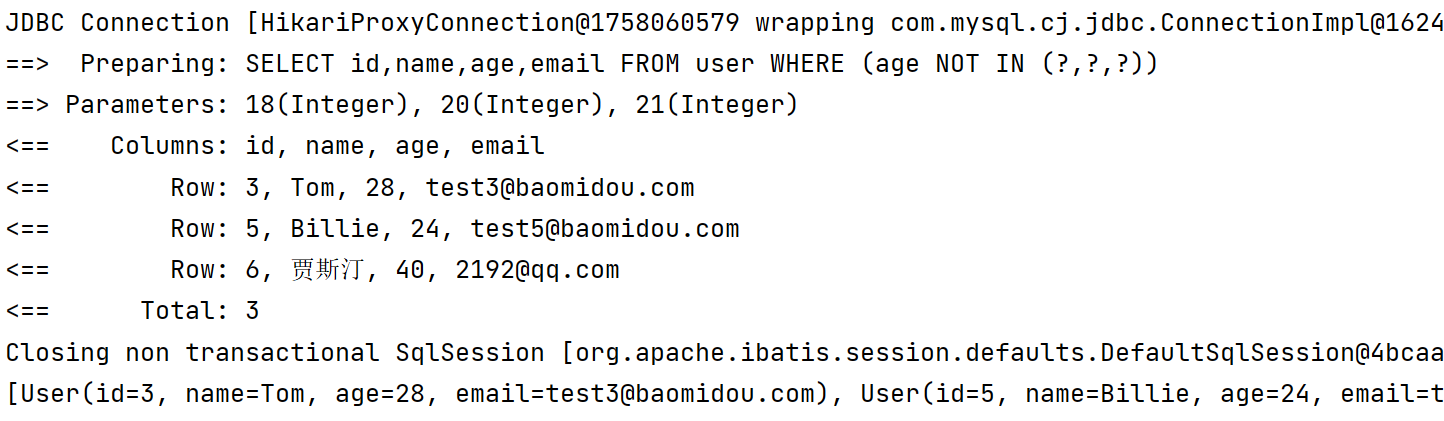
3️⃣ inSql 包含在范围内(自己拼接SQL的形式)
- 通过自己拼接SQL的方式来完成包含查询
- 字节写个字符串充当集合,多个元素用逗号分隔开
- 也可以通过 inSql 实现嵌套查询,将一个查询结果作为另一个查询条件
@Test
void inSql() {
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.inSql(User::getAge, "18, 20, 22");
List<User> users = userMapper.selectList(lambdaQueryWrapper);
System.out.println(users);
}

@Test
void inSql2() {
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.inSql(User::getAge, "select age from user where age > 20");
List<User> users = userMapper.selectList(lambdaQueryWrapper);
System.out.println(users);
}
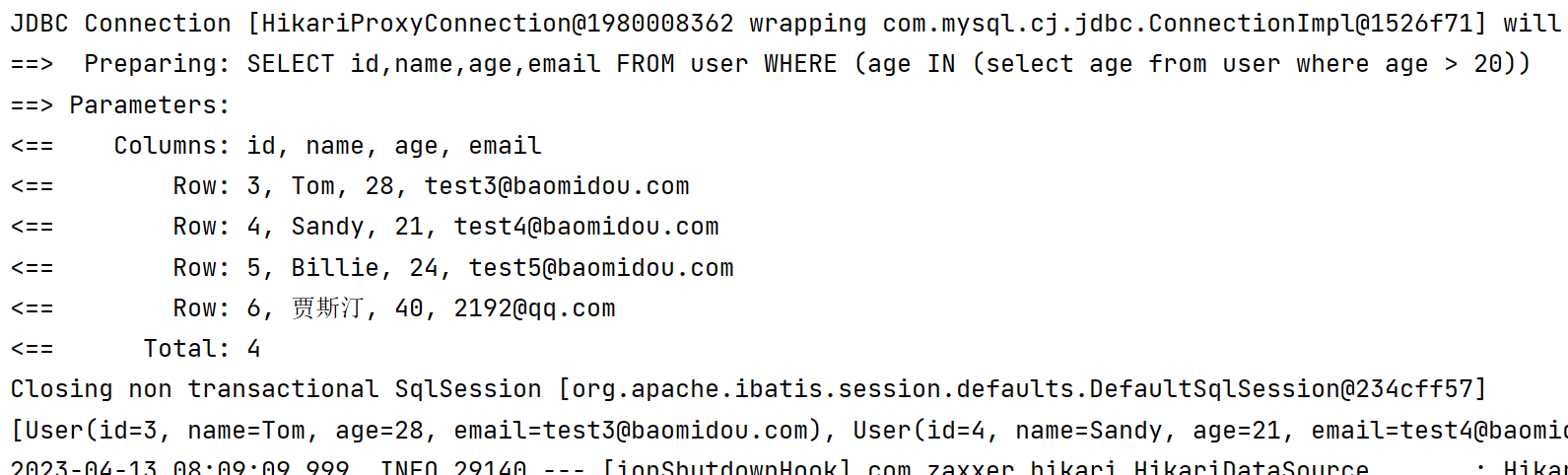
4️⃣ notInSql 不包含在范围内(自己拼接SQL的形式)
@Test
void notInSql() {
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.notInSql(User::getAge, "18, 20, 22");
List<User> users = userMapper.selectList(lambdaQueryWrapper);
System.out.println(users);
}
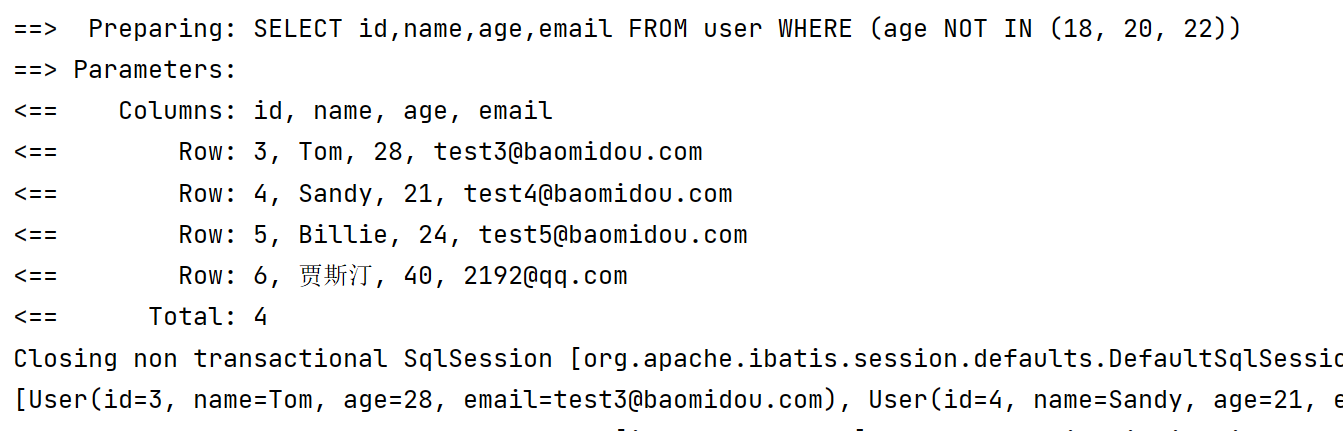
@Test
void notInSql2() {
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.notInSql(User::getAge, "select age from user where age > 20");
List<User> users = userMapper.selectList(lambdaQueryWrapper);
System.out.println(users);
}

1.3.6 分组查询
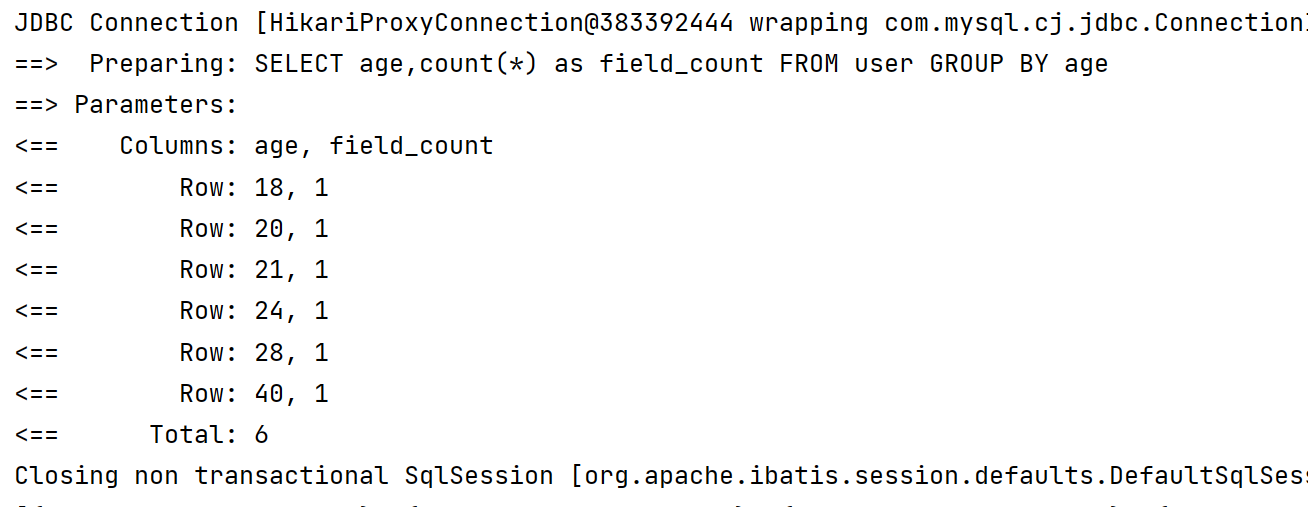
1️⃣ groupBy 按指定字段分组
@Test
void groupBy() {
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
//分组字段,我们通过groupBy方法指定按哪个字段分组
queryWrapper.groupBy("age");
//查询字段,我们要查询出来哪些数据
queryWrapper.select("age", "count(*) as field_count");
List<Map<String, Object>> maps = userMapper.selectMaps(queryWrapper);
System.out.println(maps);
}
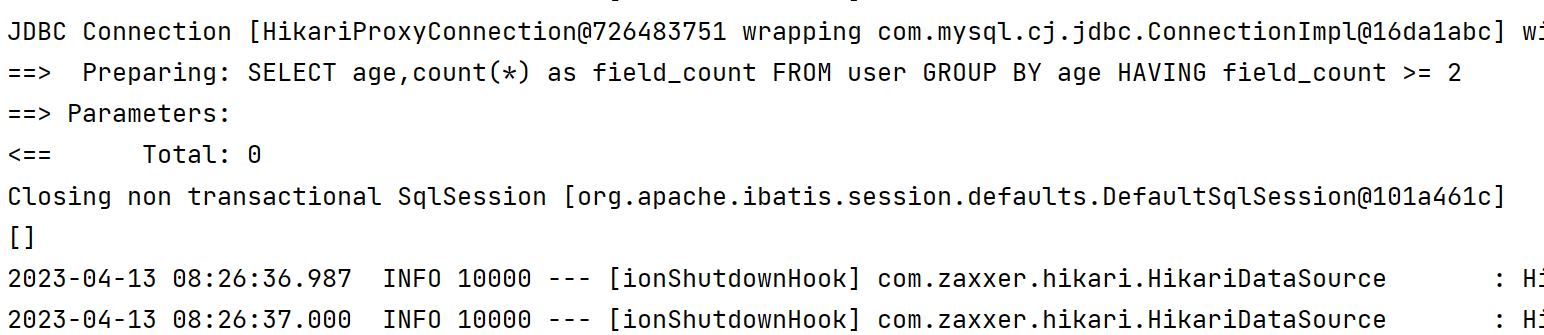
1.3.7 聚合查询
- 在分组查询的基础上,通过 having 来实现聚合查询

@Test
void having() {
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
//分组字段
queryWrapper.groupBy("age");
//查询字段
queryWrapper.select("age", "count(*) as field_count");
//聚合筛选
queryWrapper.having("field_count >= 2");
List<Map<String, Object>> maps = userMapper.selectMaps(queryWrapper);
System.out.println(maps);
}
1.3.8 排序查询
1️⃣ orderByAsc 升序查询
@Test
void orderByAsc() {
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.orderByAsc(User::getAge, User::getId);
List<User> users = userMapper.selectList(lambdaQueryWrapper);
System.out.println(users);
}
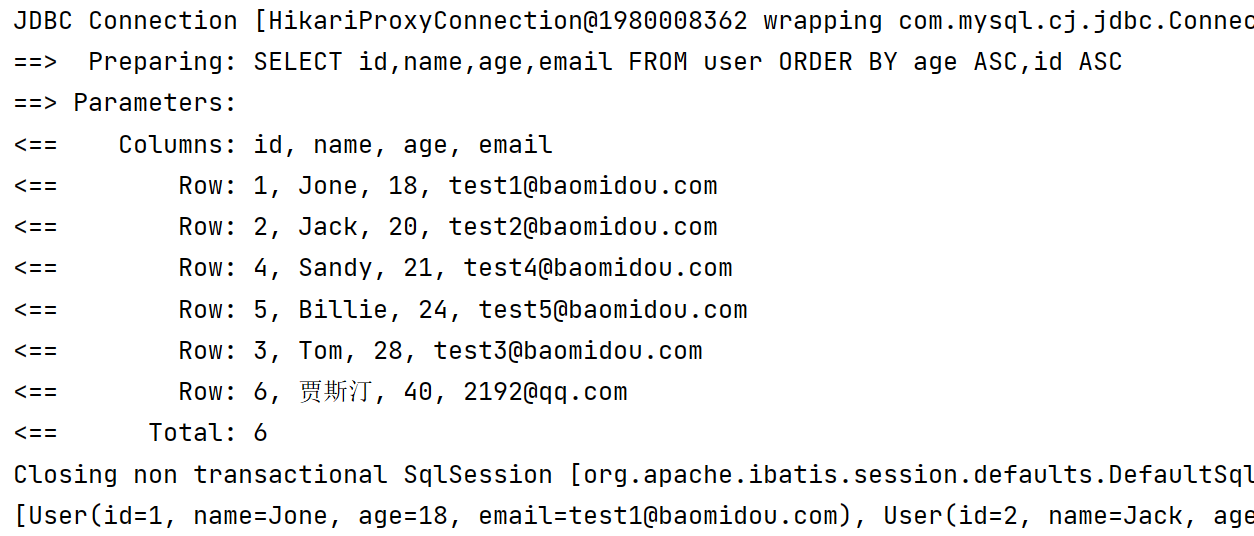
2️⃣ orderByDesc 降序查询
@Test
void orderByDesc() {
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.orderByDesc(User::getAge, User::getId);
List<User> users = userMapper.selectList(lambdaQueryWrapper);
System.out.println(users);
}
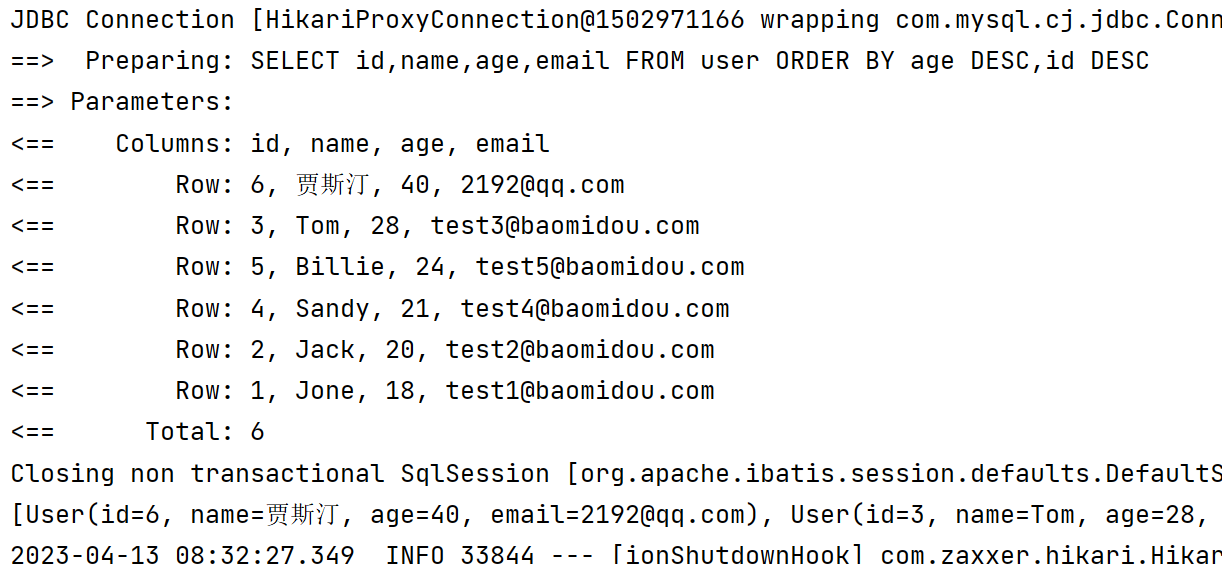
3️⃣ orderBy 可同时指定升序降序查询
- 自己定制实现根据某些字段做升序、某些字段做降序排序
- 多次调用 orderBy 方法
- 第一个参数代表 如果字段值为空,是否还参与排序
- 第二个参数代表 是否为升序排序
- 第三个参数代表 我们选择排序的字段
@Test
void orderBy(){
LambdaQueryWrapper<User> userLambdaQueryWrapper = new LambdaQueryWrapper<>();
userLambdaQueryWrapper.orderBy(false, true, User::getAge);
userLambdaQueryWrapper.orderBy(true, false, User::getId);
List<User> users = userMapper.selectList(userLambdaQueryWrapper);
System.out.println(users);
}

- 有一个需要注意的地方:说明我们将orderBy的第一个条件设置为 false,那么只要查询范围内有一条数据的age为空,那么就会导致 age 这个字段不参与排序
1.3.9 func查询
- 根据不同的业务情况来封装查询条件:【此处为了演示效果直接指定了boolean的类型】
- 就是不同条件下我们的查询内容是不同的
1️⃣ 使用匿名内部类的形式 【可以简化为 Lambda 表达式的形式】

2️⃣ 下面为简化为Lambda表达式的形式
- 在上面的代码按 Alt + Enter 就会提示我们进行转换

@Test
void func(){
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.func(userLambdaQueryWrapper -> {
if(true){
lambdaQueryWrapper.eq(User::getId, 1);
}else {
lambdaQueryWrapper.ne(User::getId, 1);
}
});
List<User> users = userMapper.selectList(lambdaQueryWrapper);
System.out.println(users);
}
- 引申知识点:
- 什么情况下, Java匿名内部类可以简化为Lambda表达式形式

- 接口中的方法不都是抽象方法吗?

- 什么情况下, Java匿名内部类可以简化为Lambda表达式形式
1.3.10 逻辑查询
1️⃣ and 与查询
- 我们通过链式调用,默认就是与查询
@Test
void and(){
LambdaQueryWrapper<User> userLambdaQueryWrapper = new LambdaQueryWrapper<>();
userLambdaQueryWrapper.gt(User::getAge, 18).lt(User::getAge, 22);
List<User> users = userMapper.selectList(userLambdaQueryWrapper);
System.out.println(users);
}
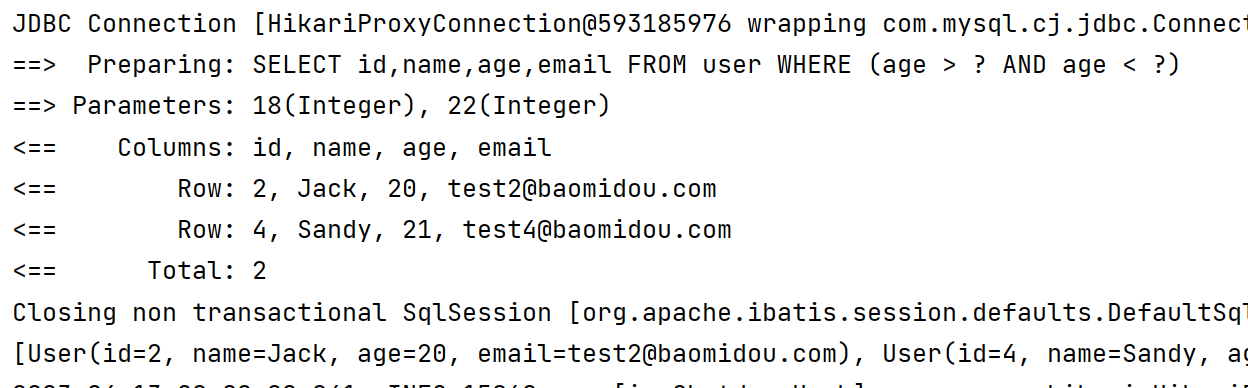
- 也可以采用嵌套的方式实现与查询

@Test
void and2(){
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
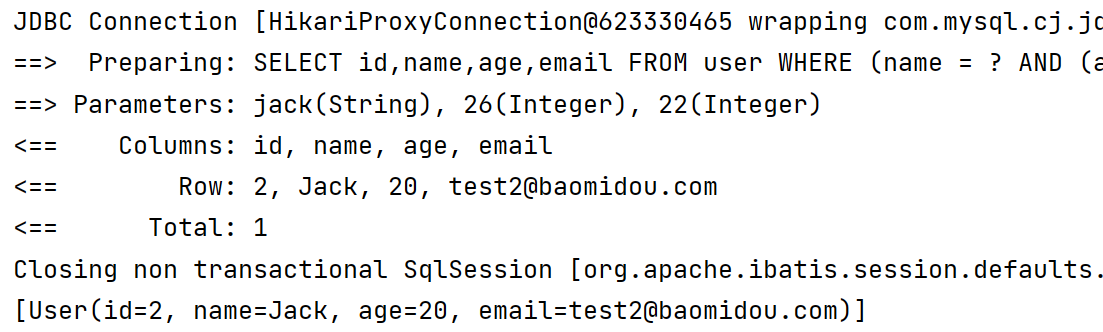
lambdaQueryWrapper.eq(User::getName, "jack").and(i -> i.gt(User::getAge, 26).or().lt(User::getAge, 22));
List<User> users = userMapper.selectList(lambdaQueryWrapper);
System.out.println(users);
}
2️⃣ or 或查询
- 链式查询直接点调用 or() 代表或查询
@Test
void or(){
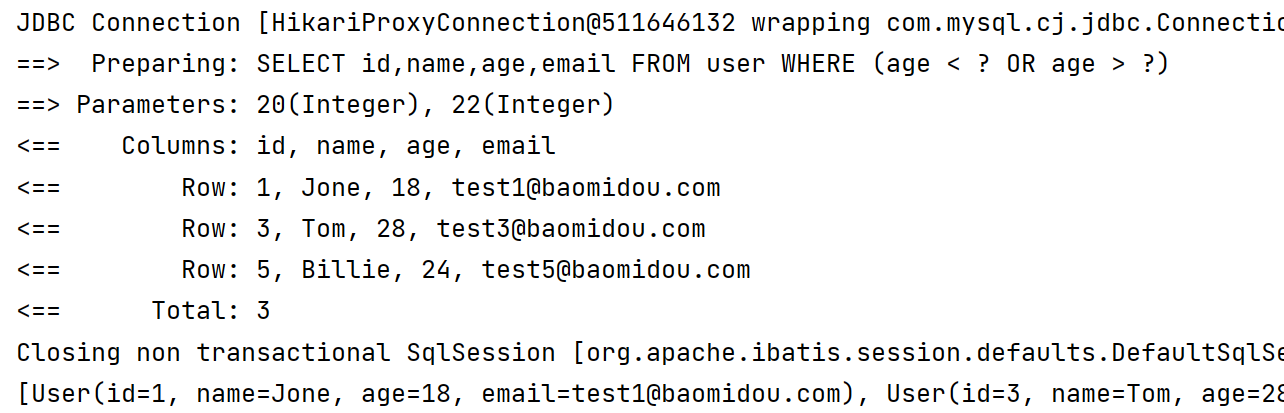
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.lt(User::getAge, 20).or().gt(User::getAge, 22);
List<User> users = userMapper.selectList(lambdaQueryWrapper);
System.out.println(users);
}
- 当然我们的或查询也支持嵌套调用
- 我们需要注意,是先完成内部查询再完成外部查询(先满足最内层的查询条件进行筛选)
@Test
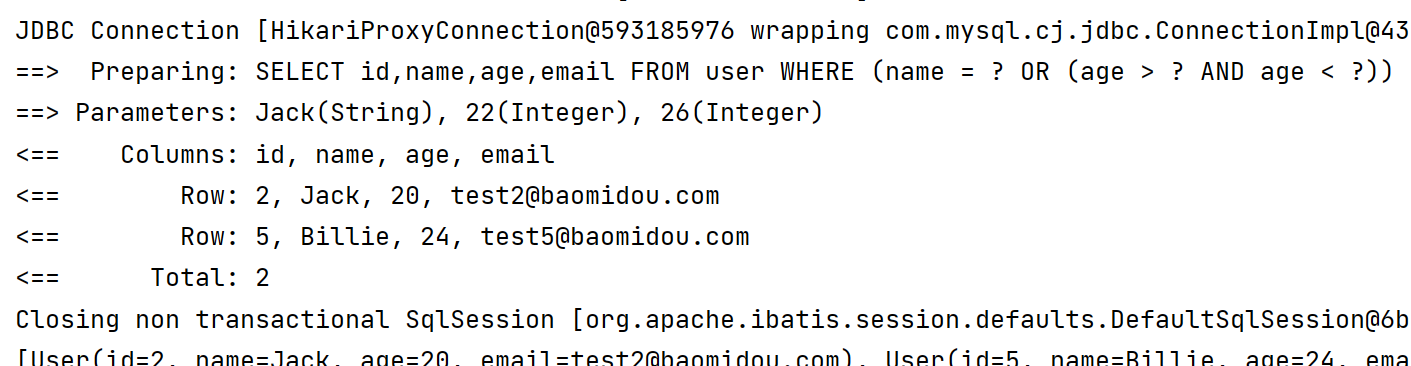
void or2(){
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.eq(User::getName, "Jack").or(i -> i.gt(User::getAge, 22).lt(User::getAge, 26));
//IDEA中通过 Ctrl + Alt + V 可以快速生成变量名
List<User> users = userMapper.selectList(lambdaQueryWrapper);
System.out.println(users);
}
3️⃣ nested 快速构建查询

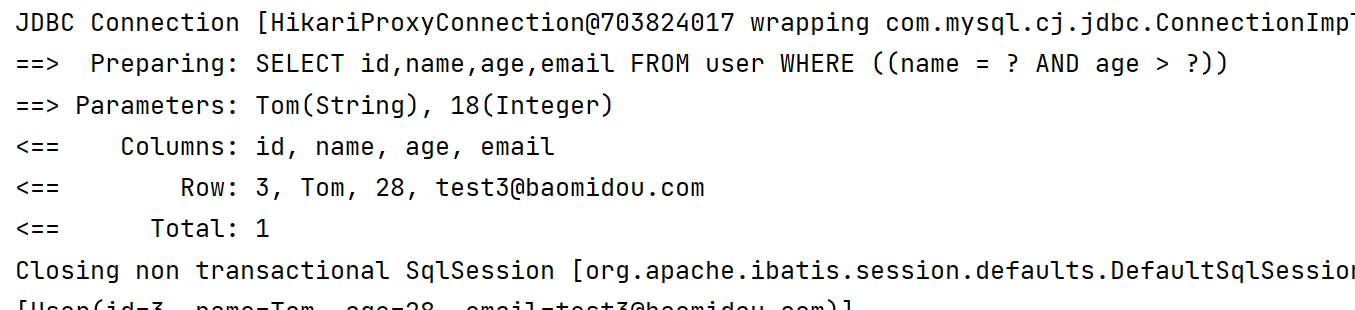
@Test
void nested(){
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.nested(i -> i.eq(User::getName, "Tom").gt(User::getAge, 18));
List<User> users = userMapper.selectList(lambdaQueryWrapper);
System.out.println(users);
}
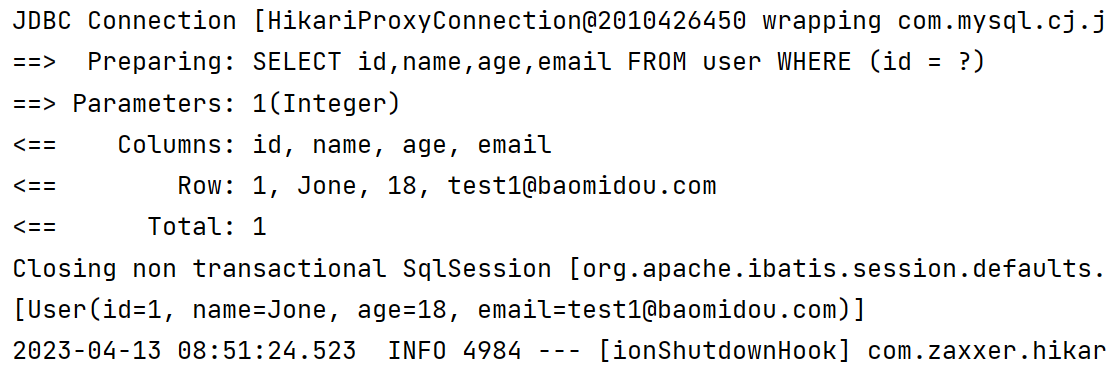
1.3.11 自定义条件查询
- 通过 apply 方法可以实现自定义查询
@Test
void apply(){
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
//会将这部分的内容拼接到SQL的where后面
lambdaQueryWrapper.apply("id = 1");
List<User> users = userMapper.selectList(lambdaQueryWrapper);
System.out.println(users);
}
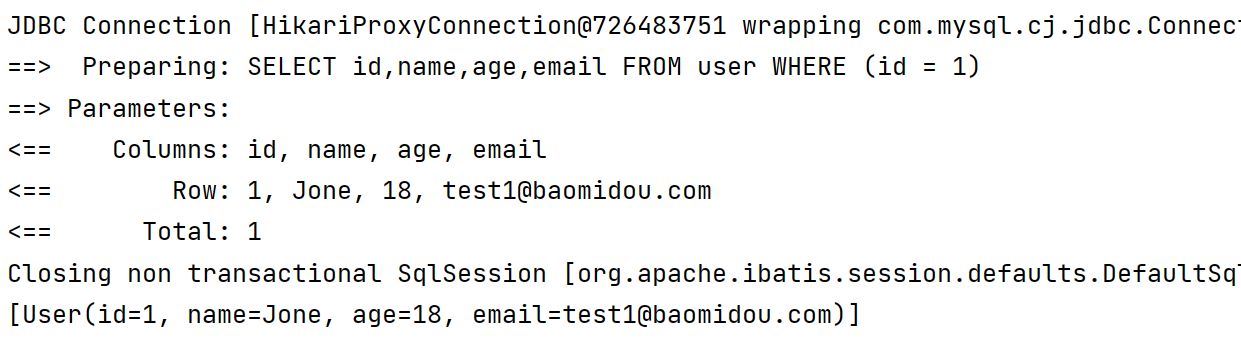
1.3.12 last查询
- 通过last查询可以将我们指定的查询条件拼接到我们sql语句的最后【可以实现简单的分页查询】
@Test
void last(){
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
//limit用于分页,两个参数代表从第几条开始获得几条数据
lambdaQueryWrapper.last("limit 0, 2");
List<User> users = userMapper.selectList(lambdaQueryWrapper);
System.out.println(users);
}
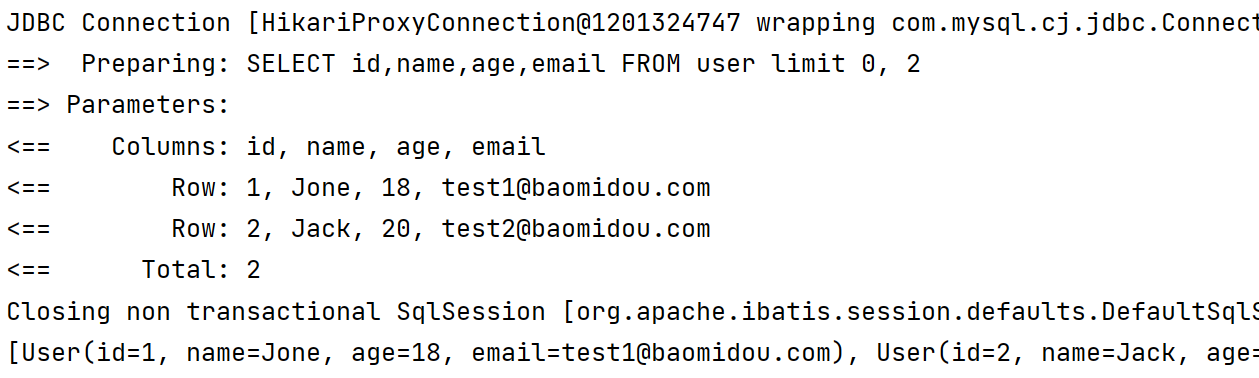
1.3.13 exists查询
1️⃣ exists 存在查询
- 就是根据子查询语句的结果来选择主查询的结果是否保留
@Test
void exists(){
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.exists("select id from user where age = 18");
List<User> users = userMapper.selectList(lambdaQueryWrapper);
System.out.println(users);
}
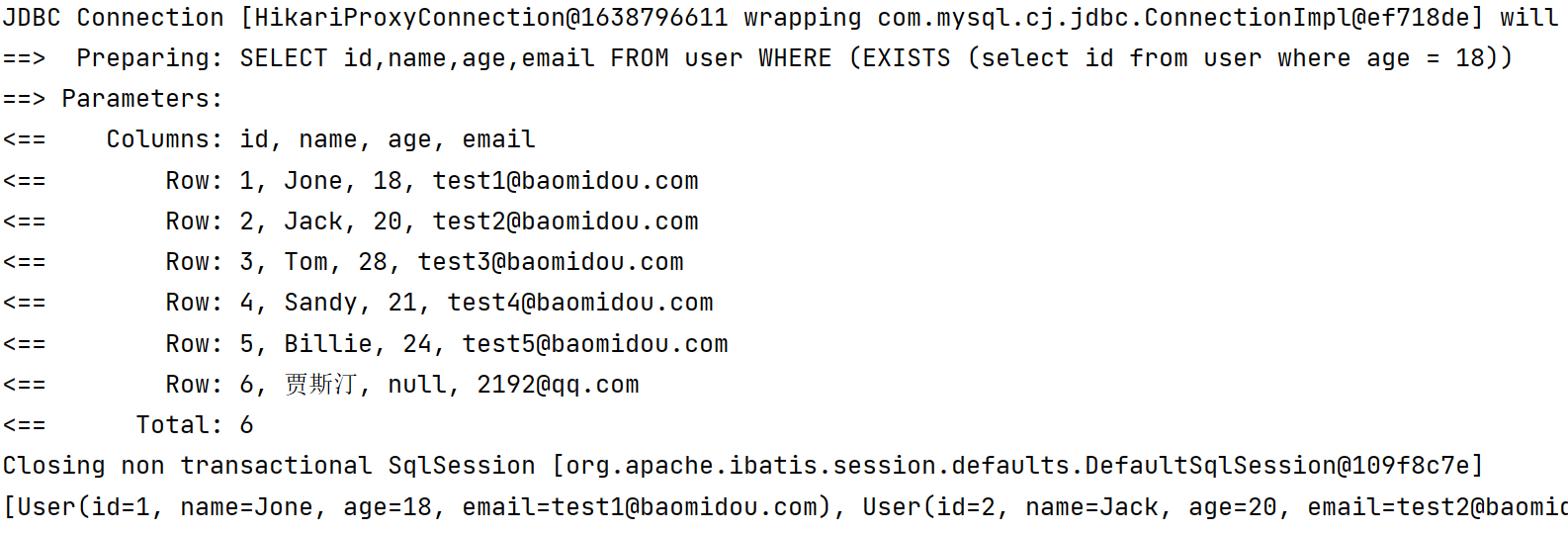
2️⃣ notExists 不存在查询
- notExists 的作用是子查询有数据–主查询不保留,子查询没数据–主查询保留
@Test
void notExists(){
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.notExists("select id from user where age = 18");
List<User> users = userMapper.selectList(lambdaQueryWrapper);
System.out.println(users);
}

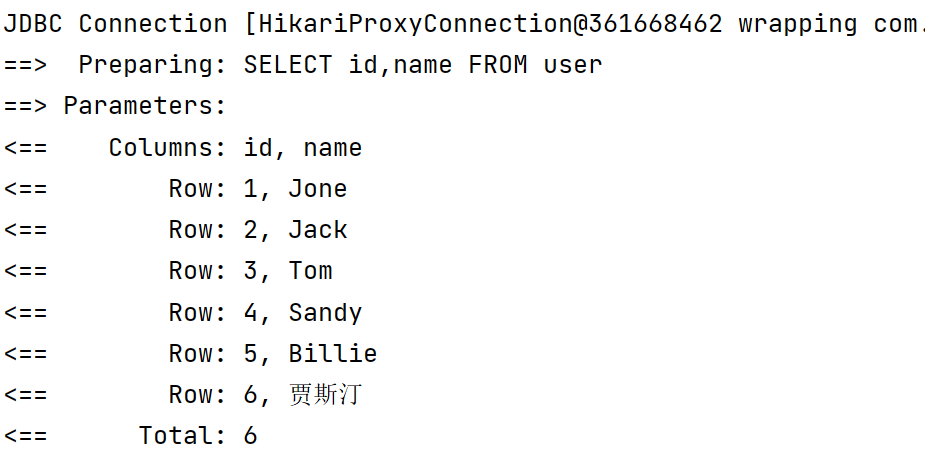
1.3.14 字段查询
- 通过 select 方法指定我们要查询哪些字段
@Test
void select(){
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.select(User::getId, User::getName);
List<User> users = userMapper.selectList(lambdaQueryWrapper);
System.out.println(users);
}
高阶篇
2.1 主键策略
2.1.1 主键生成策略介绍
- 首先大家先要知道什么是主键,主键的作用就是唯一标识,我们可以通过这个唯一标识来定位到这条数据。
- 当然对于表数据中的主键,我们可以自己设计生成规则,生成主键。
- 在MybatisPlus中提供了一个注解 @TableId,该注解提供了各种的主键生成策略,我们可以通过使用该注解来对于新增的数据指定主键生成策略
- 那么在以后新增数据的时候,数据就会按照我们指定的主键生成策略来生成对应的主键。
2.1.2 AUTO策略
- 该策略为跟随数据库表的主键递增策略,前提是数据库表的主键要设置为自增
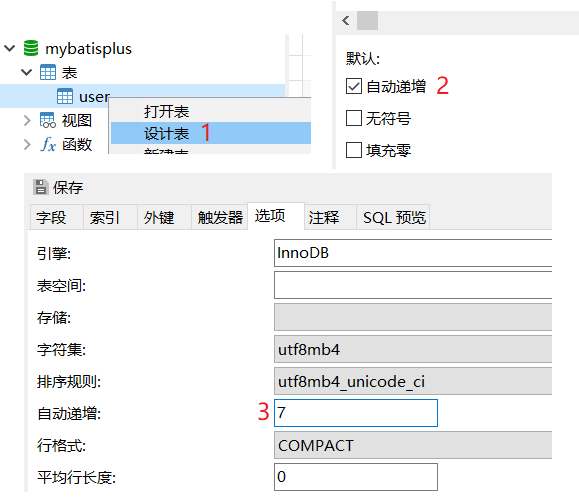
-
实体类添加注解,指定主键生成策略
@Data @AllArgsConstructor @NoArgsConstructor public class User { @TableId(type = IdType.AUTO) private Long id; private String name; private Integer age; private String email; } -
测试程序:
@Test void primaryKey(){ User user = new User(); user.setName("Mary"); user.setAge(35); user.setEmail("test7@powernode.com"); userMapper.insert(user); } -
拼接的SQL语句如下

2.1.3 INPUT策略
-
该策略表示,必须由我们手动的插入id,否则无法添加数据
@Data @AllArgsConstructor @NoArgsConstructor public class User { @TableId(type = IdType.INPUT) private Long id; private String name; private Integer age; private String email; } -
由于我们不使用AUTO了,所以把自动递增去掉
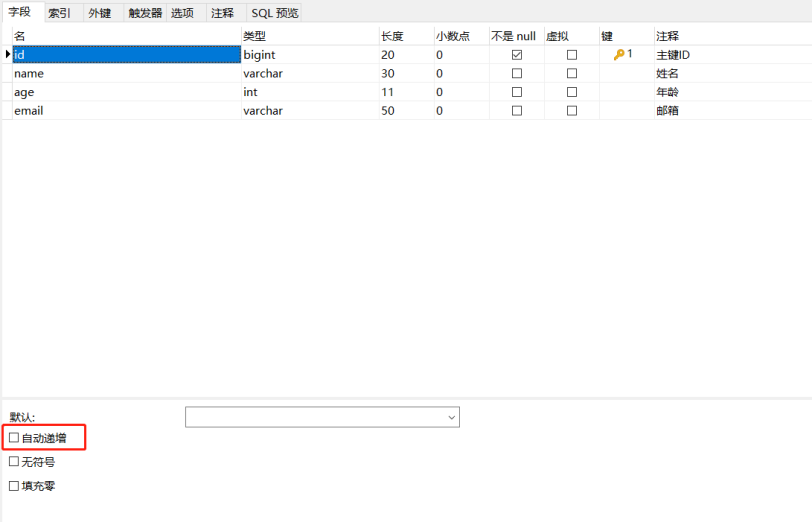
-
这里如果我们省略不写id,会发现,无法插入数据
@Test void primaryKey(){ User user = new User(); user.setName("Jerry"); user.setAge(38); user.setEmail("test8@powernode.com"); userMapper.insert(user); }

- 但是我们自己指定了id,发现可以添加成功
@Test void primaryKey(){ User user = new User(); user.setId(8L); user.setName("Jerry"); user.setAge(38); user.setEmail("test8@powernode.com"); userMapper.insert(user); }
2.1.4 ASSIGN_ID策略
-
如果我们将来一张表的数据量很大,我们需要进行分表。
-
常见的分表策略有两种:
-
水平拆分: 就是将一个大的表按照数据量进行拆分
-
垂直拆分: 垂直拆分就是将一个大的表按照字段进行拆分
-
-
其实我们对于拆分后的数据,有三点需求,就拿水平拆分来说:
- 之前的表的主键是有序的,拆分后还是有序的
- 虽然做了表的拆分,但是每条数据还需要保证主键的唯一性
- 主键最好不要直接暴露数据的数量,这样容易被外界知道关键信息
-
那就需要有一种算法,能够实现这三个需求,这个算法就是雪花算法
-
雪花算法是由一个64位的二进制组成的,最终就是一个Long类型的数值, 主要分为四部分存储【转为十进制是19位】
- 1位的符号位,固定值为0
- 41位的时间戳
- 10位的机器码,包含5位机器id和5位服务id
- 12位的序列号

- 使用雪花算法可以实现有序、唯一、且不直接暴露排序的数字
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User {
@TableId(type = IdType.ASSIGN_ID)
private Long id;
private String name;
private Integer age;
private String email;
}
@Test
void primaryKey(){
User user = new User();
user.setName("Jerry");
user.setAge(38);
user.setEmail("test8@powernode.com");
userMapper.insert(user);
}
我们可以在插入后发现一个19位长度的id,该id就是雪花算法生成的id,这是二级制的十进制表示形式
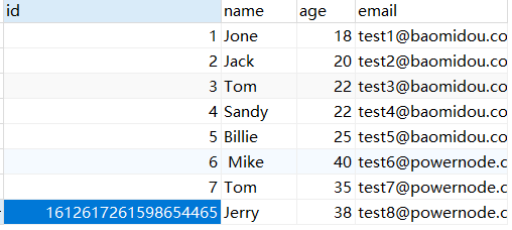
2.1.5 NONE策略
- NONE策略表示不指定主键生成策略,当我们没有指定主键生成策略或者主键策略为NONE的时候,他跟随的是全局策略
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User {
@TableId(type = IdType.NONE)
private Long id;
private String name;
private Integer age;
private String email;
}
那我们来看一下他的全局策略默认是什么,全局配置中 id-type是用于配置主键生成策略的,我们可以看一下id-type的默认值
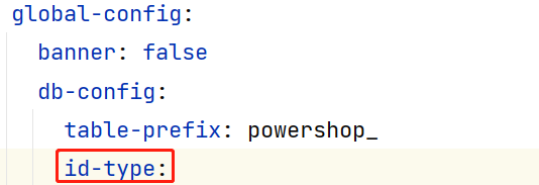
通过查看源码发现,id-type的默认值就是雪花算法
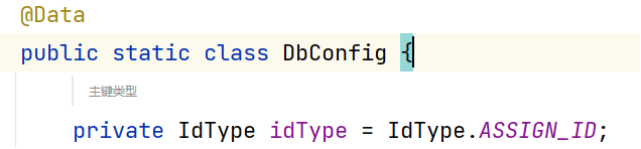
2.1.6 ASSIGN_UUID策略
-
UUID(Universally Unique Identifier)全局唯一标识符,定义为一个字符串主键,采用32位数字组成,编码采用16进制,定义了在时间和空间都完全唯一的系统信息。
-
UUID的编码规则:
- 1~8位采用系统时间,在系统时间上精确到毫秒级保证时间上的唯一性;
- 9~16位采用底层的IP地址,在服务器集群中的唯一性;
- 17~24位采用当前对象的HashCode值,在一个内部对象上的唯一性;
- 25~32位采用调用方法的一个随机数,在一个对象内的毫秒级的唯一性。
-
通过以上4种策略可以保证唯一性,在系统中需要用到随机数的地方都可以考虑采用UUID算法。
-
我们想要演示UUID的效果,需要改变一下表的字段类型和实体类的属性类型
- 将数据库表的字段类型改为varchar(50)

- 将数据库表的字段类型改为varchar(50)
将实体类的属性类型改为String,并指定主键生成策略为 IdType.ASSIGN_UUID
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User {
@TableId(type = IdType.ASSIGN_UUID)
private String id;
private String name;
private Integer age;
private String email;
}
完成数据的添加
@Test
void primaryKey(){
User user = new User();
user.setName("Jerry");
user.setAge(38);
user.setEmail("test8@powernode.com");
userMapper.insert(user);
}
我们会发现,成功添加了一条数据,id为uuid类型

小结: 本章节讲解了主键生成策略,我们可以通过指定主键生成策略来生成不同的主键id,从而达到对于数据进行唯一标识的作用。
2.2 分页
-
分页操作在实际开发中非常的常见,我们在各种平台和网站中都可以看到分页的效果
-
例如:京东商城的分页效果

-
例如:百度的分页效果

-
-
在MybatisPlus中的查询语句是怎么实现的,我们可以通过两种方式实现查询语句
- 通过MybatisPlus提供的方法来实现条件查询
- 通过自定义SQL语句的方式来实现查询
-
接下来我们就来演示这两种分页方式如何实现
2.2.1 分页插件
-
在大部分场景下,如果我们的SQL没有这么复杂,是可以直接通过MybatisPlus提供的方法来实现查询的,在这种情况下,我们可以通过配置分页插件来实现分页效果
-
分页的本质就是需要设置一个拦截器,通过拦截器拦截了SQL,通过在SQL语句的结尾添加limit关键字,来实现分页的效果

接下来看一下配置的步骤
1️⃣ 通过配置类来指定一个具体数据库的分页插件,因为不同的数据库的方言不同,具体生成的分页语句也会不同,这里为Mysql数据库
@Configuration
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
}
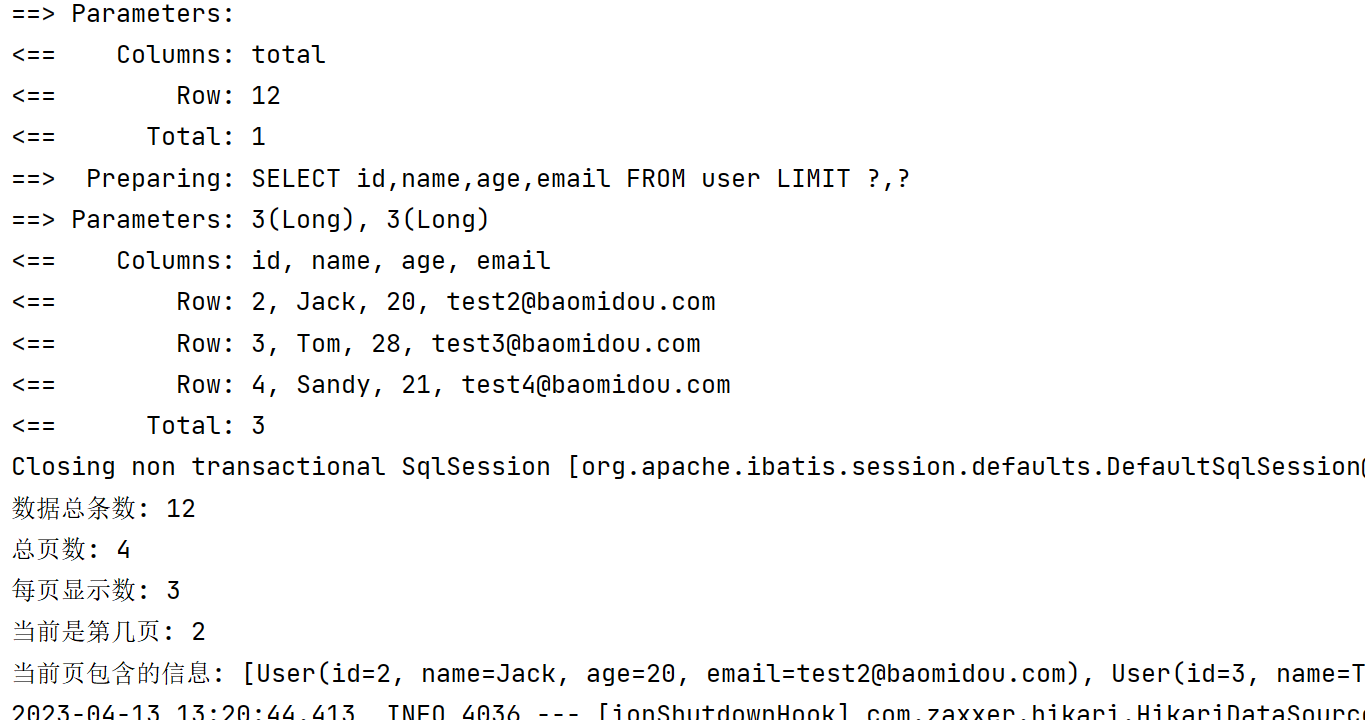
2️⃣ 实现分页查询效果
@Test
void page(){
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<User>();
//当前页是第几页,每页包含多少条信息
IPage<User> userPage = new Page<>(2, 3);
//执行查询
userMapper.selectPage(userPage, lambdaQueryWrapper);
//获取分页查询信息
System.out.println("数据总条数: " + userPage.getTotal());
System.out.println("总页数: " + userPage.getPages());
System.out.println("每页显示数: " + userPage.getSize());
System.out.println("当前是第几页: " + userPage.getCurrent());
System.out.println("当前页包含的信息: " + userPage.getRecords());
}
2.2.2 自定义分页插件
在某些场景下,我们需要自定义SQL语句来进行查询,接下来我们来演示一下自定义SQL的分页操作
1️⃣ 在 UserMapper.xml 映射配置文件中提供查询语句
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.powernode.mapper.UserMapper">
<select id="selectByName" resultType="com.powernode.domain.User">
select * from powershop_user where name = #{name}
</select>
</mapper>
2️⃣ 在Mapper接口中提供对应的方法,方法中将IPage对象作为参数传入
@Mapper
public interface UserMapper extends BaseMapper<User> {
IPage<User> selectByName(IPage<User> page, String name);
}
3️⃣ 表数据为

4️⃣ 实现分页查询效果
@Test
void page2(){
IPage<User> userPage = new Page<>(1, 3);
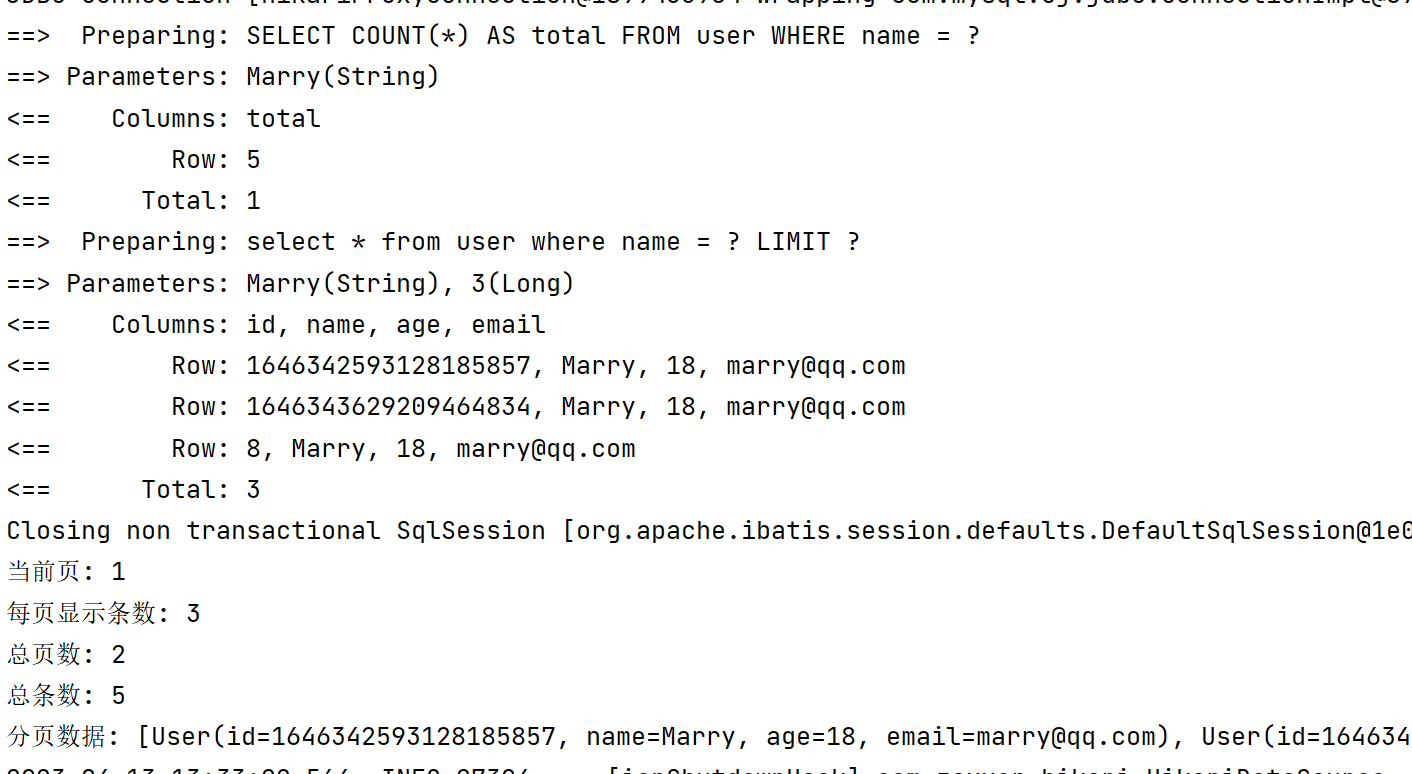
userMapper.selectByName(userPage, "Marry");
System.out.println("当前页: " + userPage.getCurrent());
System.out.println("每页显示条数: " + userPage.getSize());
System.out.println("总页数: " + userPage.getPages());
System.out.println("总条数: " + userPage.getTotal());
System.out.println("分页数据: " + userPage.getRecords());
}
小结: 这里我们学习了两种分页的配置方法,将来以后我们在进行条件查询的时候,可以使用分页的配置进行配置。
2.3 ActiveRecord模式
- ActiveRecord(活动记录,简称AR),是一种领域模型模式,特点是一个模型类对应关系型数据库中的一个表,而模型类的一个实例对应表中的一行记录 【利用我们的实体类对象去操作数据库中的表】
- ActiveRecord 一直广受解释型动态语言( PHP 、 Ruby 等)的喜爱,通过围绕一个数据对象进行CRUD操作
- 而 Java 作为准静态(编译型)语言,对于 ActiveRecord 往往只能感叹其优雅,所以 MP 也在 AR 道路上进行了一定的探索,仅仅需要让实体类继承 Model 类且实现主键指定方法,即可开启 AR 之旅。
那么如何使用 ActiveRecord 模式呢?
1️⃣ 让实体类继承Model类
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User extends Model<User> {
private Long id;
private String name;
private Integer age;
private String email;
}
- 我们可以看到,Model类中提供了一些增删改查方法,这样的话我们就可以直接使用实体类对象调用这些增删改查方法
- 简化了操作的语法,但是他的底层依然是需要UserMapper的,所以持久层接口并不能省略
测试ActiveRecord模式的增删改查
1️⃣ 添加操作
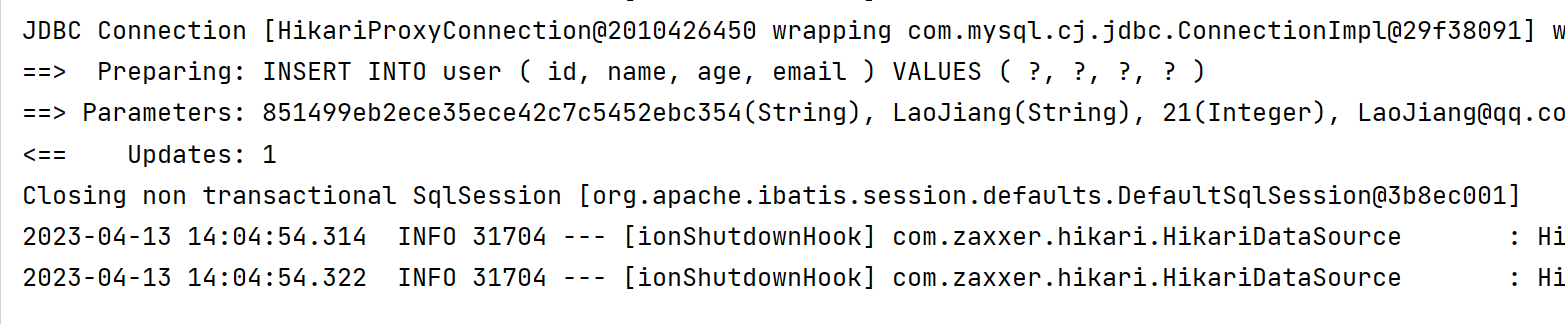
@Test
void activeRecordAdd(){
User user = new User();
user.setName("LaoJiang");
user.setAge(21);
user.setEmail("LaoJiang@qq.com");
user.insert();
}
2️⃣ 删除操作
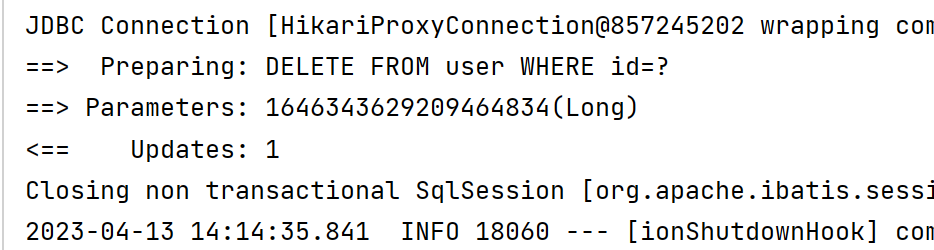
@Test
void activeRecordDelete(){
User user = new User();
user.setId(1646343629209464834L);
user.deleteById();
}
3️⃣ 修改操作
@Test
void activeRecordUpdate(){
User user = new User();
user.setId(1646342593128185857L);
user.setName("雪花");
user.updateById();
}

4️⃣ 查询操作
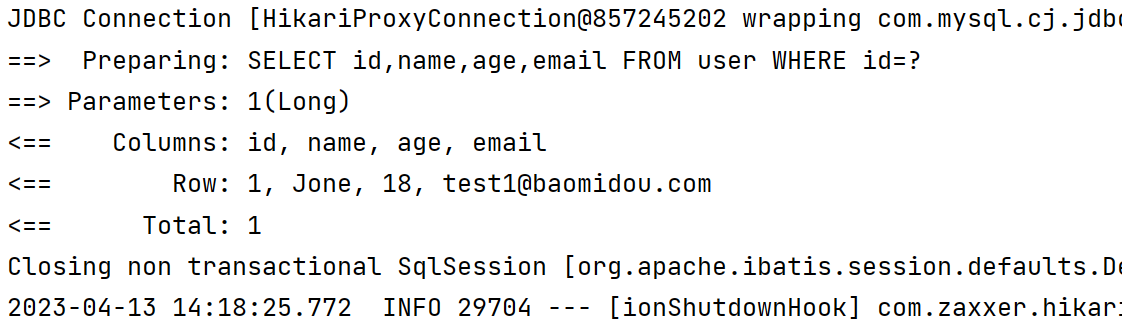
@Test
void activeRecordSelect(){
User user = new User();
user.setId(1L);
user.selectById();
}
2.3 SimpleQuery工具类
- SimpleQuery可以对selectList查询后的结果用Stream流进行了一些封装,使其可以返回一些指定结果,简洁了api的调用
1️⃣ list
演示基于字段封装集合 【在查询的同时支持Stream流的操作】
@Test
void testList(){
List<Long> ids = SimpleQuery.list(new LambdaQueryWrapper<User>().eq(User::getName, "Marry"), User::getId);
System.out.println(ids);
}
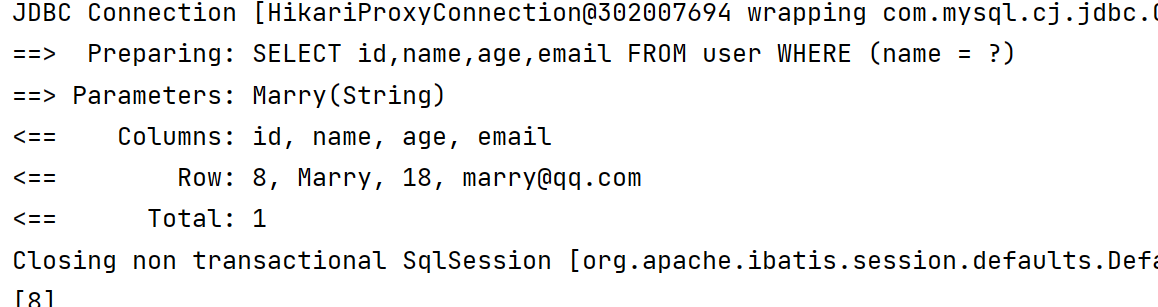
演示对于封装后的字段进行lambda操作 【获取到的数据再加工,不会修改表中的数据】
@Test
void testList2(){
List<String> list = SimpleQuery.list(new LambdaQueryWrapper<User>().eq(User::getName, "Marry"), User::getName, user -> Optional.of(user.getName()).map(String::toLowerCase).ifPresent(user::setName));
System.out.println(list);
}

2️⃣ map
演示将所有的对象以id,实体的方式封装为Map集合
@Test
void testMap(){
Map<Long, User> map = SimpleQuery.keyMap(new LambdaQueryWrapper<User>(), User::getId);
System.out.println(map);
}

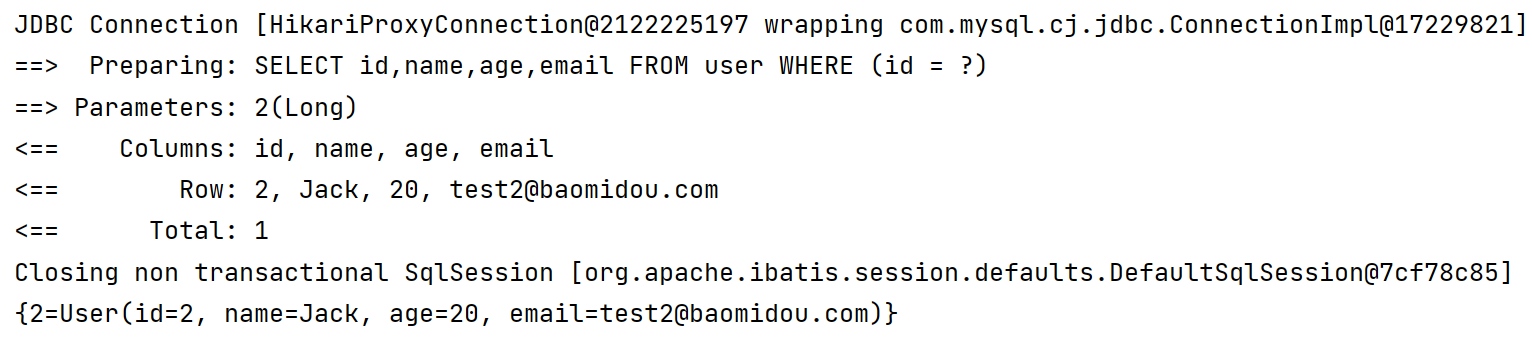
演示将单个对象以id,实体的方式封装为Map集合
@Test
void testMap2(){
//封装一条数据的Map集合
Map<Long, User> map = SimpleQuery.keyMap(new LambdaQueryWrapper<User>().eq(User::getId, 2L), User::getId);
System.out.println(map);
}
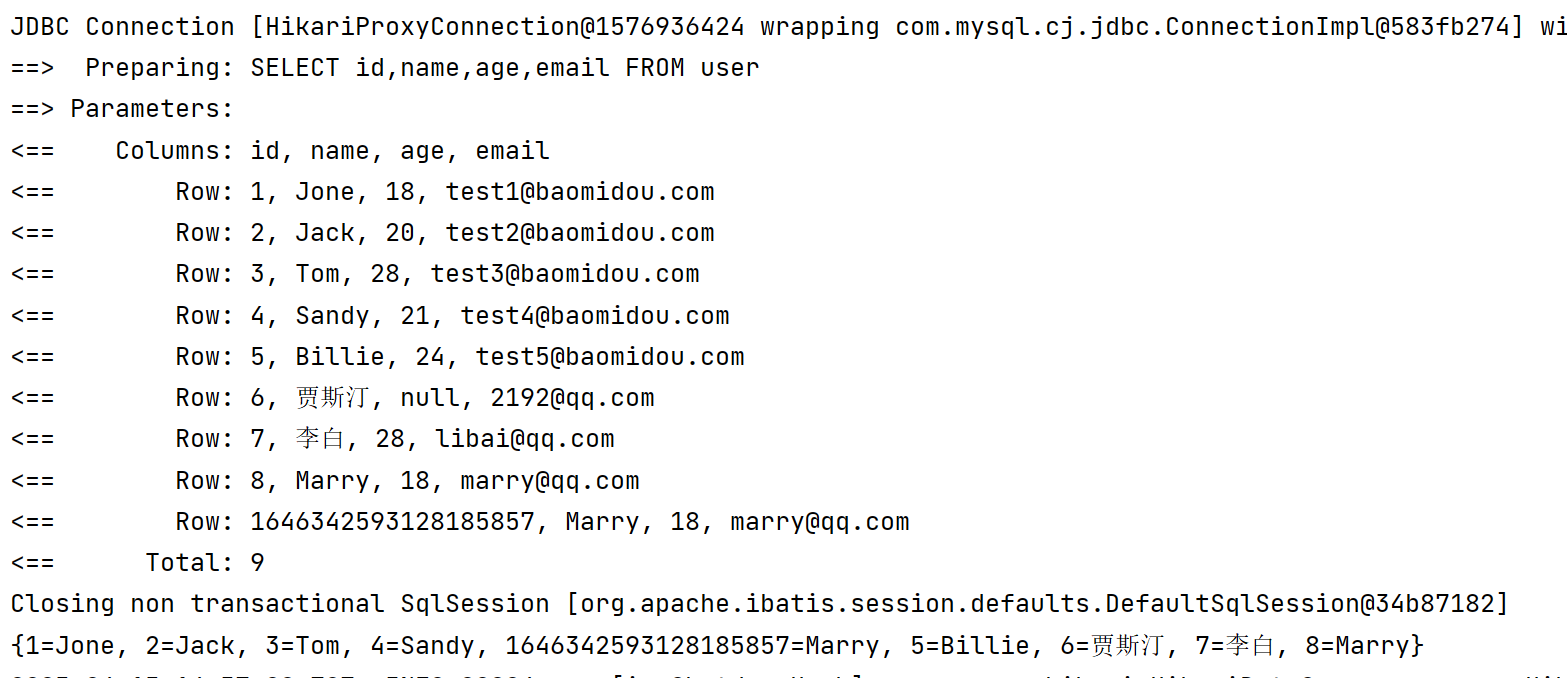
演示只想要id和name组成的map
@Test
void testMap3(){
Map<Long, String> map = SimpleQuery.map(new LambdaQueryWrapper<User>(), User::getId, User::getName);
System.out.println(map);
}
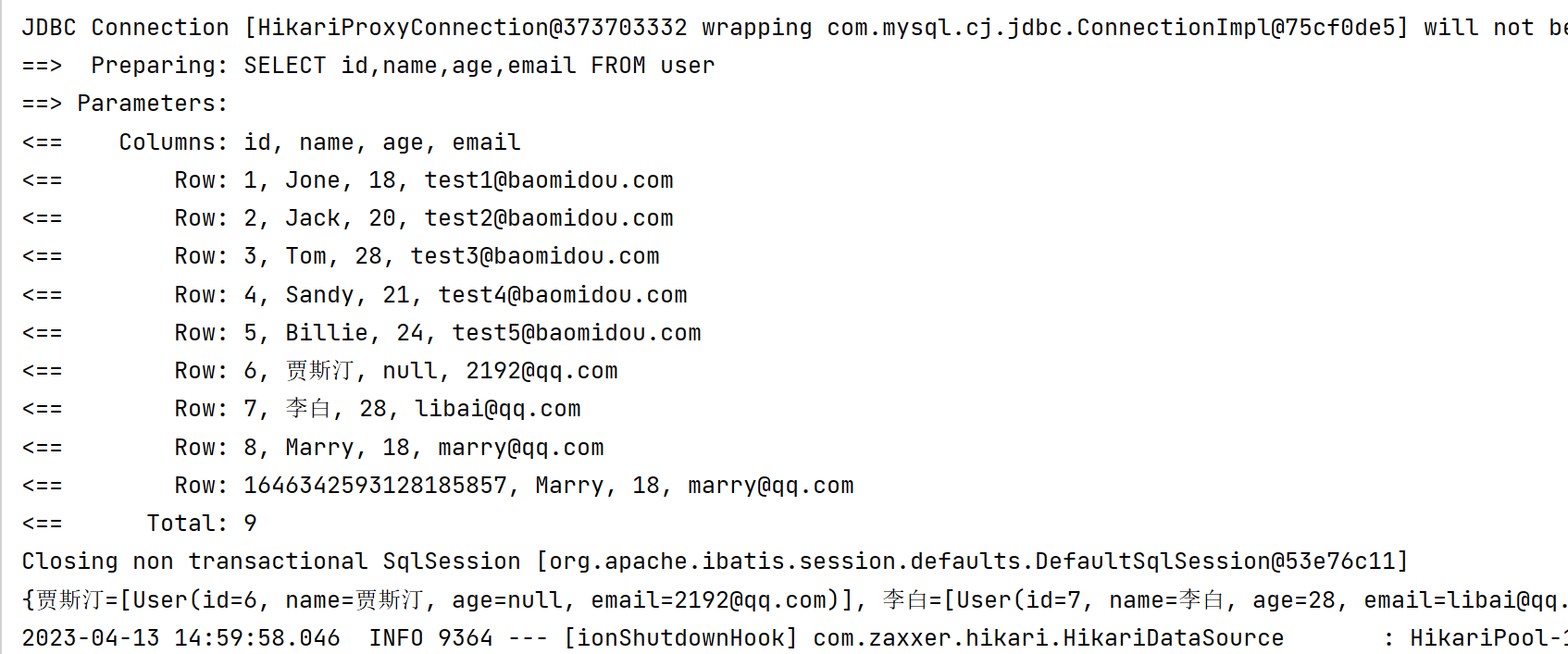
3️⃣ Group
@Test
void testGroup(){
Map<String, List<User>> group = SimpleQuery.group(new LambdaQueryWrapper<User>(), User::getName);
System.out.println(group);
}
小结: 在这一小节,我们演示了SimpleQuery提供的Stream流式操作的方法,通过这些操作继续为我们提供了查询方面简化的功能