文章目录
- ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
- 一. 简介
- 1.1 摘要
- 1.2 文本编码器,图像编码器,特征交互复杂度分析
- 1.2 特征交互方式分析
- 1.3 图像特征提取分析
- 二. 方法 Vision-and-Language Transformer
- 2.1. 方法概述
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
一. 简介
机构:韩国NAVER AILAB
代码:https://github.com/dandelin/vilt
会议: ICML 2021 long paper,截止2023.04,引用量500+
任务: 视觉语言预训练
特点: 快
方法: 视觉特征提取,无卷积,无region监督
1.1 摘要
视觉语言预训练任务已经提升了许多视觉语言下游任务的表现。现有的视觉语言预训练方法往往很依赖图像的特征提取过程,比如区域的监督(像目标检测)以及卷积的结构(像ResNet)。尽管在现有文献中这个问题并没有被重视,但是我们发现它在如下方面会存在问题:(1)效率/速度,单单在提取输入特征就需要比多模态交互步骤多更多计算。(2)表达能力,因为它是视觉潜入器以及其预定义视觉词汇表达能力的上限。在本文中,我们提出了一个更小的VLP模型,视觉语言transformer ViLT。它在处理视觉输入的时候,用到了与处理文本输入相同的无卷积的方式。我们证明ViLT比如以前VLP模型快数十倍,但是在下游的视觉语言下游任务上有与之匹敌的能力。
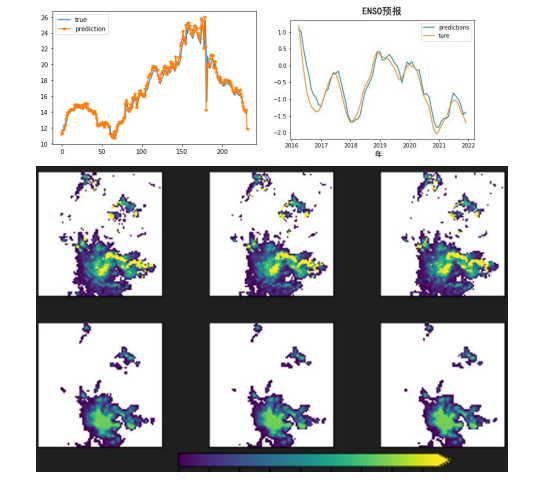
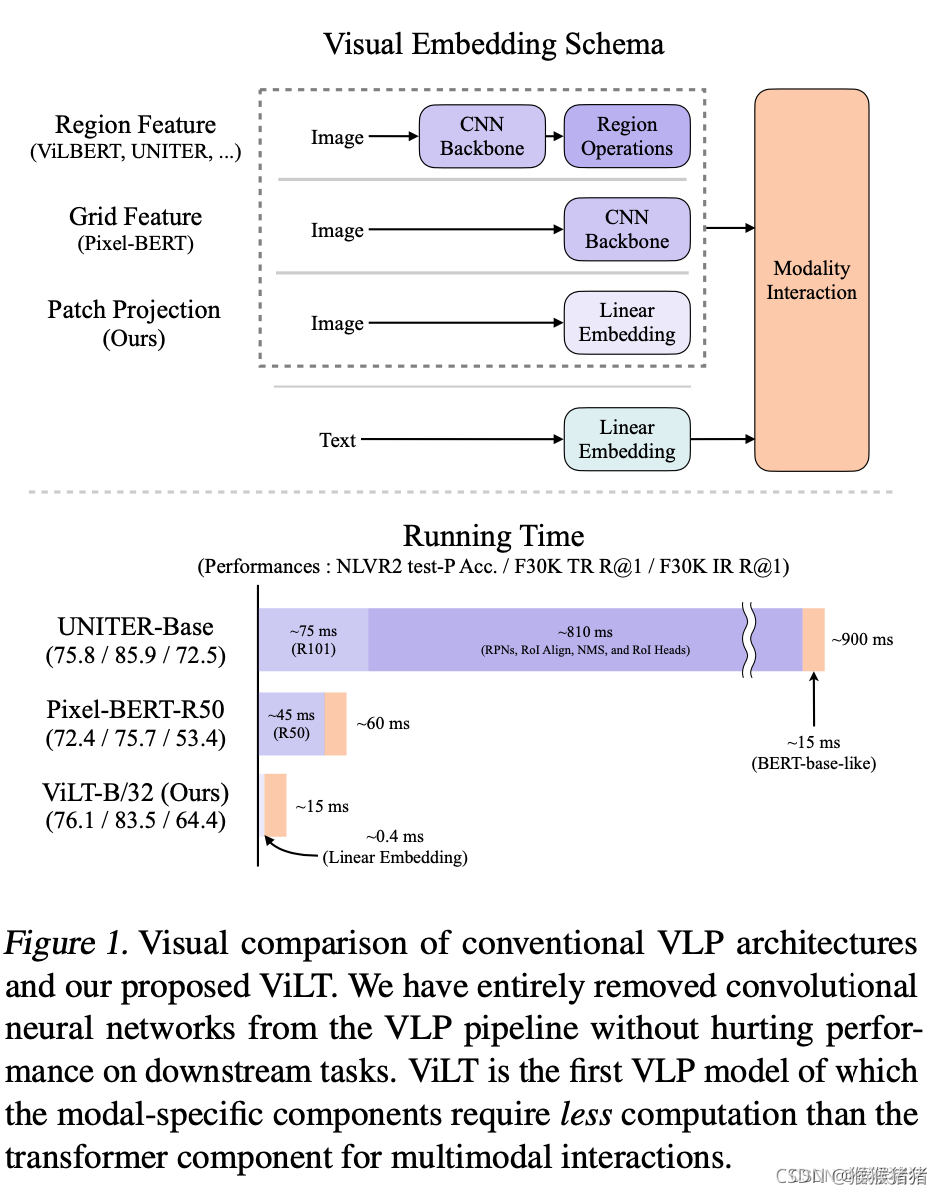
具体摘要所述的内容就如下图所示,突出的就是一个图像单支没有用CNN结构,以及没有用region的信息(可以发现之前的方法,耗时大部分在CNN以及region,即紫色的部分),用简单的linear embedding,就能实现图像的特征抽取,将更多重心关注在modality interaction这一个部分,既保证了效果,又提升了速度。
1.2 文本编码器,图像编码器,特征交互复杂度分析
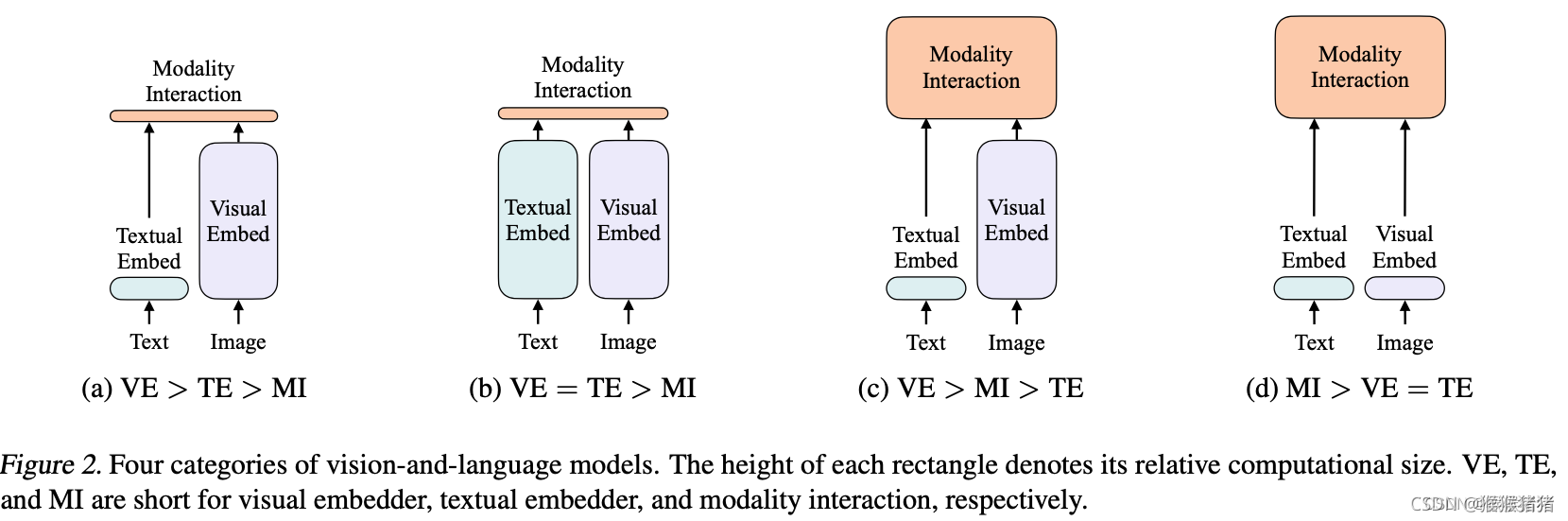
论文根据visual encoder, text encoder, modality interactioin的复杂度将视觉语言模型的设计分为四种类别:
- VE > TE > MI 文本轻,视觉重,交互轻:像visual semantic embedding (VSE) models,such as VSE++ (Faghri et al., 2017) and SCAN (Lee et al., 2018),用分别的编码器处理图像和文本,但前者会更重一些,最终用简单的点乘或者浅的注意力层来表示提取的两种特征的相似度。
- VE = TE > MI 文本重,视觉重,交互轻:CLIP (Radford et al., 2021) 用分别的但是同样重的transformer编码器来处理两个模态。但是所提特征的交互依旧使用简单的点乘来实现的。尽管CLIP在图文检索上zero shot效果可以,但是在NLVR2任务上MLP表现不佳,因为作者推测,在复杂的图文任务上,仅仅依赖单边模态良好的特征提取能力是不足够的,还需要更好的特征交互。
- VE > MI > TE 文本轻,视觉重,交互重:Pixel-bert更多地考虑了交互的复杂度,但是复杂的视觉编码器依旧比较笨重。
- MI > VE = TE 文本轻,视觉轻,交互重:本文方法,图像文本特征提取的方式都比较shallow,更关注所提取的两种特征的交互。
1.2 特征交互方式分析
对于交互这一块,根据交互的方式(Modality Interaction Schema),一般将方法分为两类:
- single stream: Visual- BERT: (Li et al., 2019), UNITER (Chen et al., 2019),layers collectively operate on a concatenation of image and text inputs。本文的ViLT方法在交互层面上是属于single stream,因为dual stream会引入额外的参数。
- dual-stream: ViLBERT (Lu et al., 2019), LXMERT (Tan & Bansal, 2019),the two modalities are not concatenated at the input level.
1.3 图像特征提取分析
现在表现好的视觉语言预训练模型,往往用的文本编码器都是一样的,即预先训练好的BERT,因此方法间差异比较多的是对视觉的编码,视觉的编码也是先有的视觉语言预训练模型的瓶颈。
根据视觉编码的方式(Visual Embedding Schema),一般也有如下的几种代表性的方式
- Region Feature. 这种特征也被叫做bottom-up features (Anderson et al., 2018). 即用先有的目标检测器来提取region features,因此其性能往往取决于目标检测的几个重要的部分,backbone,NMS,ROI head。一方面比较笨重,另一方面限制了视觉语言的能力。
- Grid Feature. 可以理解为CNN(比如ResNet)输出的 N ∗ N ∗ d N * N * d N∗N∗d特征,其中 N ∗ N N * N N∗N就表示多个格子,虽然比基于region的方式简单,一些方法验证了它的表现,但是从图1还是可以看到,这部分卷积操作,在整个过程当中还是相对比较占据时间的。
- Patch Projection. 类似ViT一样,直接对图像的patch进行映射,本文用的32 * 32 patch projection。仅仅需要2.4M参数,相比于ResNet以及检测的各个part,这个运行的时间几乎可以忽略不计。