文|肖健(花名:昱恒)
蚂蚁集团技术专家、SOFARegistry Maintainer
专注于服务发现领域,目前主要从事蚂蚁注册中心 SOFARegistry 的设计和研发工作。
本文 8339 字 阅读 15 分钟
PART. 1
前言
什么是服务发现?
我们今天主要聊的话题是“应用级服务发现”的实践,聊这个话题之前,我们先简单介绍一下什么是“服务发现”,然后再聊聊,为什么需要“应用级服务发现”。
在微服务的体系中,多个应用程序之间将以 RPC 方式进行相互通信,而这些应用程序的服务实例是动态变化的,我们需要知道这些实例的准确列表,才能让应用程序之间按预期进行 RPC 通信。这就是服务发现在微服务体系中的核心作用。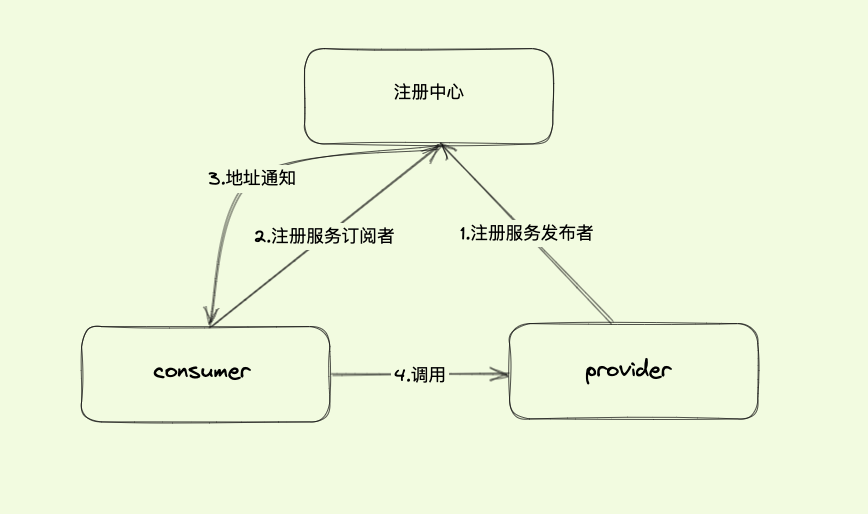
图 1
SOFARegistry 是蚂蚁集团在生产大规模使用的服务注册中心,经历了多年大促的考验,支撑了蚂蚁庞大的服务集群,具有分布式可支撑海量数据、可云原生部署、推送延迟低、高可用等特点。
PART. 2
应用级服务发现的设想
介绍完什么是服务发现之后,我们来看看什么是“接口级服务发现”,以及与之相对应的“应用级服务发现”。
从 RPC 框架说起
根据上述描述,我们先看看业界常用的 RPC 框架,是如何进行服务的发布和订阅的。以 SOFARPC 编程界面[1]为例:
|服务发布
package com.alipay.rpc.sample;
@SofaService(interfaceType = FooService.class, bindings = { @SofaServiceBinding(bindingType = "bolt") })
@Service
public class FooServiceImpl implements FooService {
@Override
public String foo(String string) {
return string;
}
}
@SofaService(interfaceType = BarService.class, bindings = { @SofaServiceBinding(bindingType = "bolt") })
@Service
public class BarServiceImpl implements BarService {
@Override
public String bar(String string) {
return string;
}
}|服务使用
@Service
public class SampleClientImpl {
@SofaReference(interfaceType = FooService.class, jvmFirst = false,
binding = @SofaReferenceBinding(bindingType = "bolt"))
private FooService fooService;
@SofaReference(interfaceType = BarService.class, jvmFirst = false,
binding = @SofaReferenceBinding(bindingType = "bolt"))
private BarService barService;
public String foo(String str) {
return fooService.foo(str);
}
public String bar(String str) {
return barService.bar(str);
}
}上述两个编程界面,完成了两个服务 FooService 和 BarService 的发布、订阅、调用。
微服务面临的挑战
上述的服务发布、订阅、调用功能,离不开注册中心的服务发现提供准确的服务地址。将图 1 的服务发现场景进一步展开,此时的工作原理如下图:
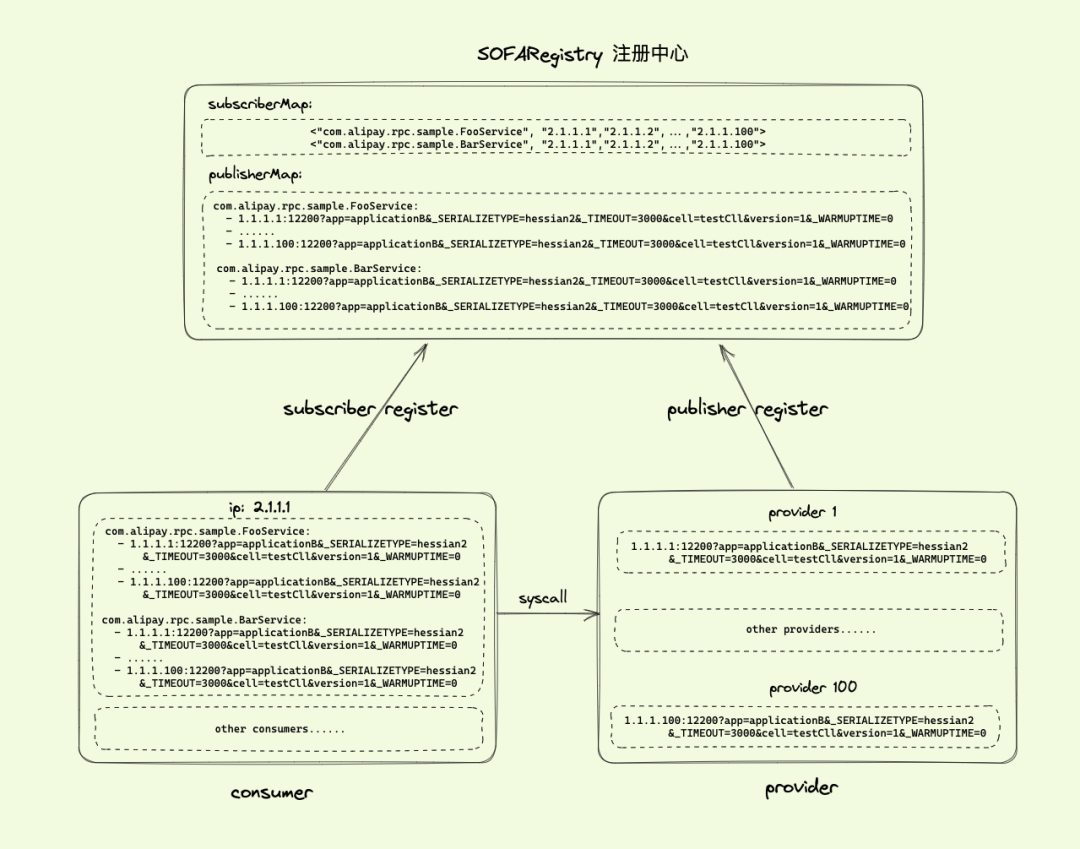
图 2(点击图片查看大图)
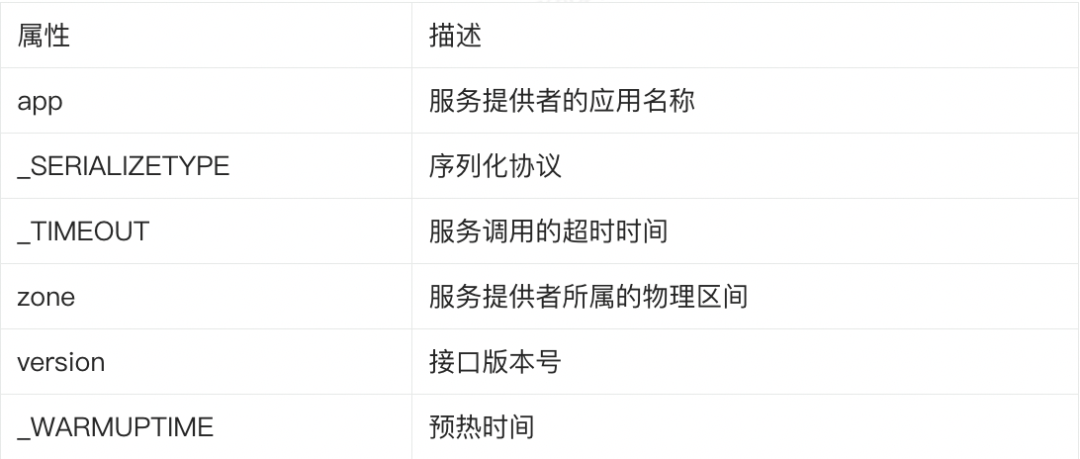
服务发布者:
- 集群内部署了 100 个 pod,IP 分别为:1.1.1.1 ~ 1.1.1.100;
- 服务发布者的 URL:1.1.1.1:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0,12200 端口为 sofarpc-bolt 协议默认的端口。
服务订阅者:集群内部署了 100 个 pod,IP 分别为:2.1.1.1 ~ 2.1.1.100。
基于上述的集群部署情况,我们来看看微服务的场景面临的挑战。
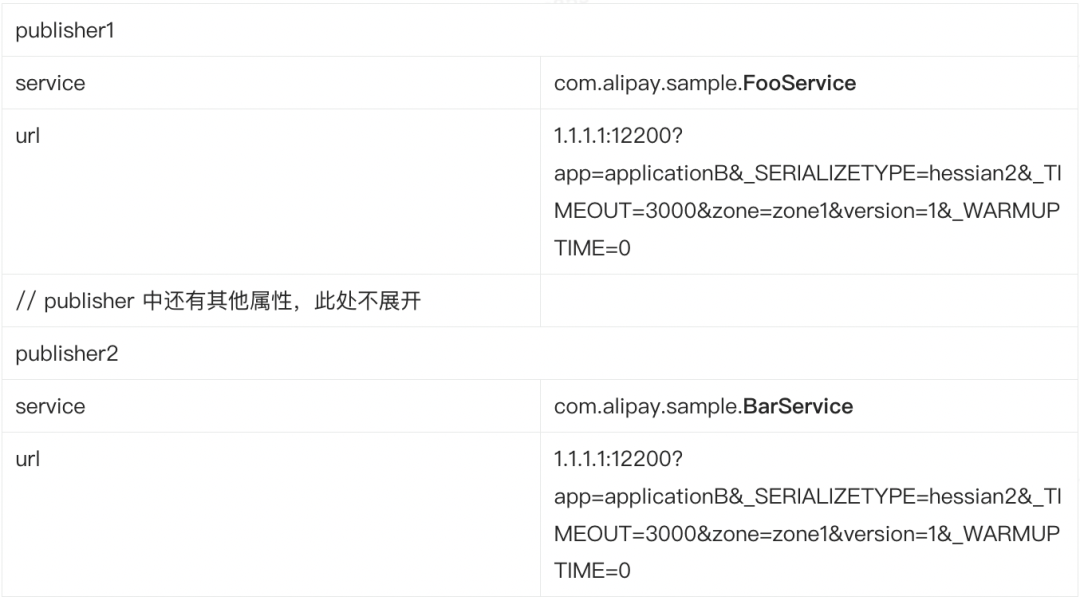
|挑战 1:注册中心 publisher 存储的挑战
在上面的集群部署中,可以看到注册中心的数据存储模型,集群内部署了 100 个 provider pod,每个 provider 发布了 2 个服务,即每个 pod 有 2 个 publisher,以 provider1 为例:
如果在每个 provider 提供更多服务的情况下呢?比如每个 provider 提供了 50 个服务,这样的量级在微服务场景中并不少见,那么此时注册中心对于 provider1,就需要存储 50 个 publisher,分别是:
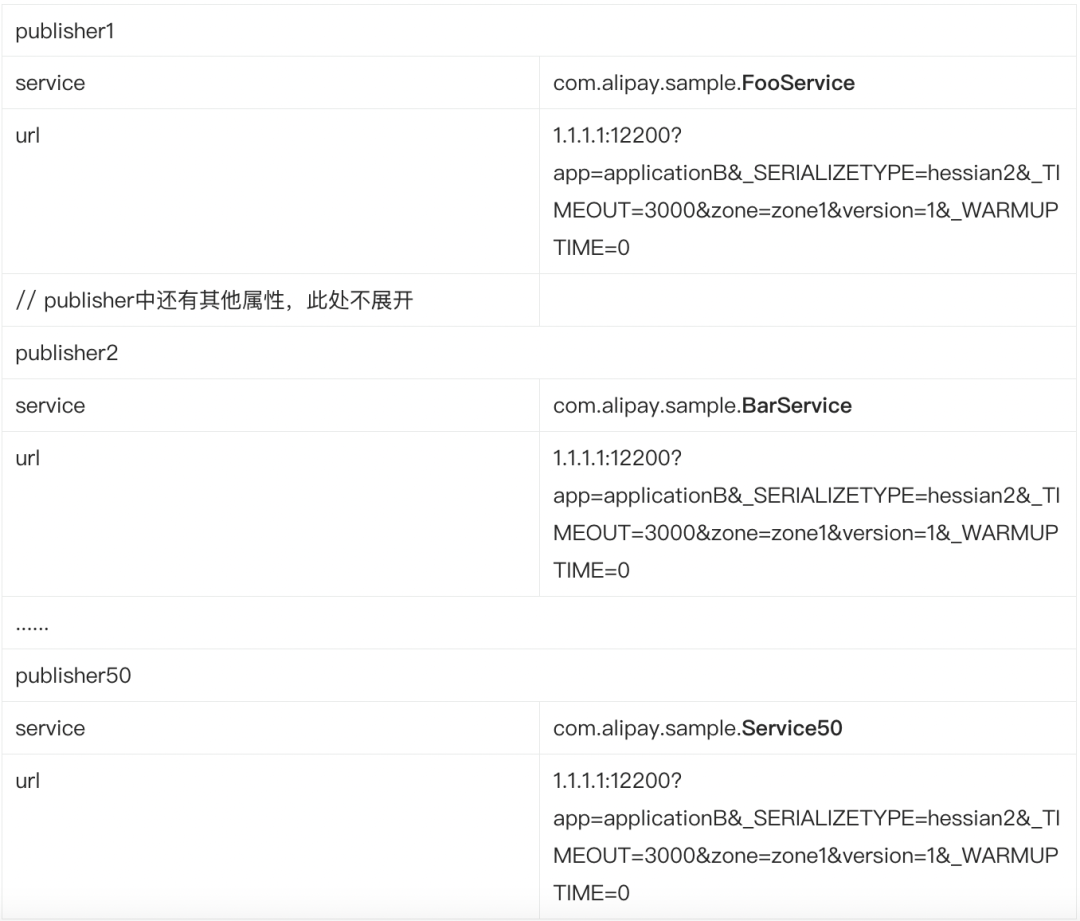
可以看到,随着 provider 的扩容,注册中心存储的 publisher 数据量是以 50 倍于 provider 的速度在增长。
如果您对 SOFARegistry 有过了解,就会知道 SOFARegistry 是支持数据存储分片,可以存储海量数据的。
但是数据量上涨带来的是 SOFARegistry 本身的服务器数量增涨,如果我们有办法可以降低 SOFARegistry 的数据存储量,那么就能节约 SOFARegistry 本身的服务器成本,同时 SOFARegistry 整个集群的稳定性也会得到提升。
|挑战 2:注册中心 subscriber 存储的挑战
在上述的集群部署中,集群内部署了 100 个 consumer pod,每个 consumer 订阅了 2 个服务,即每个 pod 有 2 个 subscriber,同理于 publisher 的存储挑战,随着 consumer 订阅的接口持续增加,例如 consumer 订阅了 provider 的 10 个 service,此时注册中心存储 consumer1 的 10 个 subscriber 如下:

随着 consumer 的扩容,注册中心内的 subscriber 存储同样面临着挑战。
|挑战 3:服务变更通知的挑战
随着 publisher 和 subscriber 数量增长,除了对存储的挑战以外,对于数据变更通知同样面临着极大的挑战,让我们来看看如下的场景:provider 下线了 1 台,从 100 台减少到了 99 台,次数集群内发生了哪些变化呢?
1、首先是在注册中心存储方面,需要将 provide 50 个 service 中的 publishers 列表都减少 1 个,每个 service 剩余 99 个 publisher;
2、然后注册中心需要将这 50 个 service 的变更,都通知给相应的 subscriber;我们上述假设是 consumer 订阅了 10 个 service,分别是:["com.alipay.sample.FooService", "com.alipay.sample.BarService", "com.alipay.sample.Service00", ..., "com.alipay.sample.Service07"];
3、那么对于 consumer1,我们需要将如下的数据推送给 consumer1:
com.alipay.sample.FooService:
- 1.1.1.1:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0
- ...
- 1.1.1.99:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0
com.alipay.sample.BarService:
- 1.1.1.1:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0
- ...
- 1.1.1.99:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0
//...中间省略
com.alipay.sample.Service07:
- 1.1.1.1:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0
- ...
- 1.1.1.99:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0可以看到一台 provider 的扩缩容,就需要对 consumer1 进行如此大量的数据推送,如果 com.alipay.sample.FooService 的 publisher 的数量更大,达到 1 千个、1 万个呢?此时注册中心的服务变更通知,也面临着网络通信数据量大的挑战。
是否有方式在 provider 的变更时,降低需要通知的数据量呢?
|挑战 4:consumer 的内存挑战
介绍完注册中心面临的挑战后,我们再从图 1 来看看 consumer 存储服务列表时,内存面临的挑战,对于注册中心推送下来的数据,consumer 也需要进行存储,然后再发起 RPC 服务调用的时候,就可以直接从 consumer 内存中获取到服务地址进行调用,consumer 中存储的数据,简化来看是如下的数据:
com.alipay.sample.FooService:
- 1.1.1.1:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0
- ...
- 1.1.1.99:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0
com.alipay.sample.BarService:
- 1.1.1.1:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0
- ...
- 1.1.1.99:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0
//...中间省略
com.alipay.sample.Service07:
- 1.1.1.1:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0
- ...
- 1.1.1.99:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0此时 privoder 只有 99 个 IP,但是因为订阅了 10 个 service,所以在 consumer 中存储了 99 * 10 = 990 个 publisher 列表;如果订阅的 service 更多,provider 的数量更大呢(比如达到 10 万)?此时 consumer 内存中存储了近 100 万个 publisher,内存将面临着极大的挑战。
微光:应用级服务发现的提出
|应用级服务发布
经过上一个章节的描述,对于一次简单的 RPC 调用背后,服务发现面临的挑战相信各位读者已经有所感受,那么可能得突破方向到底在哪里呢?
初步看,我们不难发现的是,对于一个 provider1,在注册中心存储的 publisher 数据如下:
com.alipay.sample.FooService:
- 1.1.1.1:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0
com.alipay.sample.BarService:
- 1.1.1.1:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0
//...中间省略
com.alipay.sample.Service100:
- 1.1.1.1:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0每个 publisher 中,除了 serviceName 不相同,url 存储了相同的 100 份,这里是否可以简化为存储 1 份?这是应用级服务发布最初的想法。
按照这个模型我们继续推演,可以得到如下演进模型:
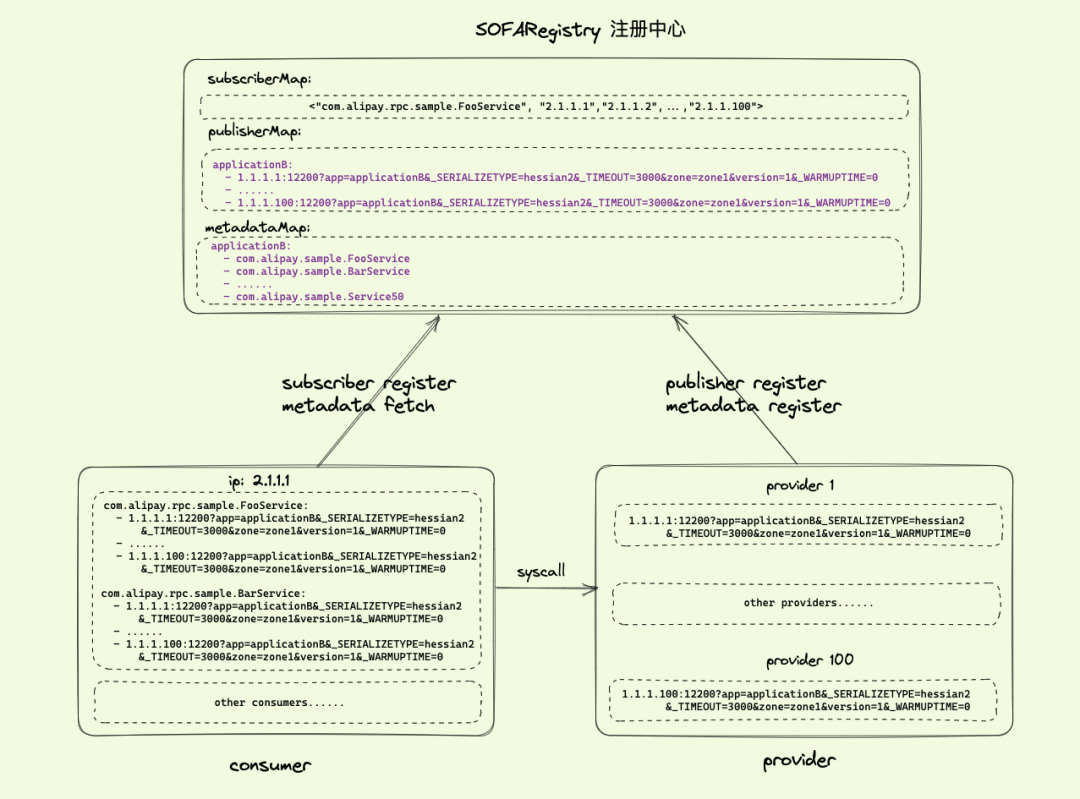
图 3(点击图片查看大图)
对比图 2 和图 3,我们设想:
1、prodiver 不再以 service=com.alipay.sample.FooService 向注册中心发布服务,而是以 service=applicationB 进行服务发布,那么注册中心对于 provide1,此时 publisher 存储的数据量从 50 个下降到 1 个,注册中心的整个集群的 publisher 存数量,也将下降 50 倍,这将使得注册中心 SOFARegistry 的服务器成本极大降低,同时注册中心的稳定性也将得到大幅度提升。
2、对于 prodiver 发布了哪些服务,这个关系维护在 metadataMap 中,供后续的应用级服务订阅使用。
|应用级服务订阅
在上一节中我们将服务发现,演进到了应用级服务发布,那么此时的服务订阅与服务调用,应该怎样进行呢?我们继续从图 3 中展开:
1、对于 comsumer1,启动时先根据接口进行一次 metadata fetch 的元数据获取,根据 metadataMap 中的数据,可以知道此时 service=com.alipay.sample.FooService 映射的 app=applicationB;同理其他 9 个 service 映射的 app 也是 applicationB;
2、然后以 applicationB 为 dataid,向注册中心发起订阅,注册中心此时不再是存储 consumer1 的 10 个 subscriber,而是存储一个 dataid=applicationB 的 subscriber;注册中心的 subscriber 数量也降低了 10 倍;
3、consumer1 发起服务订阅后,注册中心进行数据推送,此时注册中心推送的数据为:
applicationB:
- 1.1.1.1:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0
- ...
- 1.1.1.100:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=04、可以看到,此时注册中心给 consumer1 的数据推送量,相比于【Part.2 挑战 3】中推送的数据,网络的数据量交互也下降了 10 倍。
|应用级路由
经过上述的“应用级服务发布”和“应用级服务订阅”,我们解决了注册中心的数据量存储瓶颈,注册中心的变更通知网络瓶颈,最后我们来看看 consumer1 中的内存瓶颈如何解决。
通过上面的步骤,consumer1 中拿到了一些数据,分别是:metadataMap 和 publishMap:
applicationB:
- com.alipay.sample.FooService
- com.alipay.sample.BarService
- ...
- com.alipay.sample.Service50
applicationB:
- 1.1.1.1:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0
- ...
- 1.1.1.100:12200?app=applicationB&_SERIALIZETYPE=hessian2&_TIMEOUT=3000&zone=zone1&version=1&_WARMUPTIME=0此时我们可以在 consumer1 进行“应用级路由”的信息封装,如下图:
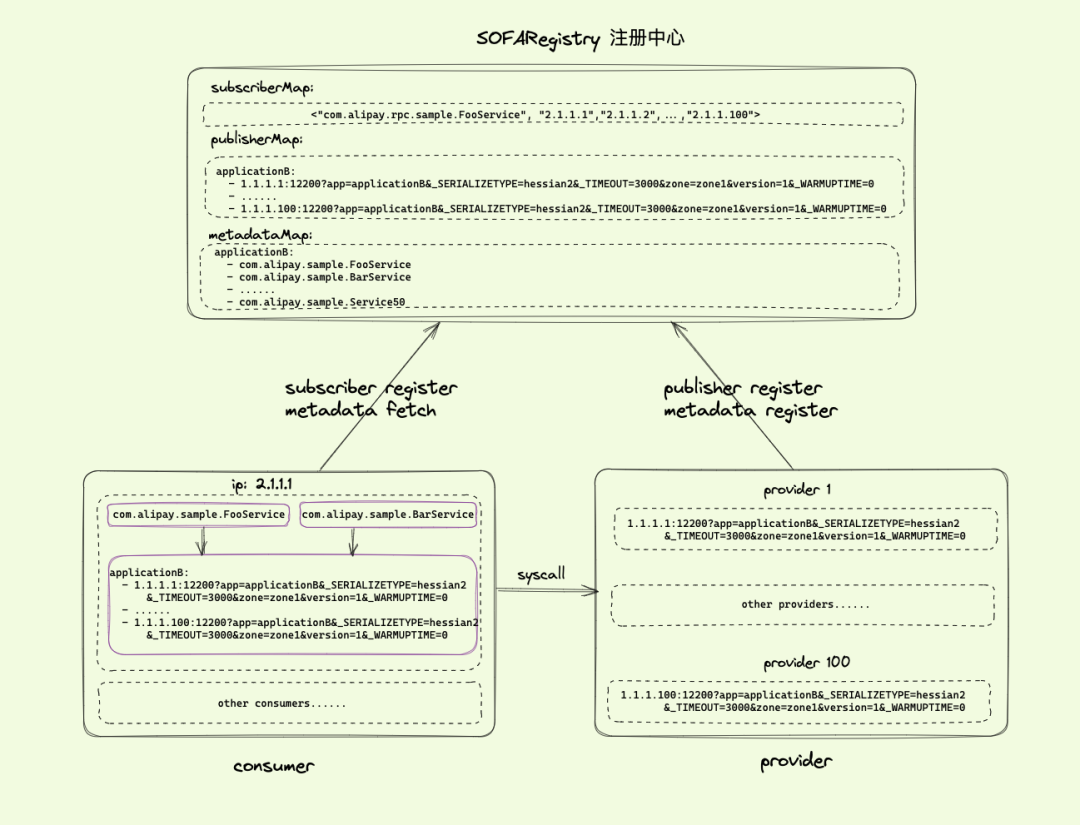
图 4(点击图片查看大图)
如图 4 所示,此时 consumer 中只需要保存 applicationB 的 100 个 publisher,而不再是保存 10(假设订阅了 10 个 service)* 100 = 1000 个 publisher,consumer1 中的服务路由表的内存使用,也降低了 10 倍。
PART. 3
长路漫漫
在上述的微服务模型中,经过上面的应用级服务发现方案推演,我们做到了:
- 注册中心存储的 publisher 数据量下降了 50 倍;
- 注册中心存储的 subscriber 数据量下降了 10 倍;
- 注册中心服务变更通知,网络通信数据量下降了 10 倍;
- 服务订阅端 consumer 中,服务路由表的内存 insue 使用降低了 10 倍;
这个推演结果是令人激动的,然而实际的场景要比上述这个数据更复杂。这个推演模型,要进行真正线上实施,并且进行大规模落地,仍然是长路漫漫。这里先抛出几个问题:
1、如果不同的接口之间,参数并不是完全相同的,我们要如何处理?例如 FooService 的 _TIMEOUT=3000,BarService的_TIMEOUT=1000,Service100的_TIMEOUT=5000;
2、provider 的不同 pod 之间,发布的服务列表有差异,要如何处理?例如 provider1 发布的服务列表是 ["com.alipay.sample.FooService","com.alipay.sample.BarService", ..., "com.alipay.sample.Service50"];provider2 发布的服务列表是 ["com.alipay.sample.FooService","com.alipay.sample.BarService", ..., "com.alipay.sample.Service51"];
3、无论是上述的 provider 还是 consumer,都需要进行 SDK 的代码改造,如何保证线上从“接口级服务发现”,平滑过渡到“应用级服务发现”;
4、如果部分应用无法升级 SDK,方案如何继续演进,拿到期望的效果收益;
5、两个方案过度期间,如何确保注册中心服务的一致性。
这些问题,我们将在下一篇文章《技术内幕|蚂蚁的应用级服务发现实践之路》中详细解答,敬请期待。
|参考链接|
[1]SOFARPC 编程界面:https://www.sofastack.tech/projects/sofa-rpc/programing-sofa-boot-xml/
[2]Dubbo 迈向云原生的里程碑 | 应用级服务发现:https://lexburner.github.io/dubbo-app-pubsub/
了解更多...
SOFARegistry Star 一下✨:
https://github.com/sofastack/sofa-registry/
插播一条重要消息🙆🏻♂️
对云原生、微服务、容器、镜像加速、应用运行时、密码学、规模化运维等方向感兴趣的的伙伴们,快来报名 SOFA五周年活动啦!现场为大家设置了包括 10 多个开源项目的开源互动集市(精美周边等你来拿),也会为大家献上一场轻松、愉快且精彩的开源分享~

本周六 12:00,我们在 C work(北京市朝阳区恒通国际创新园 C6 栋)与你不见不散哦!
 点击“阅读原文”即刻报名,一起来玩吧!
点击“阅读原文”即刻报名,一起来玩吧!