论文地址:https://arxiv.org/pdf/2303.14123.pdf
这是一篇2023年发表在CVPR上的论文,论文题目是Semantic Prompt for Few-Shot Image Recognitio,即用于小样本图像识别的语义提示。
1 Motivation
第一,最近几项研究利用 语义信息 来进行小样本学习的研究。 一方面因为通过少量样本去识别新类别很难,就想使用一些其他模态的信息辅助学习,文本特征可能包含新类和已知类之间的语义关系,所以是一个很好的选择。另一方面因为最近一些出现的强大的自然语言处理(NLP)模型能够从类别中提取出丰富且准确的文本信息。
第二,提出来的这些方法效果并不理想,模型仍然会受到从少量支持样本提取出来的 虚假特征的影响。 因为这些方法直接使用文本嵌入作为图像的分类器,比如 直接 从类名推断出文本原型然后与视觉分类器相结合,这忽略了文本特征和视觉特征之间的 信息差距,因此文本特征无法与视觉特征很好地交互,从而无法给新类别提供 具有判别性的视觉特征。
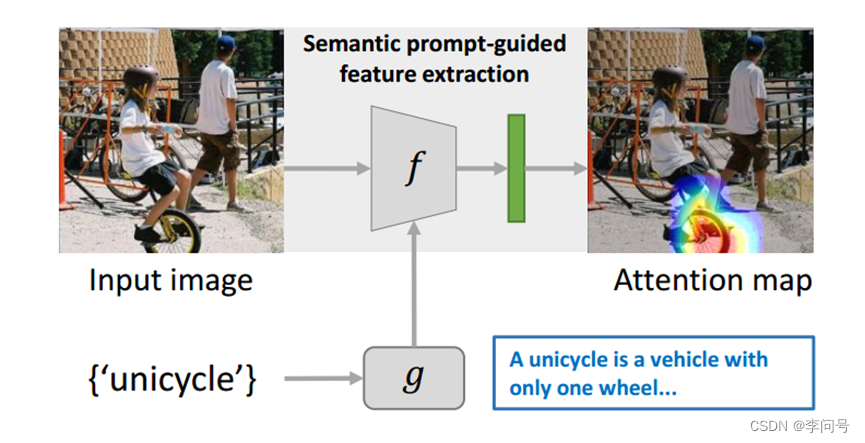
如图所示,输入一张独轮车的图像,特征提取器很容易受到背景杂波的影响,比如车上的女孩还有行人、瓦片等等,并且很有可能特征提取器无法识别其他环境中的独轮车,即无法学习到新类别的通用图像表示。
2 Idea
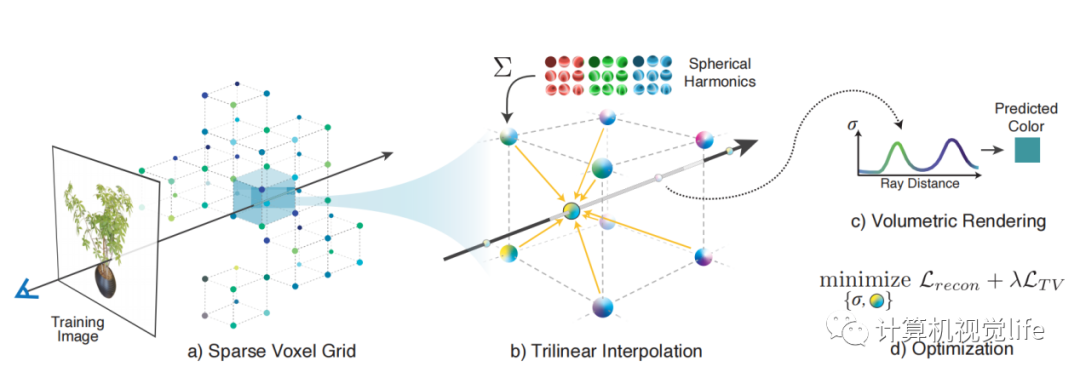
因此,本文提出了一种新的语义提示(SP)的方法,利用丰富的语义信息作为 提示 来 自适应 地调整视觉特征提取器。而不是将文本信息与视觉分类器结合来改善分类器。
本文设计了两种互补机制,将语义提示插入到特征提取器中:一种是通过 自注意力 在 空间维度 上实现 语义提示 和 patch嵌入 之间的交互,另一种是通过沿 通道维度 转换后的语义提示来 补充视觉特征。
通过结合这两种机制,特征提取器提取出具有判别性的与类相关(特定类别) 的特征,并仅用几个支持样本就可以获得 更通用的图像表示。
3 Methods
3.1 训练方法
本文提出的方法包括两个训练阶段:
步骤一采用non-episodic training方法,预训练特征提取器 f 通过分类基类中所有的图像。
步骤二采用元训练范式,使用语义提示(SP) 在大量episodes中 微调特征提取器 f ,使 f 能够在新类中提取出通用和与类相关的视觉特征表示。
3.2 预训练
主干网络采用 Visformer 。它用卷积块替换了前七个 Transformer 层,并在每个阶段之间采用池化以减少序列长度,从而降低计算成本。计算成本和序列长度成正比。
损失函数采用 标准交叉熵损失。目的使其最小化。
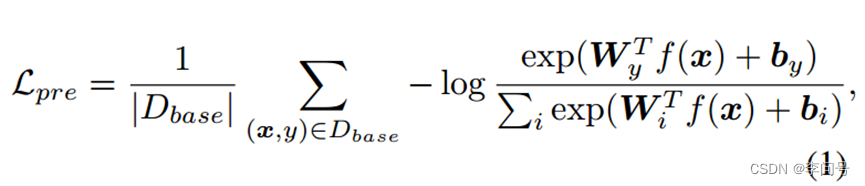
其中W表示分类器,b表示偏差。
具体的训练过程:
第一步,输入图像
x
∈
R
H
×
W
×
C
x ∈ \mathbb{R}^{H \times W \times C\ }
x∈RH×W×C 先被划分为 M 个patches序列
X
=
{
x
p
1
x
,
x
p
2
.
.
.
.
.
.
x
p
M
}
X = \left\{x_p^1x, x_p^2......x_p^M \right\}
X={xp1x,xp2......xpM},其中
x
p
i
∈
R
P
×
P
×
C
x_p^i∈ \mathbb{R}^{P \times P \times C\ }
xpi∈RP×P×C 是一个patch,P 是patch大小。
第二步,每个patch被映射到一个嵌入向量中,并添加一个可学习的位置嵌入。经过预处理的图像patches可以写为:
Z
0
=
[
z
0
1
,
z
0
2
.
.
.
.
.
.
,
z
0
M
]
Z_0= [z_0^1 , z_0^2......,z_0^M ]
Z0=[z01,z02......,z0M],其中
z
0
i
∈
R
C
z
z_0^i ∈ \mathbb{R}^{C_z}
z0i∈RCz是第0层Transformer中位置为 i 的patch token,
C
z
C_z
Cz是每个token(标记)的通道数。
第三步,Patch 标记被送入 L 个 Transformer 层以提取视觉特征,每一层都由多头自注意力 (MSA)、MLP 块、层规范 (LN) 和残差连接组成。在顶层L,我们 平均 序列中所有的嵌入向量 作为提取的图像特征:
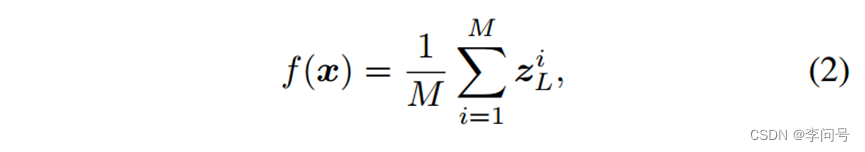
其中
z
L
i
z_L^i
zLi 是第 L 层的第 i 个嵌入向量
3.3 语义提示
首先,使用具有大规模预训练的 NLP 模型从类名中提取文本特征
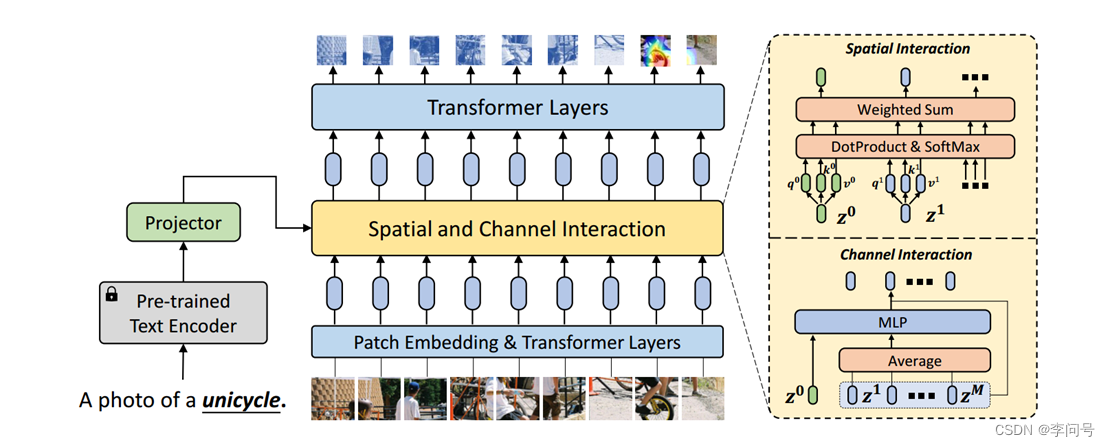
具体的训练步骤,如图所示:
第一步,在一个训练episode中,给定一个支持图像
x
s
x^s
xs,我们将其类名
y
t
e
x
t
y^{text}
ytext输入预训练语言模型
g
(
⋅
)
g(·)
g(⋅)以提取语义特征,即
g
(
y
t
e
x
t
)
g(y^{text})
g(ytext)。
第二步,特征提取过程:
f
g
(
x
s
)
=
f
(
x
s
|
g
(
y
t
e
x
t
)
)
f_{g\ }\left(x^s\right)=f\left(x^s\middle| g\left(y^{text}\right)\right)
fg (xs)=f(xs∣g(ytext))
第三步,将每个类中的支持特征平均得到 原型 ,设
p
i
p_i
pi表示类别 i 的原型,则:
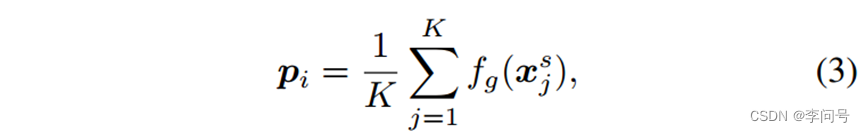
其中
x
j
s
x_j^s
xjs是第 i 类的第
j
t
h
j^{th}
jth支持图像。
第四步,在元训练期间,冻结文本编码器 g(·) 并微调其他参数,通过使用 交叉熵损失 来最大化查询样本与其原型之间的特征相似性 :
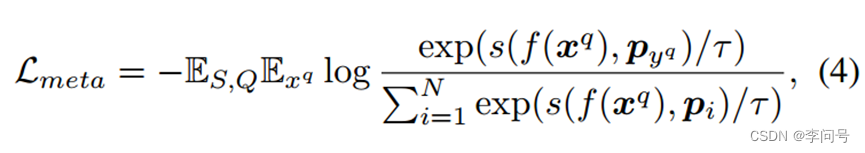
其中 s 表示余弦相似度,
p
y
q
p_{y^q}
pyq是类
y
q
y^q
yq 的原型,τ 是温度超参数。
3.3.1 空间维度的交互
为了促进空间维度上的交互,本文使用语义提示 扩展 图像patch序列 后再提供给 Transformer 编码器。通过自注意层,语义提示可以使特征提取器注意到与类相关的特征,同时抑制其他不相关特征。
给定语义特征 g ( y t e x t ) g(y^{text}) g(ytext) 和第 l 层的patch嵌入的输入序列 Z l − 1 = [ z l − 1 1 , z l − 1 2 , … , z l − 1 M ] ∈ R M × C z Z_{l-1}=\left[z_{l-1}^1,z_{l-1}^2,\ldots,z_{l-1}^M\right]\in\mathbb{R}^{M\times C_z} Zl−1=[zl−11,zl−12,…,zl−1M]∈RM×Cz
使用 投影后的语义特征 扩展
Z
l
−
1
{\ Z}_{l-1}
Zl−1 获得一个新序列
z
^
l
−
1
{\hat{z}}_{l-1}
z^l−1 ∈
R
(
M
+
1
)
×
C
z
\mathbb{R}^{(M+1)\times C_z}
R(M+1)×Cz :
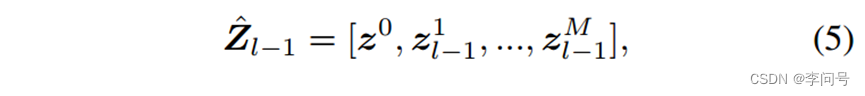
其中
z
0
=
h
s
(
g
(
(
y
t
e
x
t
)
)
∈
R
C
z
{\ z}^0=h_s(g((y^{text}))\ \in\ \mathbb{R}^{C_z}
z0=hs(g((ytext)) ∈ RCz 是空间交互的投影语义嵌入,
h
s
(
⋅
)
h_s(·)
hs(⋅)是保持语义嵌入维度与patch嵌入相同的投影器。
然后,扩展序列 z ^ l − 1 {\hat{z}}_{l-1} z^l−1被送到其他Transformer 层以允许语义提示和patch标记之间沿空间维度的交互。
具体来说:
第一步,MSA将
z
^
l
−
1
{\hat{z}}_{l-1}
z^l−1中的每个标记通过线性投影映射到三个向量
q
,
k
,
v
∈
R
N
h
×
(
M
+
1
)
×
C
z
q, k, v ∈ \mathbb{R}^{N_h\times\left(M+1\right)\times C_z}
q,k,v∈RNh×(M+1)×Cz
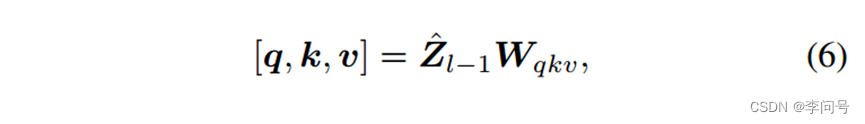
其中
N
h
N_h
Nh是注意头数,
C
h
C_h
Ch是每个注意头的通道数。
第二步,计算q 和 k 的内积并沿空间维度执行 softmax 来计算注意力权重
A
{A}
A ∈
R
N
h
×
(
M
+
1
)
×
(
M
+
1
)
\mathbb {R}^{N_h \times (M+1) \times (M+1)}
RNh×(M+1)×(M+1)
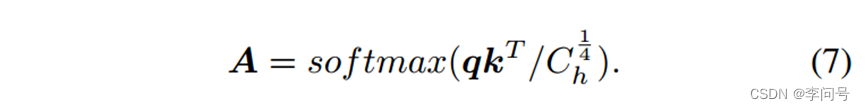
注意力权重用于选择和聚合来自不同位置的信息。
第三步,通过相加连接所有头的输出并通过线性投影得到最终输出
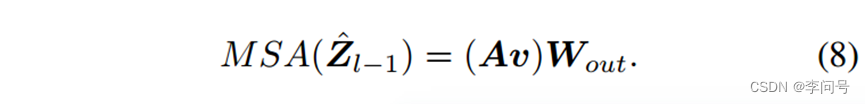
3.3.2 通道维度的交互
对于通道维度上的交互,本文首先将语义提示与从 所有patches中提取的视觉上下文 连接起来,然后将它们提供给 MLP 模块(多层感知机)。将 提取的特征向量 添加到每个patch标记中,以 逐个通道地 调制和增强视觉特征。
首先获得全局视觉上下文向量
z
l
−
1
C
∈
R
C
z
z_{l-1}^C ∈ \mathbb{R}^{C_z}
zl−1C∈RCz, 通过对所有patch 标记进行平均:
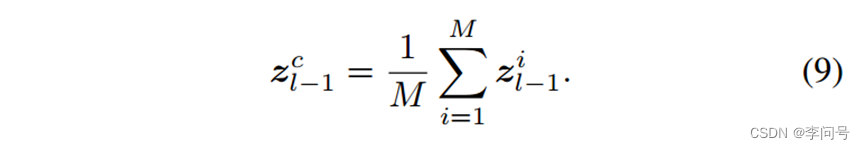
将视觉上下文
Z
l
−
1
c
Z_{l-1}^c
Zl−1c 与投影语义向量
z
0
{\ z}^0
z0连接起来,送入 2 层 MLP 模块以获得调制向量
β
l
−
1
∈
R
C
z
\beta_{l-1}\in R^{C_z}
βl−1∈RCz:
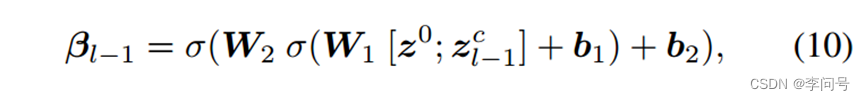
其中
W
1
、
b
1
、
W
2
、
b
2
W_1、b_1、W_2、b_2
W1、b1、W2、b2是 MLP 模块的参数,σ 是 sigmoid 激活函数,
h
c
h_c
hc是通道交互的投影器。
最终将调制向量添加到所有patch 标记,以便它可以调整每个通道的视觉特征。
调制序列
Z
~
l
−
1
∈
R
M
×
C
z
{\widetilde{Z}}_{l-1} ∈ \mathbb{R}^{M\times C_z}
Z
l−1∈RM×Cz 可以写成:
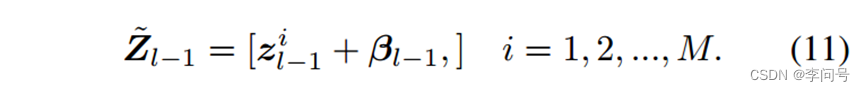
4 Results
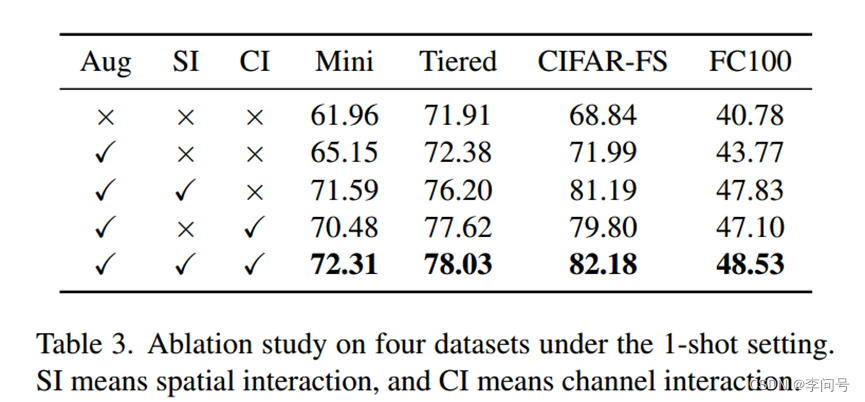
1-shot上由明显提升,CLIP为文本编码器
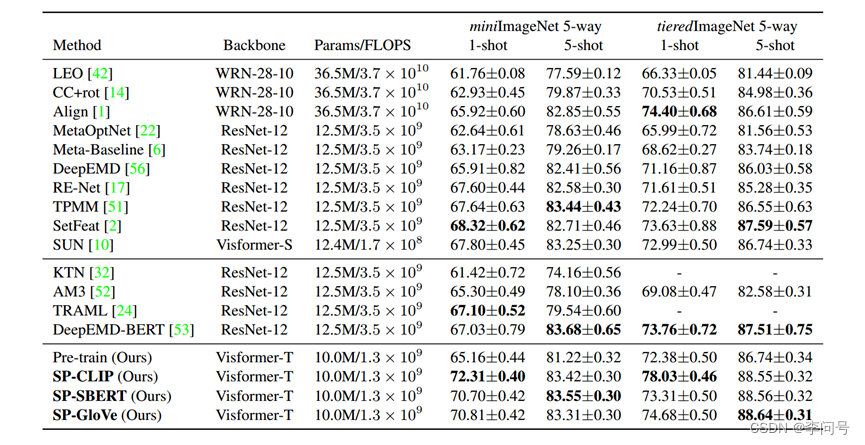
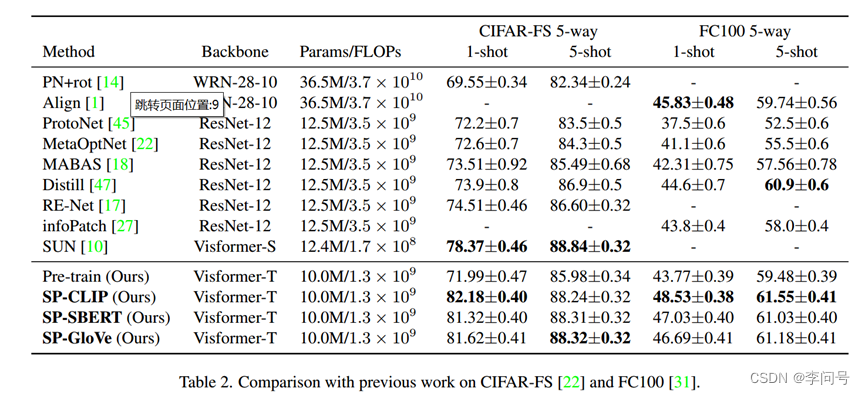
消融实验