为适配不同的数据导入需求,Doris系统提供了五种不同的数据导入方式,每种数据导入方式支持不同的数据源,存在不同的方式(异步,同步)
- Broker load
通过Broker进程访问并读取外部数据源(HDFS)导入Doris,用户通过Mysql提交导入作业,异步执行,通过show load命令查看导入结果
- Stream load
用户通过HTTP协议提交请求并携带原始数据创建导入,主要用于快速将本地文件或者数据流中的数据导入到Doris,导入命令同步返回结果
- Insert
类似Mysql中的insert语句,Doris提供insert into table select ...的方式从Doris的表中读取数据并导入到另一张表中,或者通过insert into table values(...)的方式插入单条数据
- Multi load
用户可以通过HTTP协议提交多个导入作业,Multi load可以保证多个导入作业的原子生效
- Routine load
用户通过Mysql协议提交例行导入作业,生成一个常驻线程,不间断的从数据源(如Kafka)中读取数据并导入到Doris中
1 Broker Load
Broker load是一个导入的异步方式,不同的数据源需要部署不同的 broker 进程。可以通过 show broker 命令查看已经部署的 broker。
1.1 适用场景
- 源数据在Broker可以访问的存储系统中,如HDFS
- 数据量在几十到几百GB级别
1.2 基本原理
用户在递交导入任务后,FE(Doris系统的元数据和调度节点)会生成相应的PLAN(导入执行计划,BE会导入计划将输入导入Doris中)并根据BE(Doris系统的计算和存储节点)的个数和文件的大小,将PLAN分给多个BE执行,每个BE导入一部分数据。BE在执行过程中会从Broker拉取数据,在对数据转换之后导入系统,所有BE均完成导入,由FE最终决定导入是否成功
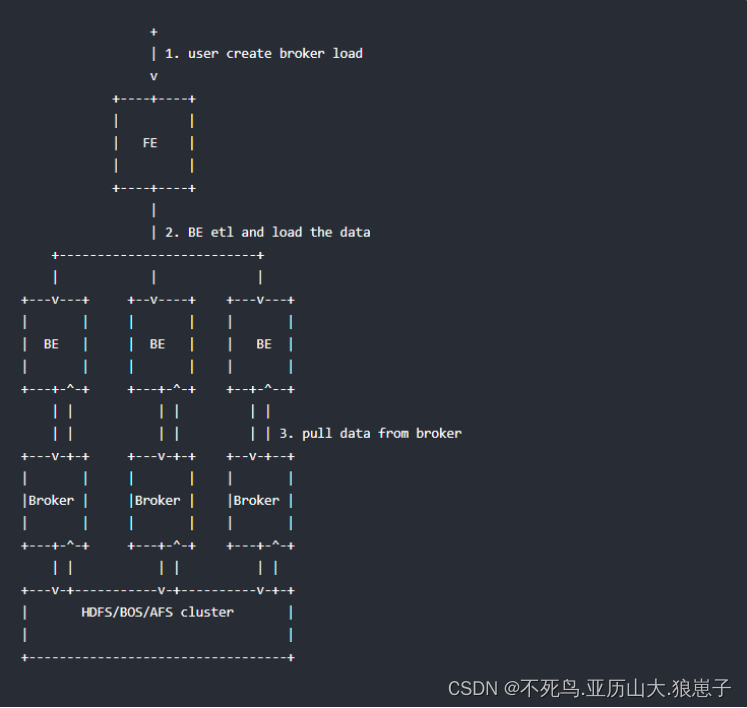
1.3 前置条件
启动hdfs集群:start-dfs.sh
1.4 语法
LOAD LABEL load_label
(
data_desc1[, data_desc2, ...]
)
WITH BROKER broker_name
[broker_properties]
[opt_properties];- load_label
当前导入批次的标签,在一个 database 内唯一。
语法:
[database_name.]your_label- data_desc
用于描述一批导入数据。
语法:
DATA INFILE
(
"file_path1"[, file_path2, ...]
)
[NEGATIVE]
INTO TABLE `table_name`
[PARTITION (p1, p2)]
[COLUMNS TERMINATED BY "column_separator"]
[(column_list)]
[SET (k1 = func(k2))]file_path:文件路径,可以指定到一个文件,也可以用 * 通配符指定某个目录下的所有文件。通配符必须匹配到文件,而不能是目录。
PARTITION:如果指定此参数,则只会导入指定的分区,导入分区以外的数据会被过滤掉。如果不指定,默认导入table的所有分区。
NEGATIVE:如果指定此参数,则相当于导入一批“负”数据。用于抵消之前导入的同一批数据。该参数仅适用于存在 value 列,并且 value 列的聚合类型仅为 SUM 的情况。
column_separator:用于指定导入文件中的列分隔符。默认为 \t如果是不可见字符,则需要加\\x作为前缀,使用十六进制来表示分隔符。如hive文件的分隔符\x01,指定为"\\x01"
column_list:用于指定导入文件中的列和 table 中的列的对应关系。当需要跳过导入文件中的某一列时,将该列指定为 table 中不存在的列名即可。
语法:(col_name1, col_name2, ...)
SET:如果指定此参数,可以将源文件某一列按照函数进行转化,然后将转化后的结果导入到table中。
目前支持的函数有:
strftime(fmt, column) 日期转换函数
- fmt: 日期格式,形如%Y%m%d%H%M%S (年月日时分秒)
- column: column_list中的列,即输入文件中的列。存储内容应为数字型的时间戳。
- 如果没有column_list,则按照palo表的列顺序默认输入文件的列。
time_format(output_fmt, input_fmt, column) 日期格式转化
- output_fmt: 转化后的日期格式,形如%Y%m%d%H%M%S (年月日时分秒)
- input_fmt: 转化前column列的日期格式,形如%Y%m%d%H%M%S (年月日时分秒)
- column: column_list中的列,即输入文件中的列。存储内容应为input_fmt格式的日期字符串。
- 如果没有column_list,则按照palo表的列顺序默认输入文件的列。
alignment_timestamp(precision, column) 将时间戳对齐到指定精度
- precision: year|month|day|hour
- column: column_list中的列,即输入文件中的列。存储内容应为数字型的时间戳。
- 如果没有column_list,则按照palo表的列顺序默认输入文件的列。
- 注意:对齐精度为year、month的时候,只支持20050101~20191231范围内的时间戳。
default_value(value) 设置某一列导入的默认值
- 不指定则使用建表时列的默认值
- md5sum(column1, column2, ...) 将指定的导入列的值求md5sum,返回32位16进制字符串
- replace_value(old_value[, new_value]) 将导入文件中指定的old_value替换为new_value
- new_value如不指定则使用建表时列的默认值
- hll_hash(column) 用于将表或数据里面的某一列转化成HLL列的数据结构
- now() 设置某一列导入的数据为导入执行的时间点。该列必须为 DATE/DATETIME 类型
- broker_name
所使用的 broker 名称,可以通过 show broker 命令查看。不同的数据源需使用对应的 broker。
- broker_properties
用于提供通过 broker 访问数据源的信息。不同的 broker,以及不同的访问方式,需要提供的信息不同。
Apache HDFS:
社区版本的 hdfs,支持简单认证、kerberos 认证。以及支持 HA 配置。
简单认证:
- hadoop.security.authentication = simple (默认)
- username:hdfs 用户名
- password:hdfs 密码
kerberos 认证:
- hadoop.security.authentication = kerberos
- kerberos_principal:指定 kerberos 的 principal
- kerberos_keytab:指定 kerberos 的 keytab 文件路径。该文件必须为 broker 进程所在服务器上的文件。
- kerberos_keytab_content:指定 kerberos 中 keytab 文件内容经过 base64 编码之后的内容。这个跟 kerberos_keytab 配置二选一就可以。
namenode HA:
通过配置 namenode HA,可以在 namenode 切换时,自动识别到新的 namenode
- dfs.nameservices: 指定 hdfs 服务的名字,自定义,如:"dfs.nameservices" = "my_ha"
- dfs.ha.namenodes.xxx:自定义 namenode 的名字,多个名字以逗号分隔。其中 xxx 为 dfs.nameservices 中自定义的名字,如 "dfs.ha.namenodes.my_ha" = "my_nn"
- dfs.namenode.rpc-address.xxx.nn:指定 namenode 的rpc地址信息。其中 nn 表示 dfs.ha.namenodes.xxx 中配置的 namenode 的名字,如:"dfs.namenode.rpc-address.my_ha.my_nn" = "host:port"
- dfs.client.failover.proxy.provider:指定 client 连接 namenode 的 provider,默认为:org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
opt_properties
用于指定一些特殊参数。
语法:
[PROPERTIES ("key"="value", ...)]可以指定如下参数:
- timeout:指定导入操作的超时时间。默认超时为4小时。单位秒。
- max_filter_ratio:最大容忍可过滤(数据不规范等原因)的数据比例。默认零容忍。
- exec_mem_limit:设置导入使用的内存上限。默认为2G,单位字节。这里是指单个 BE 节点的内存上限。一个导入可能分布于多个BE。我们假设 1GB 数据在单个节点处理需要最大5GB内存。那么假设1GB文件分布在2个节点处理,那么理论上每个节点需要内存为2.5GB。则该参数可以设置为 2684354560,即2.5GB
1.4 示例
启动hdfs集群
start-dfs.sh
进入mysqlclient,创建表
CREATE TABLE test_db.user_result(
id INT,
name VARCHAR(50),
age INT,
gender INT,
province VARCHAR(50),
city VARCHAR(50),
region VARCHAR(50),
phone VARCHAR(50),
birthday VARCHAR(50),
hobby VARCHAR(50),
register_date VARCHAR(50)
)DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 10;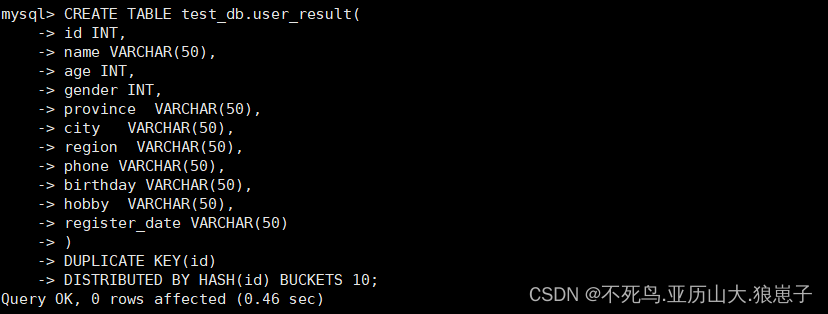
1.5 上传数据到hdfs
hdfs dfs -put user.csv /datas/user.csv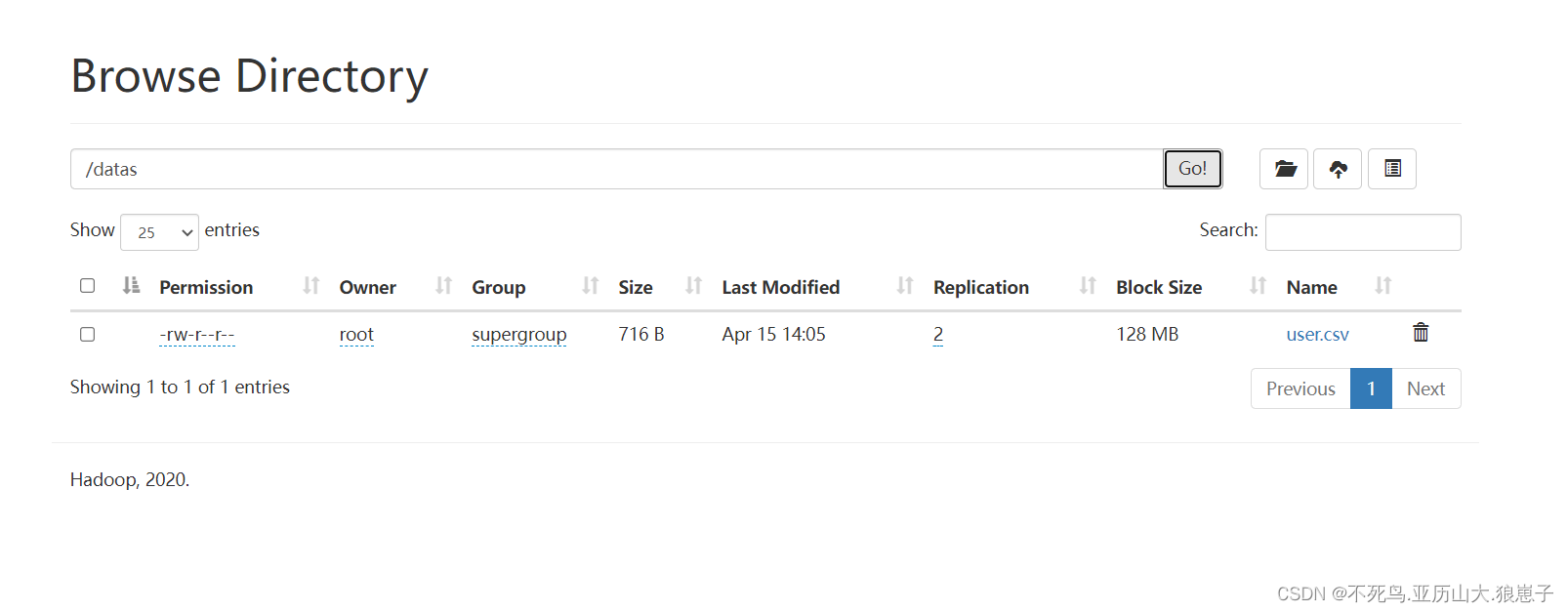
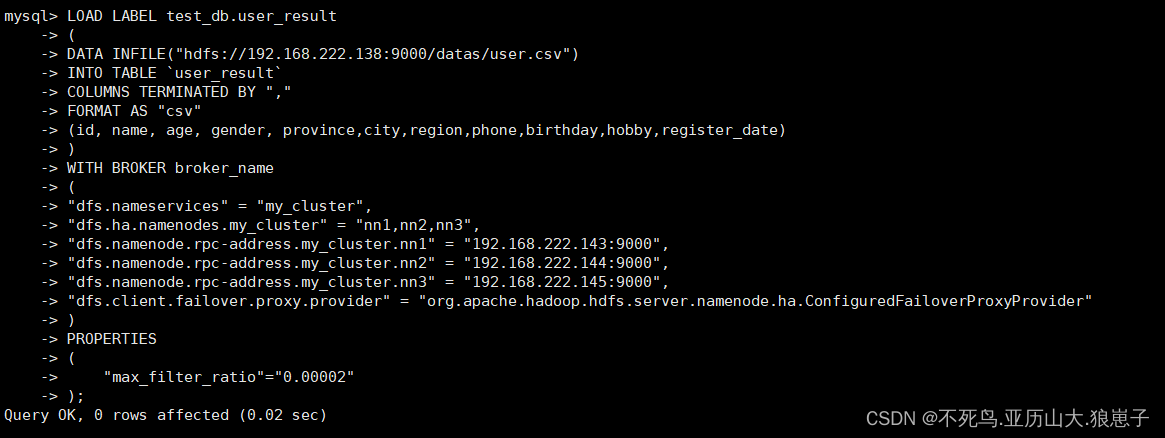
1.6 导入数据
LOAD LABEL test_db.user_result
(
DATA INFILE("hdfs://192.168.222.138:9000/datas/user.csv")
INTO TABLE `user_result`
COLUMNS TERMINATED BY ","
FORMAT AS "csv"
(id, name, age, gender, province,city,region,phone,birthday,hobby,register_date)
)
WITH BROKER broker_name
(
"dfs.nameservices" = "my_cluster",
"dfs.ha.namenodes.my_cluster" = "nn1,nn2,nn3",
"dfs.namenode.rpc-address.my_cluster.nn1" = "192.168.222.143:9000",
"dfs.namenode.rpc-address.my_cluster.nn2" = "192.168.222.144:9000",
"dfs.namenode.rpc-address.my_cluster.nn3" = "192.168.222.145:9000",
"dfs.client.failover.proxy.provider" = "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
)
PROPERTIES
(
"max_filter_ratio"="0.00002"
);
注意
broker_name:broker的名称,可以通过show broker;查看

1.7 查看load作业
show load;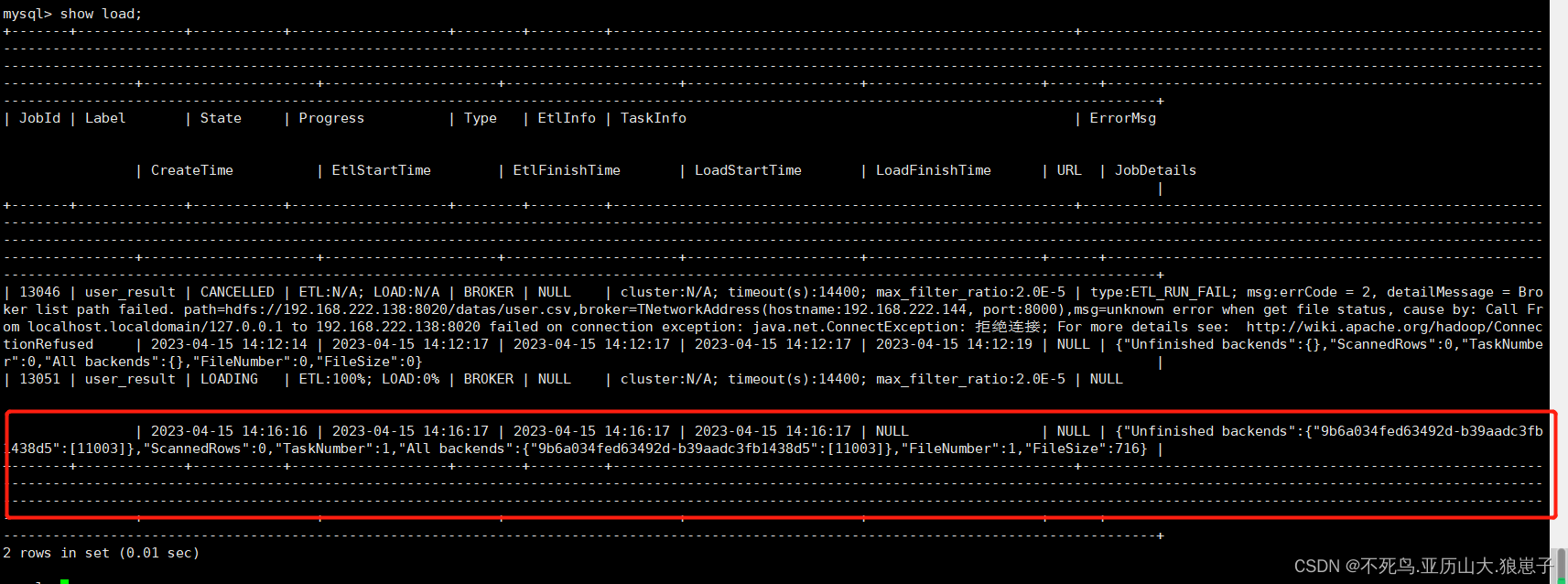
1.8 查看导入数据
select * from user_result;
1.9 查看导入
Broker load 导入方式由于是异步的,所以用户必须将创建导入的 Label 记录,并且在查看导入命令中使用 Label 来查看导入结果。查看导入命令在所有导入方式中是通用的,具体语法可执行 HELP SHOW LOAD 查看。
show load order by createtime desc limit 1\G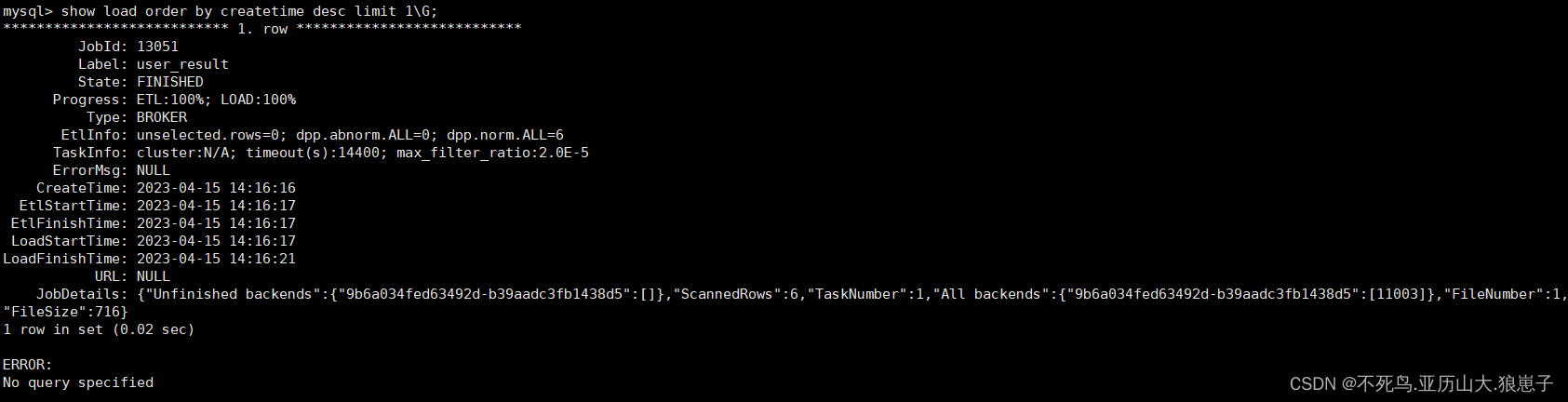
- JobId
导入任务的唯一ID,每个导入任务的 JobId 都不同,由系统自动生成。与 Label 不同的是,JobId永远不会相同,而 Label 则可以在导入任务失败后被复用。
- Label
导入任务的标识。
- State
导入任务当前所处的阶段。在 Broker load 导入过程中主要会出现 PENDING 和 LOADING 这两个导入中的状态。如果 Broker load 处于 PENDING 状态,则说明当前导入任务正在等待被执行;LOADING 状态则表示正在执行中。
导入任务的最终阶段有两个:CANCELLED 和 FINISHED,当 Load job 处于这两个阶段时,导入完成。其中 CANCELLED 为导入失败,FINISHED 为导入成功。
- Progress
导入任务的进度描述。分为两种进度:ETL 和 LOAD,对应了导入流程的两个阶段 ETL 和 LOADING。目前 Broker load 由于只有 LOADING 阶段,所以 ETL 则会永远显示为 N/A
LOAD 的进度范围为:0~100%。
LOAD 进度 = 当前完成导入的表个数 / 本次导入任务设计的总表个数 * 100%
如果所有导入表均完成导入,此时 LOAD 的进度为 99% 导入进入到最后生效阶段,整个导入完成后,LOAD 的进度才会改为 100%。
导入进度并不是线性的。所以如果一段时间内进度没有变化,并不代表导入没有在执行。
- Type
导入任务的类型。Broker load 的 type 取值只有 BROKER。
- EtlInfo
主要显示了导入的数据量指标 unselected.rows , dpp.norm.ALL 和 dpp.abnorm.ALL。用户可以根据第一个数值判断 where 条件过滤了多少行,后两个指标验证当前导入任务的错误率是否超过 max_filter_ratio。
三个指标之和就是原始数据量的总行数。
- TaskInfo
主要显示了当前导入任务参数,也就是创建 Broker load 导入任务时用户指定的导入任务参数,包括:cluster,timeout 和max_filter_ratio。
- ErrorMsg
在导入任务状态为CANCELLED,会显示失败的原因,显示分两部分:type 和 msg,如果导入任务成功则显示 N/A。
type的取值意义:
USER_CANCEL: 用户取消的任务
ETL_RUN_FAIL:在ETL阶段失败的导入任务
ETL_QUALITY_UNSATISFIED:数据质量不合格,也就是错误数据率超过了 max_filter_ratio
LOAD_RUN_FAIL:在LOADING阶段失败的导入任务
TIMEOUT:导入任务没在超时时间内完成
UNKNOWN:未知的导入错误
- CreateTime/EtlStartTime/EtlFinishTime/LoadStartTime/LoadFinishTime
这几个值分别代表导入创建的时间,ETL阶段开始的时间,ETL阶段完成的时间,Loading阶段开始的时间和整个导入任务完成的时间。
Broker load 导入由于没有 ETL 阶段,所以其 EtlStartTime, EtlFinishTime, LoadStartTime 被设置为同一个值。
导入任务长时间停留在 CreateTime,而 LoadStartTime 为 N/A 则说明目前导入任务堆积严重。用户可减少导入提交的频率。
LoadFinishTime - CreateTime = 整个导入任务所消耗时间
LoadFinishTime - LoadStartTime = 整个 Broker load 导入任务执行时间 = 整个导入任务所消耗时间 - 导入任务等待的时间
- URL
导入任务的错误数据样例,访问 URL 地址既可获取本次导入的错误数据样例。当本次导入不存在错误数据时,URL 字段则为 N/A。
- JobDetails
显示一些作业的详细运行状态。包括导入文件的个数、总大小(字节)、子任务个数、已处理的原始行数,运行子任务的 BE 节点 Id,未完成的 BE 节点 Id。
{"Unfinished backends":{"9c3441027ff948a0-8287923329a2b6a7":[10002]},"ScannedRows":2390016,"TaskNumber":1,"All backends":{"9c3441027ff948a0-8287923329a2b6a7":[10002]},"FileNumber":1,"FileSize":1073741824}
其中已处理的原始行数,每 5 秒更新一次。该行数仅用于展示当前的进度,不代表最终实际的处理行数。实际处理行数以 EtlInfo 中显示的为准。
1.10 取消导入
当 Broker load 作业状态不为 CANCELLED 或 FINISHED 时,可以被用户手动取消。取消时需要指定待取消导入任务的 Label 。取消导入命令语法可执行 HELP CANCEL LOAD查看。

1.11 其他导入案例参考
从 HDFS 导入一批数据,数据格式为CSV,同时使用 kerberos 认证方式,同时配置 namenode HA
- 设置最大容忍可过滤(数据不规范等原因)的数据比例。
LOAD LABEL test_db.user_result2
(
DATA INFILE("hdfs://node1:9000/datas/user.csv")
INTO TABLE `user_result`
COLUMNS TERMINATED BY ","
FORMAT AS "csv"
(id, name, age, gender, province,city,region,phone,birthday,hobby,register_date)
)
WITH BROKER broker_name
(
"hadoop.security.authentication"="kerberos",
"kerberos_principal"="doris@YOUR.COM",
"kerberos_keytab_content"="BQIAAABEAAEACUJBSURVLkNPTQAEcGFsbw",
"dfs.nameservices" = "my_ha",
"dfs.ha.namenodes.my_ha" = "my_namenode1, my_namenode2",
"dfs.namenode.rpc-address.my_ha.my_namenode1" = "node1:9000",
"dfs.namenode.rpc-address.my_ha.my_namenode2" = "node2:9000",
"dfs.client.failover.proxy.provider" ="org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
)
PROPERTIES
(
"max_filter_ratio"="0.00002"
);- 从 HDFS 导入一批数据,指定超时时间和过滤比例。使用铭文 my_hdfs_broker 的 broker。简单认证。
LOAD LABEL test_db.user_result3
(
DATA INFILE("hdfs://node1:9000/datas/user.csv")
INTO TABLE `user_result`
)
WITH BROKER broker_name
(
"username" = "hdfs_user",
"password" = "hdfs_passwd"
)
PROPERTIES
(
"timeout" = "3600",
"max_filter_ratio" = "0.1"
);其中 hdfs_host 为 namenode 的 host,hdfs_port 为 fs.defaultFS 端口(默认9000)
- 从 HDFS 导入一批数据,指定hive的默认分隔符\x01,并使用通配符*指定目录下的所有文件
使用简单认证,同时配置 namenode HA。
LOAD LABEL test_db.user_result4
(
DATA INFILE("hdfs://node1:9000/datas/input/*")
INTO TABLE `user_result`
COLUMNS TERMINATED BY "\\x01"
)
WITH BROKER broker_name
(
"username" = "hdfs_user",
"password" = "hdfs_passwd",
"dfs.nameservices" = "my_ha",
"dfs.ha.namenodes.my_ha" = "my_namenode1, my_namenode2",
"dfs.namenode.rpc-address.my_ha.my_namenode1" = "node1:8020",
"dfs.namenode.rpc-address.my_ha.my_namenode2" = "node2:8020",
"dfs.client.failover.proxy.provider" ="org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
)- 从 HDFS 导入一批“负”数据。同时使用 kerberos 认证方式。提供 keytab 文件路径
LOAD LABEL test_db.user_result5
(
DATA INFILE("hdfs://node1:9000/datas/input/old_file)
NEGATIVE
INTO TABLE `user_result`
COLUMNS TERMINATED BY "\t"
)
WITH BROKER broker_name
(
"hadoop.security.authentication" = "kerberos",
"kerberos_principal"="doris@YOUR.COM",
"kerberos_keytab"="/home/palo/palo.keytab"
)- 从HDFS导入一批数据,指定分区。同时使用kerberos认证方式。提供base64编码后的keytab 文件内容
LOAD LABEL test_db.user_result6
(
DATA INFILE("hdfs://node1:9000/datas/input/file")
INTO TABLE `user_result`
PARTITION (p1, p2)
COLUMNS TERMINATED BY ","
(k1, k3, k2, v1, v2)
)
WITH BROKER broker_name
(
"hadoop.security.authentication"="kerberos",
"kerberos_principal"="doris@YOUR.COM",
"kerberos_keytab_content"="BQIAAABEAAEACUJBSURVLkNPTQAEcGFsbw"
)




![[2019.01.24]JNI经验积累](https://img-blog.csdnimg.cn/7516100b75f446b29da86e26a5bf453f.png)