文章目录
- 背景
- 逻辑原理
- connector架构
- sql处理阶段
- 代码实例
- 代码debug
- 参考文献
背景
source/sink 是flink最核心的部分之一,通过对其实现原理的学习,结合源码debug,有助于加深对框架处理过程的理解,以及架构设计上的提升。
逻辑原理
如果我们对自己对接一个数据源,核心的话就是连接器connector,比如关系型数据库就是jdbc。
connector架构
flink官方connector的架构如下
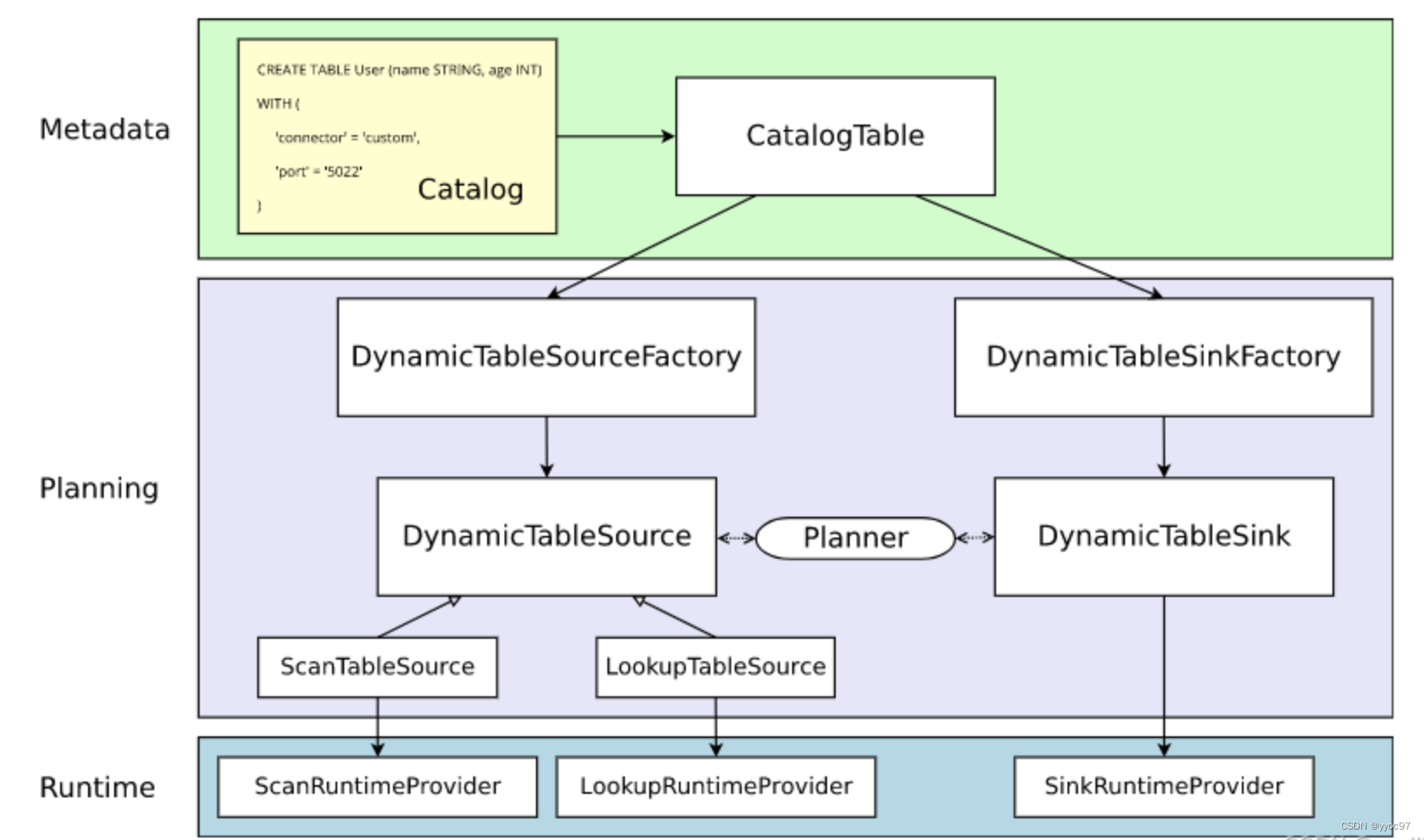
- MetaData
将 sql create source table 转化为实际的 CatalogTable,对应代码RelNode - Planning
创建 RelNode 的过程中使用 SPI 将所有的 source(DynamicTableSourceFactory)\sink(DynamicTableSinkFactory) 工厂动态加载,获取到 connector = kafka,然后从所有 source 工厂中过滤出名称为 kafka 并且 继承自 DynamicTableSourceFactory.class 的工厂类 KafkaDynamicTableFactory,使用 KafkaDynamicTableFactory 创建出 KafkaDynamicSource - Runtime
KafkaDynamicSource 创建出 FlinkKafkaConsumer,负责flink程序实际运行。
sql处理阶段
因为文章采用flink sql作为实例,所以先了解下sql在集群中经历的大致步骤,后续结合源码有助理解。
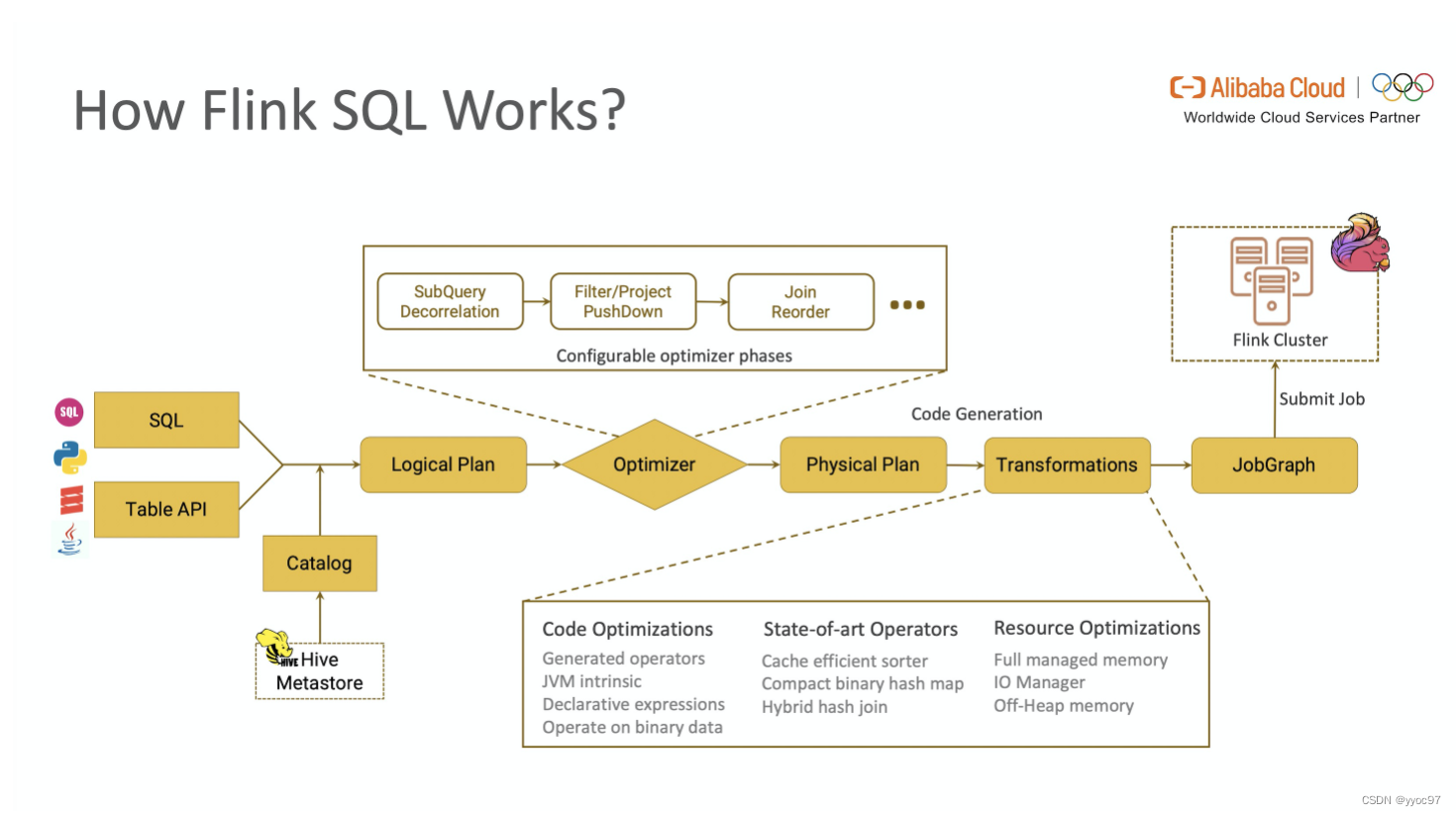
从图中可以看出,一段查询 SQL / 使用TableAPI 编写的程序(以下简称 TableAPI 代码)从输入到编译为可执行的 JobGraph 主要经历如下几个阶段
- 将 SQL文本 / TableAPI 代码转化为逻辑执行计划(Logical Plan)
- Logical Plan 通过优化器优化为物理执行计划(Physical Plan)
- 通过代码生成技术生成 Transformations 后进一步编译为可执行的 JobGraph 提交运行
代码实例
版本flink-1.13.1
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
public class KafkaSourceTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.setParallelism(1);
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.useBlinkPlanner()
.inStreamingMode().build();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env, settings);
tEnv.executeSql(
"CREATE TABLE KafkaSourceTable (\n"
+ " `f0` STRING,\n"
+ " `f1` STRING\n"
+ ") WITH (\n"
+ " 'connector' = 'kafka',\n"
+ " 'topic' = 'topic',\n"
+ " 'properties.bootstrap.servers' = 'localhost:9092',\n"
+ " 'properties.group.id' = 'testGroup',\n"
+ " 'format' = 'json'\n"
+ ")"
);
Table t = tEnv.sqlQuery("SELECT * FROM KafkaSourceTable");
tEnv.toAppendStream(t, Row.class).print();
env.execute();
}
}
代码debug
-
从tEnv.sqlQuery方法断点进入
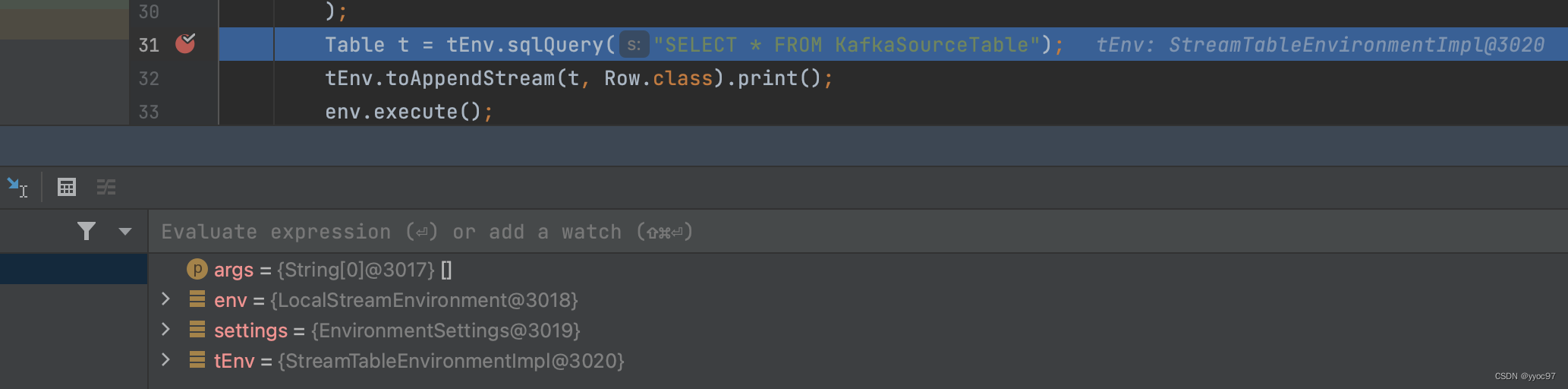
-
解析sql语法
后面回根据解析返回的操作表类型创建对应的Table
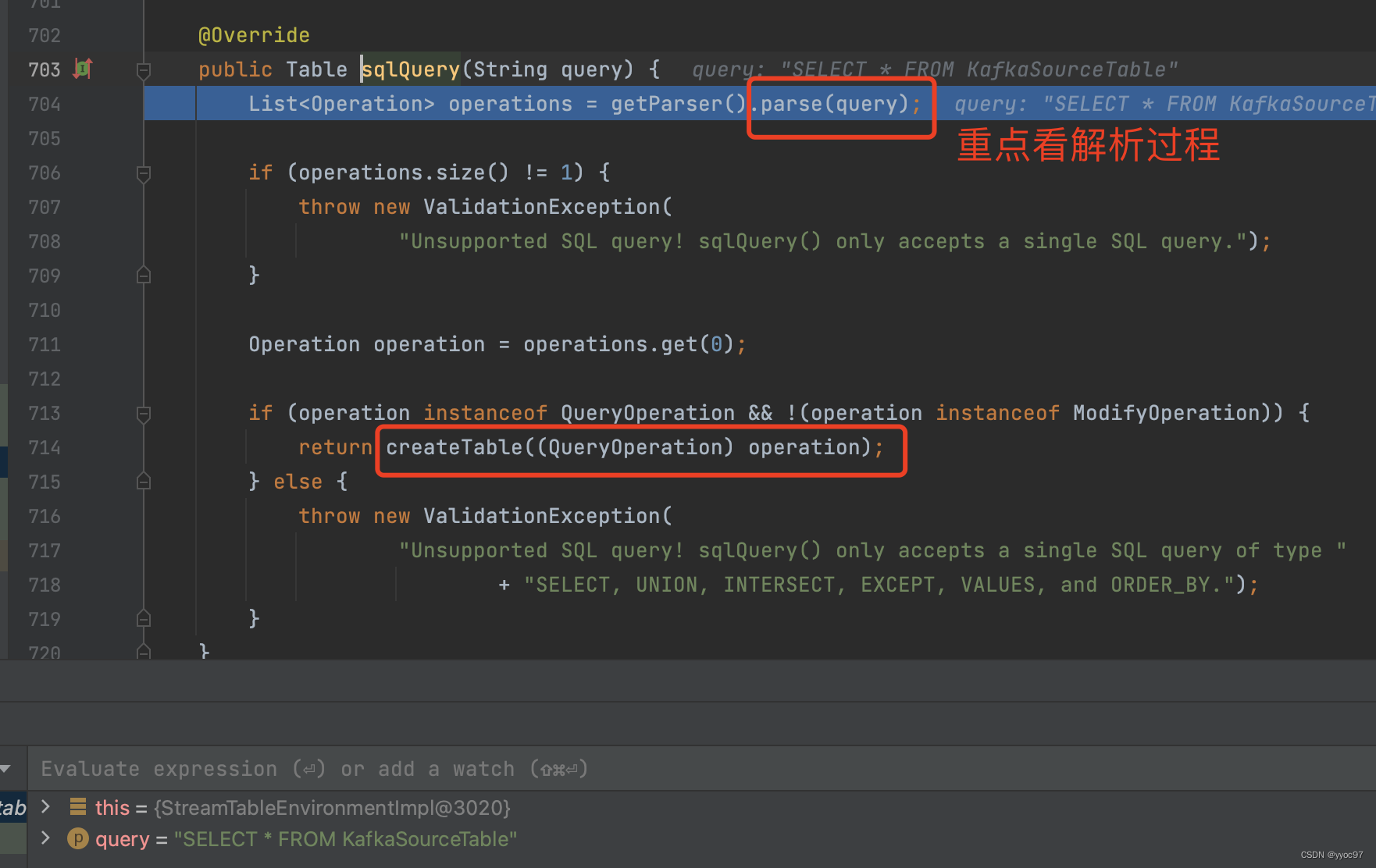
-
parse主要工作
获取语法解析器parser,查询计划实现类planner。 将sql语句解析成生成AST抽象语法树SqlNode(实际SqlSelector),之后调用convert转换方法。
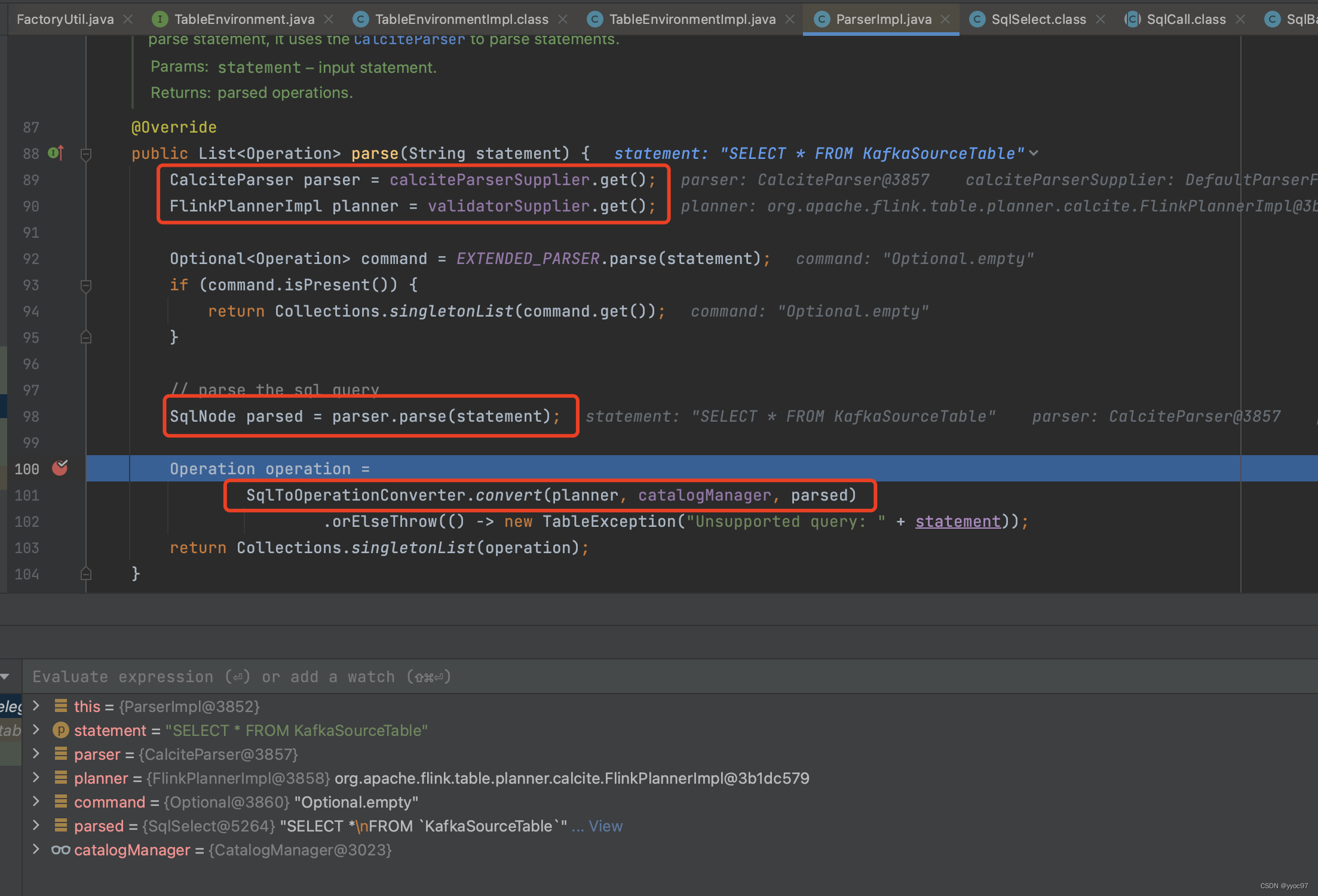
-
convert处理
首先validate验证SqlNode的正确性。

之后根据sql kind为QUERY进入converter.convertSqlQuery方法
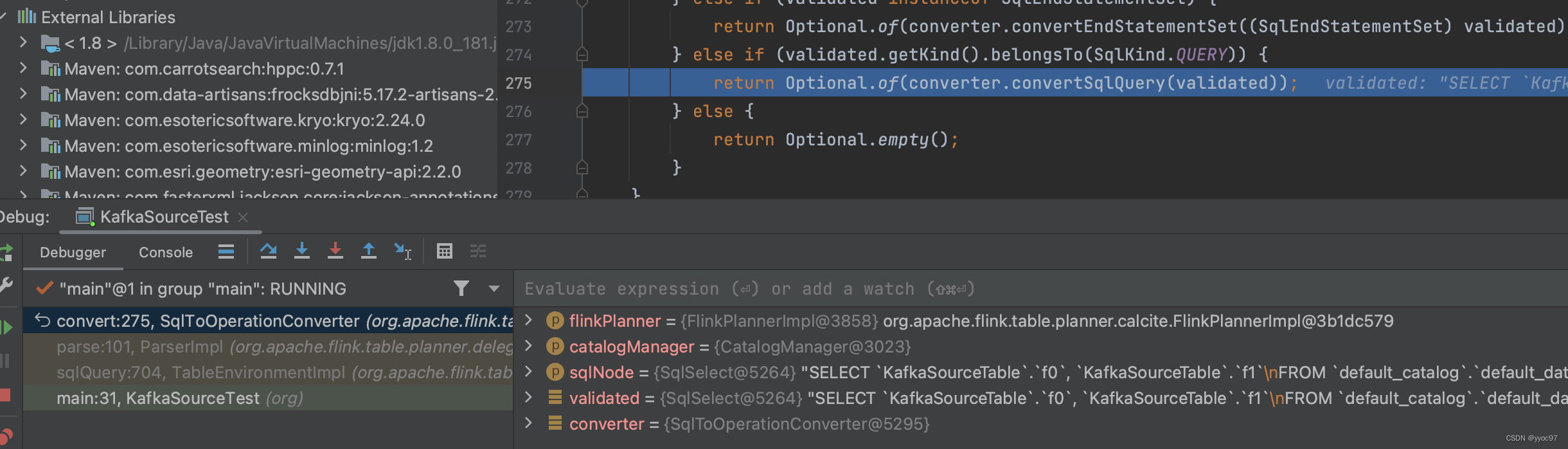
-
convertSQLQuery处理
生成逻辑计划,作用是SqlNode–>RelNode。
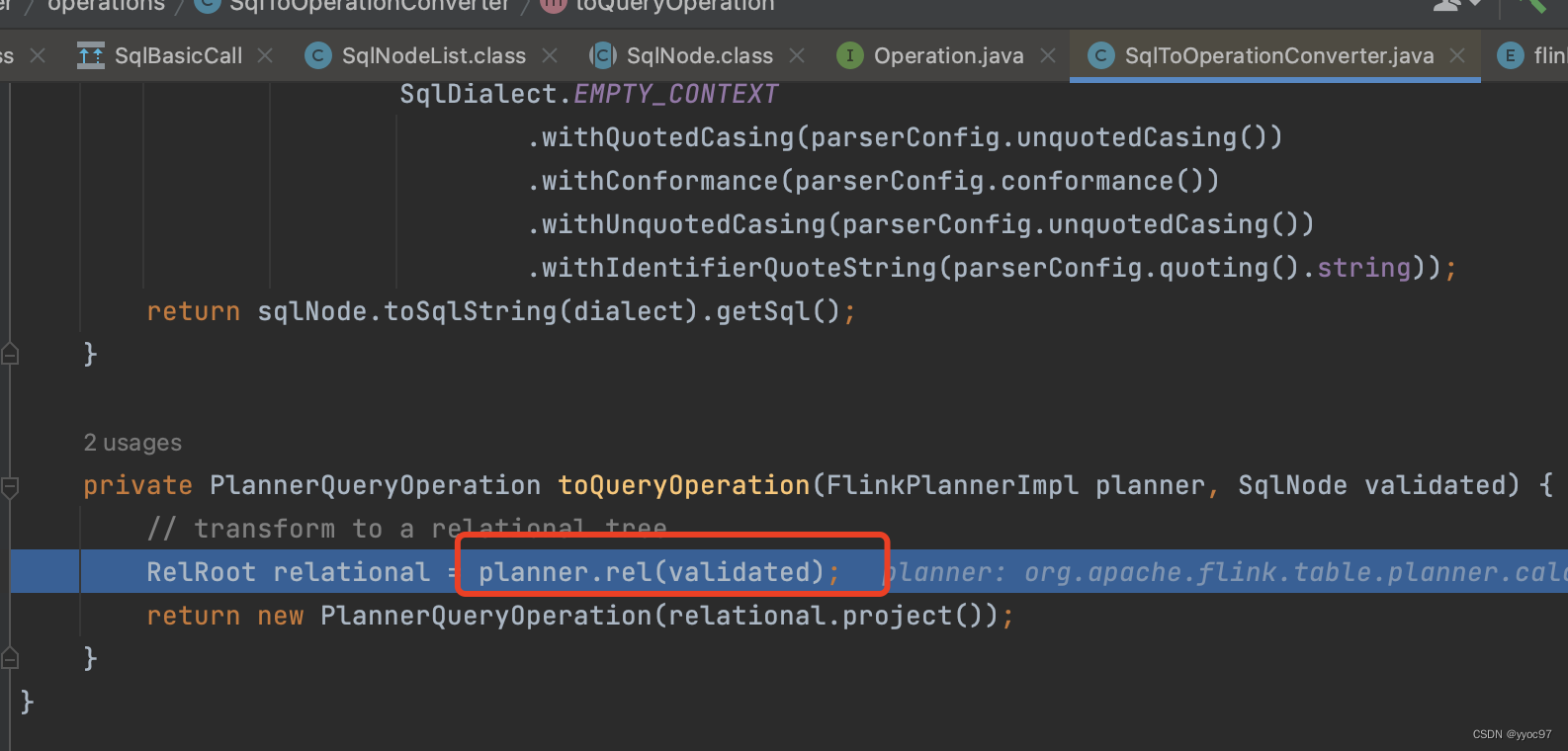
-
rel方法
调用sqlToRelConverter.convertQuery方法。
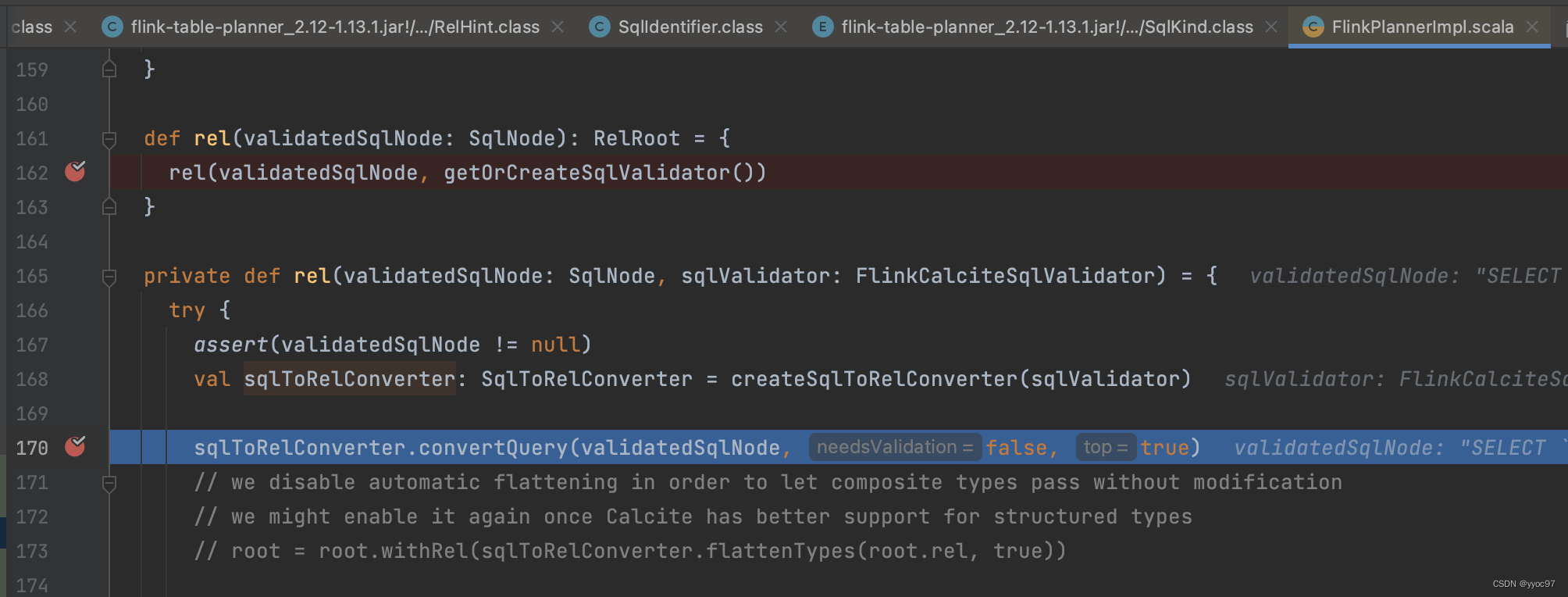
真正的实现是在 convertQueryRecursive() 方法中完成的。
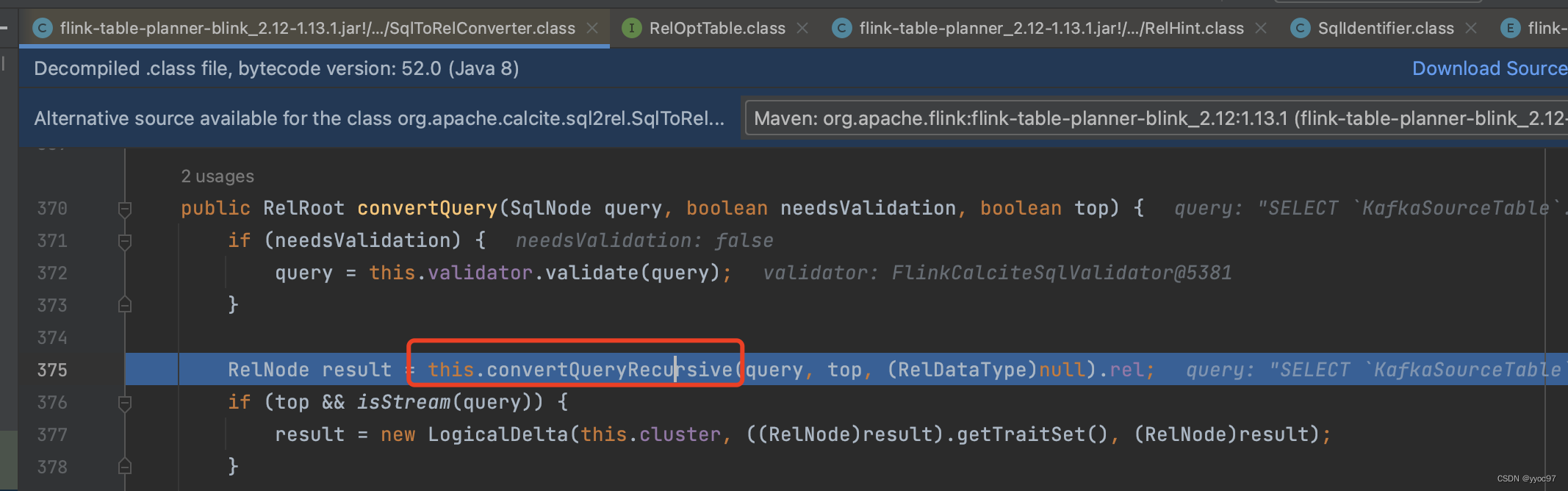
实际根据kind调用convertSelect方法
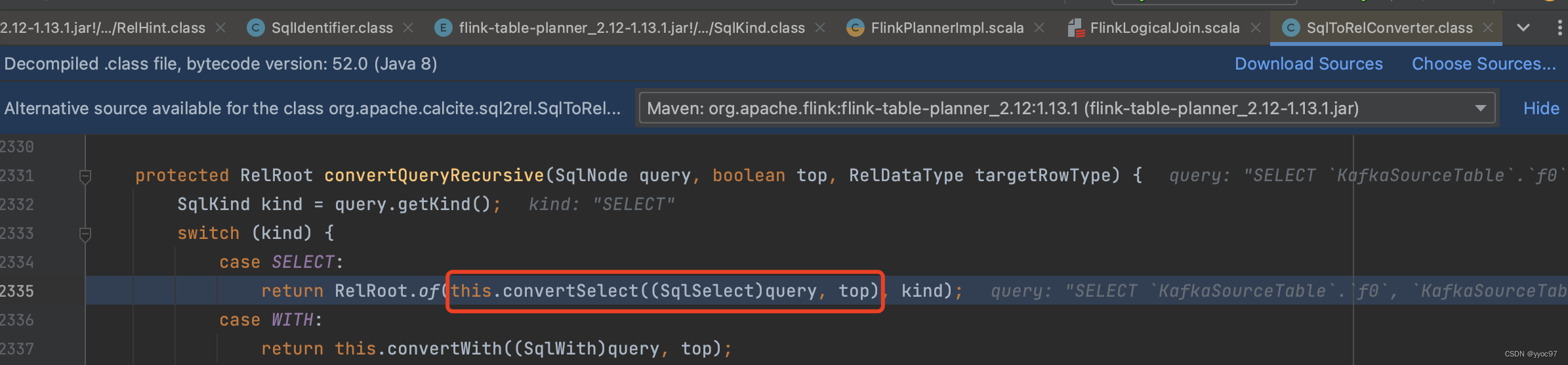
-
调用convertIdentifier
这中间过程省略一部分,实际调用到convertIdentifier方法。参数BlackBoard是对select进行转换时的一个临时工作空间,可以临时记录下转换过程中需要的信息,比如select依赖的scope、当前的root节点、当前节点是否是top节点等。这里还会创建CatalogSourceTable 类,此类继承自 FlinkPreparingTableBase,负责将 Calcite 的 RelOptTable转化为TableSourceTable
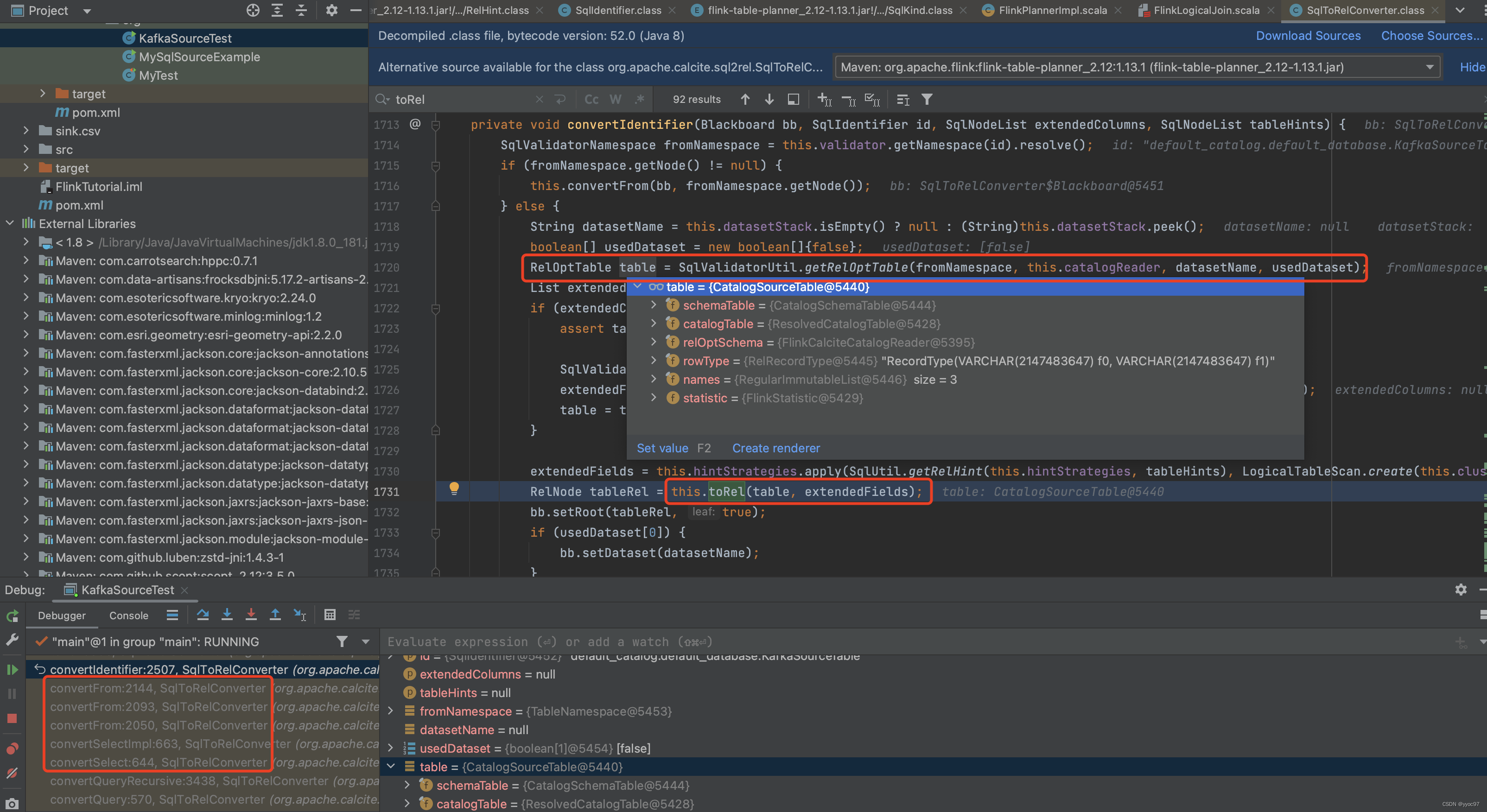
-
toRel
这里会根据指定的connector,创建对应的tableSource,就和我们connector架构部分关联上了。发现 tableSource 已经是 KafkaDynamicSource。另外可以发现创建table source参数catalogTable,包含了所有 sql create source table 中信息的 catalogTable 变量传入了。
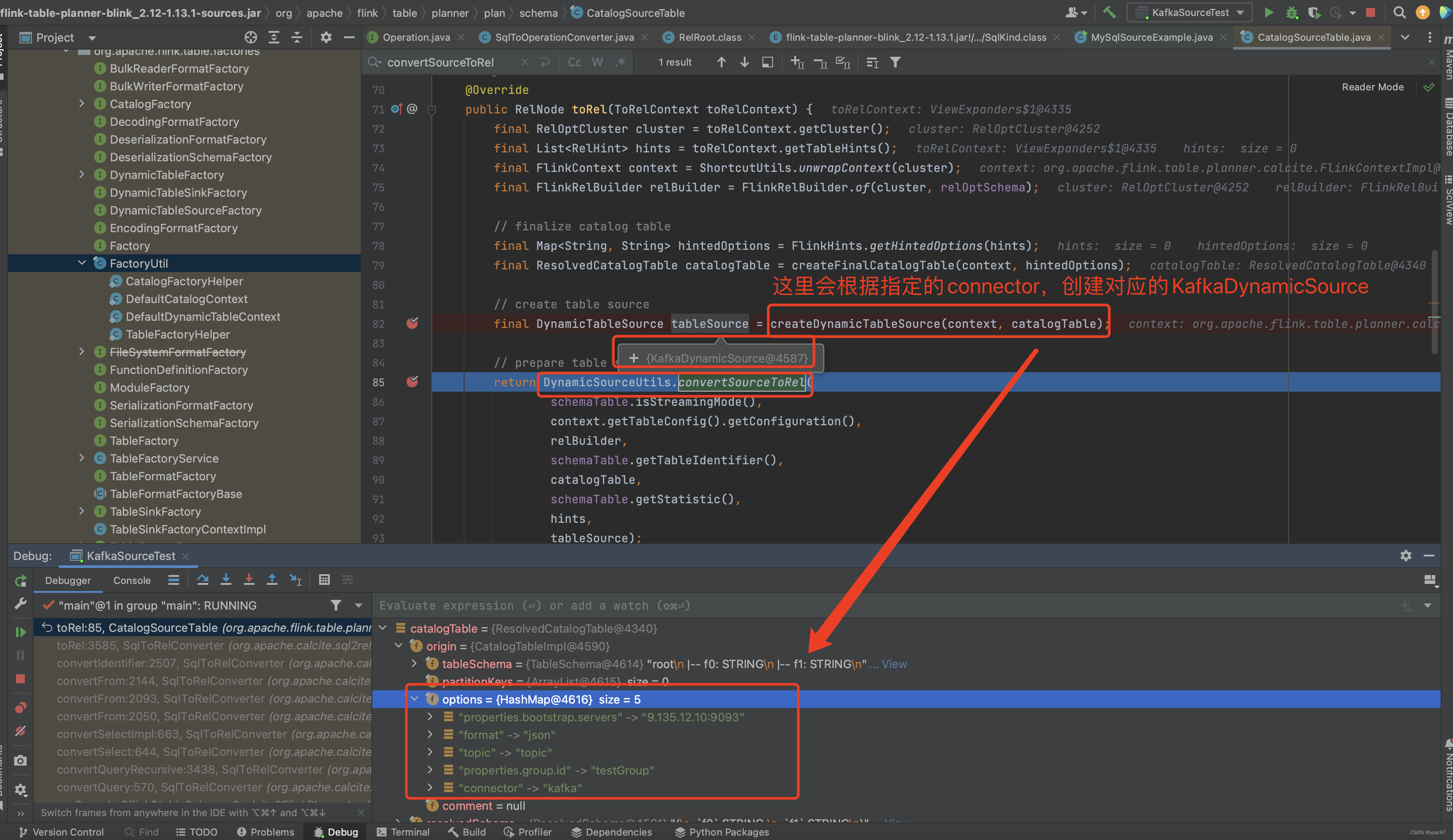
-
createDynamicTableSource
使用 SPI 将所有的 source(DynamicTableSourceFactory)\sink(DynamicTableSinkFactory) 工厂动态加载,然后根据factoryClass过滤出KafkaDynamicTableFactory
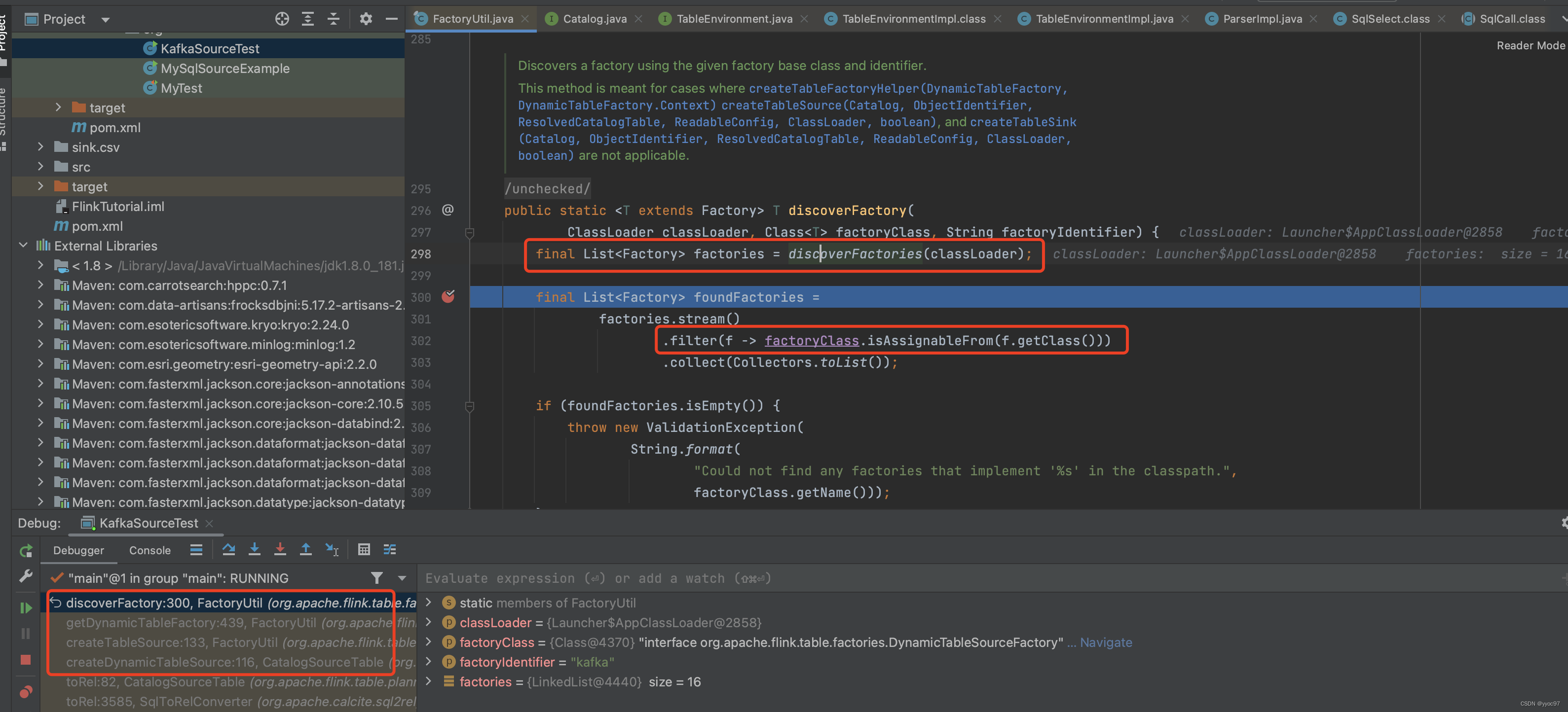
10.createTableSource
使用 kafka 工厂对象创建出 kafka source。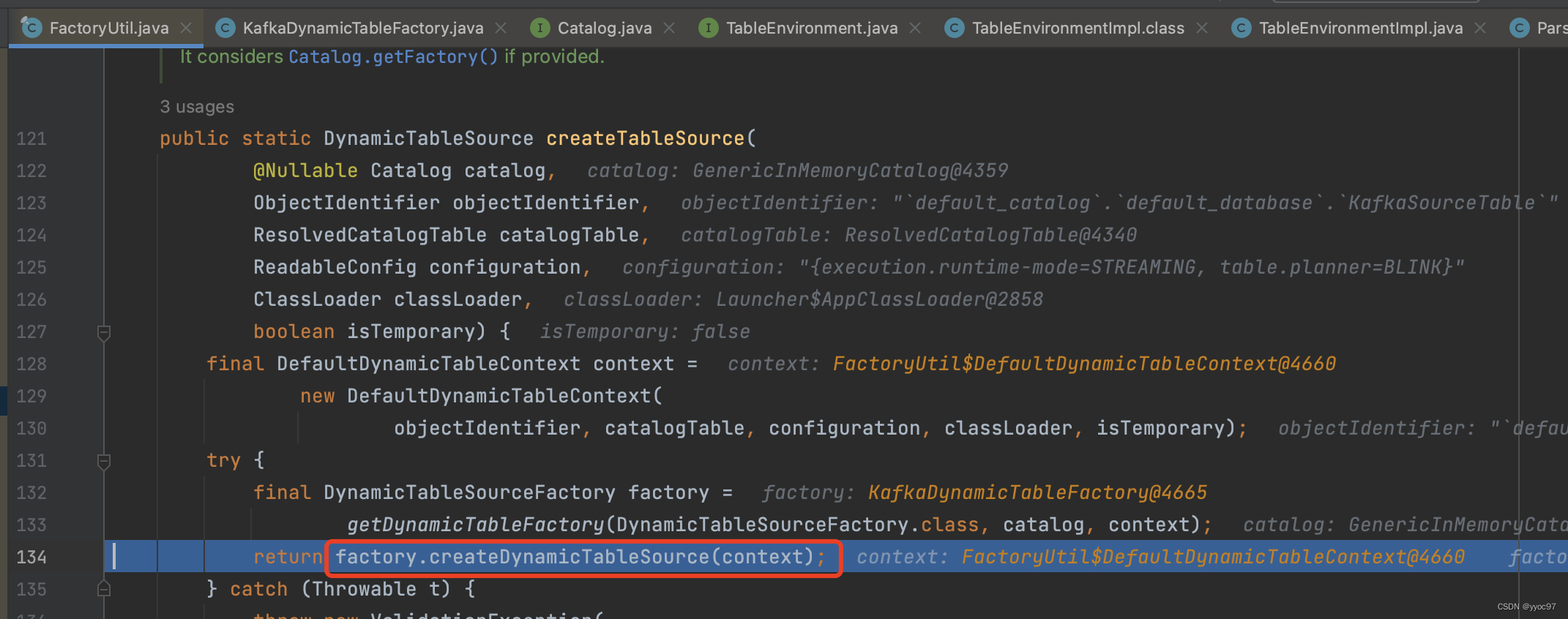
-
获取format
进入factory具体实现可以看到 KafkaDynamicTableFactory.createDynamicTableSource 中调用 KafkaDynamicTableFactory.createKafkaTableSource 来创建 KafkaDynamicSource。 另外这里还有一个重要点就是获取key value反序列化schema
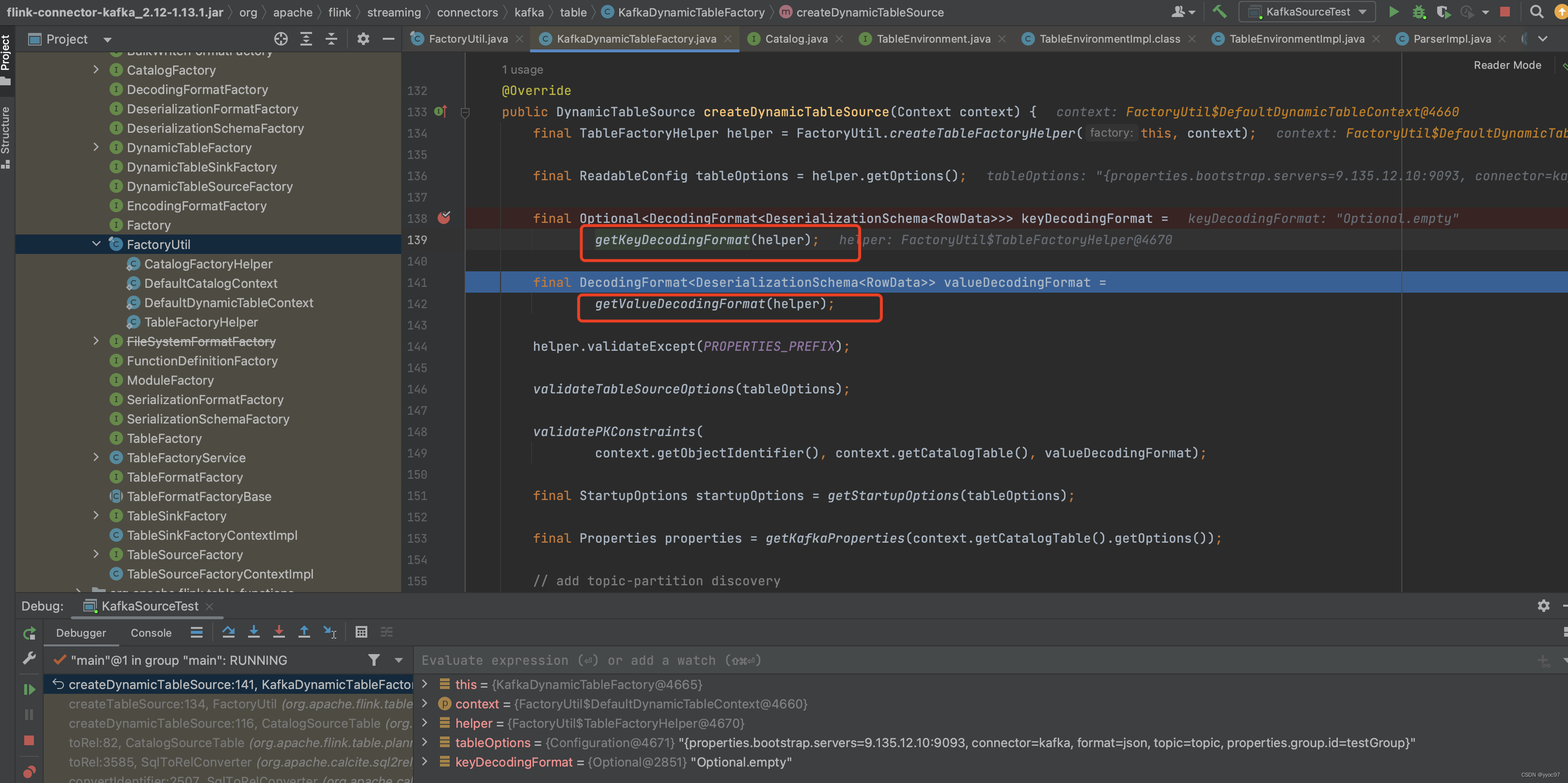
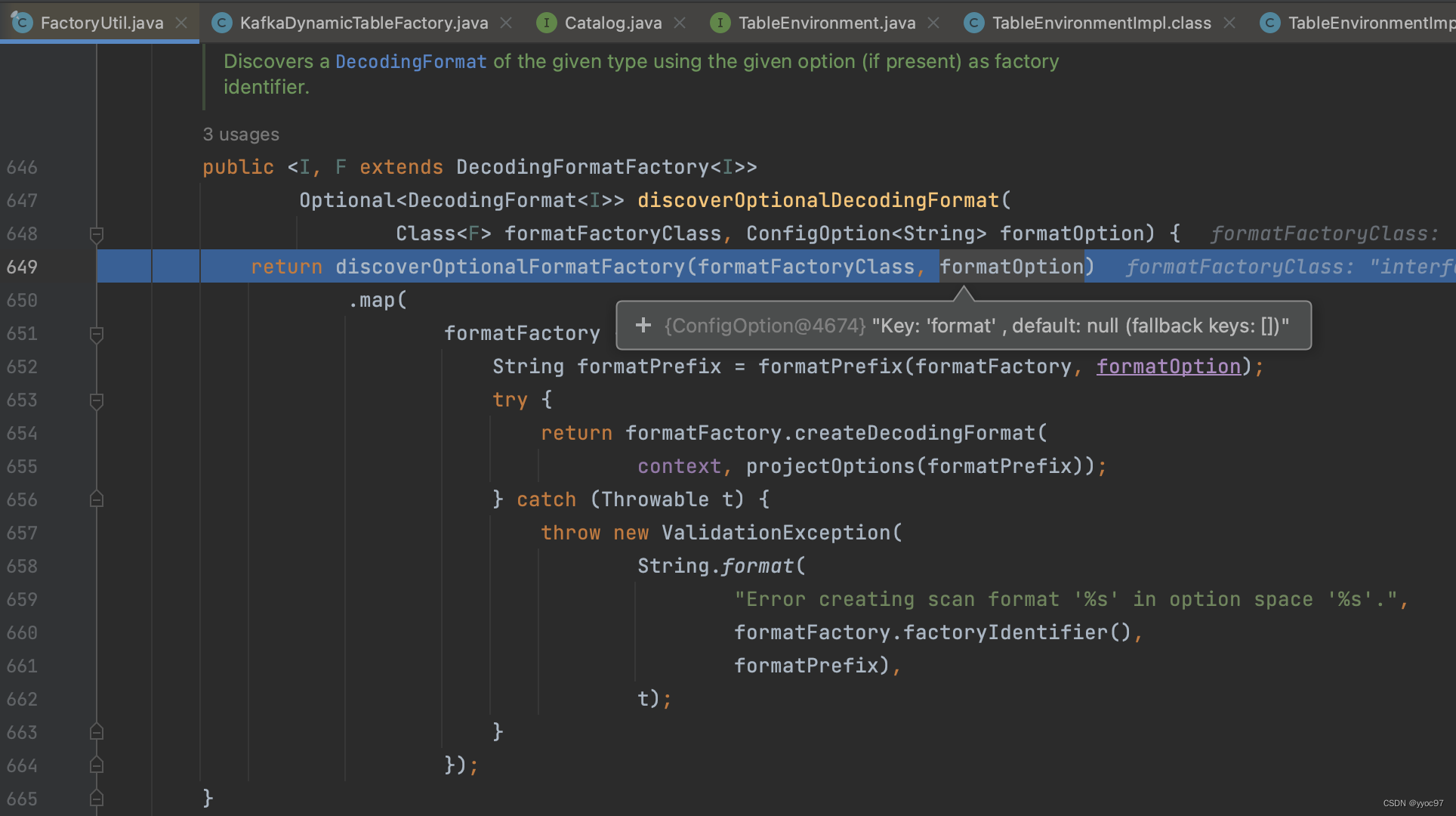
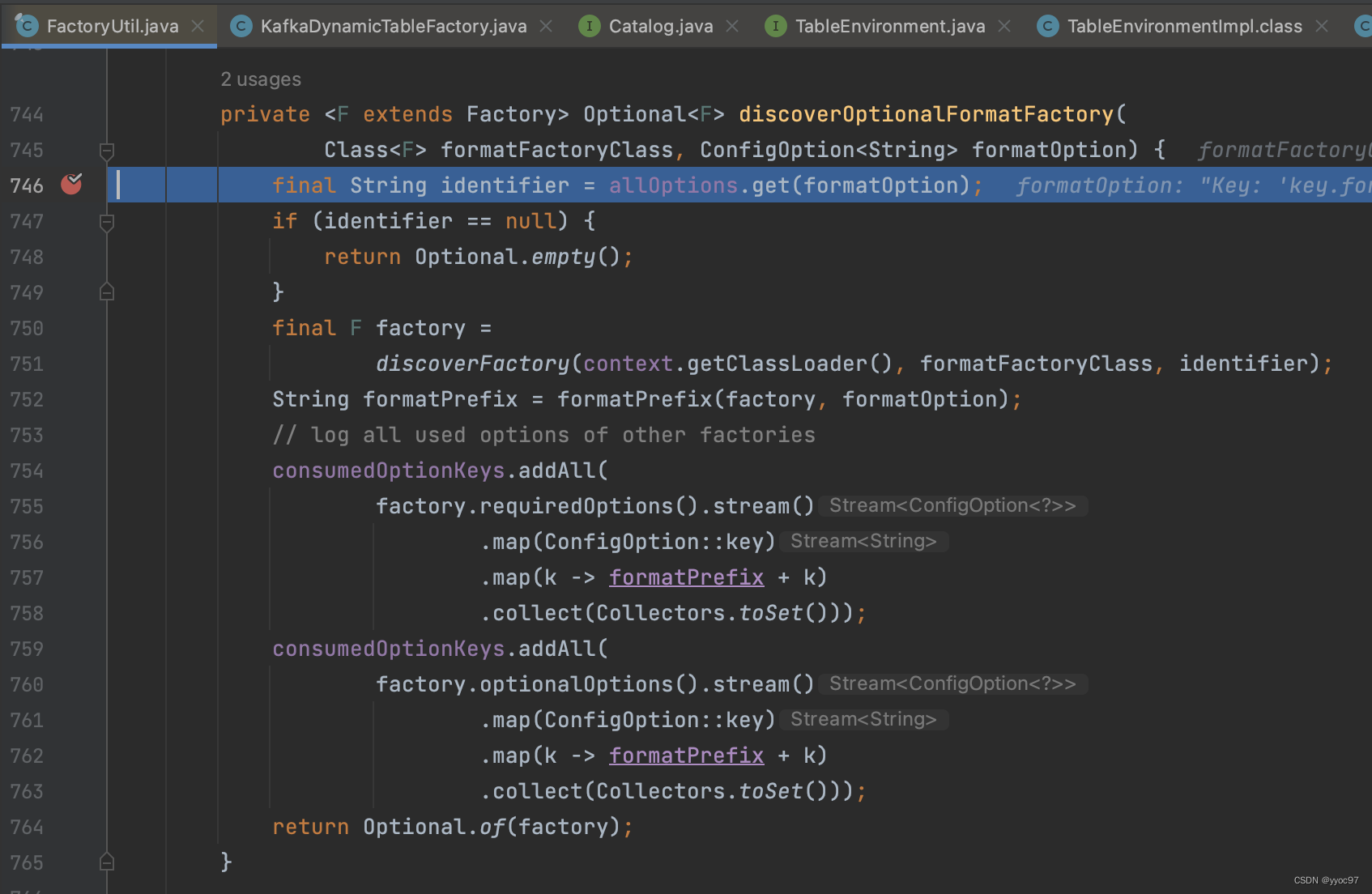
spi机制获取factory后,通过参数中的format=json过滤。
参考文献
https://developer.aliyun.com/article/765311
https://cloud.tencent.com/developer/article/1864657