- 论文链接:https://arxiv.org/abs/2203.08679

def dkd_loss(logits_student, logits_teacher, target, alpha, beta, temperature):
gt_mask = _get_gt_mask(logits_student, target) # 获取掩码
other_mask = _get_other_mask(logits_student, target)
pred_student = F.softmax(logits_student / temperature, dim=1) # 然后将学生和教师模型的输出通过softmax函数和温度参数进行缩放。
pred_teacher = F.softmax(logits_teacher / temperature, dim=1)
pred_student = cat_mask(pred_student, gt_mask, other_mask) # 接着,函数将通过之前获取到的两个掩码对学生和教师模型的输出进行切片,
pred_teacher = cat_mask(pred_teacher, gt_mask, other_mask) # 来获取属于真实标签以及不属于真实标签的模型预测结果。
log_pred_student = torch.log(pred_student) # 然后对学生模型中真实标签部分的输出取对数,
tckd_loss = ( # 并将其与教师模型的输出通过KL散度计算一种损失 tckd_loss。
F.kl_div(log_pred_student, pred_teacher, size_average=False)
* (temperature**2)
/ target.shape[0]
)
pred_teacher_part2 = F.softmax( # 接着将学生模型中不属于真实标签部分的输出取对数
logits_teacher / temperature - 1000.0 * gt_mask, dim=1 # ,并将其与教师模型获取的剩余输出通过KL散度计算另一种损失nckd_loss。
)
log_pred_student_part2 = F.log_softmax(
logits_student / temperature - 1000.0 * gt_mask, dim=1
)
nckd_loss = ( # 接着将学生模型中不属于真实标签部分的输出取对数,并将其与教师模型获取的剩余输出通过KL散度计算另一种损失nckd_loss。
F.kl_div(log_pred_student_part2, pred_teacher_part2, size_average=False)
* (temperature**2)
/ target.shape[0]
)
return alpha * tckd_loss + beta * nckd_loss # 最终将这两种损失按照权重加权求和作为总的DKD损失返回。def dkd_loss(logits_student, logits_teacher, target, alpha, beta, temperature):
定义这个函数来计算DKD的损失
需要传入 学生模型的 logits单元和老师的logits单元
知识蒸馏综述笔记_:)�东东要拼命的博客-CSDN博客
target 表示真实标签GT
alpha, beta 两个权重 表示两个知识正交 无关 互不影响
temperature 表示蒸馏温度
gt_mask = _get_gt_mask(logits_student, target) 获取标签为真实标签的掩码和标签不是真实标签的掩码 other_mask = _get_other_mask(logits_student, target)
pred_student = F.softmax(logits_student / temperature, dim=1) pred_teacher = F.softmax(logits_teacher / temperature, dim=1) 然后将学生和教师模型的输出通过softmax函数和温度参数进行缩放
pred_student = cat_mask(pred_student, gt_mask, other_mask) pred_teacher = cat_mask(pred_teacher, gt_mask, other_mask) 接着,函数将通过之前获取到的两个掩码对学生和教师模型的输出进行切片
这里应该理解起来有些困难 我去借个原文的图回来

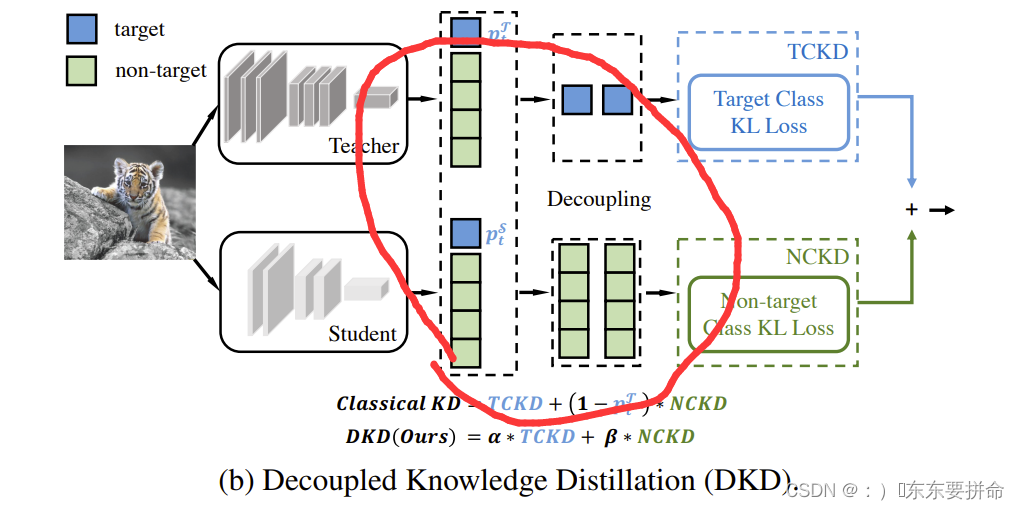
这个图很清晰了
函数是将pred_student和pred_teacher分别进行切片来获取属于真实标签以及不属于真实标签的部分。这里的切片是通过两个掩码来实现的,具体包含以下步骤:
- 首先,利用
_get_gt_mask和_get_other_mask两个帮助函数分别获取真实标签和非真实标签部分的掩码,掩码中元素的取值为0或1,1代表该类别属于真实标签;0代表该类别不属于真实标签。 - 然后,对于学生模型输出的概率分布
pred_student和教师模型输出的概率分布pred_teacher,将其按照对应的掩码进行切片,对于属于真实标签的部分,保留对应的概率,对于不属于真实标签的部分,以0填充。 - 最终得到的是两个经过切片处理的概率分布
pred_student和pred_teacher,其中分别包含了属于真实标签和不属于真实标签的部分。该方法可以减少真实标签以外的噪声对知识蒸馏效果的影响。
log_pred_student = torch.log(pred_student)
然后对学生模型中真实标签部分的输出取对数
# 并将其与教师模型的输出通过KL散度计算一种损失 tckd_loss。
tckd_loss = (
F.kl_div(log_pred_student, pred_teacher, size_average=False)
* (temperature**2)
/ target.shape[0]
)

其中F.kl_div计算的是log_pred_student(学生模型在真实标签上的预测分布取对数后得到的张量)和pred_teacher(教师模型在真实标签上的预测分布)之间的KL散度。
由于KL散度是没有单位的,所以为了方便理解和比较,一般会将其除以样本数目target.shape[0],这其实相当于计算平均KL散度。
为了进一步加强知识蒸馏的作用,我们还会乘以一个温度的平方temperature**2,这样做可以使预测结果更加平滑,并可以减轻分类器对于某些输出的过度自信。
其中 size_average=False 意味意味着 KL散度 函数不会对结果进行批次规范化,也就是不会除以批次大小。因此,输出结果是未经过规范化的,每个样本都有自己的损失值。在进行批次训练时,这些值可以被相加然后除以批次大小,以得到整个批次的平均损失。
pred_teacher_part2 = F.softmax(
logits_teacher / temperature - 1000.0 * gt_mask, dim=1
)
log_pred_student_part2 = F.log_softmax(
logits_student / temperature - 1000.0 * gt_mask, dim=1
)
这两个是为nckd服务的
nckd_loss = (
F.kl_div(log_pred_student_part2, pred_teacher_part2, size_average=False)
* (temperature**2)
/ target.shape[0]
)
这是一个对 logits_teacher 进行 softmax 函数的应用,除以一个温度常量并且减去一个大的负数值(通过与一个 ground truth mask 相乘得到)。
softmax 函数将 logits(未规范化的对数概率)转化为概率值,使它们相加等于1。
将 logits 除以温度常量可以控制结果分布的“软度”。
而 ground truth mask 是一个二进制掩码,对于目标 ground truth 标记值为1,对于所有其他标记值为0。
将其与一个大的负数值相乘可以将该标记的概率变为0,从而避免模型过度依赖真实标记,鼓励其探索其他可能性。该函数沿着第二个维度(通常是标记维度)应用。
def _get_gt_mask(logits, target):
target = target.reshape(-1)
mask = torch.zeros_like(logits).scatter_(1, target.unsqueeze(1), 1).bool()
return mask
此函数用于根据模型输出的逻辑值和目标标签生成一个掩码,
以获取与目标标签对应的类别的掩码。
这个函数首先将目标标签reshape为一维张量
(-1表示PyTorch将根据原始张量形状推断该维度的大小)。
接下来,它创建了一个与目标映射形状相同的零填充张量,
然后在沿第二维(即列)的位置上填充目标张量指示的位置,
并将1填充在这些位置上。
这是通过调用scatter_()方法来完成的,
其输入是要scatter的维度(在这种情况下为维度1),
位置索引(即目标值)和要scatter的值(即1)。
最后,它将生成的张量转换为布尔掩码以返回。
生成的掩码可用于各种目的,
例如仅选择与目标标签对应的逻辑值,以计算损失函数或计算给定批次输入的准确度等。
def _get_other_mask(logits, target):
target = target.reshape(-1)
mask = torch.ones_like(logits).scatter_(1, target.unsqueeze(1), 0).bool()
return mask
def cat_mask(t, mask1, mask2):
t1 = (t * mask1).sum(dim=1, keepdims=True)
t2 = (t * mask2).sum(1, keepdims=True)
rt = torch.cat([t1, t2], dim=1)
return rt
这是一个函数,需要输入三个张量,分别是 mask1、mask2 和 t。
其中,mask1 和 mask2 分别表示掩码,t 是待处理的张量。
这个函数实现了 t 和 mask1、mask2 之间的逐个元素相乘操作,
然后在第二个维度上对结果进行求和。
使用 keepdims=True 在结果张量中保留了该维度。
函数输出将两个求和结果沿着第二个维度拼接起来得到一个新的张量 rt,并返回。
这个函数可用于根据提供的掩码从 t 中提取某些特征。


![[洛谷-P2585][ZJOI2006]三色二叉树(树形DP+状态机DP)](https://img-blog.csdnimg.cn/img_convert/8ffc3433b3523f52cbf32fe0d6559e32.png)