文件IO
- 文件的常识
- 基础IO
- 为什么要学习操作系统的文件操作
- C语言对于函数接口的使用
- 接口函数介绍
- 如何理解文件
- 文件描述符
- 重定向
- 更新给模拟实现的shell增加重定向功能
- 为什么linux下一切皆文件?
- 缓冲区
- 为什么要有缓冲区
- 缓冲区对应的刷新策略
- 缓冲区的位置在哪里
文件的常识
1.空文件也要在磁盘占据空间
2.文件 = 内容 + 属性
3.文件操作 = 对内容 + 对属性
4.标定一个文件,必须使用文件路径 + 文件名(唯一性)
5.如果没有指明对应的文件路径,默认是在当前路径进行访问
6.当我们把fopen,fclose,fread,fwrite等接口写完之后,代码编译之后,形成二进制可执行程序之后,但是没运行,文件对应的操作有没有被执行呢?没有 —— 对文件操作的本质是进程对文件的操作。
7.一个文件如果没被打开,可以直接进行文件访问吗??不能!一个文件要被访问,就必须先被打开!(被打开的时候是用户调用端口,操作系统负责操控硬件,所以这个操作是用户进程和操作系统共同完成的)
8.磁盘的文件不是所有的都被打开,是一部分被打开,一部分关闭。
总结:文件操作的本质是进程和被打开文件之间的关系。
基础IO
为什么要学习操作系统的文件操作
语言中,C,C++,java,python,php都有文件操作的接口,可是每个接口都不一样。
但是文件是在磁盘中,磁盘是硬件,那么想访问文件就不能绕过操作系统,要使用操作系统提供的接口。
但是操作系统的接口是不会变的,语言层面的操作文件也是通过对操作系统的这些接口进行封装而已。
所以学习底层操作系统能让我们在以后学习其他语言上手更快。
C语言对于函数接口的使用
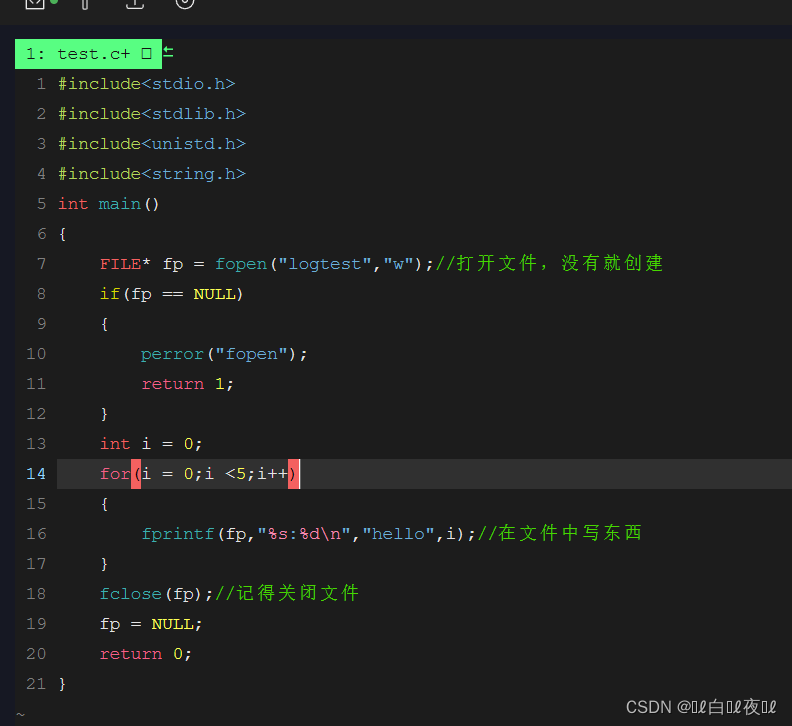
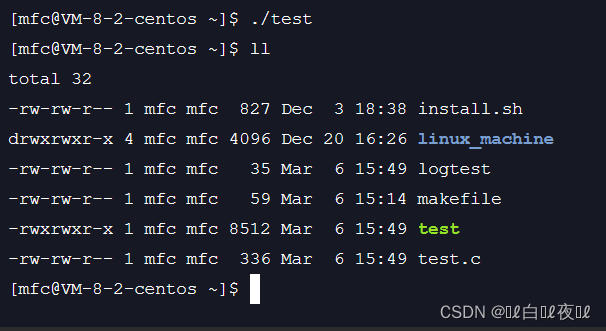
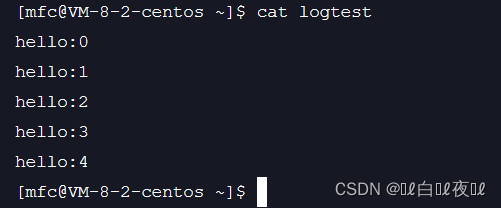
w打开只写文件,若文件存在则文件长度清为0,即该文件内容会消失。若文件不存在则建立该文件。
w+打开可读写文件,若文件存在则文件长度清为零,即该文件内容会消失。若文件不存在则建立该文件。
wb只写方式打开或新建一个二进制文件,只允许写数据。
wb+读写方式打开或建立一个二进制文件,允许读和写。
r打开只读文件,该文件必须存在,否则报错。
r+打开可读写的文件,该文件必须存在,否则报错。
rb+读写方式打开一个二进制文件,只允许读写数据。
a以附加的方式打开只写文件。
a+以附加方式打开可读写的文件。
ab+读写打开一个二进制文件,允许读或在文件末追加数据。加入b字符用来告诉函数库打开的文件为二进制文件,而非纯文字文件。
接口函数介绍
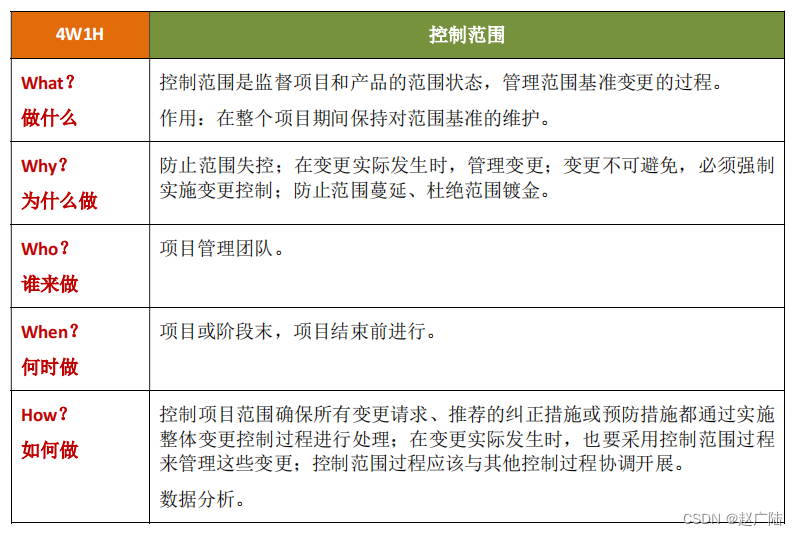
首先注意一个细节,文件的起始掩码是666,创建出文件是这样得出权限的:666 & ~numask。
先说第一个参数是包含路径的文件名(没有默认就是当前路径),第二个参数是你要进行什么操作,是一个C传标记为,靠比特位得到信息的参数,第三个参数是输入权限,起始文件的权限就是0666.。
正确返回值是文件描述符(其实就是一个小整数,下面会说明由来),错误是-1。
注意:在使用open时,如果不存在该文件,一定要注意第二个参数要传什么参数,第三个参数是必须要传的,不然就是错误文件。
这个函数可以传三个参数的原因就是为了处理不存在的文件。
这里先说一下C传标记位。
假如有八个比特位,每个比特位变成1,其他均为0,那么就有8种:

那么到时候就可以这样用:
#include<stdio.h>
#define ONE (1 << 0)
#define TWO (1 << 1)
#define FOUR (1 << 2)
#define EIGHT (1 << 3)
void print(int x)
{
if(x&ONE)
printf("ONE\n");
if(x&TWO)
printf("TWO\n");
if(x&FOUR)
printf("FOUR\n");
if(x&EIGHT)
printf("EIGHT\n");
}
int main()
{
print(ONE);//打印ONE
print(ONE|TWO);//打印ONE,TWO
print(ONE|TWO|FOUR)//打印ONE,TWO,FOUR
print(ONE|TWO|FOUR|EIGHT)//打印ONE,TWO,FOUR,EIGHT
return 0;
}
open函数的第二个参数也是同样的道理:
O_RDONLY: 只读打开
O_WRONLY: 只写打开
O_RDWR : 读,写打开
这三个常量,必须指定一个且只能指定一个
O_CREAT : 若文件不存在,则创建它。需要使用mode选项,来指明新文件的访问权限
O_APPEND: 追加写
O_TRUNC : 清空文件中的内容
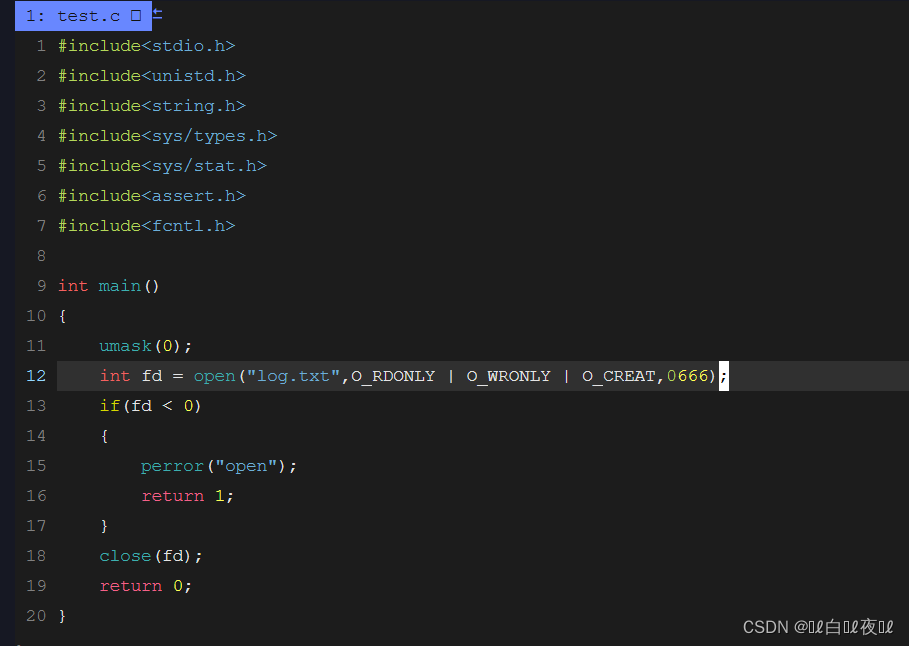
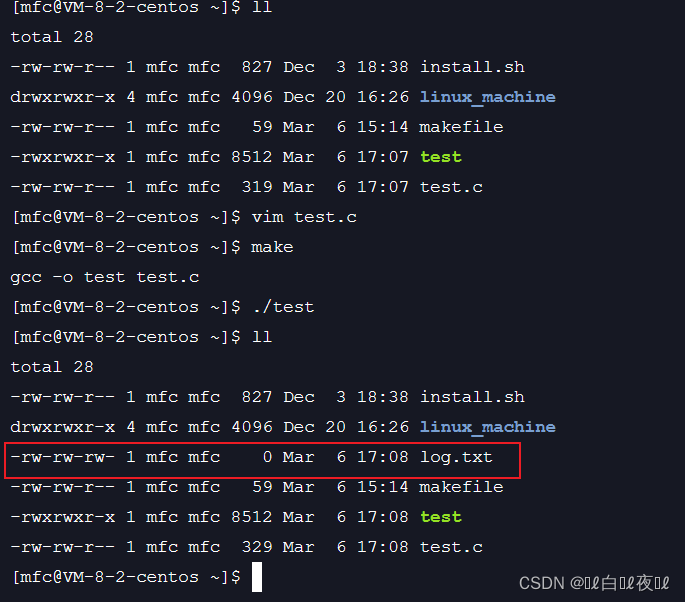
注意:这里只读和只写进行 | 操作只是为了没有对应文件去创建一个文件,如果这里既想实现读又想实现写的功能不能这样写,要用O_RDWR,因为只读和只写的特殊位都是一个位置,只不过是相反,也就是说总会有一个不起作用,下面写起了作用就代表读不会起作用。
这里就创建了一个文件,权限是对应666.
这里注意一下,umask设置的是当前进程的,跟shell的没关系。
这是系统写入函数:
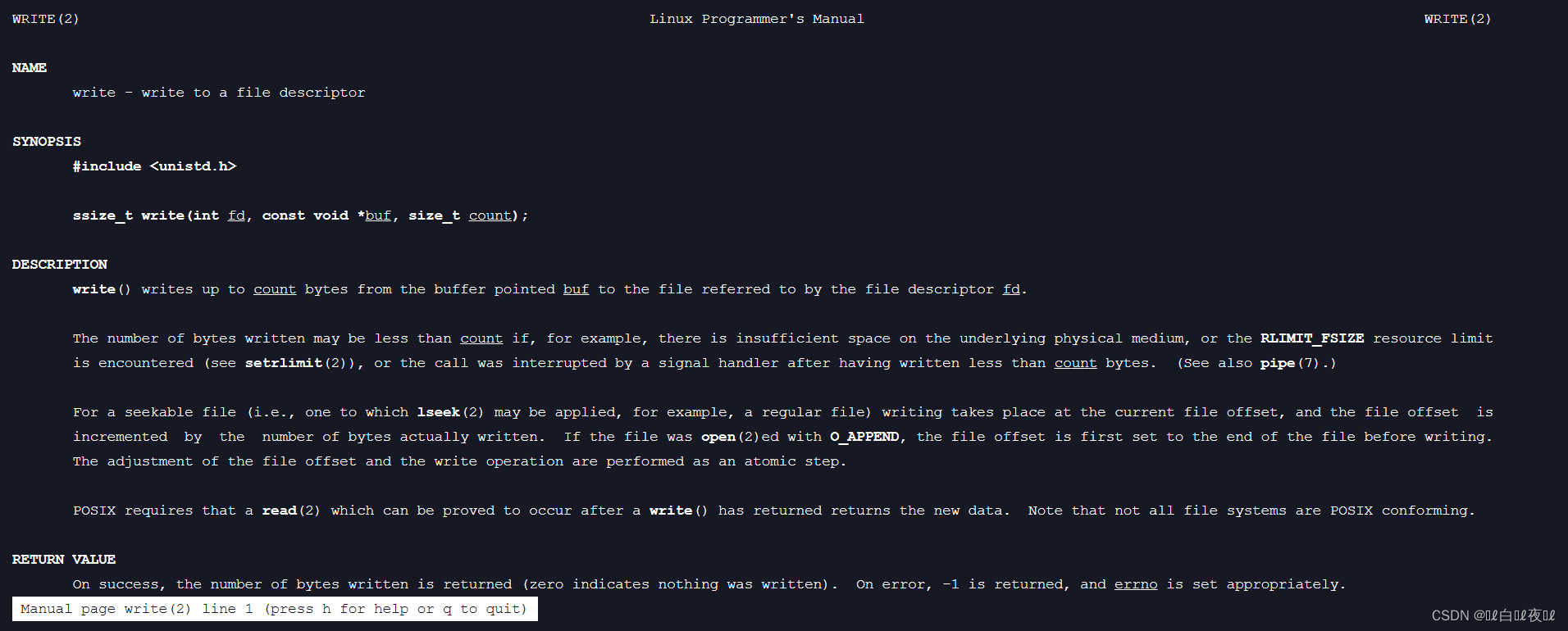
第一参数是你要写入的是文件描述符,第二参数是我们要写入缓冲区的位置,第三个是你要放进去的大小,返回值后面再说。
第二个参数是是void*,这是因为文本可以纯文本和二进制读取,但是在操作系统看来都是二进制,这个分类其实是语言给的分类。
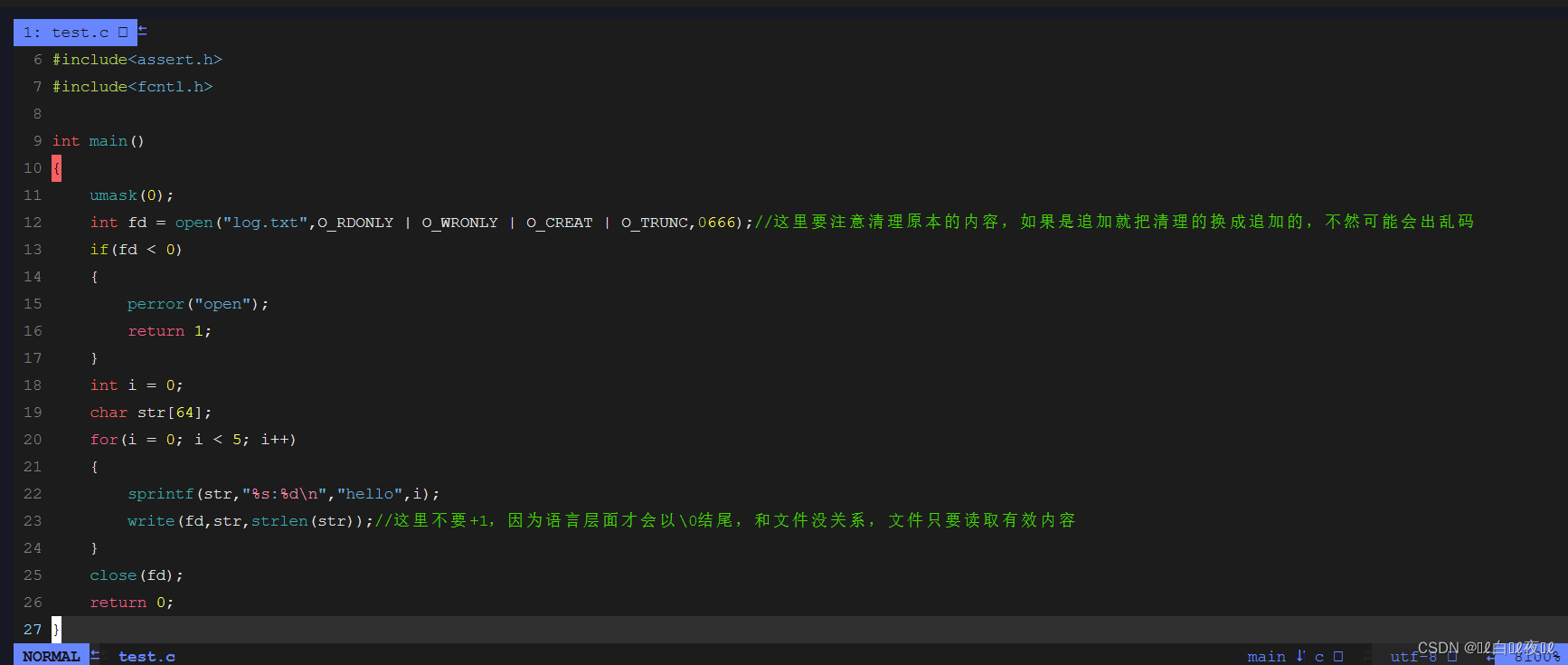
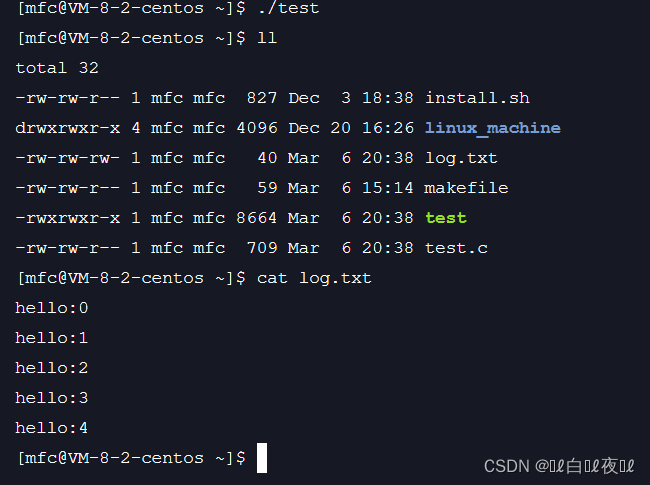
经过上面的举例其实就会发现C语言调用的fopen其实就是在传参给open上面的四个参数而已。
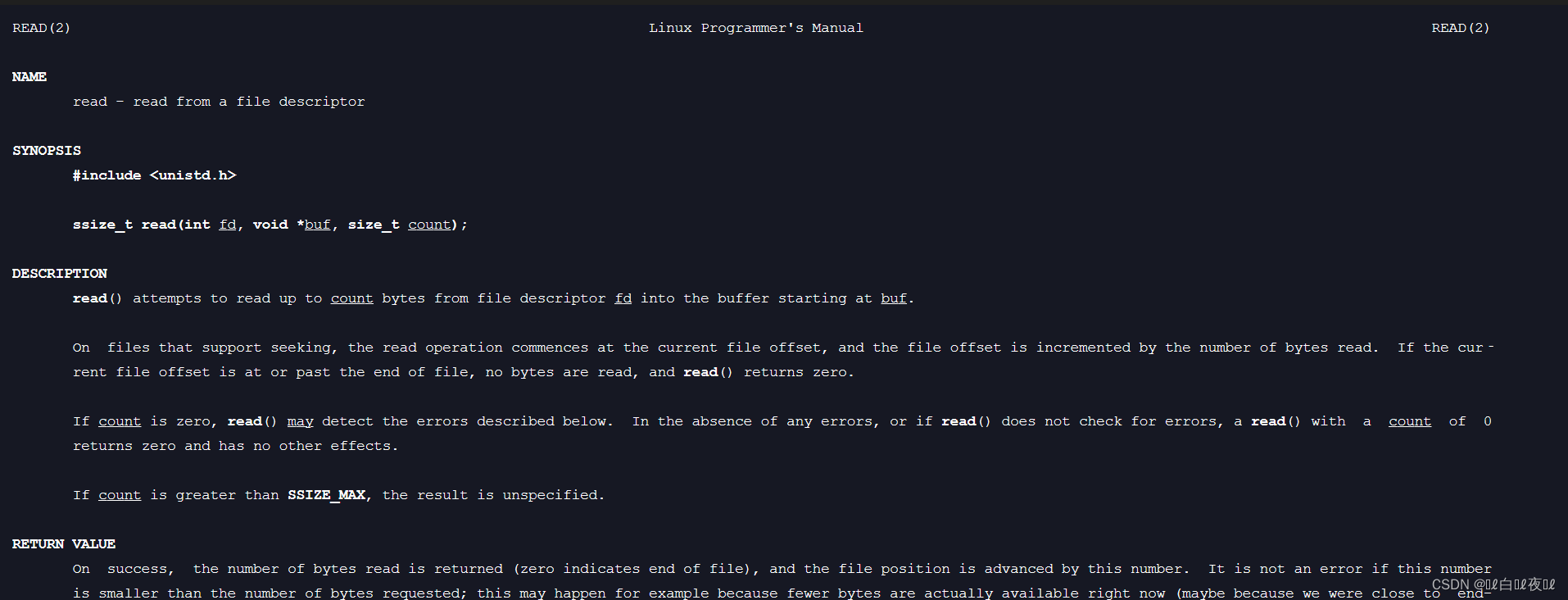
这是从文件中读取内容的函数.
第一个参数是文件描述符,第二个参数是从特定文件读取内容到缓冲区,第三个参数是读取多少个,实际上输入的500,如果缓冲区只有50,那么它只会读取50。
第二个参数也是void*,也是没有类型概念的。
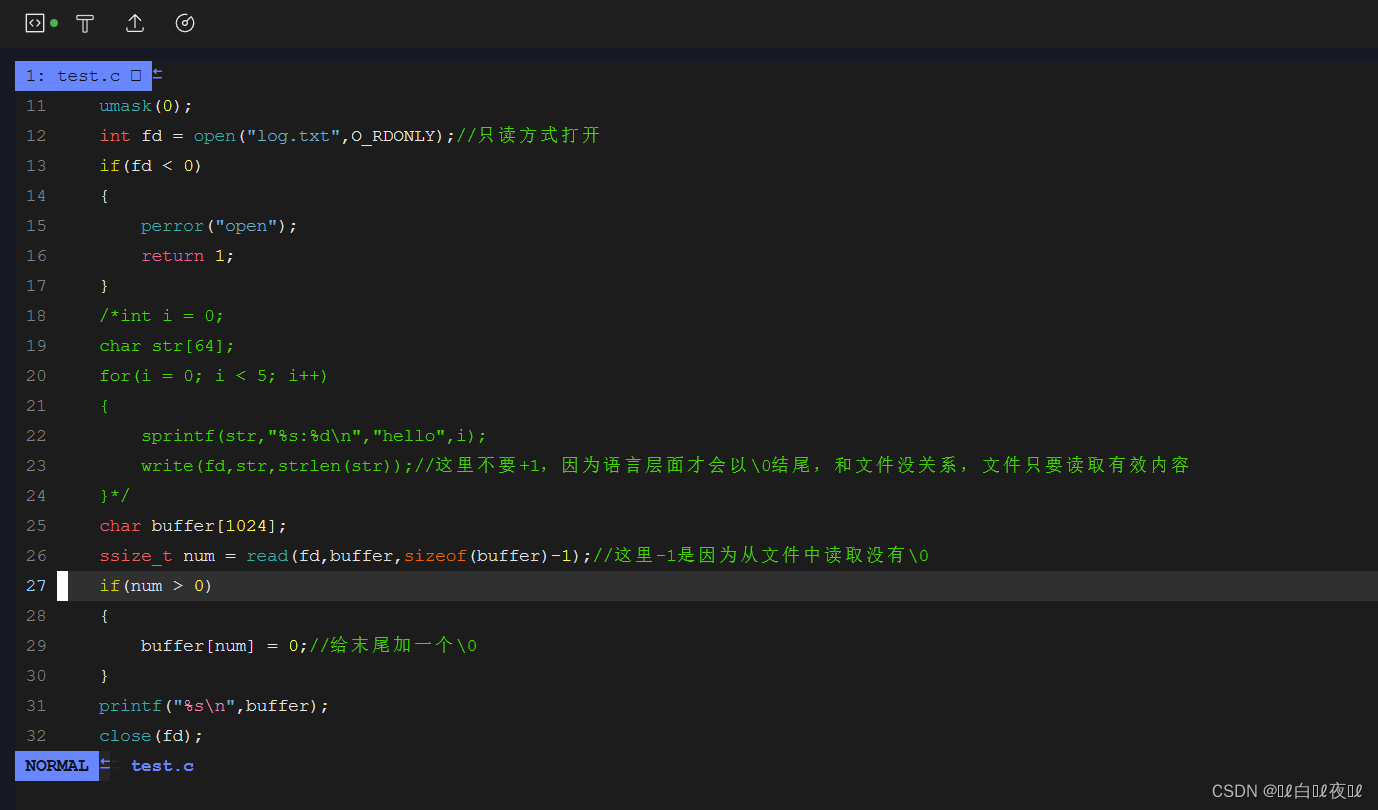
如何理解文件
文件操作的本质:进程和被打开文件的关系。
首先进程是可以打开多个文件的,系统中一定会有大量被打开的文件,那么如何管理这些文件呢?其实就像管理进程一样,先描述,再组织,先来看这一段代码:
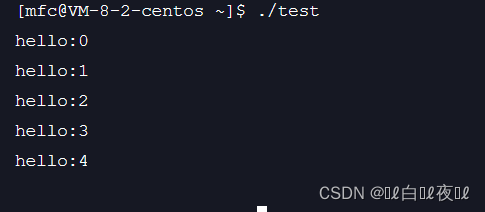
这里发现文件是有顺序的,那么为什么不像数组一样从0开始呢?
因为有三个标准输出流的存在:
stdin ——>键盘
stdout ——>显示器
stderr ——>显示器
这三个就是排在前面顺序的!
并且,C语言的FILE指针是一个结构体,因为在系统层面只认识文件描述符,所以里面必定有一个字段是文件描述符。
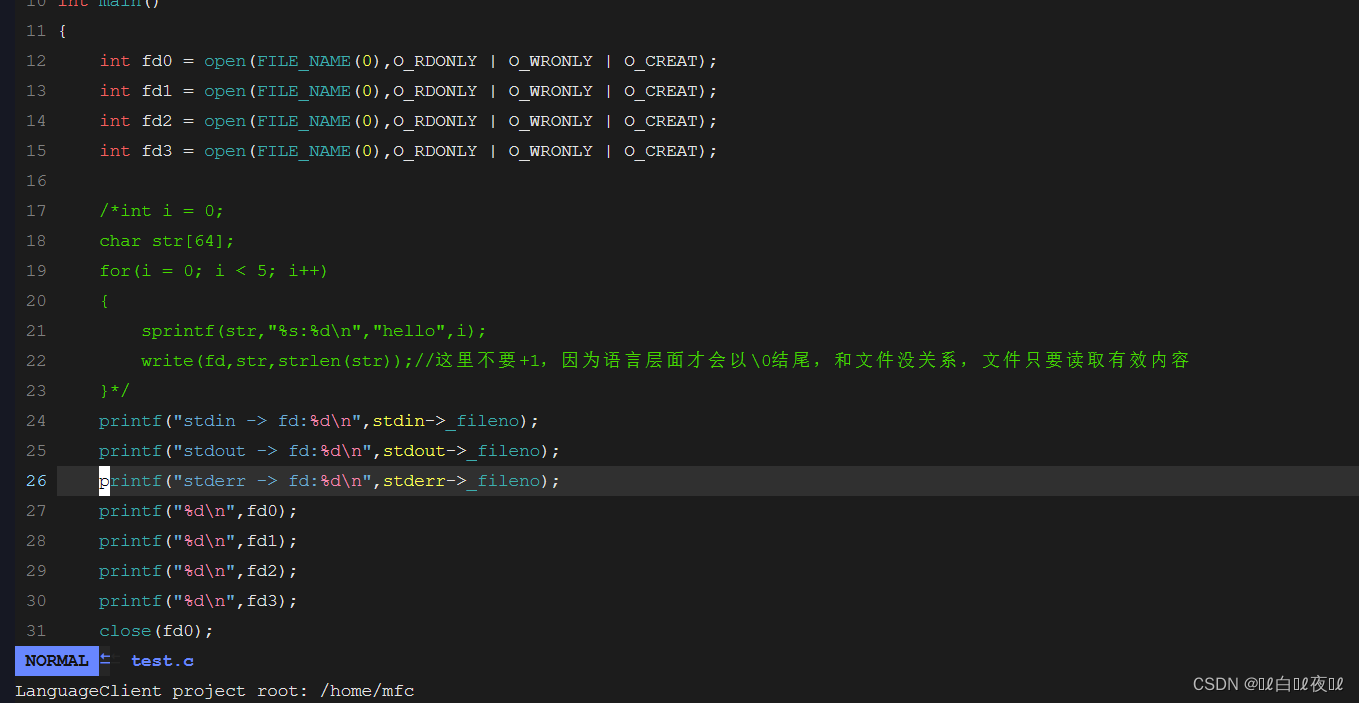
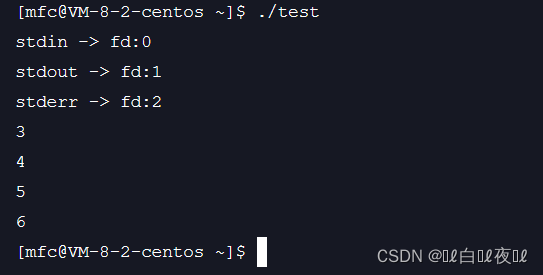
所以是从0开始的,但是前三个被占用了。
那么数字为什么是从0开始的呢?
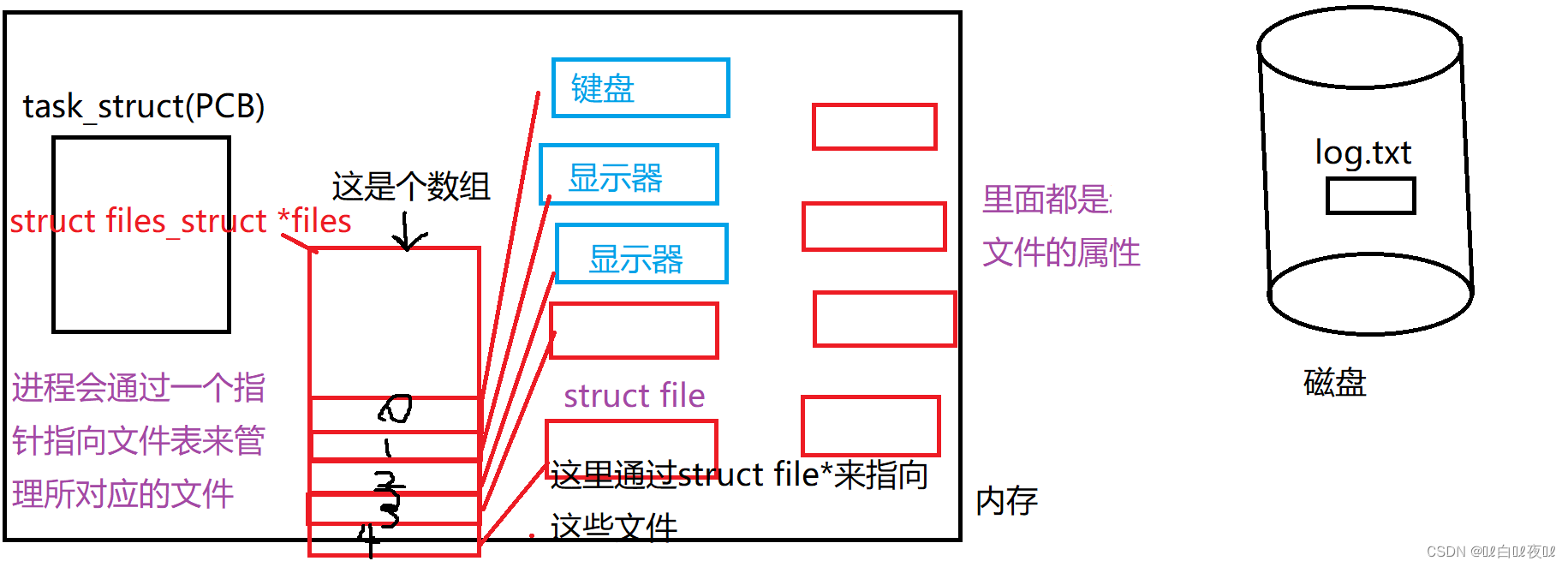
磁盘中被进程打开到内存中然后是通过struct file这个类型来描述放到内存中,然后进程的PCB中里面有一个struct file_struct *files这个指针指向一个struct file*array[]的数组来管理这些文件。
总结:文件描述的本质就是数组的下标!
文件描述符
重定向
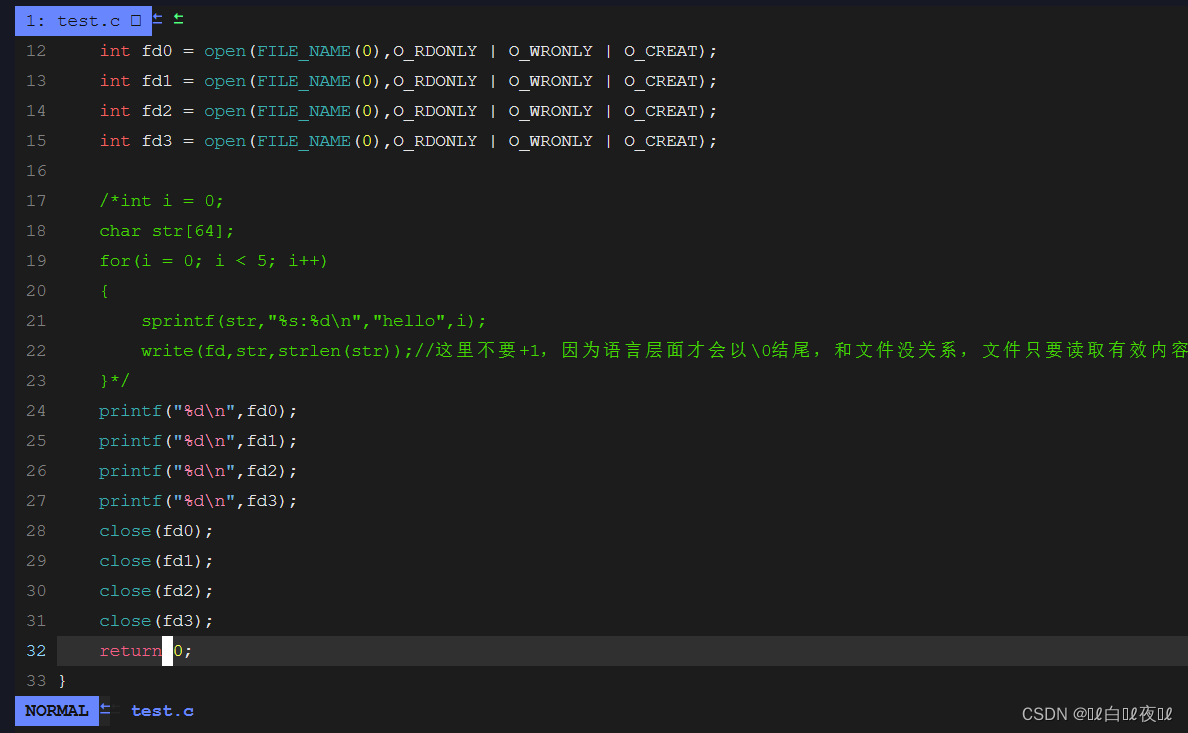
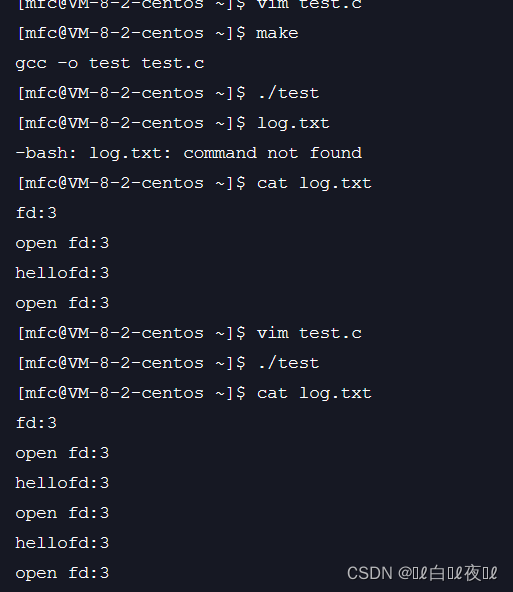
上面我们知道了0,1,2都被占用了,那么是否能够将我们的文件fd变成0,1,2呢
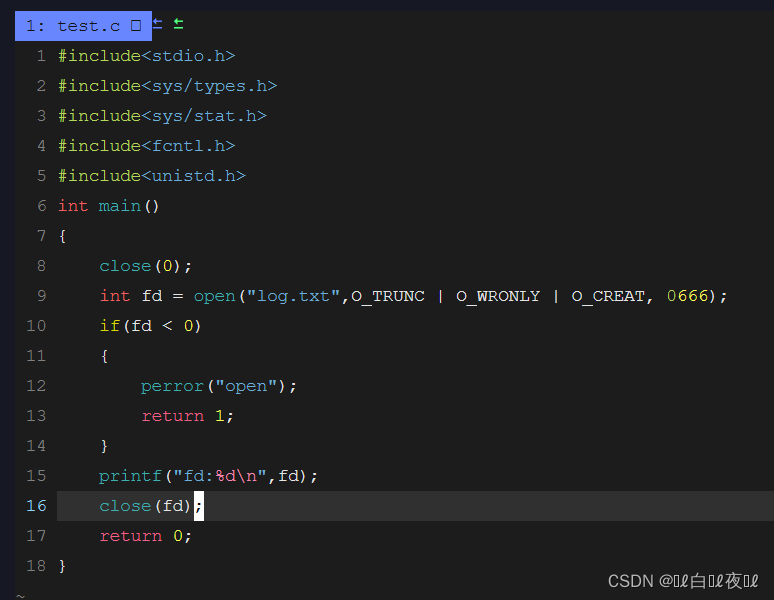
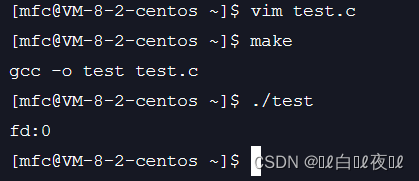
这样是可以的,也就是说,fd的分配规则是从0开始,一个新文件要打开的时候会先去扫面当前进程中的文件表,找到一个最小的没有被使用的文件描述符。
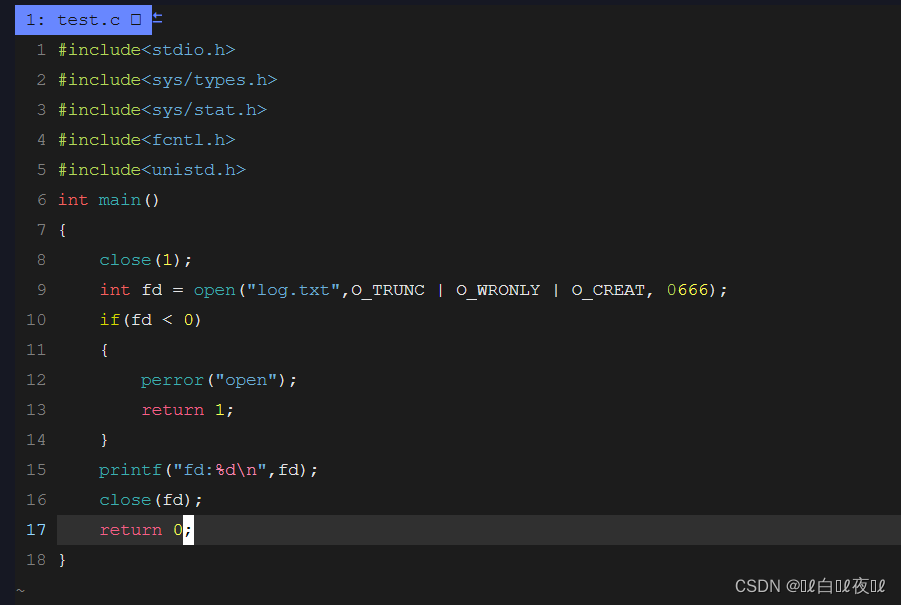
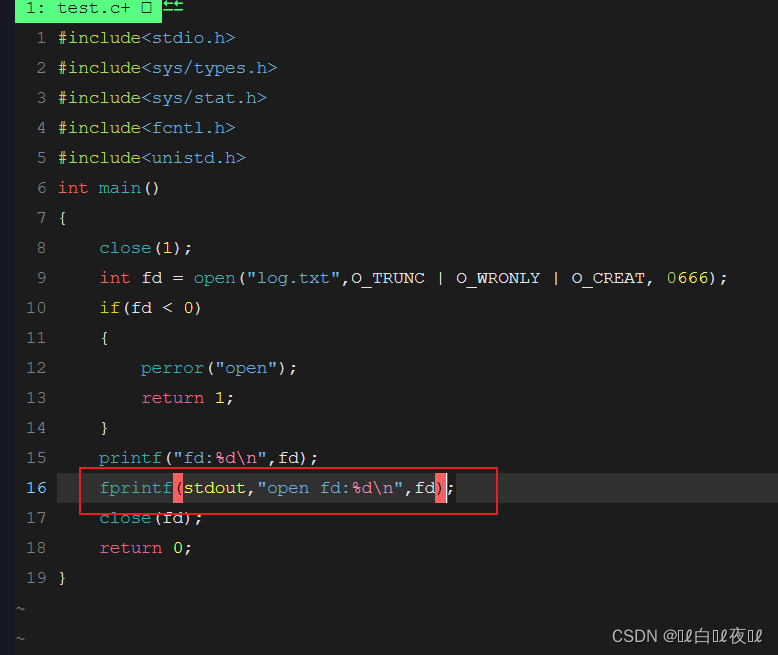
这里我们把1关闭试试:
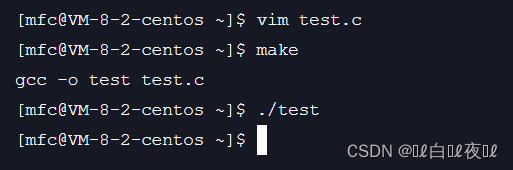
什么都没有打印出来,这是因为1是标准输入,但是就算那一行关闭了最后也打开了,为什么没有打印出来呢?
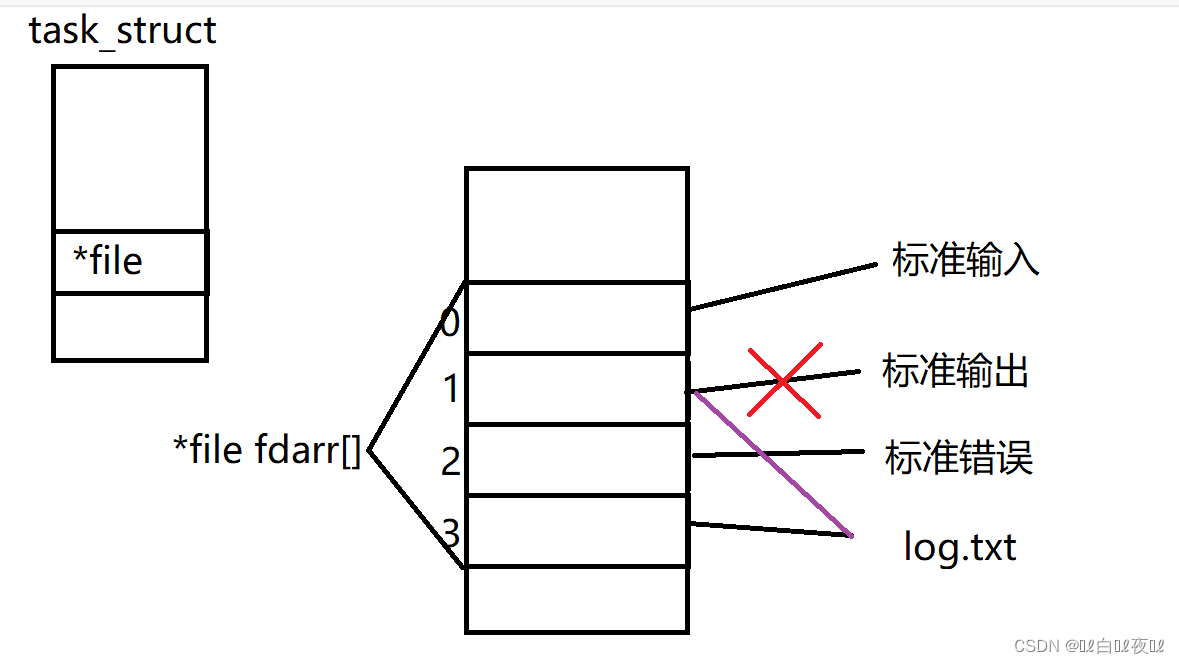
这是因为,1的位置里面已经是log.txt文件的地址了,所以到最后都没有打印出来。
那么,也就是说只要是让输入的输入到stdout中是不是就可以打印出来结果了呢?
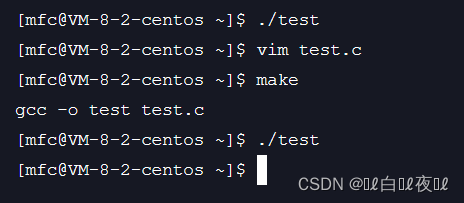
这里依然什么都没有,这时因为stdout其实就是文件表中1的位置,但是这里1的位置已经换成了log.txt,那么是不是说明会将我们要打印到屏幕上的内容变成打印到log.txt文件的内容呢?

这里什么都没有,但是确实是这样的,只不过是缓冲区的问题,这里我们强制刷新一下:
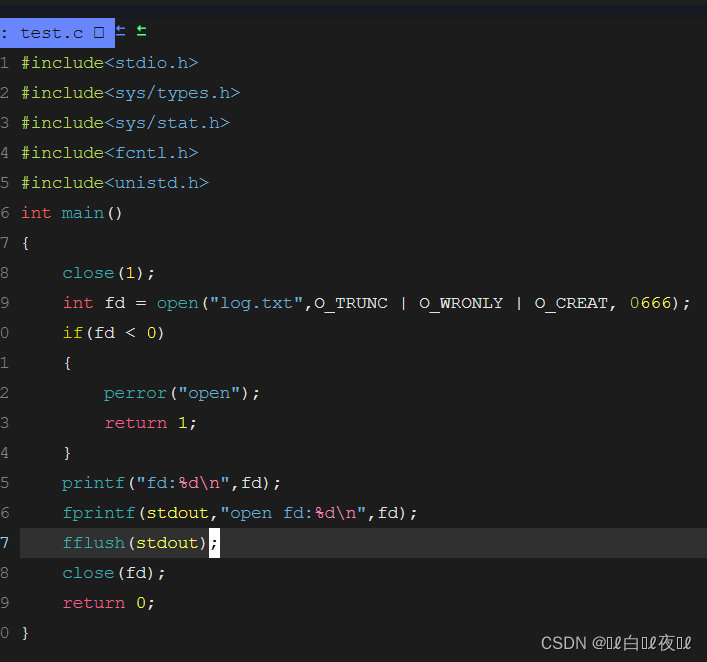
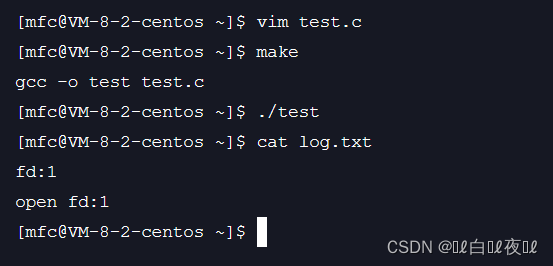
本来应该往显示器里打印的内容却打印到了文件里,这个特性就叫做重定向。
> 输出重定向
>>追加重定向
<输入重定向
重定向的本质就是,上层fd不变,在内核中更改fd对应的struct file*的地址。
但是像刚才举例,关闭对应的文件然后再进行写入,这种重定向的方式太搓,有一个函数是重定向用的:
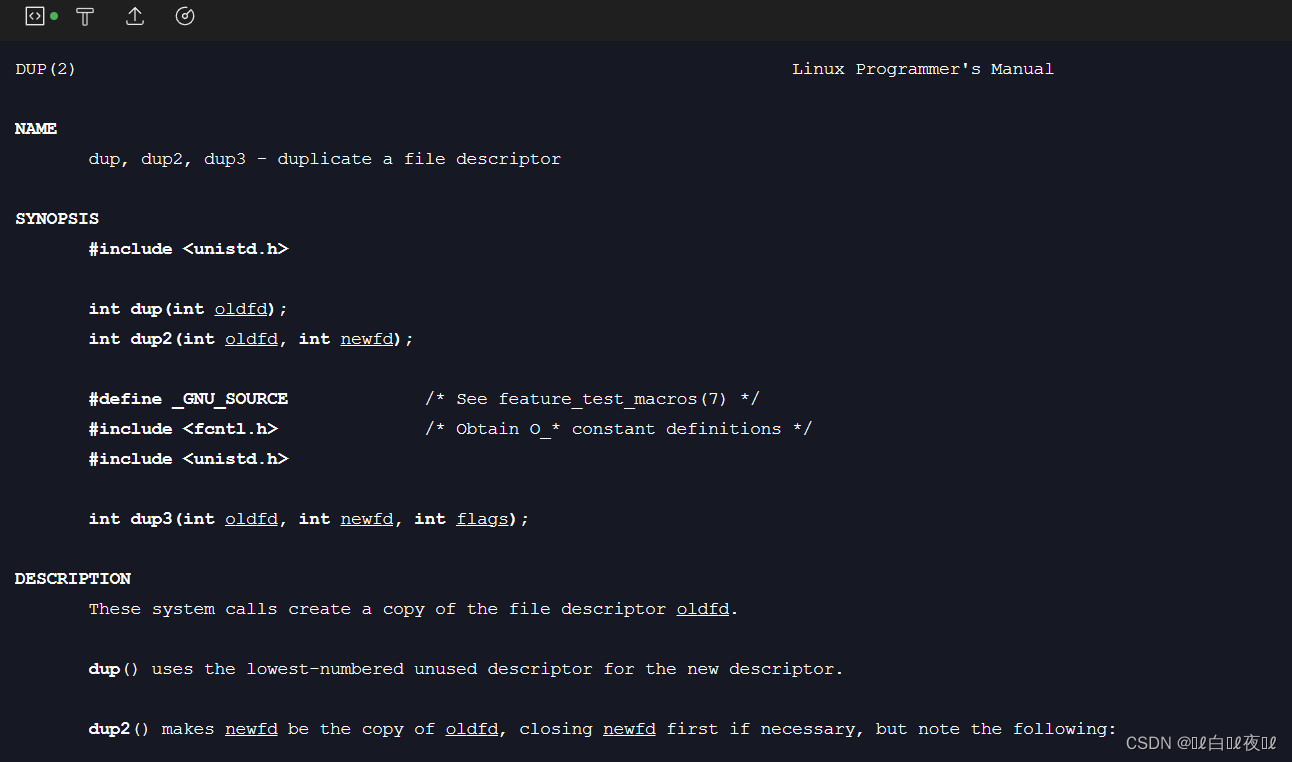
看dup2,两个参数就是文件表的下标,也就是fd,这个函数是把文件表内的两个内容拷贝。
注意,拷贝是覆盖,也就是说最后只能由一个内容!
第一个参数你你要写的内容,第二个参数是你要写的位置。
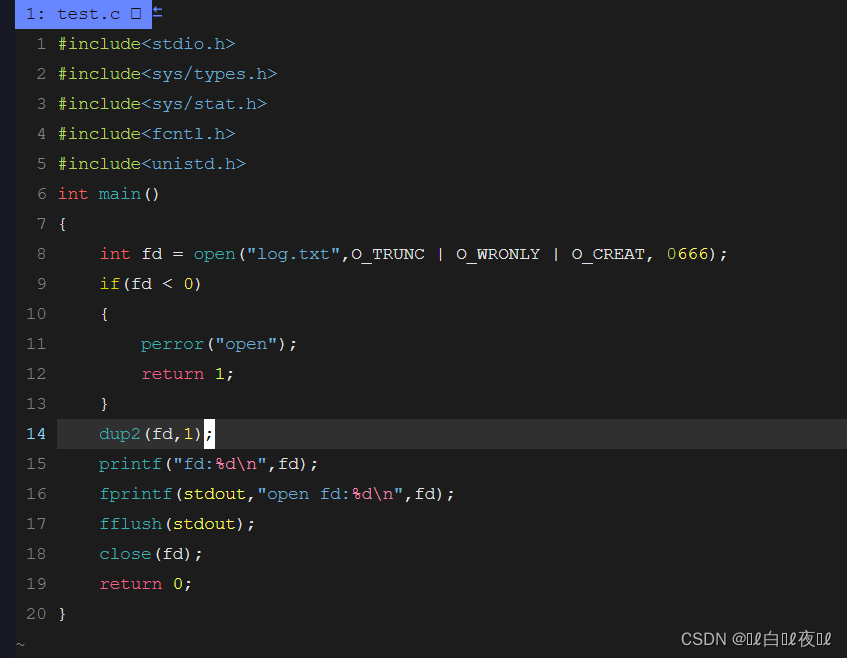
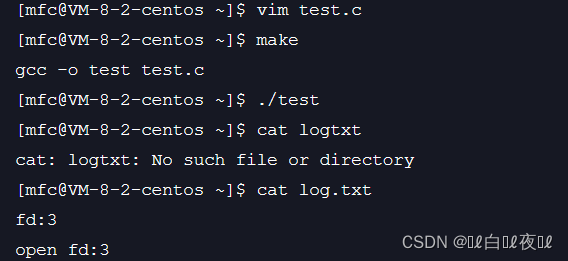
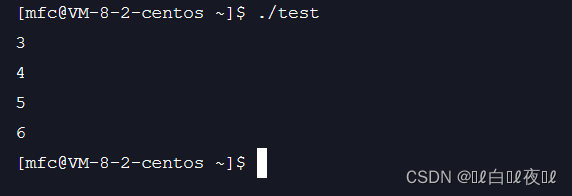
这里fd就是3了,因为是将fd的内容拷贝到1中,所以0,1,2的位置还是有内容的,fd分到的还是3。
同时我们想在屏幕上打印也不可以了,因为1也指向了fd指向的文件。
如果想要追加内容,那么打开文件的时候第二个参数记的变换。
更新给模拟实现的shell增加重定向功能
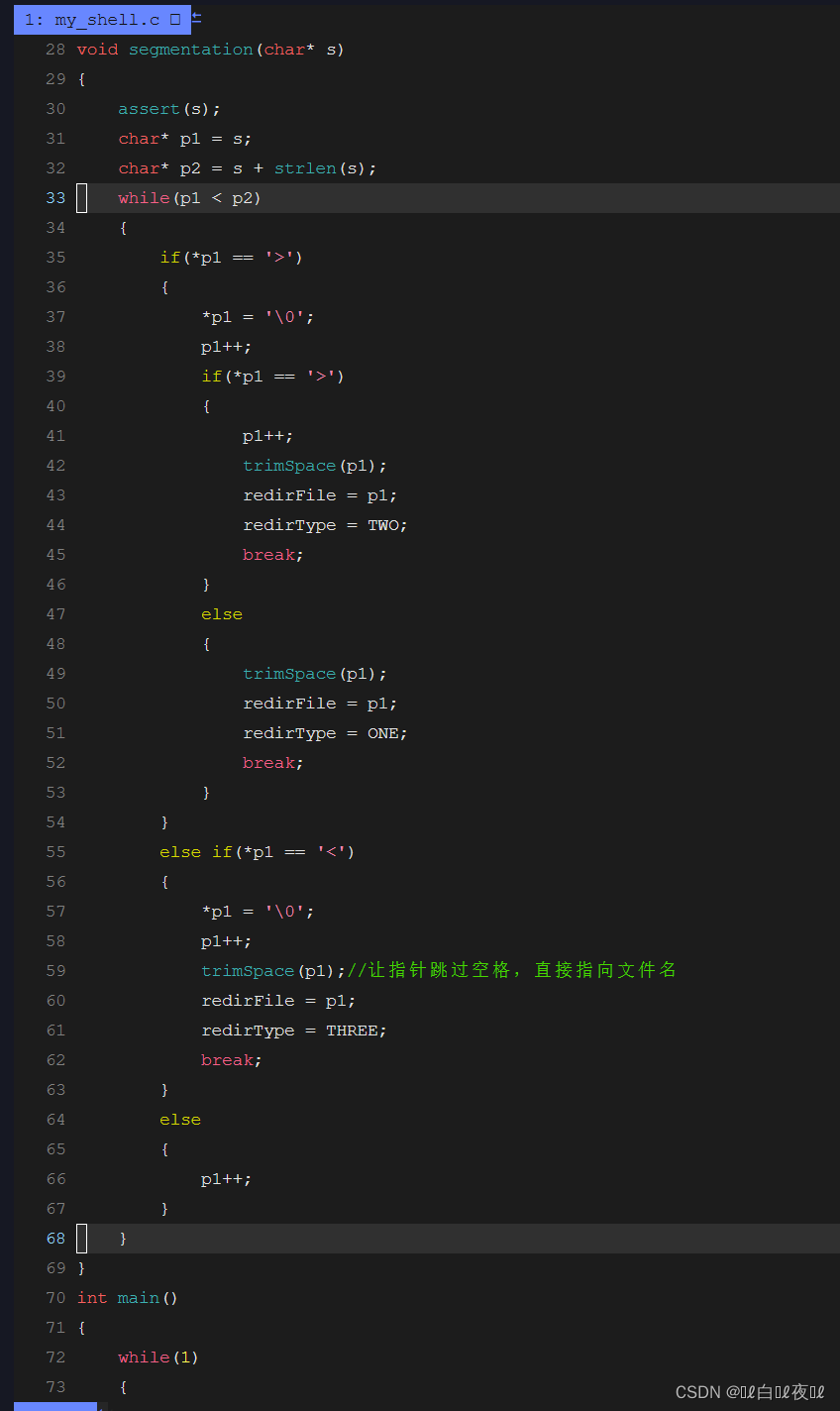
重定向是让fd中的内容进行改变,所以在执行命令之前,要先分割命令的时候,分成两个部分,从">“,”>>“,”<“中开始分割。
前面的还是按照原来的程序执行,后面的去处理重定向内容,那么怎么进行分割呢?我们可以将.”>“,”>>“,”<",变成\0。
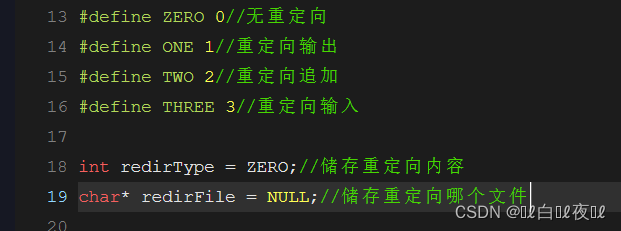
重定向先设置四个宏,分别代表,目前没有重定向,>,>>,<.
在设置两个全局变量,一个是说明什么类型的重定向,另一个是重定向的文件是哪个。
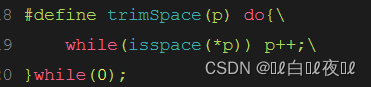
这个宏是跳过字符串空格的意思。
这个就是函数就是分割了命令串,是否是重定向,怎么重定向,文件是哪一个。
然后就是进行重定向了,首先要清楚,因为命令都是通过子进程去完成的,所以重定向也是通过子进程去完成的。
那么,为什么子进程操作不影响父进程的呢?
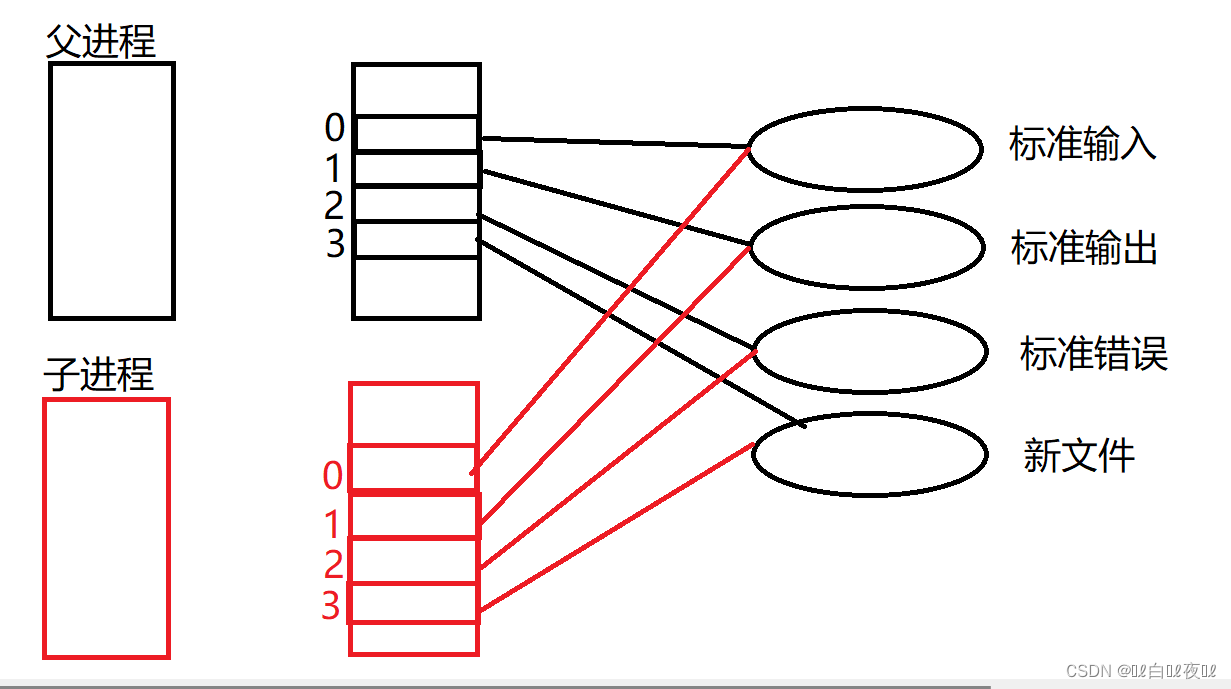
首先,进程拥有独立性,文件表也会拷贝父进程一份,但是文件是不会被拷贝的,也就是说子进程重定向是更改子进程的文件表,并不会影响父进程的。
并且,程序替换的时候也不会影响重定向打开的文件,因为程序替换替换的是程序的代码,而内存中的PCB,文件表,文件,都属于内核数据结构,就像进程的替换不会影响PCB内容的变化,也不会影响pid,ppid一样。
这样就完成了。
为什么linux下一切皆文件?
比如一些硬件,他们有自己的内核数据结构,他们每个都有自己的读写方法(键盘没有写功能,那就指向空),每种硬件读写方式都是不同的。
那么既然是不同的数据结构,怎么进行管理呢?
这时候就会定义一个结构体,里面记录硬件的数据,也能调用对应硬件的读写接口。

file是链接起来的,先描述,再组织。
所以操作系统看来,只需要调用file就可以了,所以说linux下皆文件。
那么,上面说到重定向的时候,为什么我们子进程退出时关闭了一个文件,按理来说父进程也会关闭文件,但是并没有,因为有一个叫做引用计数:
在结构体中有一个专门计数有多少个指针指向这个位置,如果这个数为0,文件就会关闭,如果不为0,即便是子进程关闭文件也就等于这个数减一而已。
因为用户要关闭文件和打开文件,只是我们去告诉操作系统我们要这么去做而已,剩下的就让操作系统实现具体内容。
缓冲区
首先来看一段代码:
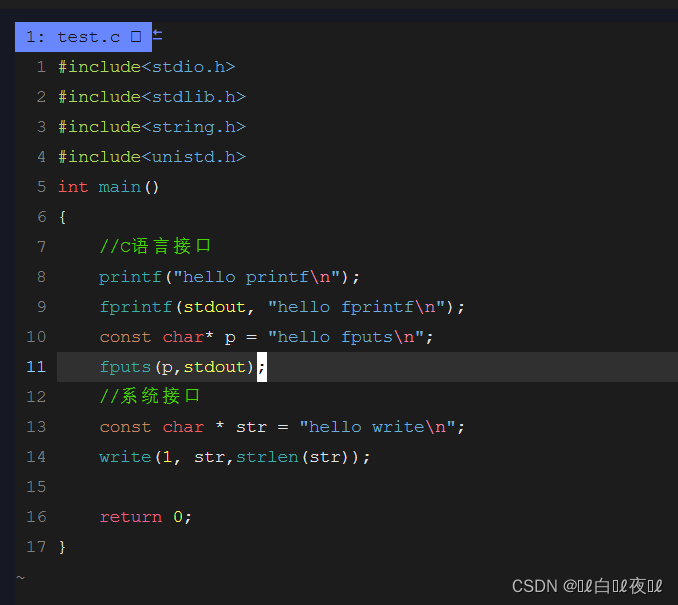
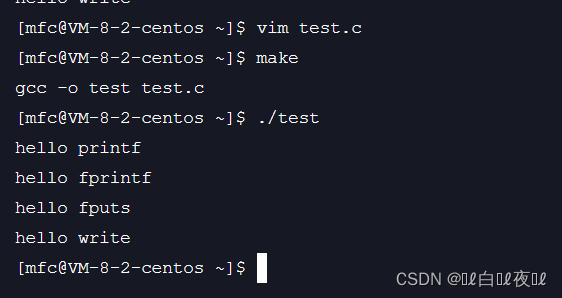
打印正常
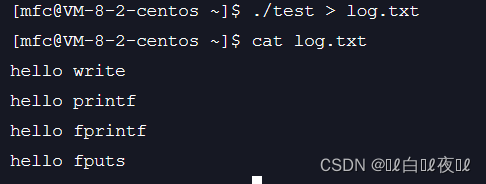
重定向正常
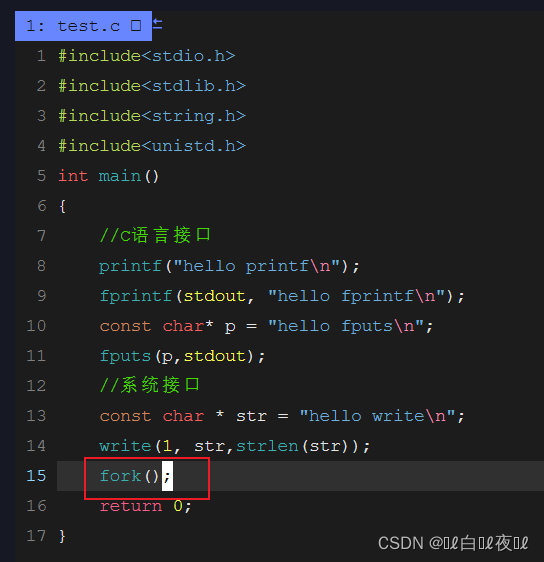
这时我加了一个fork创建子进程。
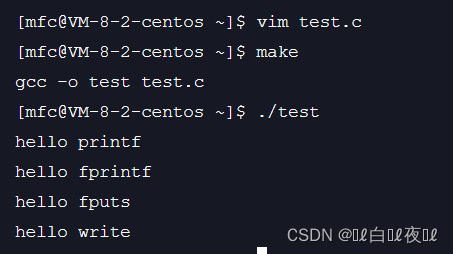
打印正常
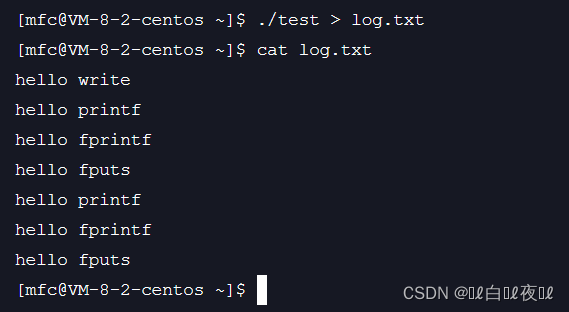
这个内容是意料之外的。
为什么要有缓冲区
举个例子,我们古代如果普通人想给别人送东西,可能就需要自己一个人去送,费时费力,但是现代有快递站,所以就不用自己人力送了。
在内存中进程也是一样的,需要与外设有接触,但是外设的I/O特别慢,这时缓冲区就可以帮我们快速的与外设传递数据了。
缓冲区的本质就是一段内存!

缓冲区对应的刷新策略
缓冲区刷新也不是随意的刷新,而是根据外设去决定怎样去刷新的。
1.立即刷新,其实就和无缓冲一样。
2.行刷新,行缓存,这个就是相对应显示器,主要是针对人类做使用的,因为我们平时看文字都是一行一行从左到右去读,所以他就是一行一行刷新的,
3.缓冲区满,全缓冲,磁盘文件就是这样的,这个效率也是最快的,因为从进程中拷贝数据到传给外设,一次假设需要10s。
那么0.1s是在从进程拷贝数据到缓冲区,剩下时间就是缓冲区刷新到外设中的时间,也就是说如果进行多次的缓冲刷新,效率不如一次性缓冲刷新。
除了上面的策略,还有两种特殊的情况:
1.用户强制刷新
2.进程退出 ——— 一般都要进行缓冲区刷新
缓冲区的位置在哪里
我们在C语言的时候就一直再说缓冲区,那么它到底在什么位置呢?
刚才打印的代码说明,不在linux内核中,要不然wirte也会被打印两次。
其实我们所说的缓冲区是语言层次的缓冲区!因为在操作系统看来他也只是一块内存而已!
在stdout,stdin,stderr中,因为任何文件中都要去调用这三个,这三个的类型是FILE*,FILE也是一个结构体,里面不仅仅有fd,也有缓冲区!
这就是为什么刷新缓冲区的函数要传入文件指针,因为里面有缓冲区!
Linux中的FILE结构体:
在/usr/include/libio.h
struct _IO_FILE {
int _flags; /* High-order word is _IO_MAGIC; rest is flags. */
#define _IO_file_flags _flags
//缓冲区相关
/* The following pointers correspond to the C++ streambuf protocol. */
/* Note: Tk uses the _IO_read_ptr and _IO_read_end fields directly. */
char* _IO_read_ptr; /* Current read pointer */
char* _IO_read_end; /* End of get area. */
char* _IO_read_base; /* Start of putback+get area. */
char* _IO_write_base; /* Start of put area. */
char* _IO_write_ptr; /* Current put pointer. */
char* _IO_write_end; /* End of put area. */
char* _IO_buf_base; /* Start of reserve area. */
char* _IO_buf_end; /* End of reserve area. */
/* The following fields are used to support backing up and undo. */
char *_IO_save_base; /* Pointer to start of non-current get area. */
char *_IO_backup_base; /* Pointer to first valid character of backup area */
char *_IO_save_end; /* Pointer to end of non-current get area. */
struct _IO_marker *_markers;
struct _IO_FILE *_chain;
int _fileno; //封装的文件描述符
#if 0
int _blksize;
#else
int _flags2;
#endif
_IO_off_t _old_offset; /* This used to be _offset but it's too small. */
#define __HAVE_COLUMN /* temporary */
/* 1+column number of pbase(); 0 is unknown. */
unsigned short _cur_column;
signed char _vtable_offset;
char _shortbuf[1];
/* char* _save_gptr; char* _save_egptr; */
_IO_lock_t *_lock;
#ifdef _IO_USE_OLD_IO_FILE
};
所以说,我们再用文件指针的时候,输入的那些内容都会被封装到对应的文件指针那里,C语言会在合适的时候去刷新这个缓冲区。
那么上面的代码现在也可以进行解释为什么会出现奇怪的内容了。
首先要知道:没用重定向之前,stdout默认使用的是行刷新,在进程fork()之前,三条C函数已经将数据进行打印到显示器上了,这个时候我们的进程内部和FILE内部就没有数据了。
那么:使用重定向之后,写入文件的不是显示器,而是文件,所以就变成全缓存,之前的三天C函数虽然结尾有\n,但是没有写满stdout。
最重要的来了:执行fork的时候,原来的stdout是属于父进程的一部分,然后创建之后整个程序就退出了,之前说过刷新缓冲区的特殊条件,进程退出,并且,刷新缓冲区的时候等于将缓冲区的数据给对应的外设,所以就属于修改内容,那么子进程和父进程只读的时候是不会进行写时拷贝的,但是这里就要谁先退出谁就进行写时拷贝!所以C语言函数的接口就会打印两次!
那么wirte为什么只打印了一次呢?因为上面过程和wirte无关,wirte没有FILE,用的是fd,所以没有C语言提供的缓冲区!