文章目录
- 一、字符串函数
- 二、数值函数
- 三、日期函数
- 四、其余常用函数
- 五、窗口函数
- 5.1、语法
- 5.2、常用窗口函数
- 六、自定义函数
- 6.1、自定义UDF函数
- 6.2、自定义UDTF函数
- 6.3、将自定义函数导入hive中
- 6.3.1、将项目打成jar包
- 6.3.2、将jar包传入hive目录
- 6.3.3、在hive中加载jar包
- 6.3.4、设置函数
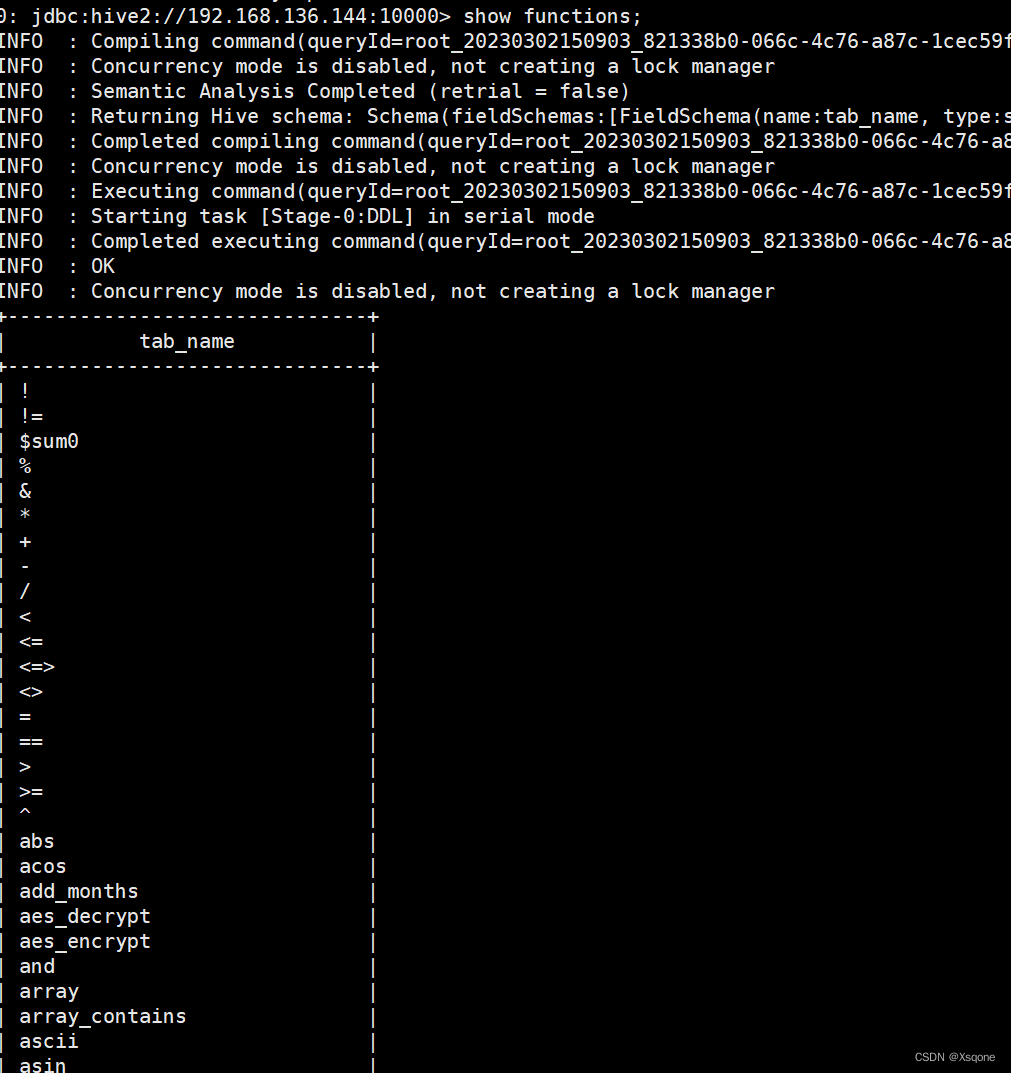
- 查看内置函数
show functions;
示例:
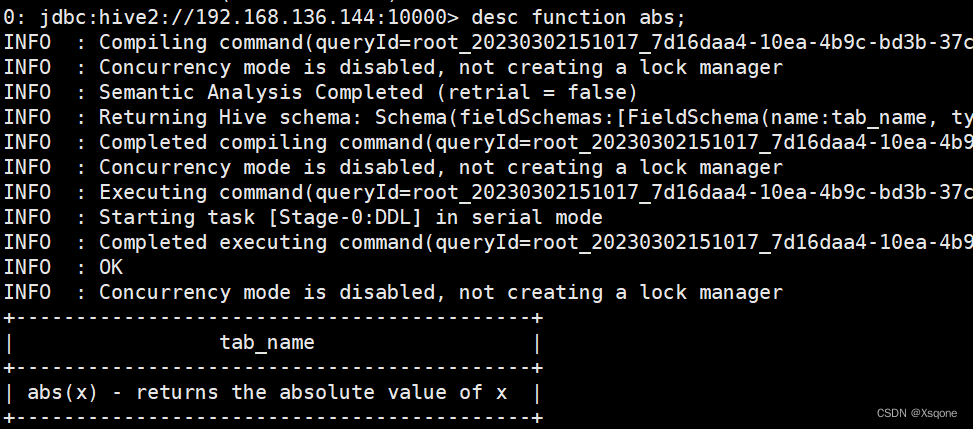
- 查看内置函数用法
desc function 函数名;
示例:
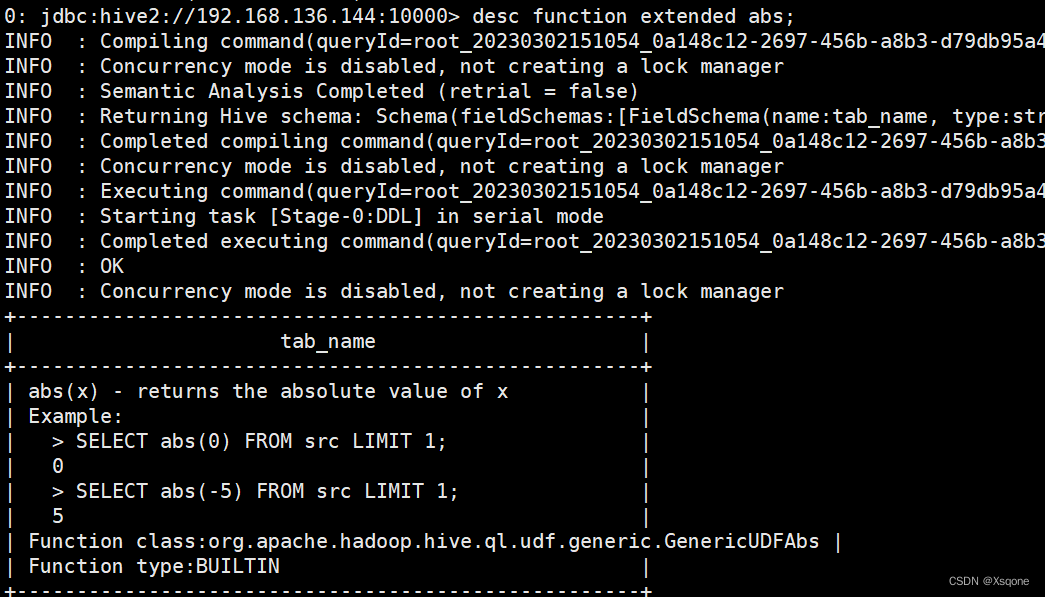
- 查看内置函数详细信息
desc function extended abs;
示例:
一、字符串函数
Hive字符串函数用于处理字符串类型的数据,包括截取、拼接、替换、转换大小写等操作。下面列举Hive中常用的字符串函数:
| 函数 | 介绍 | 示例 |
|---|---|---|
| CONCAT(str1, str2, …) | 用于拼接多个字符串 | |
| SUBSTR(str, start, length) | 用于截取字符串中的一部分 | |
| REPLACE(str, search, replacement) | 用于将字符串中的指定子串替换为另一个字符串 | |
| TRIM(str) | 用于去除字符串两侧的空格 | |
| LOWER(str) | 将字符串转换为小写 | |
| UPPER(str) | 将字符串转换为大写 | |
| LENGTH(str) | 用于获取字符串的长度 | |
| INSTR(str, substr) | 用于获取字符串中子串的位置 | |
| REGEXP_EXTRACT(str, regexp) | 用于从字符串中提取符合正则表达式的子串 | |
| SPLIT(str, delimiter) | 用于将字符串按照指定的分隔符进行拆分 | |
| CONCAT_WS(separator, str1, str2, …) | 用于拼接多个字符串,并在它们之间添加指定的分隔符 | |
| INITCAP(str) | 将字符串中的每个单词的首字母转换为大写 |
二、数值函数
Hive数值函数用于处理数字类型的数据,包括加减乘除、求绝对值、取余数、四舍五入、向上取整、向下取整等操作。下面列举Hive中常用的数值函数:
| 函数 | 介绍 | 示例 |
|---|---|---|
| ABS(n) | 用于获取一个数的绝对值 | |
| CEIL(n) | 用于将一个数向上取整 | |
| FLOOR(n) | 用于将一个数向下取整 | |
| ROUND(n, d) | 用于将一个数四舍五入到指定的小数位数 | |
| EXP(n) | 用于获取一个数的指数函数值 | |
| RAND() | 用于获取一个0到1之间的随机数 | |
| BIN(n) | 用于将一个十进制数转换为二进制数 | |
| HEX(n) | 用于将一个十进制数转换为十六进制数 |
三、日期函数
Hive提供了许多日期和时间函数,以下是一些常用的:
| 函数 | 介绍 | 示例 |
|---|---|---|
| current_date() | 返回当前日期,格式为 ‘yyyy-MM-dd’ | |
| current_timestamp() | 返回当前时间戳,格式为 ‘yyyy-MM-dd HH:mm:ss.SSS’。 | |
| date_format(date, pattern) | 将日期格式化为指定模式的字符串 | |
| year(date) | 返回日期的年份 | |
| quarter(date) | 返回日期的季度 | |
| month(date) | 返回日期的月份 | |
| day(date) | 返回日期的天数 | |
| datediff(enddate, startdate) | 计算两个日期之间相差的天数 | |
| date_add(date, days) | 给定日期加上指定天数 | |
| date_sub(date, days) | 给定日期减去指定天数 |
四、其余常用函数
| 函数 | 介绍 | 示例 |
|---|---|---|
| map_key(map<K,V>) | 获取 Map 类型列中所有键的集合 | |
| map_value(map<K,V>) | 获取Map 类型列中所有值的集合 | |
| stack(n, v1, v2, …, vn) | 创建一个包含 n 个元素的栈 | |
| explode(array<T> a) \ explode(map<K,V> m) | 将包含数组或Map类型的列中的元素分解成多行 | |
| json_tuple(jsonStr, p1, p2, …, pn) | 从JSON字符串中提取指定的字段值 | |
| get_json_object(json_string, json_path) | 从JSON字符串中提取指定的字段值 | |
| CAST(expression AS data_type) | 将一个数据类型转换为另一个数据类型 |
- stack(n, v1, v2, …, vn):
stack()函数在将多个列合并成一个列时,会将每个值都放在一个单独的行中。这意味着,输出结果的行数将是输入列数的n倍。如果需要将多个列按行合并到一个列中,可以考虑使用concat()函数或其他字符串函数。
五、窗口函数
- Hive窗口函数(Window Functions)是Hive中一种强大的分析函数,它们提供了一种在一组行中计算聚合值的方式。与常规聚合函数不同的是,窗口函数在查询结果中可以添加额外的列,这些列的值可以基于聚合函数的结果计算。
- 在Hive中,窗口函数使用OVER子句来指定要计算的行集合。在OVER子句中,可以指定窗口的边界条件(如窗口的大小、窗口的起始位置、窗口的结束位置等),以及要应用的聚合函数。一旦指定了OVER子句,Hive就会将结果集划分成指定的窗口,并计算每个窗口的聚合值。
5.1、语法
<window_function> ([expression]) OVER (
[PARTITION BY partition_expression, ...]
[ORDER BY sort_expression [ASC | DESC], ...]
[ROWS BETWEEN frame_start AND frame_end]
)
其中,<window_function> 是窗口函数的名称,expression 是要进行聚合计算的列或表达式。OVER子句中可以使用以下参数:
- PARTITION BY:指定分组列,用于将结果集划分成不同的分组,每个分组内部进行聚合计算。
- ORDER BY:指定排序列,用于将每个分组内的行进行排序。
- ROWS BETWEEN:指定窗口的边界条件,即要计算的行集合。常见的窗口类型包括:
- UNBOUNDED PRECEDING:窗口从分组的第一行开始。
- CURRENT ROW:窗口从当前行开始。
- UNBOUNDED FOLLOWING:窗口从分组的最后一行结束。
- <number> PRECEDING:窗口向前移动指定行数。
- <number> FOLLOWING:窗口向后移动指定行数。
- BETWEEN <start> AND <end>:指定窗口的起始位置和结束位置,其中 <start> 和 <end> 可以是以上任何类型。
5.2、常用窗口函数
| 函数 | 描述 |
|---|---|
| ROW_NUMBER() | 为每一行分配一个唯一的序号 |
| RANK() | 为每个唯一的值分配一个序号,如果有重复值,则序号相同 |
| DENSE_RANK() | 与RANK()函数类似,但是如果有重复值,则序号不会跳过相同的值 |
| FIRST_VALUE() | 返回窗口中第一个值 |
| LAST_VALUE() | 返回窗口中最后一个值 |
| LEAD() | 返回窗口中指定行之后的值 |
| LAG() | 返回窗口中指定行之前的值 |
| SUM() | 计算窗口中指定列的和 |
| AVG() | 计算窗口中指定列的平均值 |
| MAX() | 返回窗口中指定列的最大值 |
| MIN() | 返回窗口中指定列的最小值 |
六、自定义函数
创建maven项目,导入依赖
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<!-- 若3.1.3不可用则使用1.1.0 -->
<!--
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>1.1.0</version>
</dependency>-->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>3.1.3</version>
</dependency>
6.1、自定义UDF函数
UDF(User-Defined-Function) 一进一出,继承了org.apache.hadoop.hive.ql.exec.UDF类,并复写了evaluate方法。
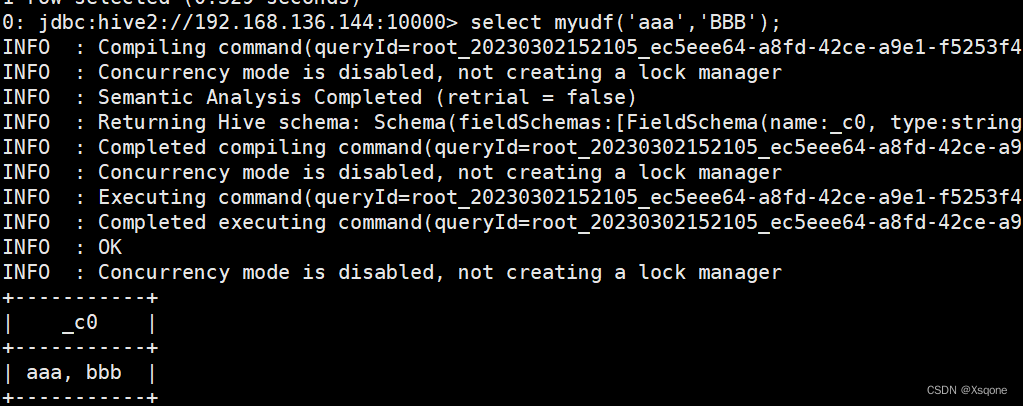
示例:将两个字符串传入,合到一起并全部转换成小写。
package org.example.udf;
import org.apache.hadoop.hive.ql.exec.UDF;
/**
* @program: hivefunction
* @interfaceName LowerUDF
* @description:
* @author: 太白
* @create: 2023-02-24 14:08
**/
public class LowerUDF extends UDF {
public String evaluate(final String txt,final String txt2){
String res = txt + ", " + txt2;
return res.toLowerCase();
}
public static void main(String[] args) {
LowerUDF lowerUDF = new LowerUDF();
System.out.println(lowerUDF.evaluate("aaa", "BBBBB"));
}
}
6.2、自定义UDTF函数
UDTF(User-Defined Table-Generating Functions)一进多出,继承org.apache.hadoop.hive.ql.udf.generic.GenericUDTF。
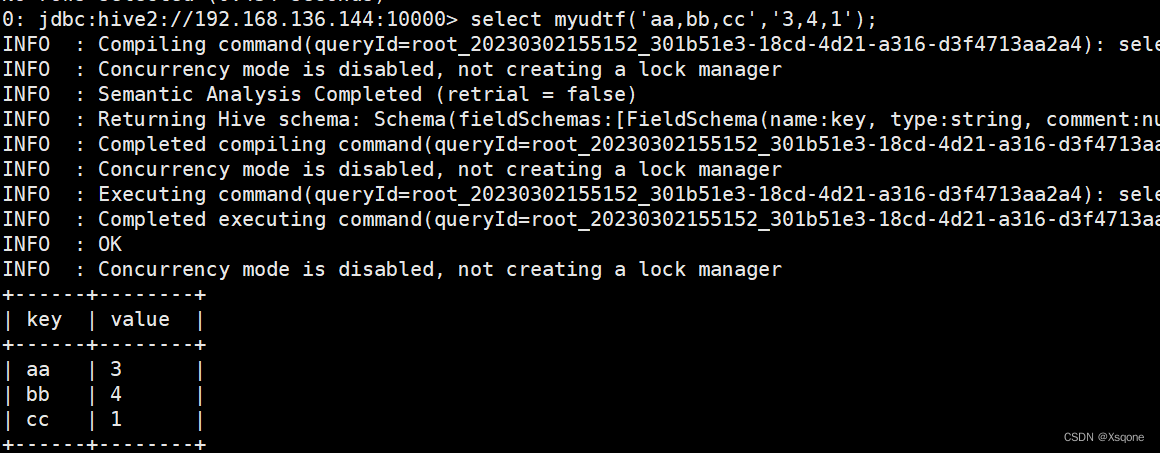
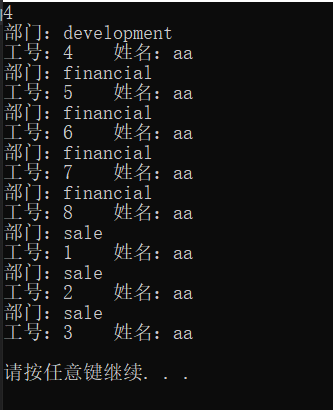
示例:将list转{“aa,bb,cc”,“3,4,1”}转换成map前面与后面一一对应。
package org.example.udtf;
import com.google.common.collect.Lists;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import java.util.ArrayList;
import java.util.LinkedList;
/**
* @program: hivefunction
* @interfaceName ArrayToMapUDTF
* @description:
* @author: 太白
* @create: 2023-02-25 08:49
**/
public class ArrayToMapUDTF extends GenericUDTF {
@Override
public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {
ArrayList<String> colName = Lists.newArrayList();
colName.add("key");
colName.add("value");
LinkedList<ObjectInspector> resType = Lists.newLinkedList();
resType.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
resType.add(PrimitiveObjectInspectorFactory.javaIntObjectInspector);
// 返回内容为列名和列的数据类型
return ObjectInspectorFactory.getStandardStructObjectInspector(colName, resType);
}
private Object[] obj = new Object[2];
@Override
public void process(Object[] args) throws HiveException {
if (args != null && args.length==2) {
String[] keys = args[0].toString().split(",");
String[] values = args[1].toString().split(",");
for (int i = 0; i < keys.length; i++) {
String key = keys[i];
Integer value = 0;
if (values.length>=i+1)
value = Integer.valueOf(values[i]);
obj[0] = key;
obj[1] = value;
forward(obj);
}
}else {
return;
}
}
@Override
public void close() throws HiveException {
}
}
6.3、将自定义函数导入hive中
6.3.1、将项目打成jar包
6.3.2、将jar包传入hive目录
传入hive的lib目录下
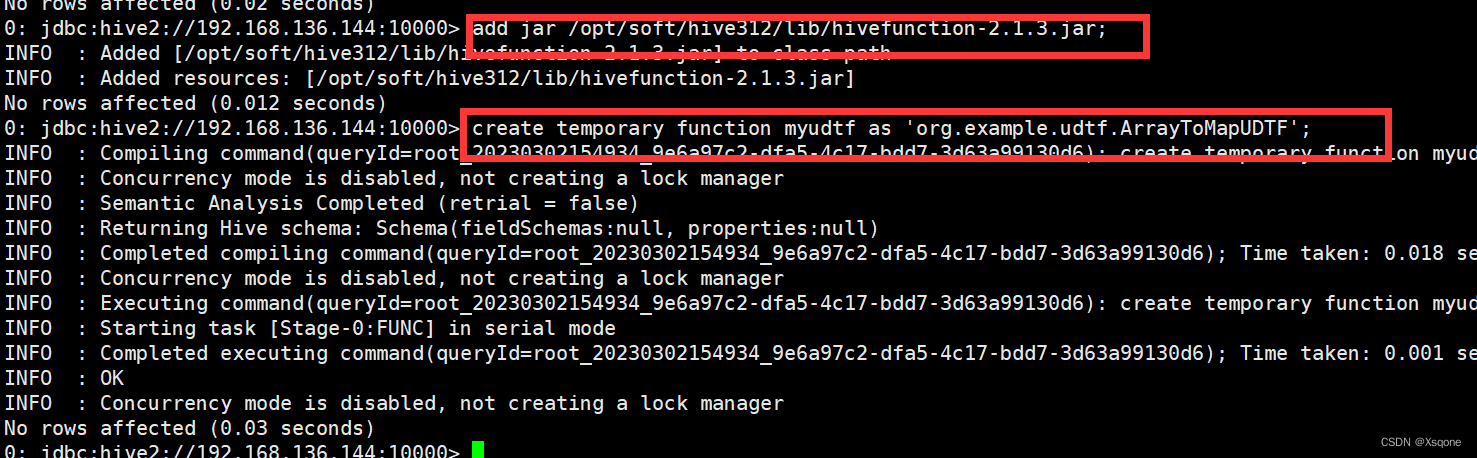
6.3.3、在hive中加载jar包
add jar /opt/soft/hive312/lib/…jar;
6.3.4、设置函数
创建临时函数
create temporary function 函数名 as ‘引用路径’;
创建函数
create function 函数名 as ‘引用路径’;




![[qiankun+nuxt]子应用请求本地文件报错404](https://img-blog.csdnimg.cn/3b92afcf06a84e25ad8c6e75e2f9d452.png)