入门需要掌握:从入门demo理解、flink 系统架构(看几个关键组件)、安装、使用flink的命令跑jar包+flink的webUI 界面的监控、常见错误、调优
一、入门demo:统计单词个数
0、单词txt 文本内容(words.txt):
hello world
hello flink
hello java
1、DataSet api(已弃用)
public class BatchWordCount {
public static void main(String[] args) throws Exception {
// 1. 创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 2. 从文件读取数据 按行读取(存储的元素就是每行的文本)
DataSource<String> lineDS = env.readTextFile("input/words.txt");
// 3. 转换数据格式
FlatMapOperator<String, Tuple2<String, Long>> wordAndOne = lineDS
.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {
String[] words = line.split(" ");
for (String word : words) {
//Tuple2.of 构建二元组
out.collect(Tuple2.of(word, 1L));
}
})
//Lambda是java的新特性(不是flink的特性),在Lambda表达式中使用泛型,存在泛型擦除,所以flink 需要用returns 显示的声明类型信息
.returns(Types.TUPLE(Types.STRING, Types.LONG));
// 4. 按照 word 进行分组(因为flink 不像Spark 有groupByKey可以直接得到字段,flink是通过索引位置得到字段,比如0就是第一个字段)
UnsortedGrouping<Tuple2<String, Long>> wordAndOneUG =
wordAndOne.groupBy(0);
// 5. 分组内聚合统计(同理,flink是通过索引位置得到字段,比如1就是第二个字段)
AggregateOperator<Tuple2<String, Long>> sum = wordAndOneUG.sum(1);
// 6. 打印结果
sum.print();
}
}
批处理结果:
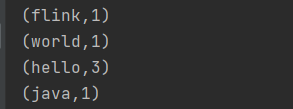
为什么说是DataSet api?
-
数据源:DataSource 继承Operator 继承DataSet
-
转换:
FlatMapOperator 继承SingleInputUdfOperator 继承SingleInputOperator 继承Operator 继承DataSet
AggregateOperator 继承SingleInputOperator 继承Operator 继承DataSet所以,把这一整套称为DataSet api。
2、DataStream api
public class FlinkDemo {
public static void main(String[] args) throws Exception {
// 1. 创建流式执行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 读取文件
DataStreamSource<String> lineDSS = env.readTextFile("./src/main/java/com/shan/words.txt");
// 3. 转换数据格式
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = lineDSS
.flatMap((String line, Collector<String> words) -> {
Arrays.stream(line.split(" ")).forEach(words::collect);
})
.returns(Types.STRING)
.map(word -> Tuple2.of(word, 1L))
.returns(Types.TUPLE(Types.STRING, Types.LONG));
// 4. 分组
KeyedStream<Tuple2<String, Long>, String> wordAndOneKS = wordAndOne
.keyBy(t -> t.f0);
// 5. 求和
SingleOutputStreamOperator<Tuple2<String, Long>> result = wordAndOneKS
.sum(1);
// 6. 打印
result.print();
// 7. 执行
env.execute();
}
}
流处理结果:
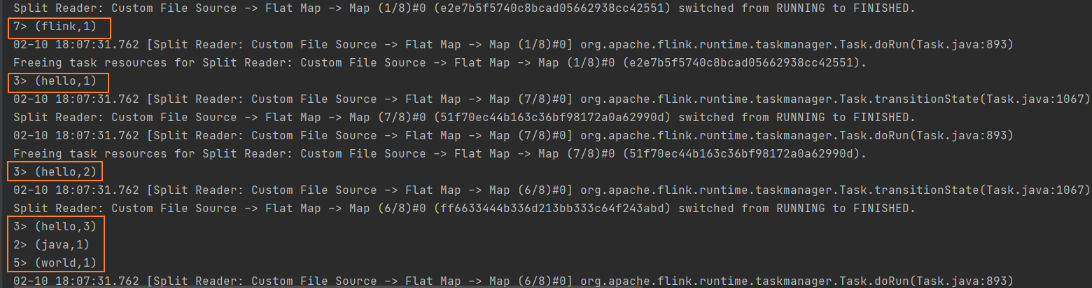
3、特点:
- idea 执行代码,通过多线程并行模拟flink这个分布式框架的并行的特点。idea通过线程模拟任务槽(flink的并行单位-并行子任务编号,它的数量是由并行度决定的)
- 简单理解:并行度,就是当前任务分成多少份去做多线程的并行处理的程度、个数
- idea 没有设置并行度,默认就是电脑cpu核心数量(逻辑处理器数量)
- 小细节:hello前面的子任务编号是相同的,说明分组的时候,将统计hello的个数分给同一个子任务去执行,只有在同一个任务上才能进行叠加
并行,不能保证顺序!
4、流数据特点:应该是源源不断的到来—需要监听捕获
- 代码中,将数据源来源进行修改成监听端口即可
public class FlinkDemo {
public static void main(String[] args) throws Exception {
// 1. 创建流式执行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 读取数据流 [代码中,将数据源来源进行修改成监听端口即可]
DataStreamSource<String> lineDSS = env.socketTextStream("hadoop102", 7777);
// 3. 转换数据格式
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = lineDSS
.flatMap((String line, Collector<String> words) -> {
Arrays.stream(line.split(" ")).forEach(words::collect);
})
.returns(Types.STRING)
.map(word -> Tuple2.of(word, 1L))
.returns(Types.TUPLE(Types.STRING, Types.LONG));
// 4. 分组
KeyedStream<Tuple2<String, Long>, String> wordAndOneKS = wordAndOne
.keyBy(t -> t.f0);
// 5. 求和
SingleOutputStreamOperator<Tuple2<String, Long>> result = wordAndOneKS
.sum(1);
// 6. 打印
result.print();
// 7. 执行
env.execute();
}
}
- socket的数据流数据的发送,可以通过Linux系统自带的netcat工具进行模拟。
# 在 Linux 环境的主机 hadoop102 上,执行下列命令,发送数据进行测试:
[atshan@hadoop102 ~]$ nc -lk 7777
-
启动 java 程序
我们会发现程序启动之后没有任何输出、也不会退出。这是正常的——因为 Flink 的流处理是事件驱动的,当前程序会一直处于监听状态,只有接收到数据才会执行任务、输出统计结果。
-
在 Linux 环境的主机 hadoop102 上发送数据
hello flink
hello world
hello java
- 可以看到程序的控制台有数据的输出
二、flink 系统架构/Flink 作业提交运行的原理
我们编写的代码,对应着在Flink集群上执行的一个作业;所以我们在本地执行代码,其实是idea开发环境中根据引入的依赖,先模拟启动一个Flink集群,
然后把我们代码中定义好的操作,作为"作业",(job要打包好)
然后将作业提交到集群上,创建好要执行的任务等待数据输入。
1、Flink 中的几个关键组件:
客户端(Client)、作业管理器(JobManager)和任务管理器(TaskManager)。
(1) 客户端:和flink 集群关系没那么大,主要就是向flink 提交一下作业。
- 我们的代码,实际上是由客户端获取并做转换,之后提交给JobManger 的。
(2) JobManager:对作业进行调度管理
- JobManager获取到要执行的作业后,会进一步处理转换,然后分发任务给众多的 TaskManager
(3) TaskManagers: 也叫worker,等待数据输入,进行实际计算。
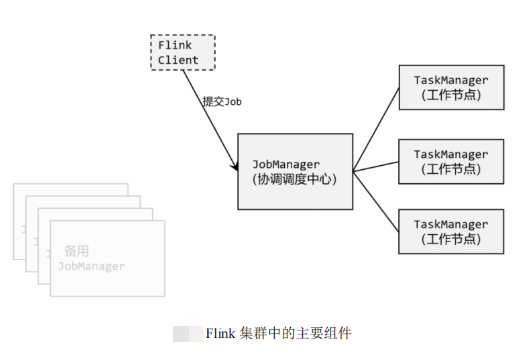
2、flink 系统架构详细图
- JobManager,也称为 master,用于协调分布式执行。负责调度任务,检查点,失败恢复等。
- TaskManager,也称为 worker,用于执行数据流图的任务(更准确地说,是计算子任务),并对数据流进行缓冲、交换。Flink 运行环境中至少包含一个任务管理器。

3、Flink之运行时环境
(1) JobManager:
JobManager是Flink系统的协调者,它负责接收Flink Job,调度组成Job的多个Task的执行。同时,JobManager还负责收集Job的状态信息,并管理Flink集群中从节点TaskManager。
■ JobManager所负责的各项管理功能,它接收到并处理的事件主要包括:RegisterTaskManager、SubmitJob、CancelJob、UpdateTaskExecutionState、JobStatusChanged、RequestNextInputSplit
- RegisterTaskManager
在Flink集群启动的时候,TaskManager会向JobManager注册,如果注册成功,则JobManager会向TaskManager回复消息AcknowledgeRegistration。
- SubmitJob
Flink程序内部通过Client向JobManager提交Flink Job,其中在消息SubmitJob中以JobGraph形式描述了Job的基本信息。
- CancelJob
请求取消一个Flink Job的执行,CancelJob消息中包含了Job的ID,如果成功则返回消息CancellationSuccess,失败则返回消息CancellationFailure。
- UpdateTaskExecutionState
TaskManager会向JobManager请求更新ExecutionGraph中的ExecutionVertex的状态信息,更新成功则返回true。
- JobStatusChanged
ExecutionGraph向JobManager发送该消息,用来表示Flink Job的状态发生的变化,例如:RUNNING、CANCELING、FINISHED等。
- RequestNextInputSplit
运行在TaskManager上面的Task,请求获取下一个要处理的输入Split,成功则返回NextInputSplit。
(2) TaskManager:
TaskManager也是一个Actor,它是实际负责执行计算的Worker,在其上执行Flink Job的一组Task。每个TaskManager负责管理其所在节点上的资源信息,如内存、磁盘、网络,在启动的时候将资源的状态向JobManager汇报。TaskManager端可以分成两个阶段: 注册、可操作阶段
- 注册阶段
TaskManager会向JobManager注册,发送RegisterTaskManager消息,等待JobManager返回AcknowledgeRegistration,然后TaskManager就可以进行初始化过程。
- 可操作阶段
该阶段TaskManager可以接收并处理与Task有关的消息,如SubmitTask、CancelTask、FailTask。如果TaskManager无法连接到JobManager,这是TaskManager就失去了与JobManager的联系,会自动进入“注册阶段”,只有完成注册才能继续处理Task相关的消息。
(3) Client
当用户提交一个Flink程序时,会首先创建一个Client,该Client首先会对用户提交的Flink程序进行预处理,并提交到Flink集群中处理,所以Client需要从用户提交的Flink程序配置中获取JobManager的地址,并建立到JobManager的连接,将Flink Job提交给JobManager。
Client会将用户提交的Flink程序组装一个JobGraph, 并且是以JobGraph的形式提交的。一个JobGraph是一个Flink Dataflow,它由多个JobVertex组成的DAG。其中,一个JobGraph包含了一个Flink程序的如下信息:JobID、Job名称、配置信息、一组JobVertex等。
三、flink 集群部署-一主二从
flink 集群默认是本地启动,即Flink 本地启动,直接执行 start-cluster.sh
0、flink 安装
(1) 下载:
- 细节1:flink有两个版本,一个版本是和hadoop捆绑的,另一个是单独的,后缀包含scala
- 细节2:注意最新版的flink 要求的java版本是11,13版本的flink,java版本是8
- 下载链接:https://flink.apache.org/zh/downloads.html
wget https://archive.apache.org/dist/flink/flink-1.13.6/flink-1.13.6-bin-scala_2.12.tgz
(2) 解压
- 习惯,解压到/opt下自己建立的模块modules目录下
tar -zxvf flink-1.13.6-bin-scala_2.12.tgz -C /opt/modules/
(3) 配置环境:
vim /etc/profile
# 在配置文件中添加如下内容
export FLINK_HOME=/opt/flink-1.13.6
export PATH=$FLINK_HOME/bin:$PATH
# 保存一下配置
source /etc/profile
1、服务器的准备
本书中三台服务器的具体设置如下:
⚫ 节点服务器 1,IP 地址为 192.168.10.102,主机名为 hadoop101。
⚫ 节点服务器 2,IP 地址为 192.168.10.103,主机名为 hadoop102。
⚫ 节点服务器 3,IP 地址为 192.168.10.104,主机名为 hadoop103。
配置工作:先在其中一台服务器上对flink根目录下配置文件进行修改,然后把修改好后的flink 根目录,分发给另外两个节点服务器(通过scp命令)。
# 主机配置修改完毕后,将 Flink 安装目录发给另外两个节点服务器 $ scp -r ./flink-1.13.0 atguigu@hadoop102:/opt/module $ scp -r ./flink-1.13.0 atguigu@hadoop103:/opt/module配置好后:
在主机那台机器,通过命令:start-cluster.sh 启动集群时,看到日志提示它是主机,通过jps命令,看到StandaloneSessionClusterEntrypoint;
在从机上,通过jps命令,看到打印信息,提示它是从机TaskManagerRunner。
■ 跨服务器的远程拷贝命令scp:
scp是secure copy的简写,用于在Linux下进行远程拷贝文件的命令,和它类似的命令有cp,不过cp只是在本机进行拷贝不能跨服务器,而且scp传输是加密的。
命令格式:scp [参数] [需要传输的文件原路径] [接收传输的文件的服务器目录路径]
- scp命令,可以将当前文件资源拷贝给远程服务器,也可以将远程服务器的文件资源拷贝到本机上
# 在本地服务器上将/root/shan目录下所有文件传输到服务器10.11.34.73 的/home/目录下,命令为: scp -r /root/shan root@10.11.34.73:/home/ # 将服务器10.11.34.73 的/home/shanshan 目录下所有文件传递到本机服务器的/root/ 目录下,命令为: scp -r @10.11.34.73:/home/shanshan /root
2、主机的配置 hadoop101
-
修改flink 配置文件conf目录下的flink-conf.yaml :
# 默认是localhost jobmanager.rpc.address: hadoop101 -
【这一步可以省略】修改flink 配置文件conf目录下的masters
# 默认是localhost hadoop101:8081
3、从机的配置 hadoop102、hadoop103
-
修改flink 配置文件conf目录下的workers
# 默认是localhost hadoop102 hadoop103
4、flink 的 webUI 界面
-
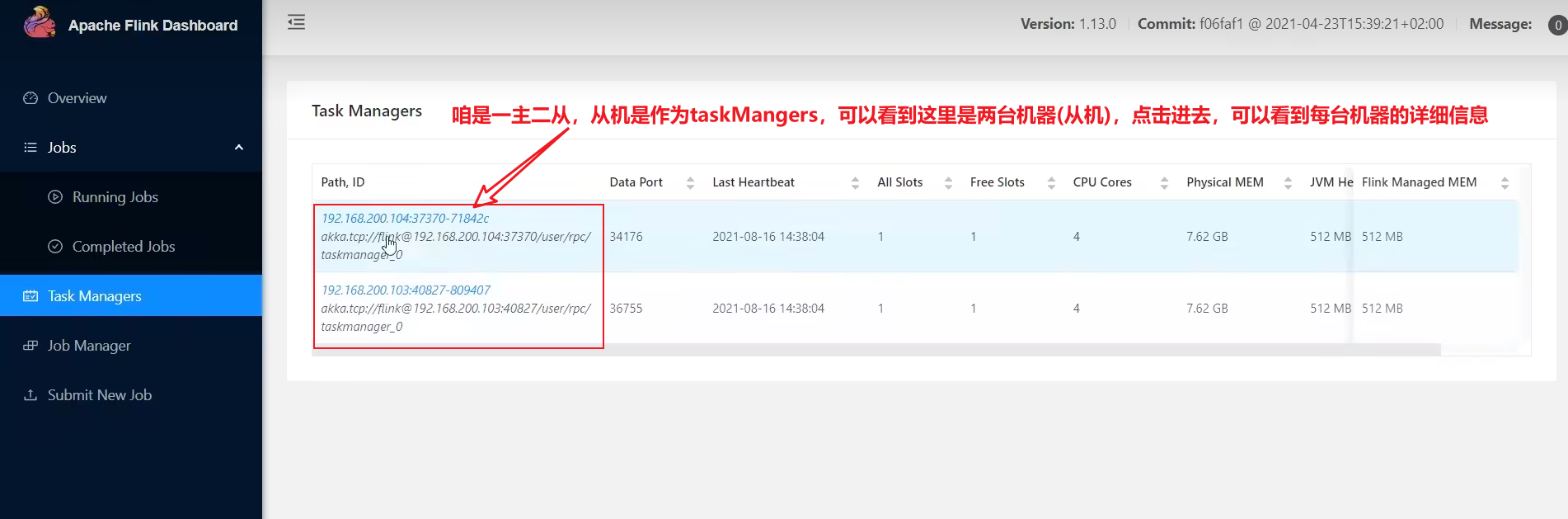
概况:可以看到可用的资源、运行的jobs数量、运行的job列表、完成的job列表(也可以在Jobs 下看到更详细的信息)
当前集群的 TaskManager 数量为 2;由于默认每个TaskManager的Slot数量为 1,所以总Slot数 和 可用Slot数都为2。

- 看到从机taskManagers 的情况:
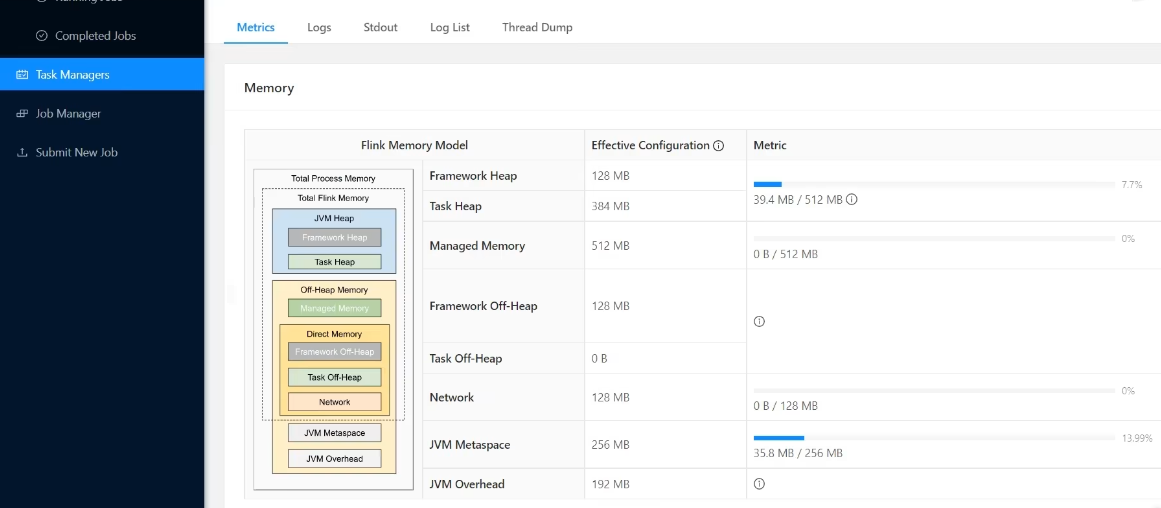
- taskManagers 内存
每一个taskManager(worker) 其实就是一个独立的jvm实例[jvm 进程],站在jvm 进程的角度理解内存:
Total Process Memory 其实就是jvm,包括了JVM Heap 堆内存、Off-Heap Memory 堆外内存。
其中,flink 管理的内存,包括代码定义的对象,放到的JVM Heap 堆内存,以及flink定义好的状态会放在 Off-Heap Memory 的Managed Memory,还有直接内存。
四、flink 命令
1、flink 提交运行作业(命令行的方式,可以设置更多的参数)
- 也可以通过ui界面提交作业:
# 在master主机上,先使用命令rz 进行文件上传
# 进入xxx.jar包所在目录
flink run -c com.xsj.whale.flink.task.CrawlerToKafka -p 4 --detached -D taskmanager.numberOfTaskSlots=4 -D jobmanager.memory.process.size=2048mb -D taskmanager.memory.process.size=5120mb xxx.jar
命令行提交作业的细节:如果是直接在主机的命令行窗口上提交,则不用通过参数指定主机。
- 在从机上通过命令行提交作业,需要通过参数 -m 主机名:端口 指定master主机和端口号。
# 先把xxx.jar 上传到从机上,然后在其目录下提交作业 flink run -m hadoop102:8081 -c 主程序的类全限定名 -p 2 xxx.jar
- 启动flink
start-cluster.sh
- 结束flink
stop-cluster.sh
- 取消作业
flink cancel 作业id
- 查看flink 输出结果
# 进入flink的日志目录
tail log/flink-*-taskexecutor-*.out
五、flink 常见错误
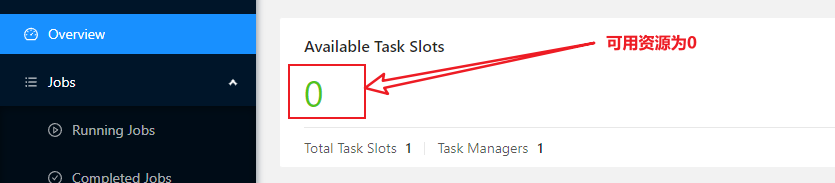
1、NoResourceAvailableException: Could not acquire the minimum required resources.
- 原因:没有资源的情况下,提交作业。
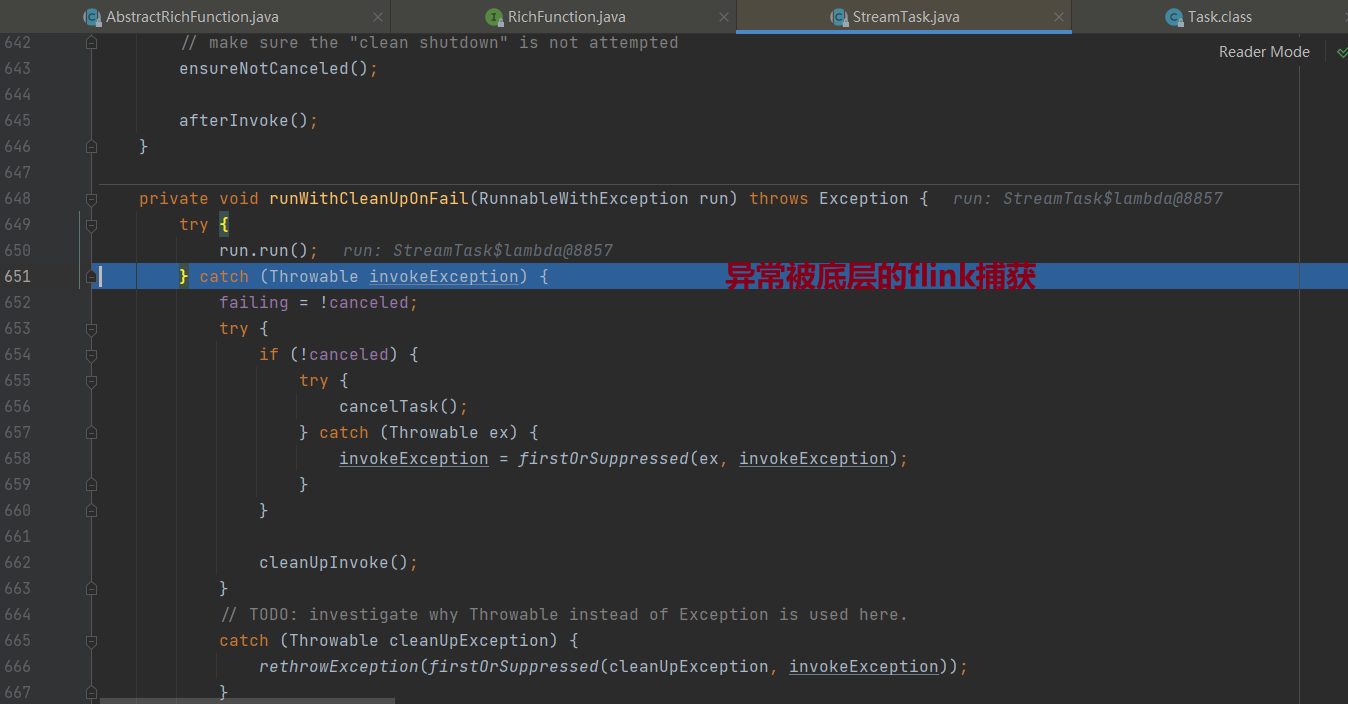
2、异常被抛出(不被catch)会导致flink任务挂掉
- 业务的代码写错了,但是对异常没有try…catch,异常被底层的fink捕获后,任务挂掉

六、flink 的优化配置与调优
在 flink-conf.yaml 文件中还可以对集群中的 JobManager 和 TaskManager 组件进行优化配置
1、通用配置-内存调优
-
jobmanager.memory.process.size:对 JobManager 进程可使用到的全部内存进行配置,包括 JVM 元空间和其他开销,默认为 1600M,可以根据集群规模进行适当调整。
-
taskmanager.memory.process.size:对 TaskManager 进程可使用到的全部内存进行配置,包括 JVM 元空间和其他开销,默认为 1600M,可以根据集群规模进行适当调整。
-
taskmanager.numberOfTaskSlots:对每个 TaskManager 能够分配的 Slot 数量进行配置,默认为 1,可根据 TaskManager 所在的机器能够提供给Flink 的 CPU 数量决定。所谓Slot 就是 TaskManager 中具体运行一个任务所分配的计算资源。
-
parallelism.default:Flink 任务执行的默认并行度,优先级低于代码中进行的并行度配置和任务提交时使用参数指定的并行度数量。
七、flink 的部署
1、flink 资源被占用的问题
flink 的资源被占用的时候,还需要提交或者追加作业,就得等前面的资源被释放了或者需要集群新增加机器。
一种手动管理一切的方式!不够方便!
真正的企业级应用里,我们更加希望是有一套平台,资源不够了,"你"再去申请,再去申请更多资源;而我只需要做的就是只是将集群跑起来,作业跑起来。
“你"不要总跟我提示"资源不够用了”。—> flink 要和不同的资源管理平台要结合在一起!
2、flink 的部署模式
flink 的不同场景,不同的部署模式。
会话模式(Session Mode)
单作业模式(Per-JobMode)
应用模式(Application Mode)
它们的区别主要在于:集群的生命周期以及资源的分配方式。
会话模式
- 特点:资源有限;优点:方便(集群启动起来后,资源也确定了,固定放在那等待使用);缺点:资源共享,一旦资源不够,提交作业就失败;
- 应用:适合**
单个规模小,执行时间短**的大量作业。(上一个作业释放完资源就可以给下一个作业了!充分利用资源!) - 集群不跟着作业的状态而发生改变,当我们kill或者cancle作业之后,集群依然存在,生命周期远大于作业。
- 作业如果竞争资源,竞争不到,怎么办?–等待那个占用了资源的作业运行结束或者被cancle,然后释放出资源!
会话模式其实最符合常规思维,就是我们前面的集群启动默认就是会话模式。我们需要先启动一个集群,保持一个会话,在这个会话中通过客户端提交作业,集群启动时所有资源就都已经确定,所以所有提交的作业会竞争集群中的资源。
八、flink的print 底层
1、旁路输出流
//旁路输出流print
taptapGroupFeedStreamSideOutput.print();
taptapGroupFeedStreamSideOutput.printToErr();
// -->PrintSinkFunction
@PublicEvolving
public DataStreamSink<T> print() {
//创建一个打印汇总算子对象
PrintSinkFunction<T> printFunction = new PrintSinkFunction<>();
//添加到汇总里
return addSink(printFunction).name("Print to Std. Out");
}
public DataStreamSink<T> addSink(SinkFunction<T> sinkFunction) {
// 1、在转换对象中获取到输出类型
transformation.getOutputType();
//如果汇总算子是输入类型的配置,则设置一下相关配置
if (sinkFunction instanceof InputTypeConfigurable) {
((InputTypeConfigurable) sinkFunction).setInputType(getType(), getExecutionConfig());
}
//2、清理一下汇总算子,并构建汇总操作
StreamSink<T> sinkOperator = new StreamSink<>(clean(sinkFunction));
//3、构建汇总数据流,并把汇总操作放进去
DataStreamSink<T> sink = new DataStreamSink<>(this, sinkOperator);
//4、给环境添加操作(汇总数据流中的转换)
getExecutionEnvironment().addOperator(sink.getTransformation());
//5、返回汇总数据流
return sink;
}
如果本文对你有帮助的话记得给一乐点个赞哦,感谢!