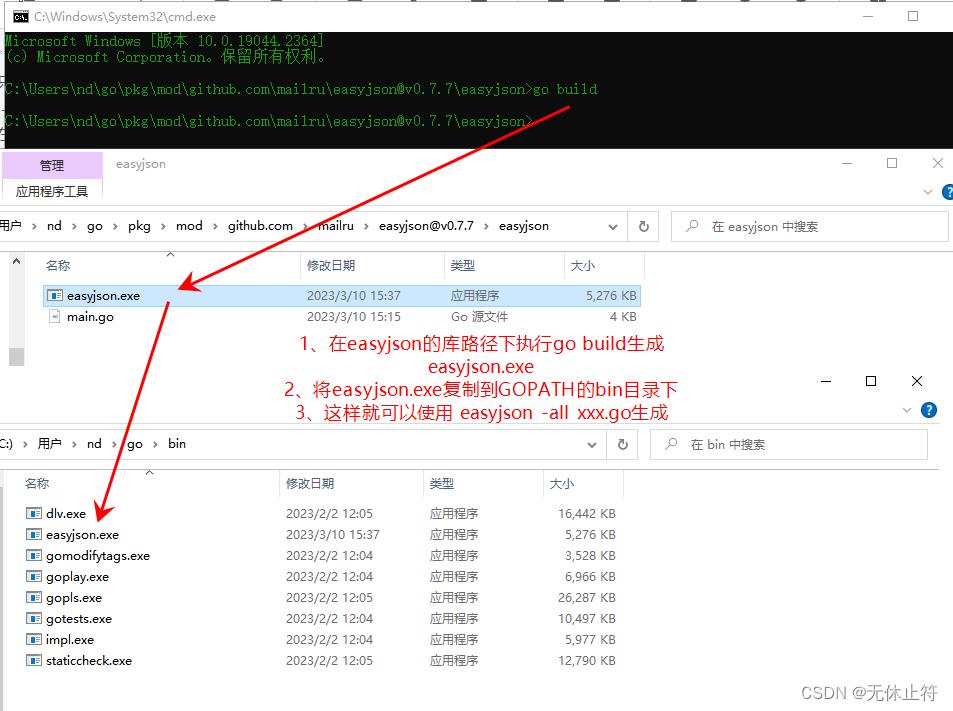
z
i
,
t
∈
R
z_{i,t}\in \mathbb{R}
zi,t∈R表示时间序列
i
i
i在
t
t
t时刻的值。给一个连续时间段
t
∈
[
1
,
T
]
t\in [1, T]
t∈[1,T],将其划分为context window
[
1
,
t
0
)
[1,t_0)
[1,t0)和prediction window
[
t
0
,
T
]
[t_0,T]
[t0,T]。用context window的时间序列预测prediction window的时间序列的目标分布是
P
(
z
i
,
t
0
:
T
∣
z
i
,
1
:
t
0
−
1
,
x
i
,
1
:
T
)
P(\mathbf z_{i,t_0:T} | \mathbf z_{i,1:t_0-1}, \mathbf x_{i,1:T})
P(zi,t0:T∣zi,1:t0−1,xi,1:T)其中
x
i
,
t
\mathbf x_{i,t}
xi,t是协变量(covariate),也就是特征,可以是时间相关的,也可以是序列相关的,比如day-of-the-week、hour-of-the-day等。
作者用自回归(autoregressive)模型建模上面时间序列的概率:
Q
Θ
(
z
i
,
t
0
:
T
∣
z
i
,
1
:
t
0
−
1
,
x
i
,
1
:
T
)
=
Π
t
=
t
0
T
Q
Θ
(
z
i
,
t
∣
z
i
,
1
:
t
−
1
,
x
i
,
1
:
T
)
=
Π
t
=
t
0
T
l
(
z
i
,
t
∣
θ
(
h
i
,
t
,
Θ
)
)
Q_\Theta(\mathbf z_{i,t_0:T} | \mathbf z_{i,1:t_0-1}, \mathbf x_{i,1:T})=\Pi_{t=t_0}^TQ_\Theta(z_{i,t} | \mathbf z_{i,1:t-1}, \mathbf x_{i,1:T}) = \Pi_{t=t_0}^T l(z_{i,t} | \theta(\mathbf h_{i,t}, \Theta))
QΘ(zi,t0:T∣zi,1:t0−1,xi,1:T)=Πt=t0TQΘ(zi,t∣zi,1:t−1,xi,1:T)=Πt=t0Tl(zi,t∣θ(hi,t,Θ))其中
h
i
,
t
=
h
(
h
i
,
t
−
1
,
z
i
,
t
−
1
,
x
i
,
t
,
Θ
)
\mathbf h_{i,t} = h(\mathbf h_{i,t-1}, z_{i, t-1}, \mathbf x_{i,t}, \Theta)
hi,t=h(hi,t−1,zi,t−1,xi,t,Θ)是RNN的隐含表示。likelihood
l
(
z
i
,
t
∣
θ
(
h
i
,
t
,
Θ
)
)
l(z_{i,t} | \theta(\mathbf h_{i,t}, \Theta))
l(zi,t∣θ(hi,t,Θ))是一个分布,参数由
θ
(
h
i
,
t
,
Θ
)
\theta(\mathbf h_{i,t}, \Theta)
θ(hi,t,Θ)给出。

likelihood l ( z i , t ∣ θ ( h i , t , Θ ) ) l(z_{i,t} | \theta(\mathbf h_{i,t}, \Theta)) l(zi,t∣θ(hi,t,Θ))的参数由网络预测,例如分布的mean和variance。具体地,作者对实数值选择Gaussian likelihood,对正的计数值选择negative-binomial likelihood。
优化目标是最大化log-likelihood:
L
=
∑
i
=
1
N
∑
t
=
t
0
T
log
l
(
z
i
,
t
∣
θ
(
h
i
,
t
)
)
\mathcal L = \sum_{i=1}^N \sum_{t=t_0}^T \log l(z_{i,t} | \theta(\mathbf h_{i,t}))
L=i=1∑Nt=t0∑Tlogl(zi,t∣θ(hi,t))因为模型没有隐变量,所以不需要inference,可以直接用梯度下降优化。需要优化的参数
Θ
\Theta
Θ包含RNN的参数,和计算分布参数的参数。