当你在学习语言的时候,是否经常听到过一种说法,"="左边的叫做左值,"="右边的叫做右值。这句话对吗?从某种意义上来说,这句话只是说对了一部分。
---前言
一、什么是左右值?
通常认为:
左值是一个表示数据的表达式(如变量名或解引用的指针), 我们可以 获取它的地址 + 可以对它赋
值(使用空间) ,左值可以出现赋值符号的左边,也可以出现在等号右边。
右值也是一个表示数据的表达式,如:字面常量、表达式返回值,函数返回值等等。右值 可以出现在赋值符号的右边 ,但是 不能出现在赋值符号的左边 , 右值不能取地址 。
//x \ y 都是左值 都可以取地址
double x = 1.1, y = 2.2;
int a = 10,b = 20;
//以下都是右值 都不用取地址
10;
x + y;
func();二、左右值引用
(1)左值引用
type& x;
在我们学习引用的时候,一定会和C语言的指针联系到一起。我们来看看下面的swap代码吧。
void SwapByPtr(int* a,int* b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
void SwapByVal(int a, int b)
{
int tmp = a;
a = b;
b = a;
}
结果我想你一定知道的!函数传值与函数传地址是不同的!一个是一份拷贝,一个是记录的地址,可以访问原变量。
但是我们知道,指针是有它的缺陷,如果不是一位资深程序员,甚至你是,也得对指针的使用报以"敬畏之心"。因此,在C++中引入了新的语法,"引用"。虽然它底层仍然是用指针实现的,但是却比指针用起来更加方便。
void SwapByRef(int& a,int& b)
{
int tmp = a;
a = b;
b = a;
}
(2)右值引用
我们时常说"引用","引用",其实都是"左值引用"。为了区别左值引用呢,右值引用的语法格式上是这样的。
type &&;
int a = 10;
int& ra = a; //左值引用
int&& rra = 10; //右值引用(3)左右值引用的特性
左值引用:
①只能引用左值,不能引用右值
②但是const左值引用 可以引用右值也可以引用左值
int a = 10;
int& ra = a; //只能引用左值
int& rb1 = 10; //不能引用右值 ×
//既可以引用左值、也可以引用右值
const int& rb2 = a;
const int& rb2 = 10; 右值引用:
①右值引用只能引用右值,不能引用左值
②标准库中提供move()函数,可以将一个左值变为右值
int a = 10;
int&& rra1 = 10; //只能引用右值
int&& rra2 = a; //不能引用左值 ×
//move后可以 a变成了右值
int&& rra3 = std::move(a);右值不能取地址,但是右值引用能够取地址!!
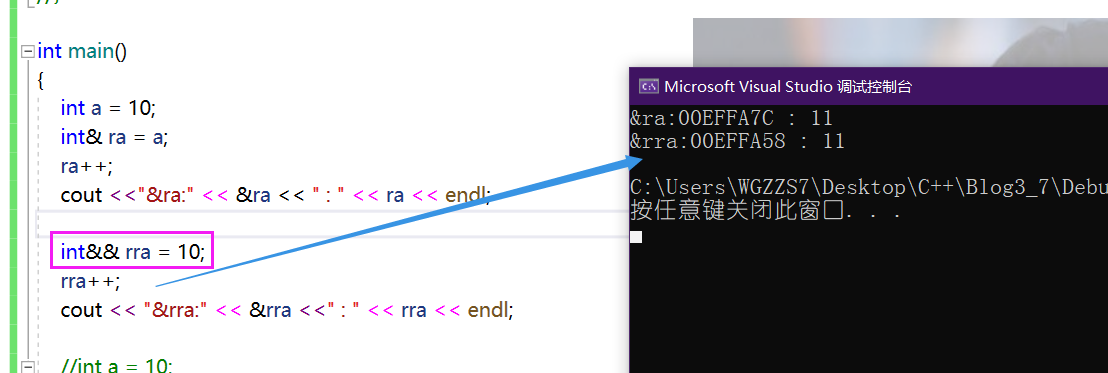
右值当然没有地址,但是我们给右值取引用时,那么这个右值引用就该有它的地址,并且可以对它引用的对象进行修改。如果你不想允许让对右值引用的值发生改变,请给它+"const"吧。
为什么这么设计呢?这和右值引用的场景有关,也就是我们之后要细讲的。
当然,这很符合我们的预期。

三、左右值引用的应用场景
也许你会疑问,已经有了左值引用,为什么还需要右值引用呢?右值引用一定有它存在必要的场景。在此之前,我们就先来列举列举左值引用的使用场景吧。
左值引用场景:
①函数传参防拷贝。
②函数返回值 引用返回。
//函数传参防拷贝
vector<int>& Func(vector<int>& ret)
{
ret.push_back(1);
//...
//函数引用返回值
return ret;
}当要进行左值引用返回时,唯一一个条件时,该对象出了作用域仍然存在!那如果该对象就是在函数体内创建的,出了作用域它就会销毁,但其拷贝的代价又很大。遇到这样的情况,我们应该怎么处理呢?
(1)移动赋值与移动构造
我们首先实现一个to_string的函数,用来将一个数字,转换为自定义字符串。
//to_string函数
string to_string(int value)
{
bool flag = true;
if (value < 0)
{
flag = false;
value = 0 - value;
}
dy::string str;
while (value > 0)
{
int x = value % 10;
value /= 10;
str += ('0' + x);
}
if (flag == false)
{
str += '-';
}
std::reverse(str.begin(), str.end());
return str;
}//自定义string 类
class string
{
public:
typedef char* iterator;
iterator begin()
{
return _str;
}
iterator end()
{
return _str + _size;
}
string(const char* str = "")
:_size(strlen(str))
, _capacity(_size)
{
_str = new char[_capacity + 1];
strcpy(_str, str);
}
// s1.swap(s2)
void swap(string& s)
{
::swap(_str, s._str);
::swap(_size, s._size);
::swap(_capacity, s._capacity);
}
// 拷贝构造
string(const string& s)
{
cout << "string(const string& s) -- 深拷贝" << endl;
string tmp(s._str);
swap(tmp);
}
// 赋值重载
string& operator=(const string& s)
{
cout << "string& operator=(string s) -- 深拷贝" << endl;
string tmp(s);
swap(tmp);
return *this;
}
~string()
{
delete[] _str;
_str = nullptr;
}
char& operator[](size_t pos)
{
assert(pos < _size);
return _str[pos];
}
void reserve(size_t n)
{
if (n > _capacity)
{
char* tmp = new char[n + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
_capacity = n;
}
}
void push_back(char ch)
{
if (_size >= _capacity)
{
size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2;
reserve(newcapacity);
}
_str[_size] = ch;
++_size;
_str[_size] = '\0';
}
//string operator+=(char ch)
string& operator+=(char ch)
{
push_back(ch);
return *this;
}
const char* c_str() const
{
return _str;
}
private:
char* _str = nullptr;
size_t _size = 0;
size_t _capacity = 0; // 不包含最后做标识的\0
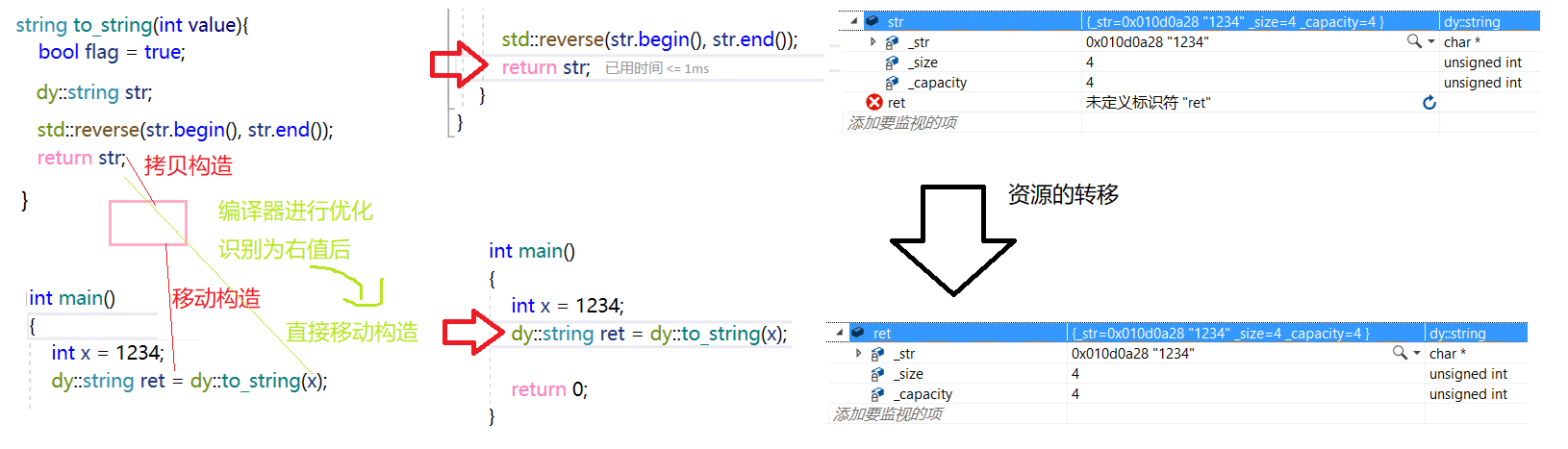
};我们此时用一个整数,使用to_string函数,得到一个自定义string类型。
int main()
{
int x = 1234;
dy::string ret = dy::to_string(x);
return 0;
}
但是,我们为了一个在to_string函数类,一个出作用域就会销毁的对象,为了得到它其中的资源,就得付出"深拷贝"一份的代价,未免有些太大。
如果仅仅是拷贝内置类型来说,那么微乎其微,但如果深拷贝对象是map、set呢?也许你仅仅只需要得到这个即将销毁对象的"根节点"即可,而非是在return返回时,让该对象拷贝构造临时对象而付出巨大代价。
秉持这样的想法,我们为该自定义类设计一个新的拷贝构造函数。
//移动赋值与移动构造
string(string&& s)
{
cout << "string(string&& s): 移动构造" << endl;
swap(s);
}
string& operator=(string&& s)
{
cout << "string& operator=(string s) 移动赋值" << endl;
swap(s);
return *this;
}我们为该类增加这两个函数,并再次运行相同的代码。
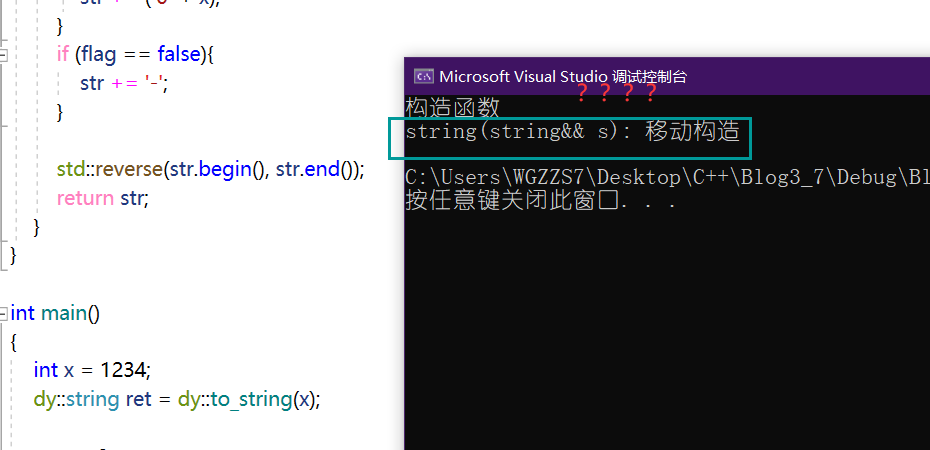
这是为什么??该对象的"拷贝"没有选择去调用"深拷贝"?那么,我们不得不搞懂以下的三个问题!
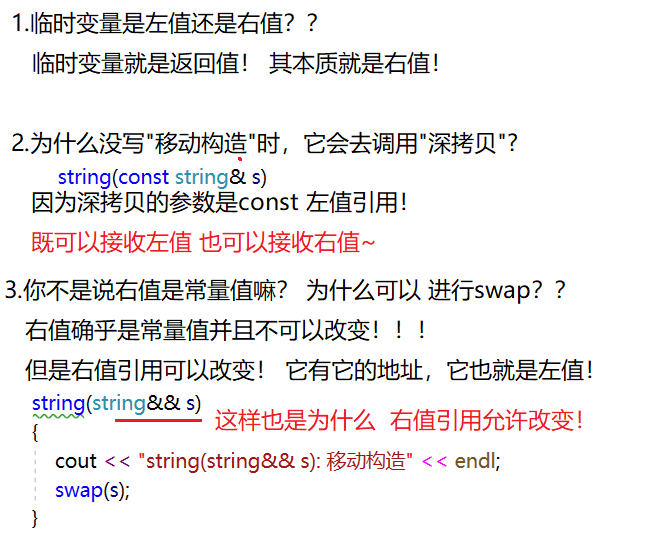
能够搞懂上述的问题,我们也就能够预知编译器会选择怎样做。
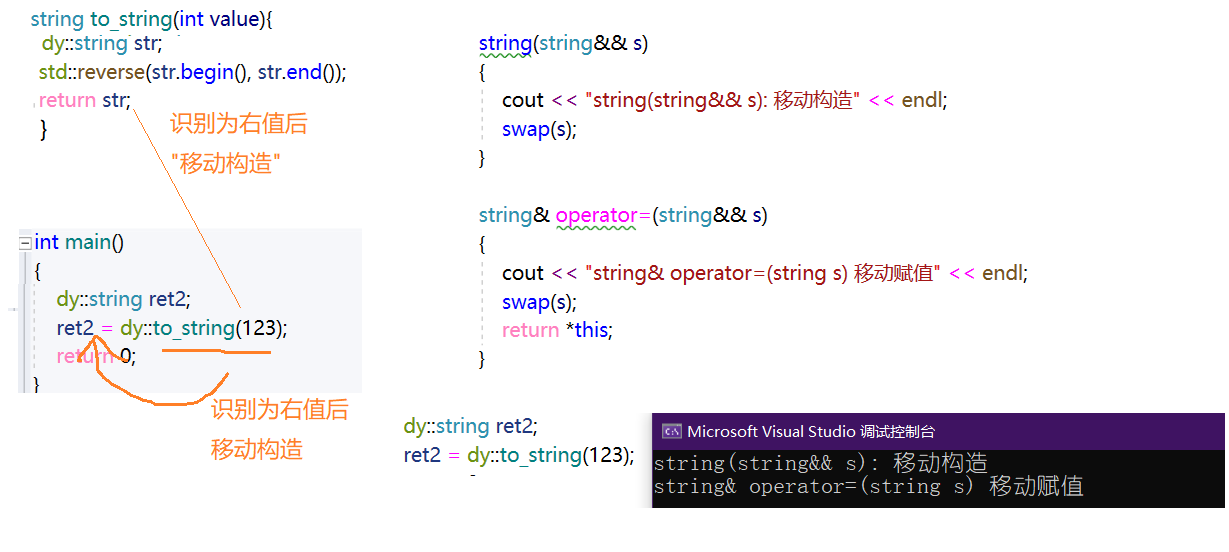
那如果是以下这样的调用,会打印出什么呢?
int main()
{
dy::string ret2;
ret2 = dy::to_string(123);
return 0;
}
小结:
左值引用与右值引用减少拷贝的方式是不一样的:
左值引用是直接起作用的,就是给一个变量取别名。
右值引用是间接起作用的,利用移动构造、移动赋值 实现的是一种资源的转移。而被转移的资源也叫做 "将亡值"。也就是出了这个作用域,就会销毁的对象。
四、左右值引用的其他应用
(1)完美转发
在前文已经提到过,一旦给右值取别名时,那么该右值引用名义上虽然是右值的别名,但本质是一个可以取地址、甚至可以改变的左值。我们来看看如下的代码。
void Func(int& x)
{
cout << "左值引用" << endl;
}
void Func(int&& x)
{
cout << "右值引用" << endl;
}
void GetFunc(int&& x)
{
Func(x);
}
int main()
{
int a = 10;
GetFunc(10);
return 0;
}唔,我们分别重载了两个函数Func,一个是用来接收左值引用的、一个是来接收右值引用的,我们传进来的是一个右值10,那么很显然调用后打印的是 "右值引用"。
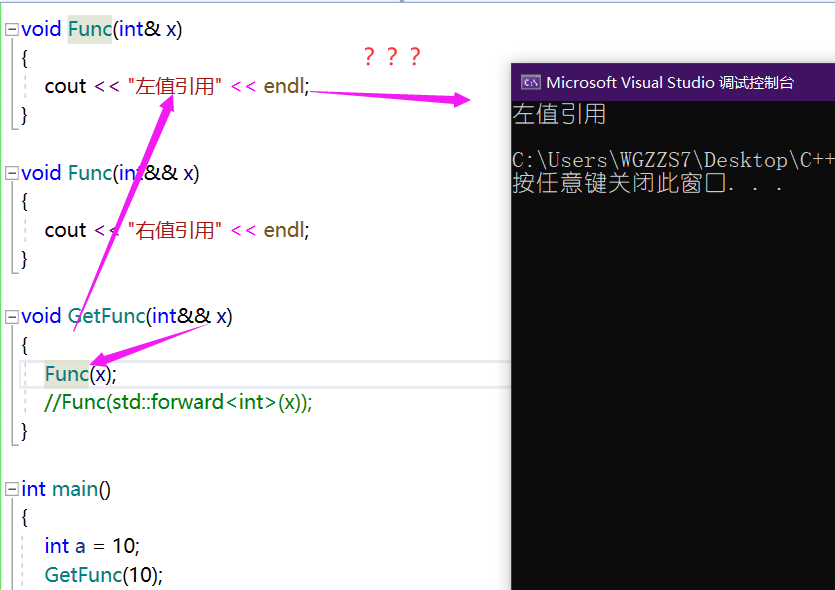
当右值引用作为参数时,虽然名义上接收的是右值,但是向下传递时,已经改变为了左值。但是我们就想让它保持原有的属性。
C++库中给提供了一个函数转发
std::forward<type>();
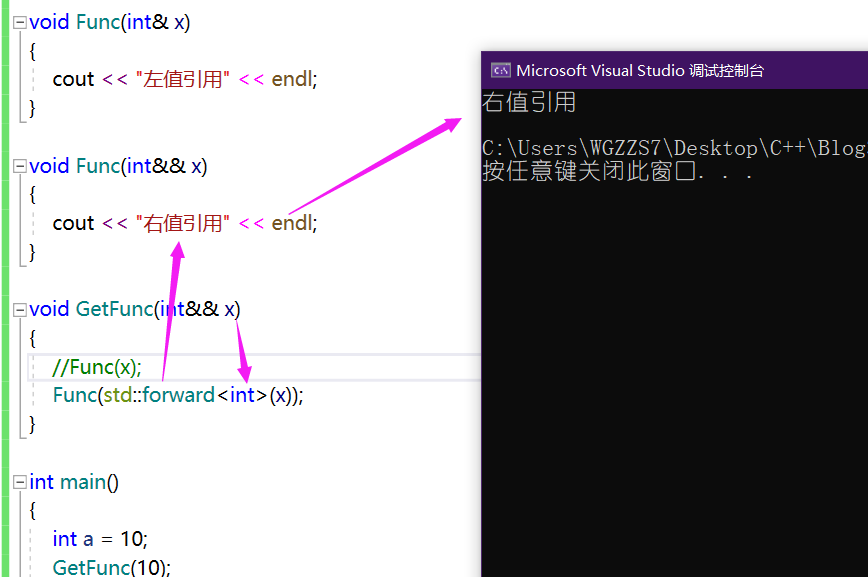
我们也就可以看到如我们的预期结果。
(2)万能引用
函数参数有左值引用、也有右值引用,C++中也有模板,那是否模板也有模板左值引用与模板右值引用呢? 是的!
template<class T>
void PerfectFunc(T& x)
{
Func(x);
}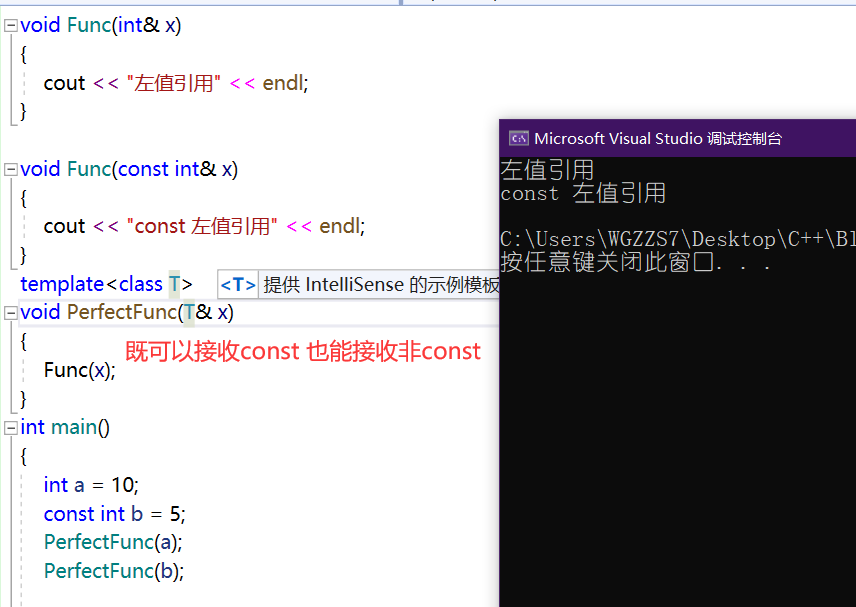
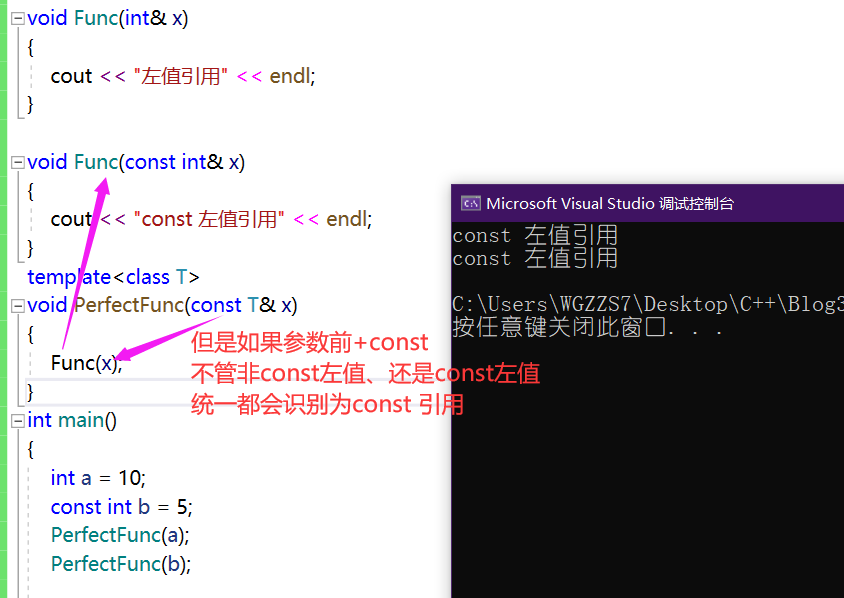
template<class T>
void PerfectFunc(const T& x)
{
Func(x);
}
但其实这都用得不多。因为接下来的操作可能会惊掉你的下把。
template<class T>
void PerfectFunc(T&& x)
{
Func(x);
}
这什么鬼???
在有模板的情况下;
template<class T>
void Func(T&& ..);
就叫做 "万能引用!"
当然,如果你没好好阅读上文,你可能还会惊奇,为什么只会调用左值引用与const左值引用。我们只需要让向下传入的值保持原属性即可。

由此可见,我们能万能引用的情况下,肯定不会去选择"T&"这单调的左值引用参数。
总结:
①左右值区分的最根本方法是,能否取地址,能否使用它的空间。
②左值引用只能引用左值,右值引用只能引用右值。但是const 左值引用可以引用左值 也可以引用右值。
③右值一定没有地址并且不能修改,但是右值引用有它自己的地址,非const可以进行修改。
④左值引用的防拷贝方式更加直接显著。右值引用防拷贝的方式是间接的,也叫"资源转移"。
⑤std::move()可以将一个左值变为右值。std::forward<T>()能保持参数的原属性。
本篇到此结束,感谢你的阅读。
祝你好运,向阳而生~










![[入门必看]数据结构1.1:数据结构的基本概念](https://img-blog.csdnimg.cn/c3dbbca0e18a4064be7335cd61b266a2.png#pic_center)