https://www.bilibili.com/video/BV1g84y147sX/?p=126&spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=51f694f71c083955be7443b1d75165e0
一、概述
Explain呈现的执行计划,由一系列Stage组成,这一系列Stage具有依赖关系,每个Stage对应一个Mapreduce Job,或者一个文件系统的操作(select *、load,这种不走MR)。
若某个Stage对应一个MapReduce,其Map端和Reduce端的计算逻辑分别由Map Operator Tree(Map操作树)和Reduce Operator Tree(Reduce操作树)进行描述,Operator Tree由一系列的Operator组成,一个Oprator代表在Map或Reduce阶段的一个单一的逻操作。
常见的Operator如下
TableScan:表扫描操作,通常map端第一个操作肯定是扫描操作
Select Operator:选取操作
Group By Operator:分组聚合操作
Reduce Output Operator:输出到reduce操作
Filter Operator:过滤操作,如where、having
Join Oprator:jojn操作
File Output Operator:文件输出操作,输出到hdfs的临时文件
Fetch Operator:客户端获取数据操作。正常我们写一个select的sql,
就将结果写在hdfs的一个临时目录MR正常就是从hdfs读数据,并将结果写入hdfs,
如果idea展示数据,需要把这个临时文件拉过来查看,这个操作就是fetch.下图是由一个执行计划绘制而成:
explain select
zheng_shi_indicator,
count(*)
from
test.test_formal_edu
group by zheng_shi_indicator
二、基本语法
explain [formatted、extended、dependency] 查询语句
注:formatted、extended、dependency关键字为可选项,各自作用如下:
formatted:将执行计划以json串的形式输出
extended:输出执行计划中的额外信息,通常是读写的临时文件名等信息
dependency:输出sql读取的表和分区(不常用)三、例子
1、SQL
explain select
zheng_shi_indicator,
count(*)
from
test.test_formal_edu
group by zheng_shi_indicator
2、如何看执行计划
从底层Stage看
Stage中先看Map Operator Tree,再看Reduce Operator Tree
操作树中一个Operator一个Operator的看,从上往下看
3、执行计划
STAGE DEPENDENCIES:--stage间的依赖关系
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1 --stage0依赖于stage1
--顺序是stage1、stage0
STAGE PLANS:--每个stage具体的计划
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan --读表
alias: test_formal_edu --要扫描的表名,下面的信息是该表的数据量和行数,不知道为什么行数是1
Statistics: Num rows: 1 Data size: 3119547392 Basic stats: COMPLETE Column stats: NONE
--sql还没跑怎么知道是多少行?
Select Operator --选取字段,根据sql语句找到需要的字段
expressions: zheng_shi_indicator (type: string)
outputColumnNames: zheng_shi_indicator
Statistics: Num rows: 1 Data size: 3119547392 Basic stats: COMPLETE Column stats: NONE
Group By Operator --可以看到在map端就已经在做group by操作了即map端聚合
aggregations: count() --聚合函数是什么
keys: zheng_shi_indicator (type: string) --分组的key
mode: hash --hash模式
outputColumnNames: _col0, _col1 --输出两个字端
Statistics: Num rows: 1 Data size: 3119547392 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator --输出到reduce的操作
key expressions: _col0 (type: string)
sort order: + --shuffle时进行排序
--一个+表示按照一个分区字段进行升序排序 两个+号表示按照两个分区字段进行升序排序
--一个+一个-表示按照第一个字段升序排序,按照第二个字段降序排序
Map-reduce partition columns: _col0 (type: string) --按照第一个字段进行分区
Statistics: Num rows: 1 Data size: 3119547392 Basic stats: COMPLETE Column stats: NONE
value expressions: _col1 (type: bigint)
Execution mode: vectorized
Reduce Operator Tree:--Reduce操作树
Group By Operator
aggregations: count(VALUE._col0)
keys: KEY._col0 (type: string)
mode: mergepartial --部分合并,将每个map各自聚合后的结果进行汇总聚合
outputColumnNames: _col0, _col1
Statistics: Num rows: 1 Data size: 3119547392 Basic stats: COMPLETE Column stats: NONE
File Output Operator --将最终的计算结果输出到hdfs
compressed: false
Statistics: Num rows: 1 Data size: 3119547392 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator --客户端获取数据的操作
limit: -1
Processor Tree:
ListSink
4、图
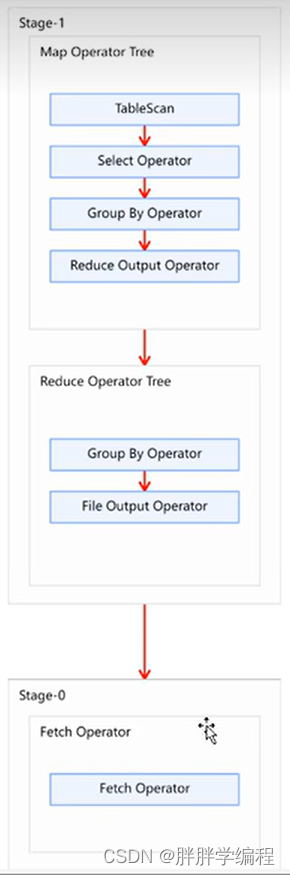
说明
1、Stage1:有Map也有Reduce所以是一个MR
1)Map Operator Tree:描述Map端的具体操作,有如下操作
①tablescan:读表
②select operator:select
③group by operator:group by
④reduce output operator(往reduce发送数据)
2)Reduce Operator Tree:描述Reduce端的具体操作
①Group By Operator:group by
②File Output Operator:输出最终结果到hdfs的临时文件中
Stage0:只有Map。Fetch Operator客户端拉取操作)