前言:
这篇文章完全是为新手准备的。我们会通过用Python从头实现一个神经网络来理解神经网络的原理。
文章目录
- 神经元
- 1、一个简单的例子
- 2、编码一个神经元
- 把神经元组装成网络
- 1、例子:前馈
- 2、编码神经网络:前馈
- 训练神经网络 第一部分
- 1、损失
- 2、损失计算例子
- 3、代码:MSE损失
- 训练神经网络 第二部分
- 1、例子:计算偏导数
- 2、训练:随机梯度下降
- 代码:一个完整的神经网络
神经元
首先让我们看看神经网络的基本单位,神经元。神经元接受输入,对其做一些数据操作,然后产生输出。例如,这是一个2-输入神经元:
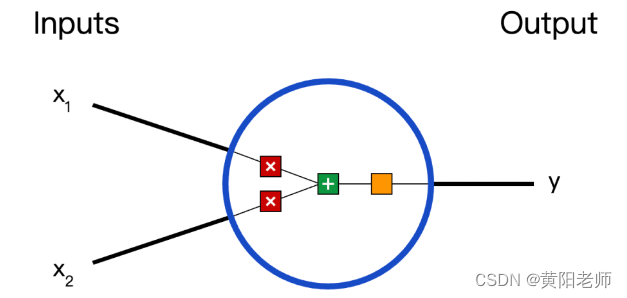
这里发生了三个事情。首先,每个输入都跟一个权重相乘(红色):
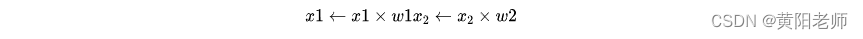 然后,加权后的输入求和,加上一个偏差b(绿色):
然后,加权后的输入求和,加上一个偏差b(绿色):
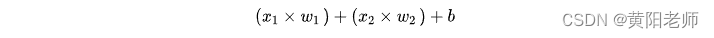
最后,这个结果传递给一个激活函数f:
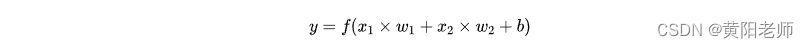
激活函数的用途是将一个无边界的输入,转变成一个可预测的形式。常用的激活函数就是S型函数:
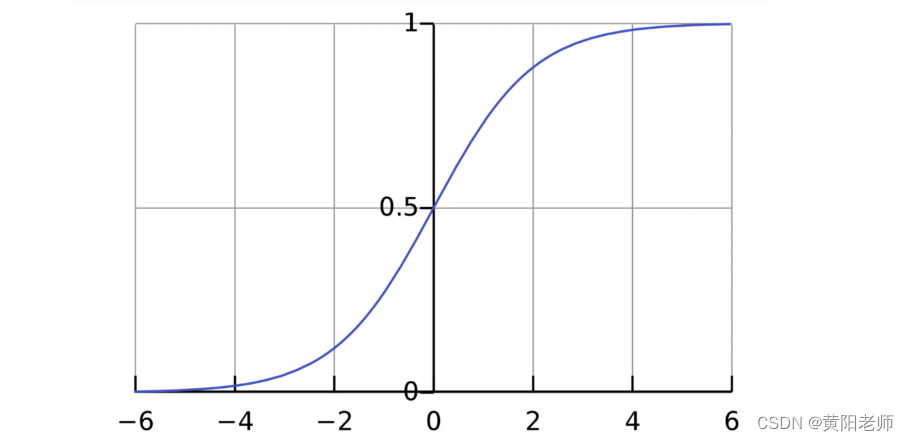
S型函数的值域是(0, 1)。简单来说,就是把(−∞, +∞)压缩到(0, 1) ,很大的负数约等于0,很大的正数约等于1。
1、一个简单的例子

2、编码一个神经元
让我们来实现一个神经元!用Python的NumPy库来完成其中的数学计算:
import numpy as np
def sigmoid(x):
# 我们的激活函数: f(x) = 1 / (1 + e^(-x))
return 1 / (1 + np.exp(-x))
class Neuron:
def __init__(self, weights, bias):
self.weights = weights
self.bias = bias
def feedforward(self, inputs):
# 加权输入,加入偏置,然后使用激活函数
total = np.dot(self.weights, inputs) + self.bias
return sigmoid(total)
weights = np.array([0, 1]) # w1 = 0, w2 = 1
bias = 4 # b = 4
n = Neuron(weights, bias)
x = np.array([2, 3]) # x1 = 2, x2 = 3
print(n.feedforward(x)) # 0.9990889488055994
还记得这个数字吗?就是我们前面算出来的例子中的0.999。
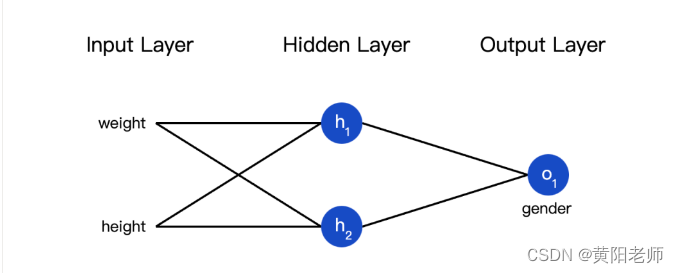
把神经元组装成网络
所谓的神经网络就是一堆神经元。这就是一个简单的神经网络:
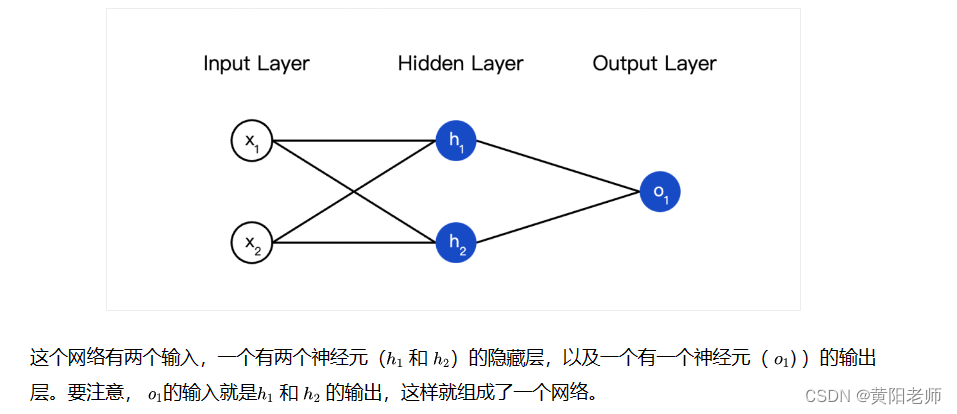
隐藏层就是输入层和输出层之间的层,隐藏层可以是多层的。
1、例子:前馈

2、编码神经网络:前馈
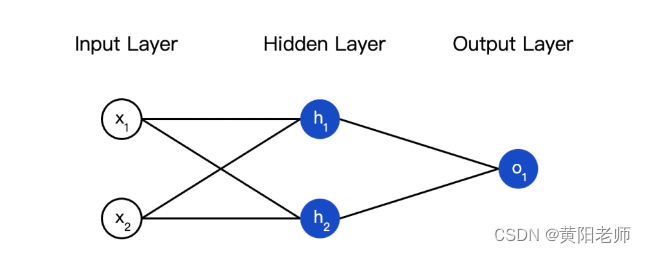
接下来我们实现这个神经网络的前馈机制,还是这个图:
import numpy as np
def sigmoid(x):
# 我们的激活函数:f(x)=1/(1+e^(-x))
return 1/(1+np.exp(-x))
# 单个神经元
class Neuron:
def __init__(self,weights,bias):
self.weights=weights
self.bias=bias
def feedforward(self,inputs):
total=np.dot(self.weights,inputs)+self.bias
return sigmoid(total)
class OurNeuralNetwork:
'''
A neural network with:
- 2 inputs
- a hidden layer with 2 neurons (h1, h2)
- an output layer with 1 neuron (o1)
Each neuron has the same weights and bias:
- w = [0, 1]
- b = 0
'''
def __init__(self):
weights = np.array([0, 1])
bias = 0
# 这里是来自前一节的神经元类
self.h1 = Neuron(weights, bias)
self.h2 = Neuron(weights, bias)
self.o1 = Neuron(weights, bias)
def feedforward(self, x):
out_h1 = self.h1.feedforward(x)
out_h2 = self.h2.feedforward(x)
# o1的输入是h1和h2的输出
out_o1 = self.o1.feedforward(np.array([out_h1, out_h2]))
return out_o1
network = OurNeuralNetwork()
x = np.array([2, 3])
print(network.feedforward(x)) # 0.7216325609518421
结果正确,看上去没问题。
训练神经网络 第一部分
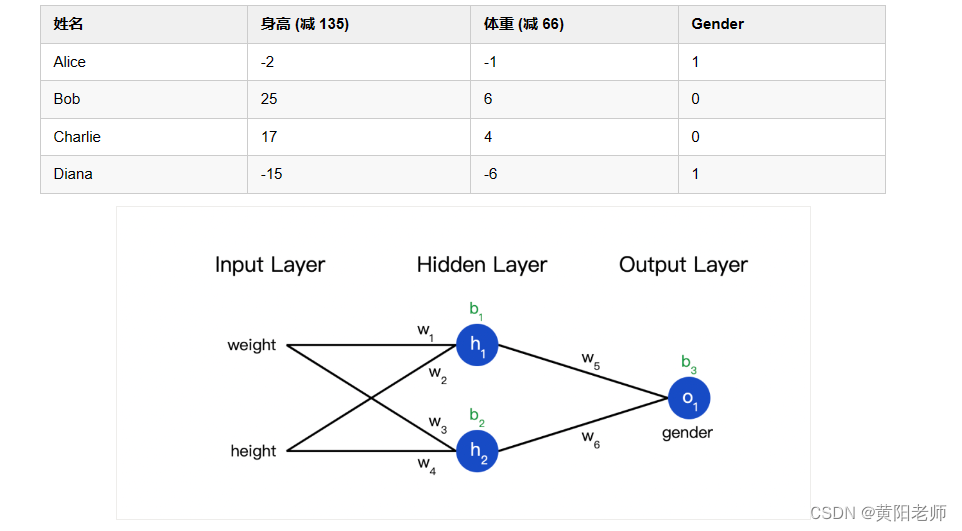
现在有这样的数据:
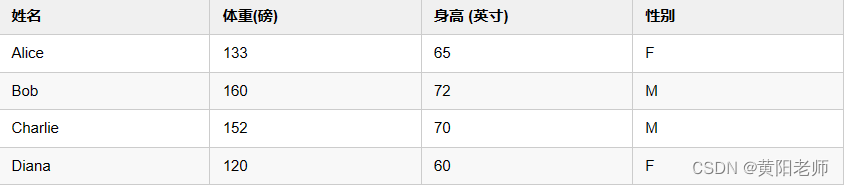
接下来我们用这个数据来训练神经网络的权重和截距项,从而可以根据身高体重预测性别:
我们用0和1分别表示男性(M)和女性(F),并对数值做了转化:
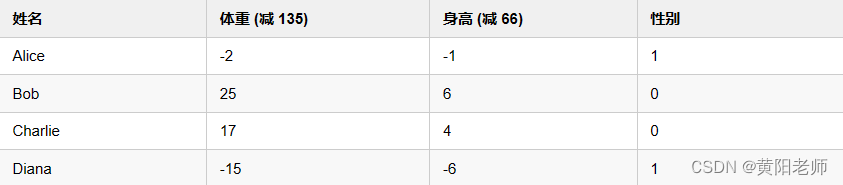
我这里是随意选取了135和66来标准化数据,通常会使用平均值。
1、损失
在训练网络之前,我们需要量化当前的网络是『好』还是『坏』,从而可以寻找更好的网络。这就是定义损失的目的。
我们在这里用平均方差(MSE)损失: ,让我们仔细看看:


被称为方差(squared error)。我们的损失函数就是所有方差的平均值。预测效果越好,损失就越少。
更好的预测 = 更少的损失!
训练网络 = 最小化它的损失。
2、损失计算例子
假设我们的网络总是输出0,换言之就是认为所有人都是男性。损失如何?

3、代码:MSE损失
下面是计算MSE损失的代码:
import numpy as np
def mse_loss(y_true, y_pred):
# y_true and y_pred are numpy arrays of the same length.
return ((y_true - y_pred) ** 2).mean()
y_true = np.array([1, 0, 0, 1])
y_pred = np.array([0, 0, 0, 0])
print(mse_loss(y_true, y_pred)) # 0.5
如果你不理解这段代码,可以看看NumPy的快速入门中关于数组的操作。
好的,继续。
训练神经网络 第二部分
现在我们有了一个明确的目标:最小化神经网络的损失。通过调整网络的权重和截距项,我们可以改变其预测结果,但如何才能逐步地减少损失?
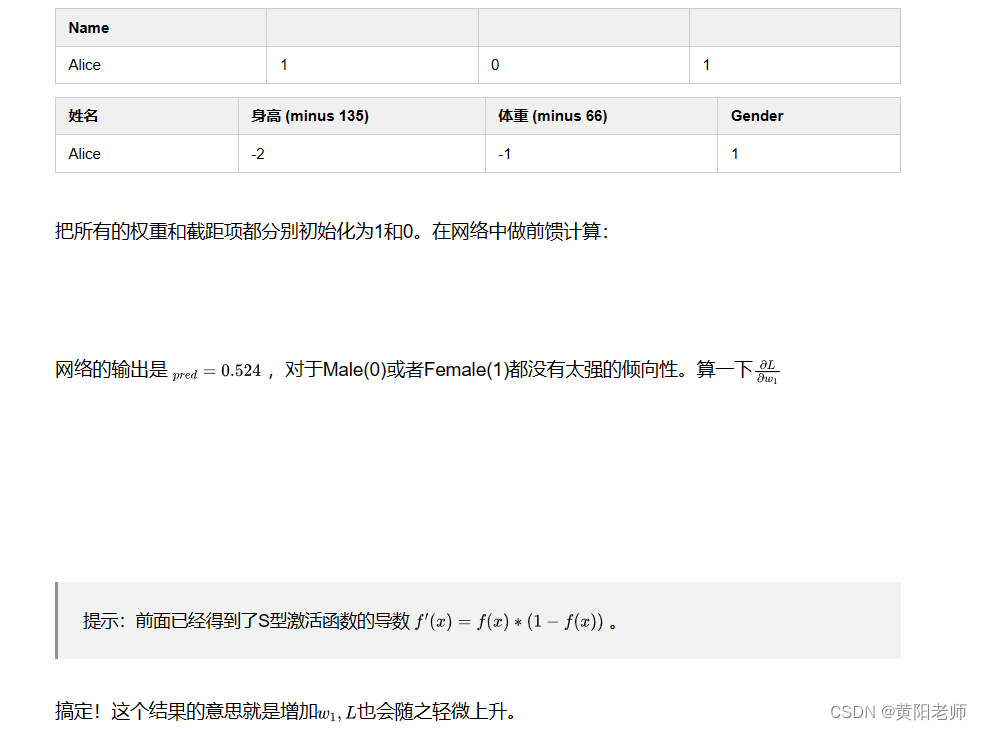
为了简化问题,假设我们的数据集中只有Alice:假设我们的网络总是输出0,换言之就是认为所有人都是男性。损失如何?

那均方差损失就只是Alice的方差:
也可以把损失看成是权重和截距项的函数。让我们给网络标上权重和截距项:
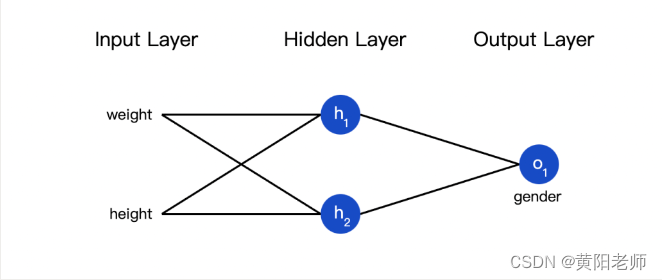
这样我们就可以把网络的损失表示为:

1、例子:计算偏导数
我们还是看数据集中只有Alice的情况:
2、训练:随机梯度下降
现在训练神经网络已经万事俱备了!我们会使用名为随机梯度下降法的优化算法来优化网络的权重和截距项,实现损失的最小化。核心就是这个更新公式:

代码:一个完整的神经网络
我们终于可以实现一个完整的神经网络了:
import numpy as np
def sigmoid(x):
# Sigmoid activation function: f(x) = 1 / (1 + e^(-x))
return 1 / (1 + np.exp(-x))
def deriv_sigmoid(x):
# Derivative of sigmoid: f'(x) = f(x) * (1 - f(x))
fx = sigmoid(x)
return fx * (1 - fx)
def mse_loss(y_true, y_pred):
# y_true和y_pred是相同长度的numpy数组。
return ((y_true - y_pred) ** 2).mean()
class OurNeuralNetwork:
'''
A neural network with:
- 2 inputs
- a hidden layer with 2 neurons (h1, h2)
- an output layer with 1 neuron (o1)
*** 免责声明 ***:
下面的代码是为了简单和演示,而不是最佳的。
真正的神经网络代码与此完全不同。不要使用此代码。
相反,读/运行它来理解这个特定的网络是如何工作的。
'''
def __init__(self):
# 权重,Weights
self.w1 = np.random.normal()
self.w2 = np.random.normal()
self.w3 = np.random.normal()
self.w4 = np.random.normal()
self.w5 = np.random.normal()
self.w6 = np.random.normal()
# 截距项,Biases
self.b1 = np.random.normal()
self.b2 = np.random.normal()
self.b3 = np.random.normal()
def feedforward(self, x):
# X是一个有2个元素的数字数组。
h1 = sigmoid(self.w1 * x[0] + self.w2 * x[1] + self.b1)
h2 = sigmoid(self.w3 * x[0] + self.w4 * x[1] + self.b2)
o1 = sigmoid(self.w5 * h1 + self.w6 * h2 + self.b3)
return o1
def train(self, data, all_y_trues):
'''
- data is a (n x 2) numpy array, n = # of samples in the dataset.
- all_y_trues is a numpy array with n elements.
Elements in all_y_trues correspond to those in data.
'''
learn_rate = 0.1
epochs = 1000 # 遍历整个数据集的次数
for epoch in range(epochs):
for x, y_true in zip(data, all_y_trues):
# --- 做一个前馈(稍后我们将需要这些值)
sum_h1 = self.w1 * x[0] + self.w2 * x[1] + self.b1
h1 = sigmoid(sum_h1)
sum_h2 = self.w3 * x[0] + self.w4 * x[1] + self.b2
h2 = sigmoid(sum_h2)
sum_o1 = self.w5 * h1 + self.w6 * h2 + self.b3
o1 = sigmoid(sum_o1)
y_pred = o1
# --- 计算偏导数。
# --- Naming: d_L_d_w1 represents "partial L / partial w1"
d_L_d_ypred = -2 * (y_true - y_pred)
# Neuron o1
d_ypred_d_w5 = h1 * deriv_sigmoid(sum_o1)
d_ypred_d_w6 = h2 * deriv_sigmoid(sum_o1)
d_ypred_d_b3 = deriv_sigmoid(sum_o1)
d_ypred_d_h1 = self.w5 * deriv_sigmoid(sum_o1)
d_ypred_d_h2 = self.w6 * deriv_sigmoid(sum_o1)
# Neuron h1
d_h1_d_w1 = x[0] * deriv_sigmoid(sum_h1)
d_h1_d_w2 = x[1] * deriv_sigmoid(sum_h1)
d_h1_d_b1 = deriv_sigmoid(sum_h1)
# Neuron h2
d_h2_d_w3 = x[0] * deriv_sigmoid(sum_h2)
d_h2_d_w4 = x[1] * deriv_sigmoid(sum_h2)
d_h2_d_b2 = deriv_sigmoid(sum_h2)
# --- 更新权重和偏差
# Neuron h1
self.w1 -= learn_rate * d_L_d_ypred * d_ypred_d_h1 * d_h1_d_w1
self.w2 -= learn_rate * d_L_d_ypred * d_ypred_d_h1 * d_h1_d_w2
self.b1 -= learn_rate * d_L_d_ypred * d_ypred_d_h1 * d_h1_d_b1
# Neuron h2
self.w3 -= learn_rate * d_L_d_ypred * d_ypred_d_h2 * d_h2_d_w3
self.w4 -= learn_rate * d_L_d_ypred * d_ypred_d_h2 * d_h2_d_w4
self.b2 -= learn_rate * d_L_d_ypred * d_ypred_d_h2 * d_h2_d_b2
# Neuron o1
self.w5 -= learn_rate * d_L_d_ypred * d_ypred_d_w5
self.w6 -= learn_rate * d_L_d_ypred * d_ypred_d_w6
self.b3 -= learn_rate * d_L_d_ypred * d_ypred_d_b3
# --- 在每次epoch结束时计算总损失
if epoch % 10 == 0:
y_preds = np.apply_along_axis(self.feedforward, 1, data)
loss = mse_loss(all_y_trues, y_preds)
print("Epoch %d loss: %.3f" % (epoch, loss))
# 定义数据集
data = np.array([
[-2, -1], # Alice
[25, 6], # Bob
[17, 4], # Charlie
[-15, -6], # Diana
])
all_y_trues = np.array([
1, # Alice
0, # Bob
0, # Charlie
1, # Diana
])
# 训练我们的神经网络!
network = OurNeuralNetwork()
network.train(data, all_y_trues)
随着网络的学习,损失在稳步下降。
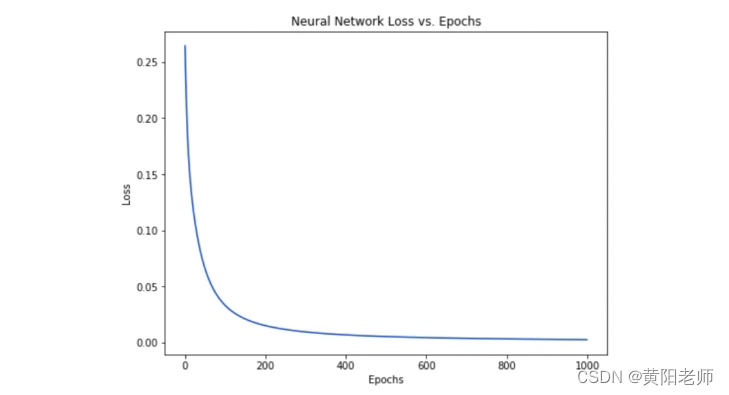
现在我们可以用这个网络来预测性别了:
# 做一些预测
emily = np.array([-7, -3]) # 128 磅, 63 英寸
frank = np.array([20, 2]) # 155 磅, 68 英寸
print("Emily: %.3f" % network.feedforward(emily)) # 0.951 - F
print("Frank: %.3f" % network.feedforward(frank)) # 0.039 - M
把这段代码插入到上述完整的神经网络代码中:
import numpy as np
def sigmoid(x):
# Sigmoid激活函数:f(x)=1/(1+e^(-x))
return 1/(1+np.exp(-x))
def deriv_sigmoid(x):
# Derivative of sigmoid: f'(x)=f(x)*(1-f(x))
fx=sigmoid(x)
return fx*(1-fx)
def mse_loss(y_true,y_pred):
# y_true和y_pred是相同长度的numpy数组
return ((y_true-y_pred)**2).mean()
class OurNeuralNetwork:
'''
A neural network with:
- 2 inputs
- a hidden layer with 2 neurons (h1, h2)
- an output layer with 1 neuron (o1)
*** 免责声明 ***:
下面的代码是为了简单和演示,而不是最佳的。
真正的神经网络代码与此完全不同。不要使用此代码。
相反,读/运行它来理解这个特定的网络是如何工作的。
'''
def __init__(self):
# 权重,Weights
self.w1=np.random.normal()
self.w2=np.random.normal()
self.w3=np.random.normal()
self.w4=np.random.normal()
self.w5=np.random.normal()
self.w6=np.random.normal()
# 截距项 Biaes
self.b1=np.random.normal()
self.b2=np.random.normal()
self.b3=np.random.normal()
def feedforward(self,x):
# X是一个有2个元素的数组。
h1=sigmoid(self.w1 * x[0] + self.w2 * x[1] + self.b1)
h2=sigmoid(self.w3*x[0]+self.w4*x[1]+self.b2)
o1=sigmoid(self.w5*h1+self.w6*h2+self.b3)
return o1
def train(self,data,all_y_trues):
'''
- data is a(nx2)numpy array,n=#of samples in the dataset.
- all_y_trues is a numpy array with n elements
Elements in all_y_trues correspond to those in data.
'''
learn_rate=0.1
epochs=1000 #遍历整个数组的次数
for epoch in range(epochs):
for x,y_true in zip(data,all_y_trues):
# ---做一个前馈(稍后我们将需要这些值)
sum_h1=self.w1*x[0]+self.w2*x[1]+self.b1
h1=sigmoid(sum_h1)
sum_h2 = self.w3 * x[0] + self.w4 * x[1] + self.b2
h2 = sigmoid(sum_h2)
sum_o1 = self.w5 * h1 + self.w6 * h2 + self.b3
o1 = sigmoid(sum_o1)
y_pred=o1
# ---计算偏导数
# ---Naming:d_L_d_w1 represents "partial L/partial w1"
d_L_d_ypred=-2*(y_true-y_pred)
# Neuron o1
d_ypred_d_w5 = h1*deriv_sigmoid(sum_o1)
d_ypred_d_w6 = h2 * deriv_sigmoid(sum_o1)
d_ypred_d_b3 = deriv_sigmoid(sum_o1)
d_ypred_d_h1=self.w5* deriv_sigmoid(sum_o1)
d_ypred_d_h2=self.w6 * deriv_sigmoid(sum_o1)
# Neuron h1
d_h1_d_w1=x[0]*deriv_sigmoid(sum_h1)
d_h1_d_w2=x[1]*deriv_sigmoid(sum_h1)
d_h1_d_b1=deriv_sigmoid(sum_h1)
# Neuron h2
d_h2_d_w3 = x[0] * deriv_sigmoid(sum_h2)
d_h2_d_w4 = x[1] * deriv_sigmoid(sum_h2)
d_h2_d_b2 = deriv_sigmoid(sum_h2)
# --- 更新权重和偏差
# Neuron h1
self.w1 -=learn_rate*d_L_d_ypred*d_ypred_d_h1*d_h1_d_w1
self.w2 -= learn_rate * d_L_d_ypred * d_ypred_d_h1 * d_h1_d_w2
self.b1 -= learn_rate * d_L_d_ypred * d_ypred_d_h1 * d_h1_d_b1
# Neuron h2
self.w3 -= learn_rate * d_L_d_ypred * d_ypred_d_h2 * d_h2_d_w3
self.w4 -= learn_rate * d_L_d_ypred * d_ypred_d_h2 * d_h2_d_w4
self.b2 -= learn_rate * d_L_d_ypred * d_ypred_d_h2 * d_h2_d_b2
# Neuron o1
self.w5 -= learn_rate * d_L_d_ypred * d_ypred_d_w5
self.w6 -= learn_rate * d_L_d_ypred * d_ypred_d_w6
self.b3 -= learn_rate * d_L_d_ypred * d_ypred_d_b3
# --- 在每次epoch结束时计算总损失
if epoch % 10==0:
y_preds=np.apply_along_axis(self.feedforward, 1, data)
loss=mse_loss(all_y_trues, y_preds)
print("Epoch %d loss: %.3f"%(epoch,loss))
# 定义数据集
data=np.array([
[-2,1],#Alice
[25,6],#Bob
[17,4],#Charlie
[-15,-6],#Diana
])
all_y_trues=np.array([
1,#Alice
0,#Bob
0,#Charlie
1,#Diana
])
network=OurNeuralNetwork()
#训练我们的神经网络
network.train(data, all_y_trues)
#做一些预测
emily=np.array([-7,-3])#128磅,63英寸
frank=np.array([20,2])#155磅,68英寸
print("Emily:%.3f"%network.feedforward(emily))
print("Emily:%.3f"%network.feedforward(frank))
以上代码都可以直接运行