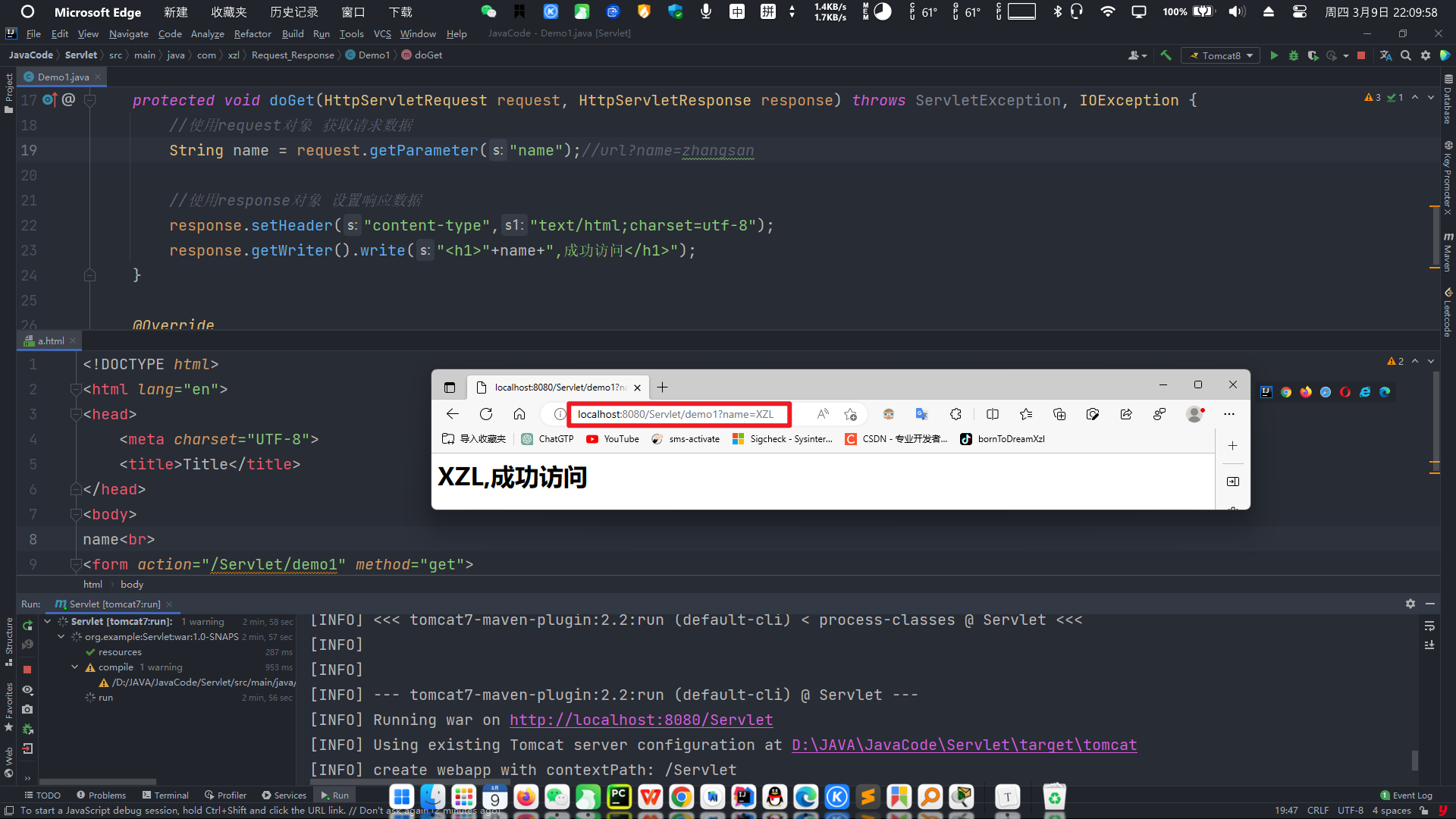
双 Value 类型
1、intersection(交集)
2、union(并集)
3、subtract(差集)
4、zip(拉链)
Key - Value 类型
1、partitionBy
2、reduceByKey
3、groupByKey
4、aggregateByKe
5、foldByKey
6、combineByKey
7、join
8、 leftOuterJoin
9、cogroup
双 Value 类型
1、intersection(交集)
对源 RDD 和参数 RDD 求交集后返回一个新的 RDD
def intersection(other: RDD[T]): RDD[T]val dataRDD1 = sc.makeRDD(List(1,2,3,4))
val dataRDD2 = sc.makeRDD(List(3,4,5,6))
val dataRDD = dataRDD1.intersection(dataRDD2)2、union(并集)
对源 RDD 和参数 RDD 求并集后返回一个新的 RDD
def union(other: RDD[T]): RDD[T]
val dataRDD1 = sc.makeRDD(List(1,2,3,4))
val dataRDD2 = sc.makeRDD(List(3,4,5,6))
val dataRDD = dataRDD1.union(dataRDD2)3、subtract(差集)
以一个 RDD 元素为主,去除两个 RDD 中重复元素,将其他元素保留下来。求差集
def subtract(other: RDD[T]): RDD[T]
val dataRDD1 = sc.makeRDD(List(1,2,3,4))
val dataRDD2 = sc.makeRDD(List(3,4,5,6))
val dataRDD = sc.subtract(dataRDD2)
4、zip(拉链)
将两个 RDD 中的元素,以键值对的形式进行合并。其中,键值对中的 Key 为第 1 个 RDD 中的元素,Value 为第 2 个 RDD 中的相同位置的元素。
要求两个数据源分区数量要保持一致
def zip[U: ClassTag](other: RDD[U]): RDD[(T, U)]
val dataRDD1 = sc.makeRDD(List(1,2,3,4))
val dataRDD2 = sc.makeRDD(List(3,4,5,6))
val dataRDD = dataRDD1.zip(dataRDD2)
println(dataRDD.collect.mkString(" "))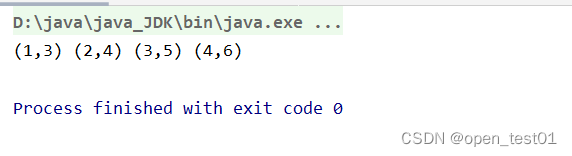
Key - Value 类型
1、partitionBy
将数据按照指定 Partitioner 重新进行分区。Spark 默认的分区器是 HashPartitioner
def partitionBy(partitioner: Partitioner): RDD[(K, V)]
def main(args: Array[String]): Unit = {
//准备环境
//"*"代表线程的核数 应用程序名称"RDD"
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
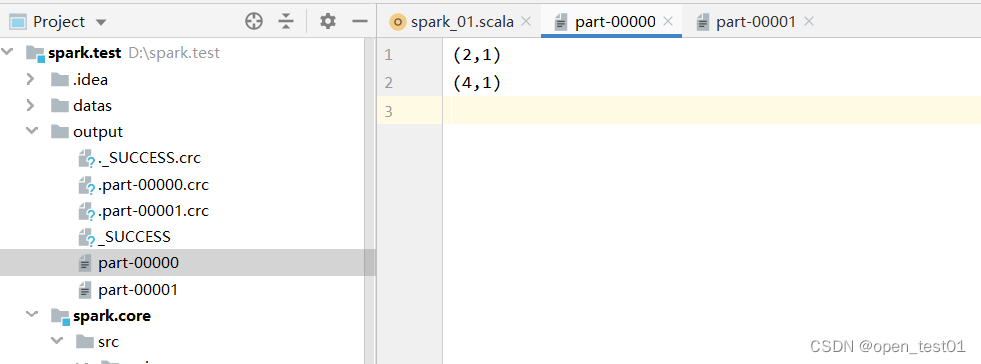
val rdd = sc.makeRDD(List(1,2,3,4),2)
val mapRDD: RDD[(Int, Int)] = rdd.map((_,1))
//partitionBy根据指定的分区规则对数据进行重新分区
mapRDD.partitionBy(new HashPartitioner(2)).saveAsTextFile("output")
//关闭环境
sc.stop()
}
2、reduceByKey
可以将数据按照相同的 Key 对 Value 进行聚合
def reduceByKey(func: (V, V) => V): RDD[(K, V)]
def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)] def main(args: Array[String]): Unit = {
//准备环境
//"*"代表线程的核数 应用程序名称"RDD"
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(("a",1),("a",2),("b",3),("b",4)))
//相同Key的数据进行value数据的聚合(两两聚合)
val rdRDD: RDD[(String, Int)] = rdd.reduceByKey((x:Int, y:Int)=> x+y)
rdRDD.collect().foreach(println)
//关闭环境
sc.stop()
}
3、groupByKey
将数据源的数据根据 key 对 value 进行分组
def groupByKey(): RDD[(K, Iterable[V])]
def groupByKey(numPartitions: Int): RDD[(K, Iterable[V])]
def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])]def main(args: Array[String]): Unit = {
//准备环境
//"*"代表线程的核数 应用程序名称"RDD"
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(("a",1),("a",2),("b",3),("b",4)))
//将数据源中相同Key的数据分在一个组中,形成一个对偶元组
//元组中第一个元素:Key ,元组中第二个元素:相同Key中相同Key的value的集合
val gpRDD: RDD[(String, Iterable[Int])] = rdd.groupByKey()
gpRDD.collect().foreach(println)
//关闭环境
sc.stop()
}
4、aggregateByKe
将数据根据不同的规则进行分区内计算和分区间计算
def aggregateByKey[U: ClassTag](zeroValue: U)(seqOp: (U, V) => U,
combOp: (U, U) => U): RDD[(K, U)]
def main(args: Array[String]): Unit = {
//准备环境
//"*"代表线程的核数 应用程序名称"RDD"
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(("a",1),("a",2),("a",3),("a",4)))
//将数据源中相同Key的数据分在一个组中,形成一个对偶元组
//元组中第一个元素:Key ,元组中第二个元素:相同Key中相同Key的value的集合
//存在柯里化 有两个参数 rdd.aggregate(初始值)(分区内计算规则,分区间计算规则)
//初始值:主要用于当碰见一个Key的时候 和value进行分区计算
rdd.aggregateByKey(0)(
(x,y) => math.max(x,y),
(x,y) => x + y
).collect().foreach(println)
//关闭环境
sc.stop()
}5、foldByKey
当分区内计算规则和分区间计算规则相同时,aggregateByKey 就可以简化为 foldByKey
def foldByKey(zeroValue: V)(func: (V, V) => V): RDD[(K, V)] def main(args: Array[String]): Unit = {
//准备环境
//"*"代表线程的核数 应用程序名称"RDD"
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(("a",1),("a",2),("a",3),("a",4)))
rdd.foldByKey(0)(_+_).collect().foreach(println)
//关闭环境
sc.stop()
}6、combineByKey
最通用的对 key-value 型 rdd 进行聚集操作的聚集函数(aggregation function)。类似于 aggregate(),combineByKey()允许用户返回值的类型与输入不一致。
def combineByKey[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C): RDD[(K, C)]
将数据 List(("a", 88), ("b", 95), ("a", 91), ("b", 93), ("a", 95), ("b", 98))求每个 key 的平 均值 :
def main(args: Array[String]): Unit = {
//准备环境
//"*"代表线程的核数 应用程序名称"RDD"
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(("a", 88), ("b", 95), ("a", 91), ("b", 93), ("a", 95), ("b", 98)))
//combineByKey(参数1:将相同key的第一个数据进行结构的转换实现操作 ,参数2:分区内计算规则 ,参数3:分区间计算规则)
rdd.combineByKey(
(_, 1),
(acc: (Int, Int), v) => (acc._1 + v, acc._2 + 1),
(acc1: (Int, Int), acc2: (Int, Int)) => (acc1._1 + acc2._1, acc1._2 + acc2._2)
).collect().foreach(println)
//关闭环境
sc.stop()
}7、join
在类型为(K,V)和(K,W)的 RDD 上调用,返回一个相同 key 对应的所有元素连接在一起的 (K,(V,W))的 RDD
def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))]
def main(args: Array[String]): Unit = {
//准备环境
//"*"代表线程的核数 应用程序名称"RDD"
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
val rdd1 = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3)))
val rdd2 = sc.makeRDD(List(("a", 4), ("b", 5), ("c", 6)))
//连接条件:Key需要相同
//如果两个数据源中没有相同Key元素,那么改数据不会出现在结果中
//如果两个数据源中Key有多个相同的数据,则会依次匹配,可能会出现笛卡尔乘积,数据量会几何性增长(导致性能降低)
val joinRDD: RDD[(String, (Int, Int))] = rdd1.join(rdd2)
joinRDD.collect().foreach(println)
//关闭环境
sc.stop()
}
8、 leftOuterJoin
类似于 SQL 语句的左外连接
def leftOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (V, Option[W]))]
def main(args: Array[String]): Unit = {
//准备环境
//"*"代表线程的核数 应用程序名称"RDD"
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
val rdd1 = sc.makeRDD(List(("a", 1), ("b", 2)))
val rdd2 = sc.makeRDD(List(("a", 4), ("b", 5), ("c", 6)))
val leftRDD: RDD[(String, (Int, Option[Int]))] = rdd1.leftOuterJoin(rdd2)
val rightRDD: RDD[(String, (Option[Int], Int))] = rdd1.rightOuterJoin(rdd2)
leftRDD.collect().foreach(println)
println("----------------------------------------")
rightRDD.collect().foreach(println)
//关闭环境
sc.stop()
}
9、cogroup
在类型为(K,V)和(K,W)的 RDD 上调用,返回一个(K,(Iterable,Iterable))类型的 RDD
def cogroup[W](other: RDD[(K, W)]): RDD[(K, (Iterable[V], Iterable[W]))]def main(args: Array[String]): Unit = {
//准备环境
//"*"代表线程的核数 应用程序名称"RDD"
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
val rdd1 = sc.makeRDD(List(("a", 1), ("b", 2)))
val rdd2 = sc.makeRDD(List(("a", 4), ("b", 5), ("c", 6)))
//connect + group = cogroup (分组与连接的概念)
val cRDD: RDD[(String, (Iterable[Int], Iterable[Int]))] = rdd1.cogroup(rdd2)
cRDD.collect().foreach(println)
//关闭环境
sc.stop()
}