目录
进程间通信目的
进程间通信标准
管道
匿名管道
管道实现进程间通信
管道的特点
进程池
ProcessPool.cc
Task.hpp
习题
进程间通信目的
数据传输:一个进程需要将它的数据发送给另一个进程
资源共享:多个进程之间共享同样的资源。
通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程)。
进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变
进程间通信不是目的,是手段。
技术背景
1.进程是具有独立性的,虚拟地址空间+页表保证进程允许的独立性(进程内核数据结构+进程的代码和数据)
2.通信成本会比较高
进程间通信的本质理解
1.进程间通信的前提,首先需要让不同的进程看到同一块“内存”(特定的结构组织的)
2.这个所谓的“内存”不属于任何一个进程,强调的是共享
进程间通信标准
1.Linux原生能提供——管道(匿名,命名)
2.SystemV——多进程——单机通信
SystemV有共享内存,消息队列,信号量
3.posix——多线程——网络通信
这些标准在使用者看来,都是接口上具有一定的规律。
管道
管道是Unix中最古老的进程间通信的形式。
我们把从一个进程连接到另一个进程的一个数据流称为一个“管道”
只要是管道就一定有出口和入口,但是出入口数量有n种可能,单向传输内容,管道是用来传资源的。计算机的设计者,设计了一种单向通信模式——管道。
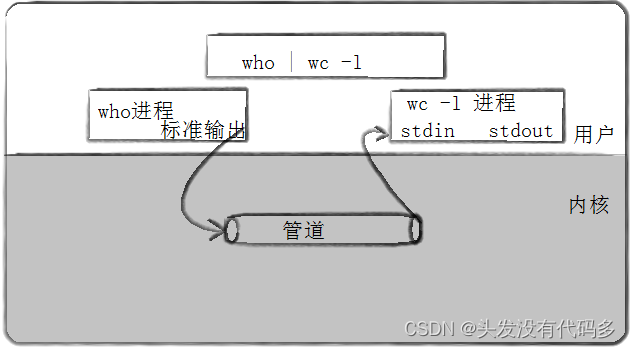
管道通信背后是进程之间通过管道进行通信
每个进程都有一个自己的文件描述符表,进程内部有files*指针,指向自己的文件描述符表,文件描述符表都有自己的数组下标,0,1,2是标准输入,标准输出,标准错误流,linux下一切皆文件,没个文件都有自己的struct_file结构,struct_file不仅包含inode属性,也包含文件对应的内核缓冲区,这个缓冲区在内核中对应的结构叫address_space
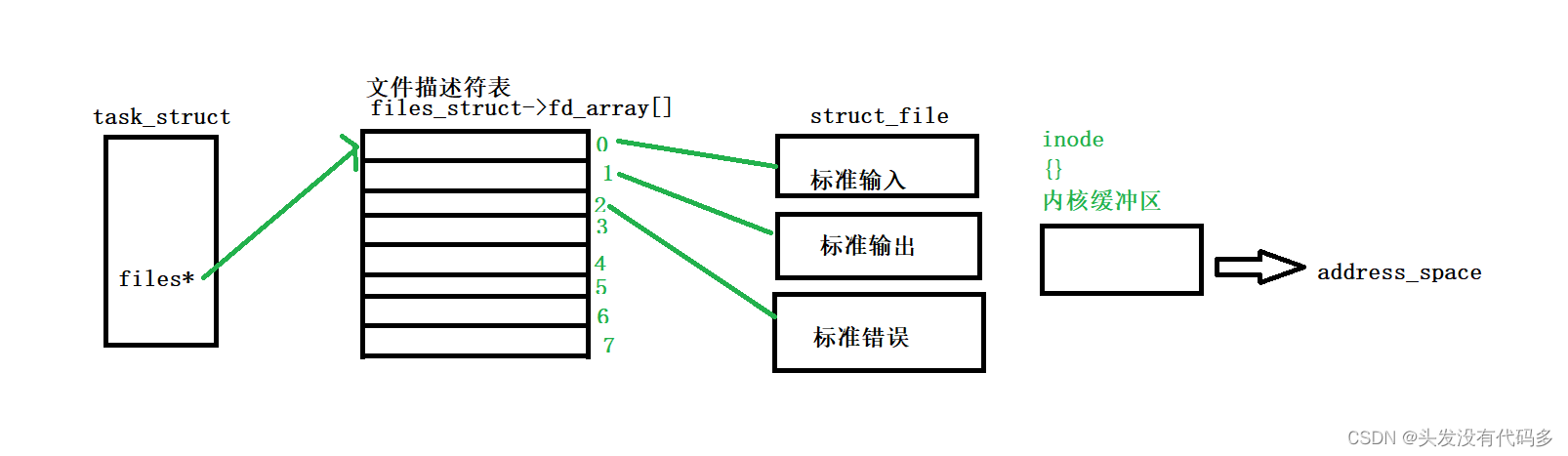
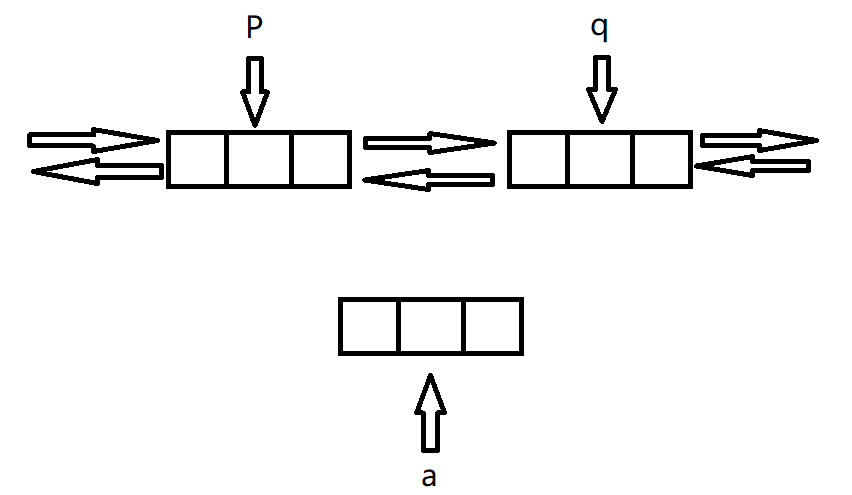
1. 我们以读和写的方式打开同一个文件,给父进程返回的时候会返回俩个文件描述符
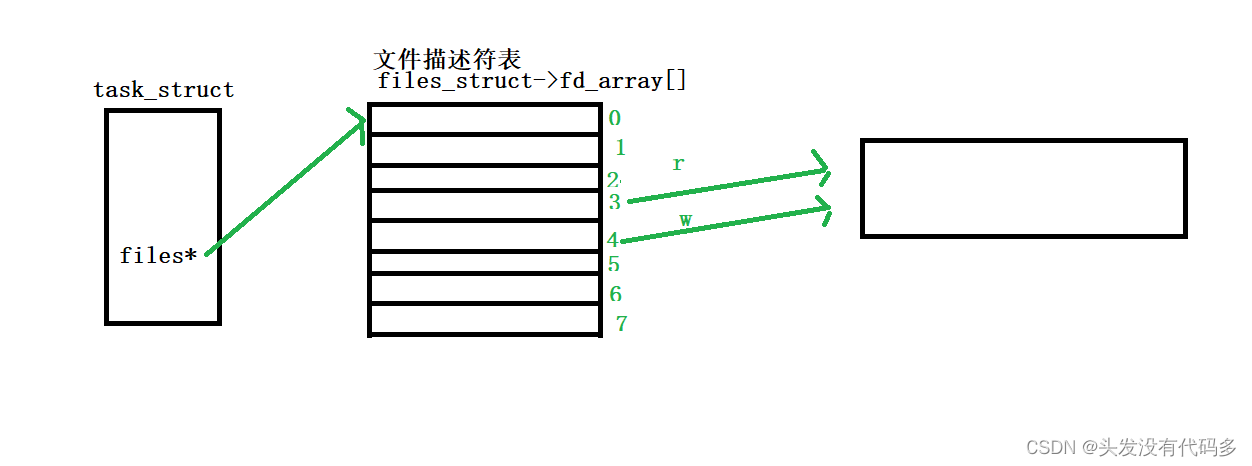
2.fork()创建子进程
由于进程具有独立性,子进程会有自己的task_struct和文件描述符表,之后父进程相关的数据会拷贝给子进程,文件描述符表也会拷贝给子进程。
这样不同的进程看到同一份资源(内存),这里这是创建了子进程,我们的目的是子进程,不会拷贝文件相关数据结构,只会拷贝进程相关数据结构。

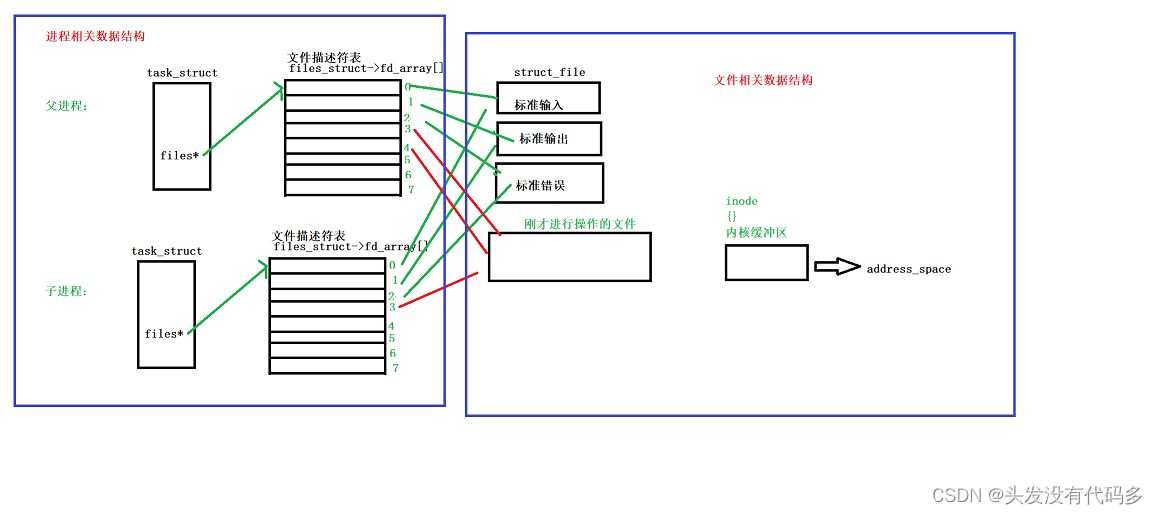
管道的底层原理就是以文件的形式设计
3.双方进程各自关闭自己不需要的文件描述符。
由于管道是单向通信,我们目前规定父进程写入,子进程读取。
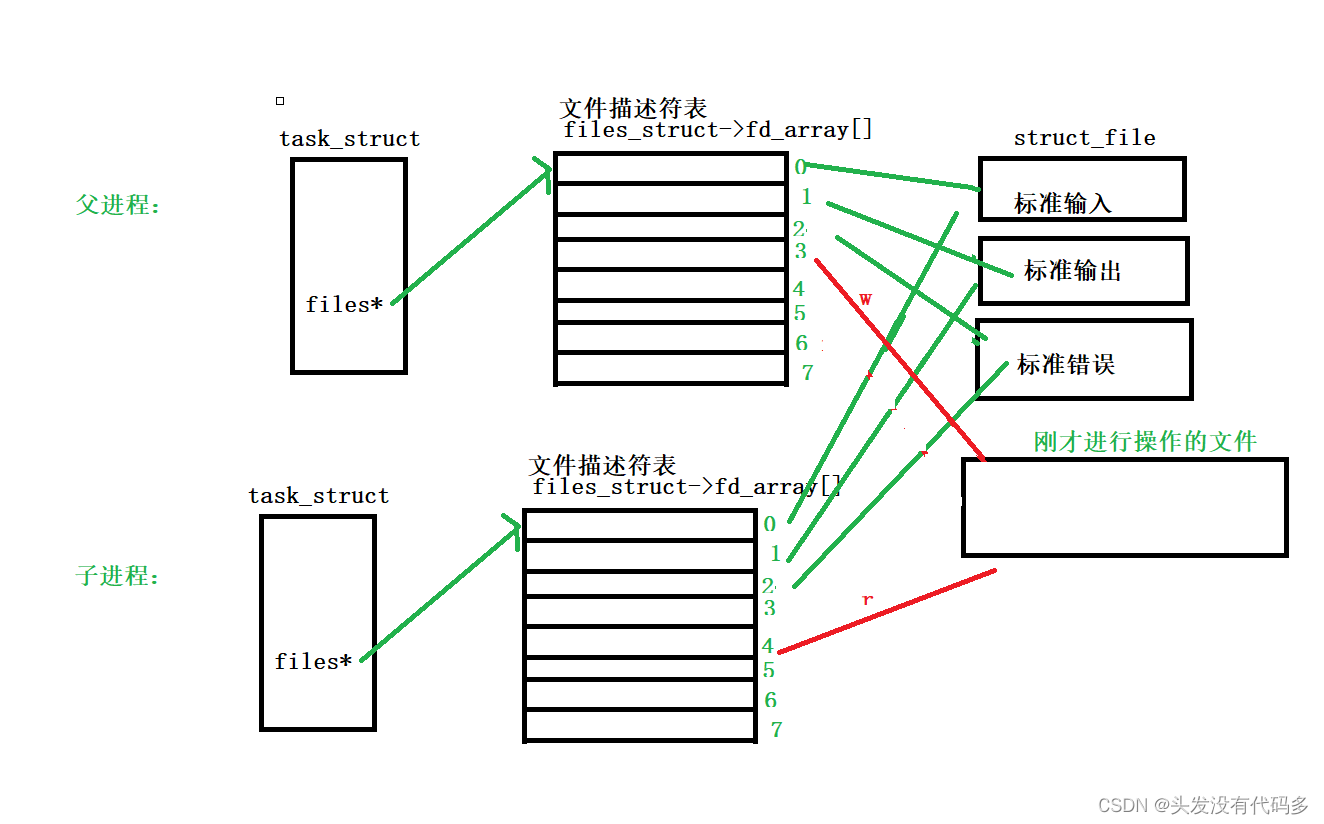
这就叫管道 ,管道就是文件,俩个进程通过文件来进行通信

当我们在上面操作的文件中写入了数据,没必要把这些数据刷新到磁盘中,进程间通信要保证纯内存级别的通信,磁盘是外设。
匿名管道
#include <unistd.h>
功能:创建一无名管道
原型
int pipe(int fd[2]);
输出型参数,期望通过调用它,得到被打开的文件fd,创建成功时返回值为0,失败返回值为-1。
谁调用pipe,就让谁以读写方式打开文件,不需要指定文件名,这个文件是纯内存级别的,如struct_file就不在磁盘中。文件属于内核,一个进程把文件给操作系统,然后另一个进程通过操作系统去读取。
参数
fd:文件描述符数组,其中fd[0]表示读端, fd[1]表示写端
返回值:成功返回0,失败返回错误代码
用代码进行测试


进行调试

如果要不想调试
在-DDEBUG前面加#
此时结果不能打印

我们接下来要实现让父进程写入,子进程读取。
创建子进程,并进行读写通道的建立

read的返回值类型是ssize_t这是long int
snprintf,把特定的字符串内容显示到字符串中

管道实现进程间通信
#include<iostream>
#include<cstdio>
#include<cstring>
#include<unistd.h>
#include<assert.h>
#include<string>
#include<sys/types.h>
#include<sys/wait.h>
using namespace std;
int main()
{
int pipefd[2]={0};//默认设置为0
int n=pipe(pipefd);//完成了管道的创建,默认以读写方式打开
//断言在DEBUG模式下有效,release无效
//如果没有(void)n n就只被定义而未被使用,可能会在 Realse模式下会出现大量的警告,所以我们加了(void)n
assert(n!=-1);
(void)n;
//查看读和写对应的文件描述符
#ifdef DEBUG
cout << "pipefd[0]: " << pipefd[0] << endl; // 3 读端
cout << "pipefd[1]: " << pipefd[1] << endl; // 4 写端
#endif
//2.创建子进程
pid_t id=fork();
assert(id!=-1);
if(id==0)
{
//子进程
//3.构建单向通信的信道
// 3.1关闭子进程不需要的fd
close(pipefd[1]);//子进程关闭写端
char buffer[1024];
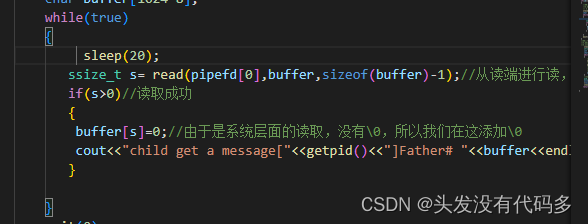
while(true)
{
ssize_t s= read(pipefd[0],buffer,sizeof(buffer)-1);//从读端进行读,将内容读取到buffer中,大小为buffer-1
if(s>0)//读取成功
{
buffer[s]=0;//由于是系统层面的读取,没有\0,所以我们在这添加\0
cout<<"child get a message["<<getpid()<<"]Father# "<<buffer<<endl;//打印来自父进程的文件内容
}
}
exit(0);
}
//父进程
//3.构建单向通信的信道
//3.1关闭父进程不需要的fd
close(pipefd[0]);//父进程关闭读端
string message="我是父进程,我正在给你发消息";
int count=0;//计数器,统计发送消息的条数
char send_buffer[1024];//要发送的缓冲区
while(true)
{
//3.2 构建一个变化的字符串
snprintf(send_buffer,sizeof(send_buffer),"%s[%d]:%d",message.c_str(),getpid(),count++);//把消息和统计次数格式化到缓冲区当中
//3.3 写入
write(pipefd[1],send_buffer,strlen(send_buffer));//把缓冲区的内容写入到写端,这里的strlen后面不需要+1
//因为管道也是文件,不需要给文件描述符对应的文件写入\0,因为没意义
//3.4 故意sleep
sleep(1);
}
//等待子进程
pid_t ret=waitpid(id,nullptr,0);
assert(ret<0);
(void)ret;
close(pipefd[1]);//结束之后,关闭写端,子进程不需要写,因为子进程程序中有exit(0),当推出后,文件描述符会被关掉,此时文件不一定被释放。文件是父进程打开的,当父进程结束时,文件会被释放
return 0;
}

我们在程序里写端缓冲区有一个buffer,读端缓冲区也有一个buffer, 不用全局buffer是因为有写时拷贝的存在,父子进程要确保自己数据的私有性,再怎么定义全局变量,也无法进行通信。
管道的特点
1.管道是用来进行具有“学院”关系的进程进行进程间通信——常用于父子通信
管道是一个文件,显示器也是一个文件,父子同时往显示器写入的时候,如果没有先后顺序俩个同时写入,这种情况是由于缺乏访问控制。
管道文件,在进行读取的时候,子进程会等待父进程,如这里休眠10s,在休眠的这段时间,子进程一直都在等父进程,所以显示器未打印数据,这叫具有访问控制

2.管道具有通过让进程间协同,提供了访问控制
不控制父进程的写入速度,让子子进程20s后再读
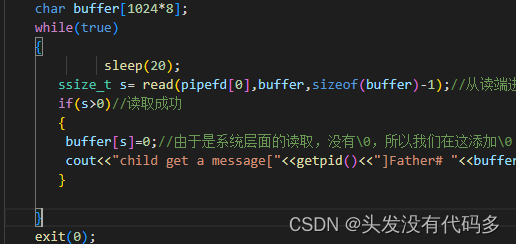
程序一执行,管道就被写满

之后子进程进行读取,一次性把管道里的内容读取完

子进程读取完之后,父进程又开始写,直到写满

3.管道提供的时面向流式的服务——面向字节流一般需要定制协议
4.管道是基于文件的,文件的生命周期时随进程的,管道的生命周期是随进程的(如果父子进程在使用管道通信,通信双方退出,管道会被自动释放)
如果读的时候,写入的一方的fd没有关闭,如果有数据就读,没有数据就等,如果写入的一方fd关闭,读取的一方,read会返回0,表示读到了文件的结尾
写了10次,关闭写端

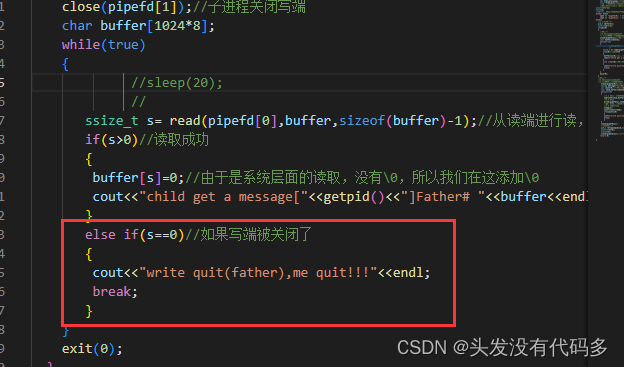
 写入端关闭,子进程 退出
写入端关闭,子进程 退出
5.管道是单向通信的,就是半双工通信的一种特殊情况(要么一者在接收,要么一者在发送)。 全双工(俩人吵架,俩人同时在说,同时在听)。
a.写快,读慢,写满就不能再写了
b.写慢,读快,管道没有数据的时候,就必须等待
c.写关,读到了0(读到文件结尾,即把所有文件读取完),表示读到了文件结尾
d.读关,写继续写,OS终止写进程
当要写入的数据量不大于PIPE_BUF时,linux将保证写入的原子性(只有做和不做俩种选择)。
当要写入的数据量大于PIPE_BUF时,linux将不再保证写入的原子性。
进程池
每个子进程和父进程形成一个管道,0是fd为0,1是fd为1,当用户要父进程完成任务时,父进程可指派子进程进行完成,可随机选子进程或按照某种特定顺序让子进程执行。
我们在这里让父进程每次写4字节,子进程读四字节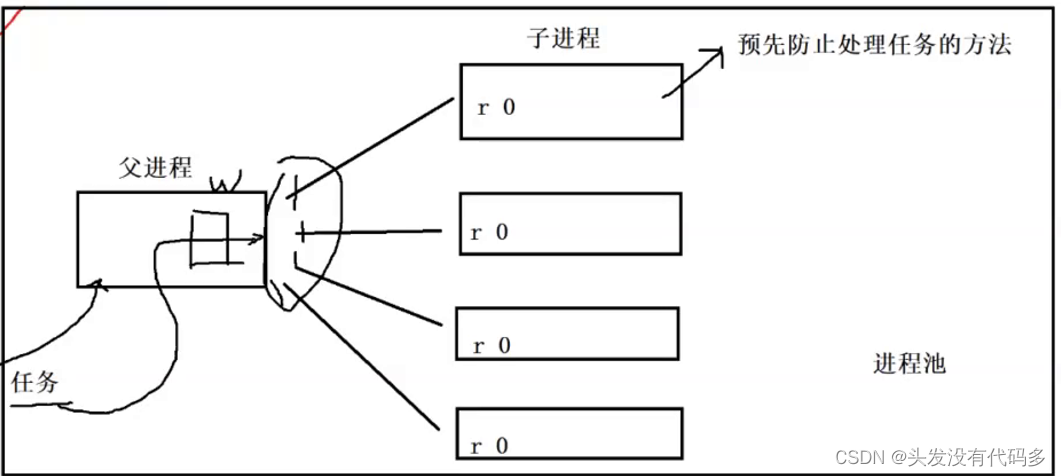
ProcessPool.cc
#include <iostream>
#include <vector>
#include <cstdlib>
#include <ctime>
#include <cassert>
#include <unistd.h>
#include <sys/wait.h>
#include <sys/types.h>
#include "Task.hpp"
#define PROCESS_NUM 5//进程个数
using namespace std;
int waitCommand(int waitFd,bool &quit)
{
//uint32_t是4个字节
uint32_t command=0;
ssize_t s=read(waitFd,&command,sizeof(command));//从waitFd里读取内容到command,大小为4个字节
if(s==0)//此时把文件描述符关了
{
quit=true;
return -1;
}
assert(s==sizeof(uint32_t));
return command;//返回读到的命令
}
void sendAndWakeup(pid_t who, int fd, uint32_t command)
{
//给who进程通过fd发送command命令
write(fd, &command, sizeof(command));
cout << "main process: call process " << who << " execute " << desc[command] << " through " << fd << endl;
}
int main()
{
load();
vector<pair<pid_t,int>> slots;//pair的first是pid,second是进程相关信息pipefd
//slots是一个表,表里存的是子进程的id和pipefd,父进程可以通过该表选择让哪个子进程执行任务
//创建多个进程
for(int i=0;i<PROCESS_NUM;++i)
{
int pipefd[2]={0};
//创建管道
int n=pipe(pipefd);
assert(n==0);
pid_t id=fork();
(void)n;
assert(id!=-1);
//子进程让他进行读取
if(id==0)
{
//子进程
//关闭子进程写端
close(pipefd[1]);
while(true)
{
bool quit=false;//一开始先不退出,后面要等待命令
int command=waitCommand(pipefd[0],quit);//子进程等命令,在读取文件描述符那里等命令,如果对方不发命令,我们就阻塞
if(quit)
break;
//执行对应的命令
if(command>=0&&command<handlerSize())//如果范围之类
{
callbacks[command]();//直接调用对应的方法
}
else
{
cout<<"非法command"<<command<<endl;
}
}
exit(1);
}
//父进程
close(pipefd[0]);
slots.push_back(pair<pid_t,int>(id,pipefd[1]));//子进程ID,写端描述符
//把所有的子进程信息,放到vector里,形成一张子进程表
}
//整个for循环就是在选择父进程在选择子进程,并且准备给子进程发指令
//父进程派发任务,用单机版的负载均衡(防止出现一个子进程做多个任务,均衡一下子进程工作量)
//我们用随机数派发
srand((unsigned long)time(nullptr)^getpid()^2323232323L);//让数据源更随机
while(true)
{
cout<<"########################################"<<endl;
cout<<"# 1.show functions 2.send command #"<<endl;
cout<<"########################################"<<endl;
cout<<"Please Select";
int select;
int command;//命令
cin>>select;
if(select==1)//显示可以被执行的任务
{
showHandler();
}
else if(select==2)//发送命令
{
//选择任务
cout<<"Enter Your Command";
cin>>command;//输入命令
//选择进程
int choice=rand()%slots.size();
//布置任务,把任务给指定的进程
sendAndWakeup(slots[choice].first,slots[choice].second,command);//发送命令并且唤醒子进程
}
else
{}
}
//关闭fd,结束所有进程
for(const auto slot:slots)
{
close(slot.second);
}
//回收所有的子进程信息
for(const auto slot:slots)
{
waitpid(slot.first,nullptr,0);
}
return 0;
}Task.hpp
#pragma once
#include <iostream>
#include <string>
#include <vector>
#include <unordered_map>
#include <unistd.h>
#include <functional>
typedef std::function<void()> func;//定义一个函数类型,返回值类型void,参数()
std::vector<func> callbacks;//回调
std::unordered_map<int, std::string> desc;
void readMySQL()
{
std::cout << "sub process[" << getpid() << " ] 执行访问数据库的任务\n" << std::endl;
}
void execuleUrl()
{
std::cout << "sub process[" << getpid() << " ] 执行url解析\n" << std::endl;
}
void cal()
{
std::cout << "sub process[" << getpid() << " ] 执行加密任务\n" << std::endl;
}
void save()
{
std::cout << "sub process[" << getpid() << " ] 执行数据持久化任务\n" << std::endl;
}
void load()
{
desc.insert({callbacks.size(), "readMySQL: 读取数据库"});//相当于构建键值对,0号命令对应readmysql
callbacks.push_back(readMySQL);//下标为0,插入ReadMysql
desc.insert({callbacks.size(), "execuleUrl: 进行url解析"});
callbacks.push_back(execuleUrl);
desc.insert({callbacks.size(), "cal: 进行加密计算"});
callbacks.push_back(cal);
desc.insert({callbacks.size(), "save: 进行数据的文件保存"});
callbacks.push_back(save);
}
void showHandler()//显示当前所有的方法
{
for(const auto &iter : desc )
{
std::cout << iter.first << "\t" << iter.second << std::endl;
}
}
int handlerSize()//共有多少任务的处理方法
{
return callbacks.size();
}习题
1.以下描述正确的有:B
A.进程之间可以直接通过地址访问进行相互通信
B.进程之间不可以直接通过地址访问进行相互通信
C.所有的进程间通信都是通过内核中的缓冲区实现的
D.以上都是错误的
A错误: 进程之间具有独立性,拥有自己的虚拟地址空间,因此无法通过各自的虚拟地址进行通信(A的地址经过B的页表映射不一定映射在什么位置)
B正确
C错误: 除了内核中的缓冲区之外还有文件以及网络通信的方式可以实现
2.以下选项属于进程间通信的是(A,B,D)[多选]
A.管道
B.套接字
C.内存
D.消息队列
典型进程间通信方式:管道,共享内存,消息队列,信号量。 除此之外还有网络通信,以及文件等多种方式
C选项,这里的内存太过宽泛,并没有特指某种技术,错误。
3.下列关于管道(Pipe)通信的叙述中,正确的是(C)
A.一个管道可以实现双向数据传输
B.管道的容量仅受磁盘容量大小限制
C.进程对管道进行读操作和写操作都可能被阻塞
D.一个管道只能有一个读进程或一个写进程对其操作
A错误 管道是半双工通信,是可以选择方向的单向通信
B错误 管道的本质是内核中的缓冲区,通过内核缓冲区实现通信,命名管道的文件虽然可见于文件系统,但是只是标识符,并非通信介质
C正确 管道自带同步(没有数据读阻塞,缓冲区写满写阻塞)与互斥
D错误 多个进程只要能够访问同一管道就可以实现通信,不限于读写个数
4.以下关于管道的描述中,正确的是 [多选]B,D
A错误,匿名管道只能用于具有亲缘关系的进程间通信,命名管道可以用于同一主机上的任意进程间通信
B正确
C错误,匿名管道需要在创建子进程之前创建,因为只有这样才能复制到管道的操作句柄,与具有亲缘关系的进程实现访问同一个管道通信
D正确
5.以下关于管道的描述中错误的是 [多选]B,C
A.可以通过int pipe(int pipefd[2])接口创建匿名管道,其中pipefd[0]用于从管道中读取数据
B.可以通过int pipe(int pipefd[2])接口创建匿名管道,其中pipefd[0]用于向管道中写入数据
C.若在所有进程中将管道的写端关闭,则从管道中读取数据时会返回-1;
D.管道的本质是内核中的一块缓冲区;
- 管道本质是内核中的一块缓冲区,多个进程通过访问同一块缓冲区实现通信。
- 使用int pipe(int pipefd[2])接口创建匿名管道,pipefd[0]用于从管道读取数据,pipefd[1]用于向管道写入数据。
- 管道特性:半双工通信,自带同步与互斥,生命周期随进程,提供字节流传输服务。
- 在同步的提现中,若管道所有写段关闭,则从管道中读取完所有数据后,继续read会返回0,不再阻塞;若所有读端关闭,则继续write写入会触发异常导致进程退出
根据以上管道理解分析:A正确,B错误,C错误,D正确
因为题目为选择错误选项,因此选择B和C选项