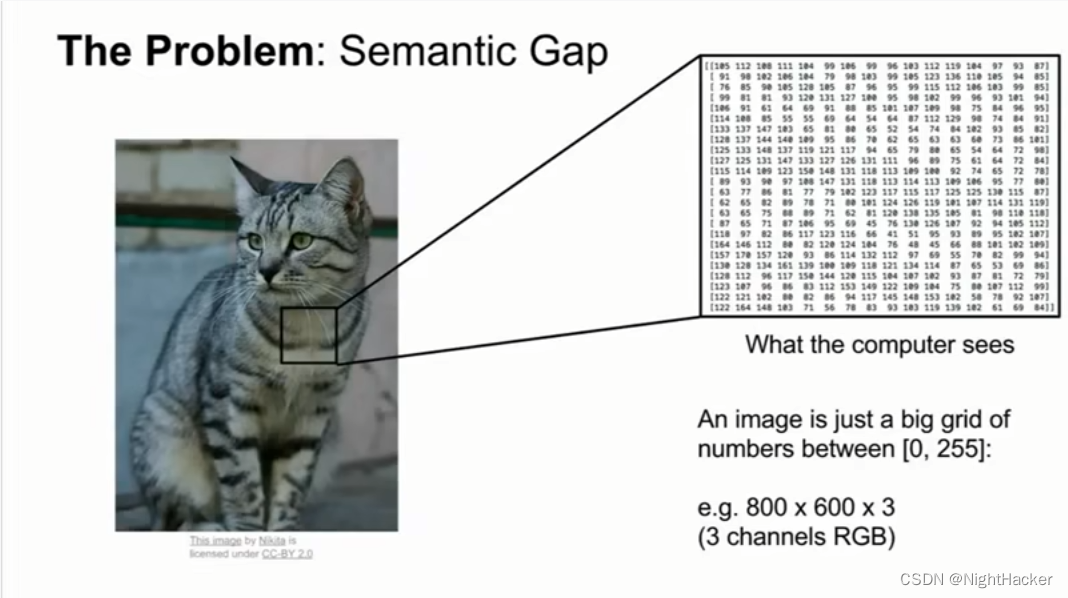
姿态、环境、遮挡这些问题算法都因该是robust
课程中提到具体写一个识别猫咪的算法是不稳定的,容易出错的。
所以提出了Data-Driven Approach的方法

一个是训练函数, 这函数接受图片和标签,然后输出标签
另一个则是预测函数,输入model对图像标签进行预测
最近邻算法:
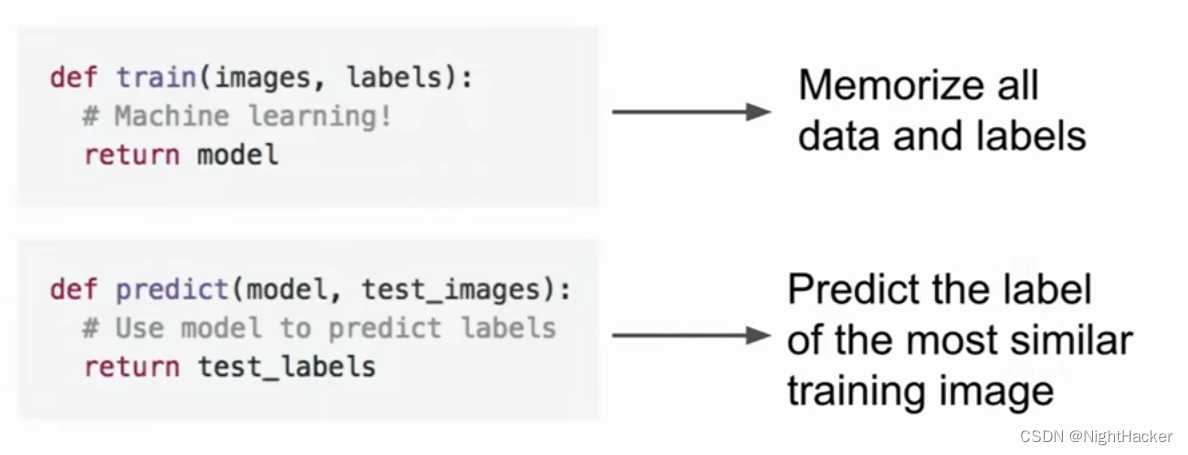
在预测环节中,会拿一些新的图片,在模型中寻找与新图片最相似的,基于此给出一个新的标签
这里用的很多很多属性都是数据驱动的。
数据集:CIFAR10
曼哈顿距离(L1距离):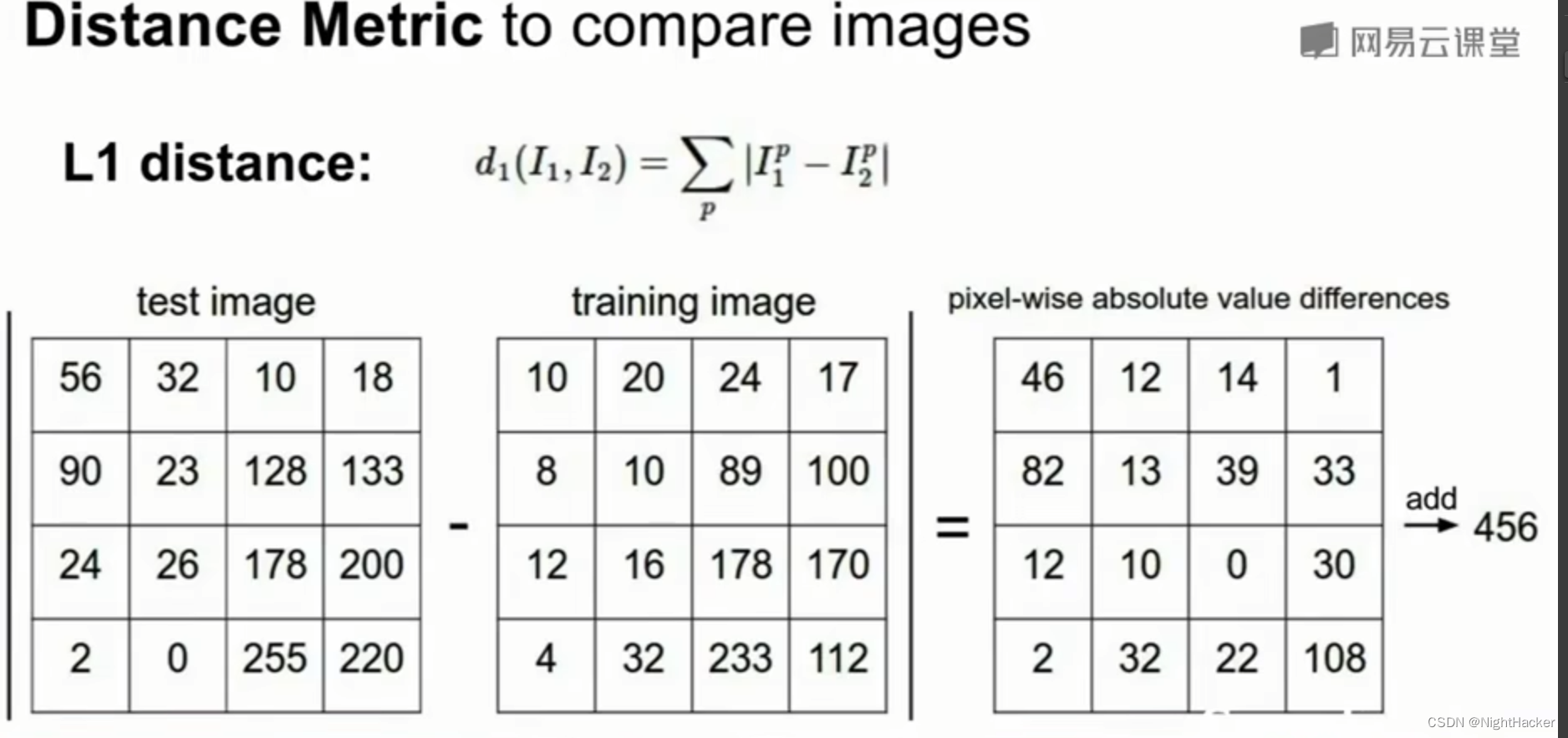
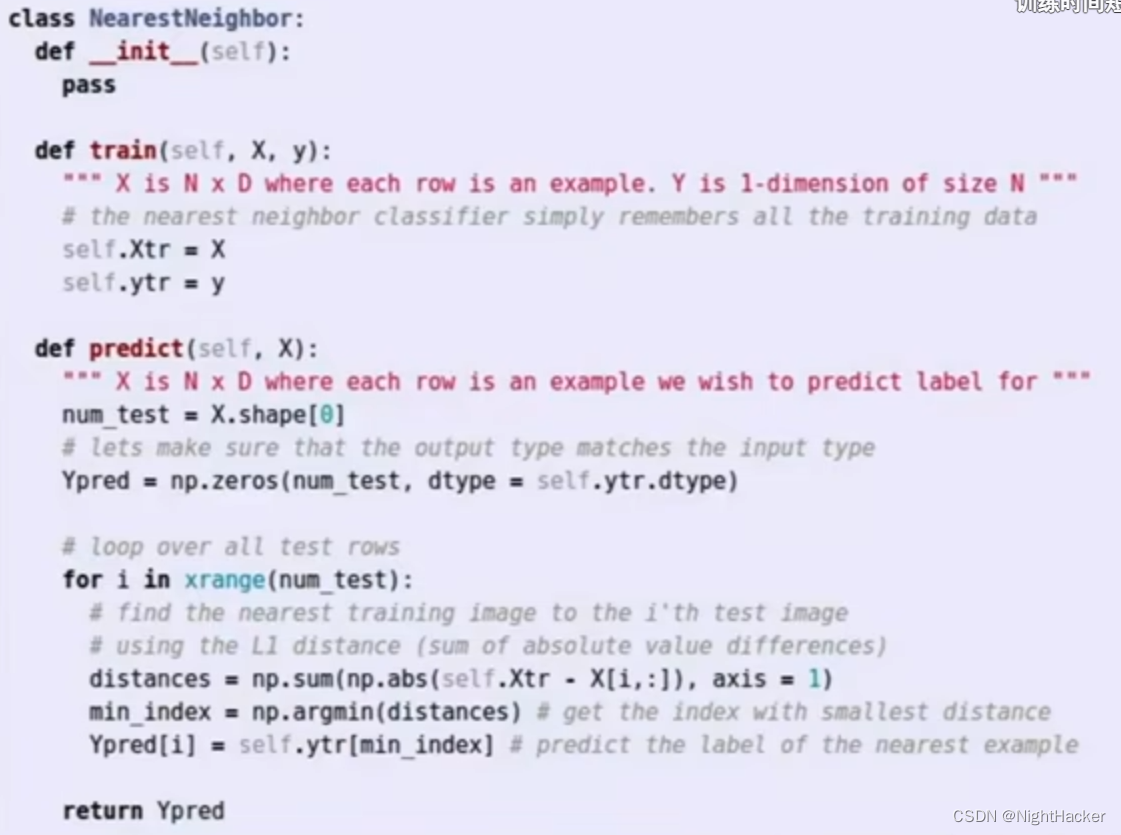
最近邻算法时间复杂度:
Train:O(1)
Predict:O(n)
花了很多时间在预测上,所以算法比较落后。
L2距离(欧氏距离):


K近邻算法没听懂的可以去看:(虽然我觉得这个算法不重要hh),但可以去听这个视频里讲的kd树后面会用到的!
[5分钟学算法] #01 k近邻法_哔哩哔哩_bilibili