文章目录
- TiDB体系架构
- TiDB Server
- Storage Cluster(存储引擎)
- PD cluster
- 题目
TiDB体系架构
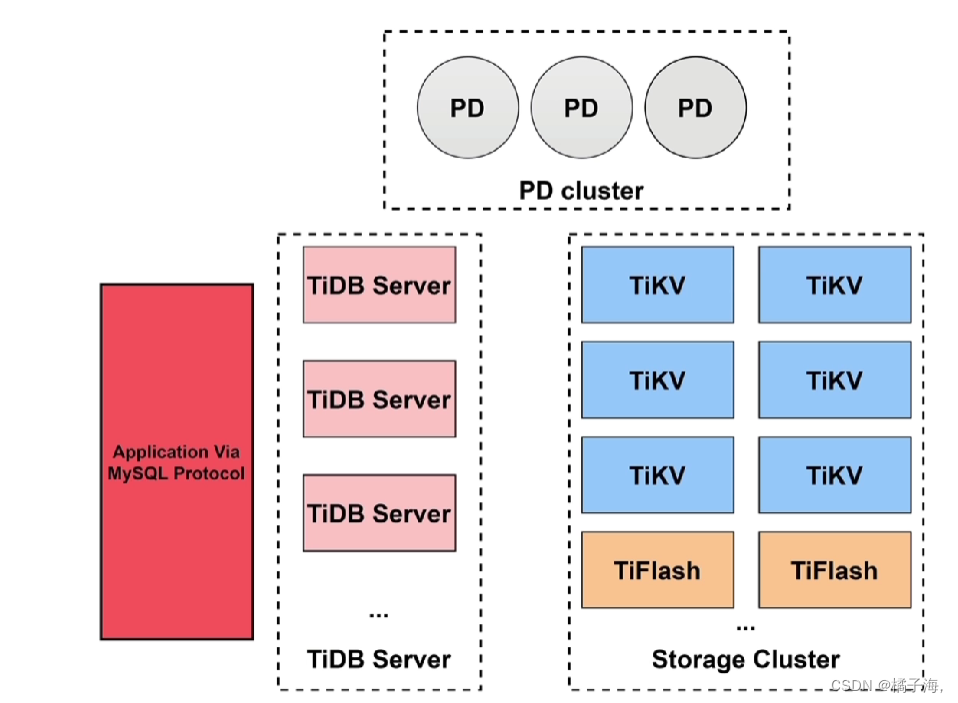
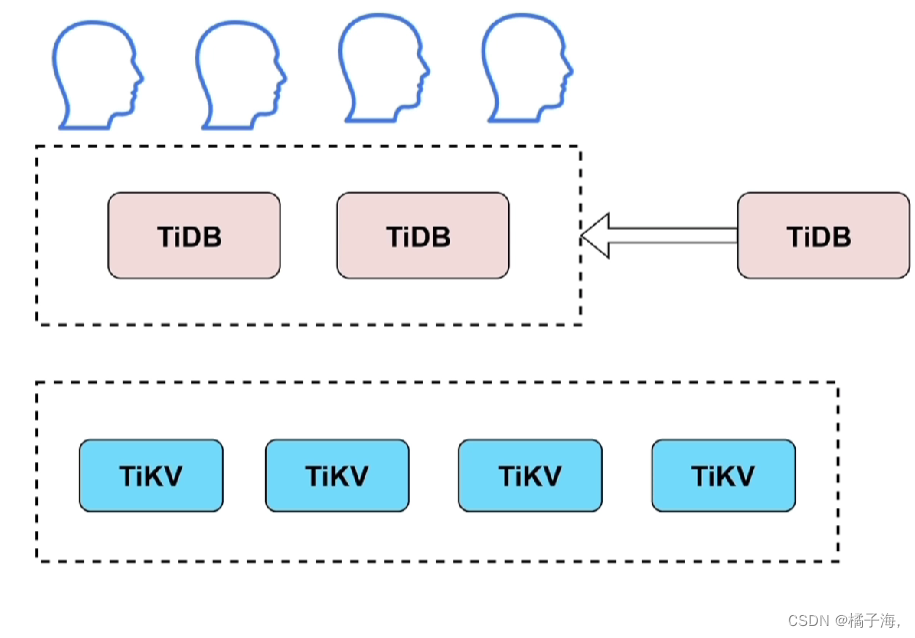
TiDB Server
Sql语句最先到达 TiDB Server集群
它是无状态的,数据并不是存储在这里面,当一个会话连接到TiDB Server集群上,sql语句发过来,它负责解析、编译、优化sql语句并且生成执行计划
它可以扩展,当并发很高的时候,也就是大量的会话连接到一个TiDB时,这时候就可以向整个集群中增加结点,分走一部分会话,减小高并发压力
小结
- 处理客户端的连接
- SQL语句的解析和编译
- 关系型数据与KV键值对的转化
- SQL语句的执行
- 执行 online DDL
- 垃圾回收(默认十分钟做一次垃圾回收)
Storage Cluster(存储引擎)
TiKV
它里面存的数据并不是我们create table 建的表,写数据时会经过TiDB Server时把这张表转化成一个一个的存储单位,称为region(96M~144M),分布的存储在TiKV中
TiKV会利用特定的协议为它创建一个副本,一般默认为3个副本,具有高可用性
如果容量不过,通过增加结点的方式使数据库容量增大,如果冷数据被清理,那么就可以把多余的TiKV回收掉
TiFlash
存的数据和TiKV里面的一样,但是TiFlash里面的数据是列存,TiKV里面的数据是行存,它是非常善于做统计分析的
小结
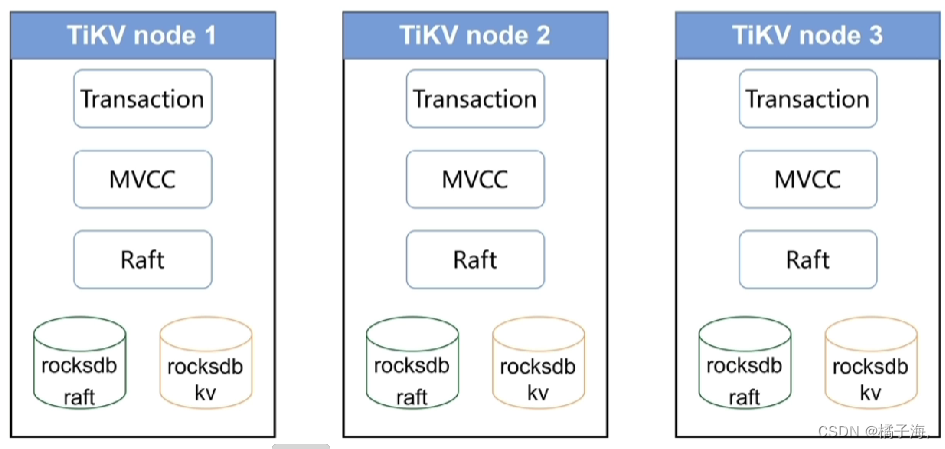
-
数据持久化:内部是用rocksdb这个数据库保证数据持久化的
- rocksdb kv:将表数据转成kv存在该实例中
- rocksdb raft:存指令的,对表的增删改查都存在这里面
-
副本的强一致性和高可用性
- 三个副本中有一个副本可以读写,其他的副本不能读写,其他副本跟着变化,通过Raft协议将副本的修改复制到其他副本上,实现数据的一致性
-
MVCC(多版本并发控制):当数据修改的时候,可以进行读操作,读的是修改前的数据
-
分布式事务支持
-
Coprocessor(算子下推):每个结点都有一个cpu,做过滤等操作时不是一定要送到Server中,实现的分布式计算
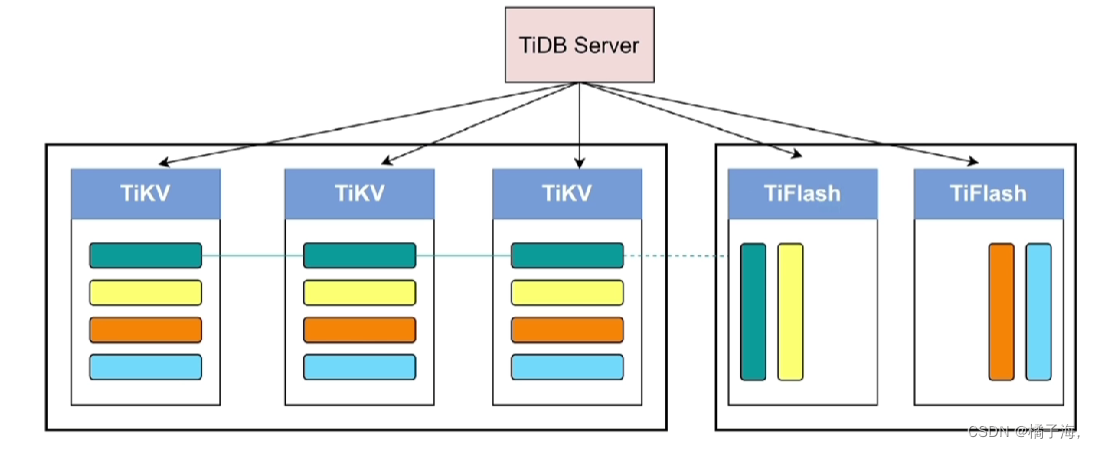
TiFlash
- 异步复制
- 一致性
- 列式存储提高分析查询效率
- 业务隔离
- 只能选择
PD cluster
PD被称为整个集群的大脑,TiDB Server执行完sql语句会生成执行计划,也就是说明要执行什么操作,比如要读一张表,但是这张表到底是在哪个或者哪几个TiKV或者TiFlash上呢,这些叫做这个region的元数据,也就是这个region和TiKV的对应关系,这个对应关系就是存在PD中的。
当sql要执行的时候它首先到PD的结点中去查表在哪几个TiKV或者TiFlash上分布
PD提供了TSO时间戳,每条sql执行的时候都有一个开始时间,开始时间的查询也是从PD开始的,在数据库中,对于时间不是以时分秒计算的,会有一个标识,叫做TSO一个时间戳,随着时间增长不断增加,每一天sql执行都会获得一个时间戳,标识执行的时间,事务提交时也会获得一个结束的TSO
小结
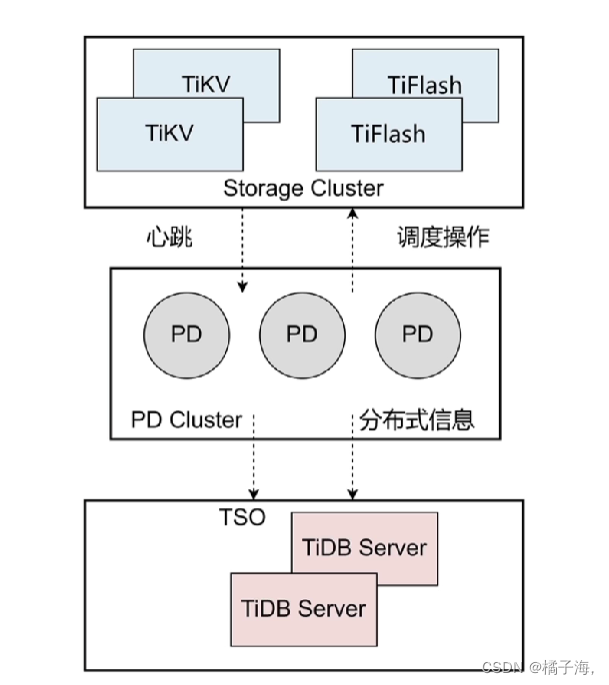
Placement Driver
- 整个集群TiKV的元数据存储
- 分配全局ID和事务ID
- 生成全局时间戳TSO
- 收集集群信息进行调度
- 提供TiDB Dashboard服务
题目
下面让我们来做两道题练习一下