前言
代码大部分来自
- https://fate.readthedocs.io/en/latest/tutorial/pipeline/nn_tutorial/Hetero-NN-Customize-Dataset/#example-implement-a-simple-image-dataset
- https://fate.readthedocs.io/en/latest/tutorial/pipeline/nn_tutorial/Homo-NN-Customize-your-Dataset/
但是官方的文档不完整,我自己记录完整一下。
我用的是mnist数据集https://webank-ai-1251170195.cos.ap-guangzhou.myqcloud.com/fate/examples/data/mnist.zip。
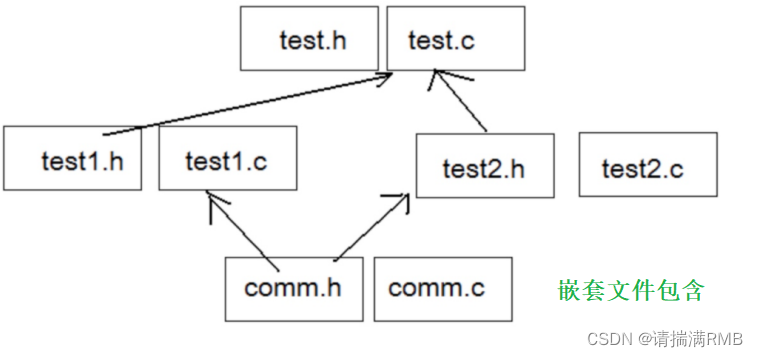
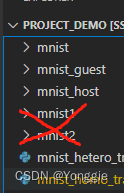
目录结构如下,横向的话,加载两次mnist就可以,而纵向一方加载mnist_guest带标签,一方加载mnist_host没有标签。mnist12两个文件夹没有用,不用管。
由于官方demo中的需要使用jupyter,不适合普通Python代码,本文给出此例子。在Python的解释器上,要注意在环境变量里加入FATE的安装包里的bin/init_env.sh里面的Python解释器路径,否则federatedml库会找不到。
横向
自定义数据集
自定义数据集,然后再本地测试一下。
import os
from torchvision.datasets import ImageFolder
from torchvision import transforms
from federatedml.nn.dataset.base import Dataset
class MNISTDataset(Dataset):
def __init__(self, flatten_feature=False): # flatten feature or not
super(MNISTDataset, self).__init__()
self.image_folder = None
self.ids = None
self.flatten_feature = flatten_feature
def load(self, path): # read data from path, and set sample ids
# read using ImageFolder
self.image_folder = ImageFolder(root=path, transform=transforms.Compose([transforms.ToTensor()]))
# filename as the image id
ids = []
for image_name in self.image_folder.imgs:
ids.append(image_name[0].split('/')[-1].replace('.jpg', ''))
self.ids = ids
return self
def get_sample_ids(self): # implement the get sample id interface, simply return ids
return self.ids
def __len__(self,): # return the length of the dataset
return len(self.image_folder)
def __getitem__(self, idx): # get item
ret = self.image_folder[idx]
if self.flatten_feature:
img = ret[0][0].flatten() # return flatten tensor 784-dim
return img, ret[1] # return tensor and label
else:
return ret
ds = MNISTDataset(flatten_feature=True)
ds.load('mnist/')
# print(len(ds))
# print(ds[0])
# print(ds.get_sample_ids()[0])
成功输出后,要手动在FAET/federatedml.nn.datasets下新建数据集文件,把上文的代码扩充成组件类的形式,如下
import torch
from federatedml.nn.dataset.base import Dataset
from torchvision.datasets import ImageFolder
from torchvision import transforms
import numpy as np
# 这里的包缺什么补什么哈
class MNISTDataset(Dataset):
def __init__(self, flatten_feature=False): # flatten feature or not
super(MNISTDataset, self).__init__()
self.image_folder = None
self.ids = None
self.flatten_feature = flatten_feature
def load(self, path): # read data from path, and set sample ids
# read using ImageFolder
self.image_folder = ImageFolder(root=path, transform=transforms.Compose([transforms.ToTensor()]))
# filename as the image id
ids = []
for image_name in self.image_folder.imgs:
ids.append(image_name[0].split('/')[-1].replace('.jpg', ''))
self.ids = ids
return self
def get_sample_ids(self): # implement the get sample id interface, simply return ids
return self.ids
def __len__(self,): # return the length of the dataset
return len(self.image_folder)
def __getitem__(self, idx): # get item
ret = self.image_folder[idx]
if self.flatten_feature:
img = ret[0][0].flatten() # return flatten tensor 784-dim
return img, ret[1] # return tensor and label
else:
return ret
if __name__ == '__main__':
pass
这样就完成了他官方文档所谓的“手动添加”了。添加后federatedml的目录应该是这样的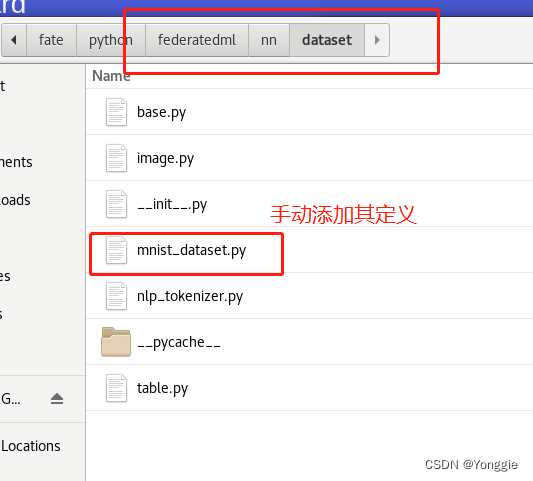 文件名称要和下文的
文件名称要和下文的dataset param对应。
添加后,FATE就“认识”我们自建的数据集了。
下文中的local test是不需要做手动添加的步骤的,但是local只是做个测试。生产中没什么用……
横向训练
import os
from torchvision.datasets import ImageFolder
from torchvision import transforms
from federatedml.nn.dataset.base import Dataset
# test local process
# from federatedml.nn.homo.trainer.fedavg_trainer import FedAVGTrainer
# trainer = FedAVGTrainer(epochs=3, batch_size=256, shuffle=True, data_loader_worker=8, pin_memory=False) # set parameter
# trainer.local_mode()
# import torch as t
# from pipeline import fate_torch_hook
# fate_torch_hook(t)
# # our simple classification model:
# model = t.nn.Sequential(
# t.nn.Linear(784, 32),
# t.nn.ReLU(),
# t.nn.Linear(32, 10),
# t.nn.Softmax(dim=1)
# )
# trainer.set_model(model) # set model
# optimizer = t.optim.Adam(model.parameters(), lr=0.01) # optimizer
# loss = t.nn.CrossEntropyLoss() # loss function
# trainer.train(train_set=ds, optimizer=optimizer, loss=loss) # use dataset we just developed
# 必须在federatedml.nn.datasets目录下 手动加入新的数据集的信息!https://blog.csdn.net/Yonggie/article/details/129404212
# real training
import torch as t
from torch import nn
from pipeline import fate_torch_hook
from pipeline.component import HomoNN
from pipeline.backend.pipeline import PipeLine
from pipeline.component import Reader, Evaluation, DataTransform
from pipeline.interface import Data, Model
t = fate_torch_hook(t)
import os
# bind data path to name & namespace
fate_project_path = os.path.abspath('./')
host = 1
guest = 2
arbiter = 3
pipeline = PipeLine().set_initiator(role='guest', party_id=guest).set_roles(guest=guest, host=host,
arbiter=arbiter)
data_0 = {"name": "mnist_guest", "namespace": "experiment"}
data_1 = {"name": "mnist_host", "namespace": "experiment"}
data_path_0 = fate_project_path + '/mnist'
data_path_1 = fate_project_path + '/mnist'
pipeline.bind_table(name=data_0['name'], namespace=data_0['namespace'], path=data_path_0)
pipeline.bind_table(name=data_1['name'], namespace=data_1['namespace'], path=data_path_1)
reader_0 = Reader(name="reader_0")
reader_0.get_party_instance(role='guest', party_id=guest).component_param(table=data_0)
reader_0.get_party_instance(role='host', party_id=host).component_param(table=data_1)
from pipeline.component.nn import DatasetParam
dataset_param = DatasetParam(dataset_name='mnist_dataset', flatten_feature=True) # specify dataset, and its init parameters
from pipeline.component.homo_nn import TrainerParam # Interface
# our simple classification model:
model = t.nn.Sequential(
t.nn.Linear(784, 32),
t.nn.ReLU(),
t.nn.Linear(32, 10),
t.nn.Softmax(dim=1)
)
nn_component = HomoNN(name='nn_0',
model=model, # model
loss=t.nn.CrossEntropyLoss(), # loss
optimizer=t.optim.Adam(model.parameters(), lr=0.01), # optimizer
dataset=dataset_param, # dataset
trainer=TrainerParam(trainer_name='fedavg_trainer', epochs=2, batch_size=1024, validation_freqs=1),
torch_seed=100 # random seed
)
pipeline.add_component(reader_0)
pipeline.add_component(nn_component, data=Data(train_data=reader_0.output.data))
pipeline.add_component(Evaluation(name='eval_0', eval_type='multi'), data=Data(data=nn_component.output.data))
pipeline.compile()
pipeline.fit()
# print result and summary
pipeline.get_component('nn_0').get_output_data()
pipeline.get_component('nn_0').get_summary()
纵向
会用到mnist_host和mnist guest,下载
guest data: https://webank-ai-1251170195.cos.ap-guangzhou.myqcloud.com/fate/examples/data/mnist_guest.zip
host data: https://webank-ai-1251170195.cos.ap-guangzhou.myqcloud.com/fate/examples/data/mnist_host.zip
你查看一下数据集的格式。FATE里面的纵向,都是一方有标签,一方没标签,跟我所认知的合并数据集那种场景有差别。
纵向数据集
做法参考横向那里,我这里只给出新建的类的代码,跟横向的有一点点差别。
import torch
from federatedml.nn.dataset.base import Dataset
from torchvision.datasets import ImageFolder
from torchvision import transforms
import numpy as np
class MNISTDataset(Dataset):
def __init__(self, return_label=True):
super(MNISTDataset, self).__init__()
self.return_label = return_label
self.image_folder = None
self.ids = None
def load(self, path):
self.image_folder = ImageFolder(root=path, transform=transforms.Compose([transforms.ToTensor()]))
ids = []
for image_name in self.image_folder.imgs:
ids.append(image_name[0].split('/')[-1].replace('.jpg', ''))
self.ids = ids
return self
def get_sample_ids(self, ):
return self.ids
def get_classes(self, ):
return np.unique(self.image_folder.targets).tolist()
def __len__(self,):
return len(self.image_folder)
def __getitem__(self, idx): # get item
ret = self.image_folder[idx]
img = ret[0][0].flatten() # flatten tensor 784 dims
if self.return_label:
return img, ret[1] # img & label
else:
return img # no label, for host
if __name__ == '__main__':
pass
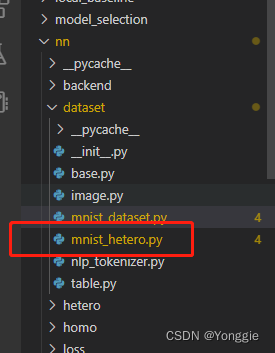
纵向训练
详细的注释都放在里面了。
import numpy as np
from federatedml.nn.dataset.base import Dataset
from torchvision.datasets import ImageFolder
from torchvision import transforms
# 本地定义的
# class MNISTHetero(Dataset):
# def __init__(self, return_label=True):
# super(MNISTHetero, self).__init__()
# self.return_label = return_label
# self.image_folder = None
# self.ids = None
# def load(self, path):
# self.image_folder = ImageFolder(root=path, transform=transforms.Compose([transforms.ToTensor()]))
# ids = []
# for image_name in self.image_folder.imgs:
# ids.append(image_name[0].split('/')[-1].replace('.jpg', ''))
# self.ids = ids
# return self
# def get_sample_ids(self, ):
# return self.ids
# def get_classes(self, ):
# return np.unique(self.image_folder.targets).tolist()
# def __len__(self,):
# return len(self.image_folder)
# def __getitem__(self, idx): # get item
# ret = self.image_folder[idx]
# img = ret[0][0].flatten() # flatten tensor 784 dims
# if self.return_label:
# return img, ret[1] # img & label
# else:
# return img # no label, for host
# test guest dataset
# ds = MNISTHetero().load('mnist_guest/')
# print(len(ds))
# print(ds[0][0])
# print(ds.get_classes())
# print(ds.get_sample_ids()[0: 10])
# test host dataset
# ds = MNISTHetero(return_label=False).load('mnist_host')
# print(len(ds))
# print(ds[0]) # no label
import os
import torch as t
from torch import nn
from pipeline import fate_torch_hook
from pipeline.component import HeteroNN
from pipeline.component.hetero_nn import DatasetParam
from pipeline.backend.pipeline import PipeLine
from pipeline.component import Reader, Evaluation, DataTransform
from pipeline.interface import Data, Model
fate_torch_hook(t)
# bind path to fate name&namespace
fate_project_path = os.path.abspath('./')
guest = 4
host = 3
pipeline_img = PipeLine().set_initiator(role='guest', party_id=guest).set_roles(guest=guest, host=host)
guest_data = {"name": "mnist_guest", "namespace": "experiment"}
host_data = {"name": "mnist_host", "namespace": "experiment"}
guest_data_path = fate_project_path + '/mnist_guest'
host_data_path = fate_project_path + '/mnist_host'
pipeline_img.bind_table(name='mnist_guest', namespace='experiment', path=guest_data_path)
pipeline_img.bind_table(name='mnist_host', namespace='experiment', path=host_data_path)
guest_data = {"name": "mnist_guest", "namespace": "experiment"}
host_data = {"name": "mnist_host", "namespace": "experiment"}
reader_0 = Reader(name="reader_0")
reader_0.get_party_instance(role='guest', party_id=guest).component_param(table=guest_data)
reader_0.get_party_instance(role='host', party_id=host).component_param(table=host_data)
# 这里为什么要这样定义,可以看文档,有模型https://fate.readthedocs.io/en/latest/federatedml_component/hetero_nn/
hetero_nn_0 = HeteroNN(name="hetero_nn_0", epochs=3,
interactive_layer_lr=0.01, batch_size=512, task_type='classification', seed=100
)
guest_nn_0 = hetero_nn_0.get_party_instance(role='guest', party_id=guest)
host_nn_0 = hetero_nn_0.get_party_instance(role='host', party_id=host)
# define model
# image features 784, guest bottom model
# our simple classification model:
guest_bottom = t.nn.Sequential(
t.nn.Linear(784, 8),
t.nn.ReLU()
)
# image features 784, host bottom model
host_bottom = t.nn.Sequential(
t.nn.Linear(784, 8),
t.nn.ReLU()
)
# Top Model, a classifier
guest_top = t.nn.Sequential(
nn.Linear(8, 10),
nn.Softmax(dim=1)
)
# interactive layer define
interactive_layer = t.nn.InteractiveLayer(out_dim=8, guest_dim=8, host_dim=8)
# add models, 根据文档定义,guest要add2个,host只有一个
guest_nn_0.add_top_model(guest_top)
guest_nn_0.add_bottom_model(guest_bottom)
host_nn_0.add_bottom_model(host_bottom)
# opt, loss
optimizer = t.optim.Adam(lr=0.01)
loss = t.nn.CrossEntropyLoss()
# use DatasetParam to specify dataset and pass parameters
# 注意和你手动加入的文件库名字要对应
guest_nn_0.add_dataset(DatasetParam(dataset_name='mnist_hetero', return_label=True))
host_nn_0.add_dataset(DatasetParam(dataset_name='mnist_hetero', return_label=False))
hetero_nn_0.set_interactive_layer(interactive_layer)
hetero_nn_0.compile(optimizer=optimizer, loss=loss)
pipeline_img.add_component(reader_0)
pipeline_img.add_component(hetero_nn_0, data=Data(train_data=reader_0.output.data))
pipeline_img.add_component(Evaluation(name='eval_0', eval_type='multi'), data=Data(data=hetero_nn_0.output.data))
pipeline_img.compile()
pipeline_img.fit()
# 获得结果
pipeline_img.get_component('hetero_nn_0').get_output_data() # get result
![[沧海月明珠有泪]两数求和](https://img-blog.csdnimg.cn/img_convert/11d8aa859eb07bf39d6ee7caf5f2df05.png)