很多时候想要测试代码运行时间,或者比较2个运行的效率。 最简单的方法就是Sytem.currentTimeMillis记录2开始和结束时间来算
但是Java 代码越执行越快,放在后面的方法会有优势,这个原因受留个眼,以后研究。大概有受类加载,缓存预热, jit 编译优化等原因。
简单点的StopWatch
//创建对象
StopWatch s = new StopWatch();
//计时
s.start("这一次的名字");
....程序
//结束
s.stop();
//生成一个字符串,其中包含描述所有已执行任务的表。
System.out.println(s.prettyPrint());
多个对象
需要有参构造
//使用给定的 ID 构造一个新 StopWatch 。
//当我们有来自多个秒表的输出并需要区分它们时,该 ID 很方便。
public StopWatch(String id)
其他的应该不太用的着
JMH
一款一款官方的微基准测试工具 - JMH.
JMH(Java Microbenchmark Harness)是用于代码微基准测试的工具套件,主要是基于方法层面的基准测试,精度可以达到纳秒级。使用 JMH 可以让你方便快速的进行一次严格的代码基准测试,并且有多种测试模式,多种测试维度可供选择;而且使用简单、增加注解便可启动测试。
加入依赖
他们说高版本jdk自带,我用的jdk17不知道为啥没有,也没有找到有教程。
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<version>1.35</version>
</dependency>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<version>1.35</version>
</dependency>
插件
这里可以使用JMH Java Microbenchmark Harness插件快速生成。而且可以像 JUnit 一样,运行单独的 Benchmark 方法\运行类中所有的 Benchmark 方法.
生成代码
右边可以直接运行
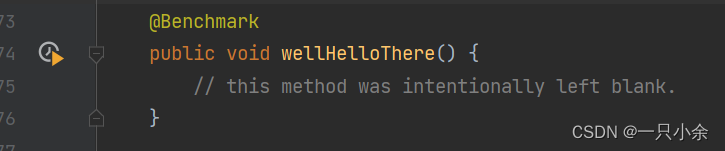
第一个案列
将要测试的方法添加@Benchmark注解即可。
然后用main方法启动就可以了。
public class JMHSample_01_HelloWorld {
@Benchmark
public void wellHelloThere() {
// this method was intentionally left blank.
}
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(JMHSample_01_HelloWorld.class.getSimpleName())
.forks(1)
.build();
new Runner(opt).run();
}
}
最后的结果,前面还有一大堆,在结果进行分析

结果分析(逐行分析)
结果输出有这样几个部分
版本和参数
// JMH版本号
# JMH version: 1.35
//jdk的版本和路径参数
# VM version: JDK 17, Java HotSpot(TM) 64-Bit Server VM, 17+35-LTS-2724
# VM invoker: D:\study\app\jdk\bin\java.exe
# VM options: -javaagent:D:\idea\IntelliJ IDEA 2021.3.3\lib\idea_rt.jar=9272:D:\idea\IntelliJ IDEA 2021.3.3\bin -Dfile.encoding=UTF-8
//黑洞模式
# Blackhole mode: compiler (auto-detected, use -Djmh.blackhole.autoDetect=false to disable)
//预热的次数和每一次的时间
# Warmup: 5 iterations, 10 s each //5次每次10s
// 测试的次数和时间
# Measurement: 5 iterations, 10 s each
// 超时,每次迭代10分钟
# Timeout: 10 min per iteration
//线程
# Threads: 1 thread, will synchronize iterations
//输出结果打印方式
# Benchmark mode: Throughput, ops/time//吞吐量
//执行的类
# Benchmark: org.openjdk.jmh.samples.JMHSample_01_HelloWorld.wellHelloThere
每次的统计
# Run progress: 0.00% complete, ETA 00:01:40
# Fork: 1 of 1
# Warmup Iteration 1: 1895950720.598 ops/s
# Warmup Iteration 2: 1906625977.172 ops/s
# Warmup Iteration 3: 2580159163.977 ops/s
# Warmup Iteration 4: 2564641382.865 ops/s
# Warmup Iteration 5: 2561493559.473 ops/s
Iteration 1: 2529900034.146 ops/s
Iteration 2: 2497119600.056 ops/s
Iteration 3: 2512703440.984 ops/s
Iteration 4: 2568341912.143 ops/s
Iteration 5: 2574424415.895 ops/s
这一部分是总体的统计
有最小值平均值和最大值 、标准差、置信区间
Result "org.openjdk.jmh.samples.JMHSample_01_HelloWorld.wellHelloThere":
2536497880.645 ±(99.9%) 130763529.779 ops/s [Average]
(min, avg, max) = (2497119600.056, 2536497880.645, 2574424415.895), stdev = 33958873.426
CI (99.9%): [2405734350.865, 2667261410.424] (assumes normal distribution)
一些介绍,没啥用
# Run complete. Total time: 00:01:41
REMEMBER: The numbers below are just data. To gain reusable insights, you need to follow up on
why the numbers are the way they are. Use profilers (see -prof, -lprof), design factorial
experiments, perform baseline and negative tests that provide experimental control, make sure
the benchmarking environment is safe on JVM/OS/HW level, ask for reviews from the domain experts.
Do not assume the numbers tell you what you want them to tell.
NOTE: Current JVM experimentally supports Compiler Blackholes, and they are in use. Please exercise
extra caution when trusting the results, look into the generated code to check the benchmark still
works, and factor in a small probability of new VM bugs. Additionally, while comparisons between
different JVMs are already problematic, the performance difference caused by different Blackhole
modes can be very significant. Please make sure you use the consistent Blackhole mode for comparisons.
这里比较重要,一般都会看
| 属性 | 介绍 |
|---|---|
| benchmark | 执行的 |
| mod | 执行模式 |
| cnt | 轮次 |
| score | 执行的结果平均值 |
| error | 误差 |
| units | 单位 |
Benchmark Mode Cnt Score Error Units
JMHSample_01_HelloWorld.wellHelloThere thrpt 5 2536497880.645 ± 130763529.779 ops/s
进程已结束,退出代码0
使用介绍
只打算简单介绍对象的配置,注解肯定用的更舒服。
对象配置
创建对象后在后面逐个添加属性,然后在使用Runner类启动。

Benchmark
为该方法生成基准代码,在基准列表中将该方法注册为基准,从注释中读出默认值,并大致为基准测试运行准备环境。
适用:ElementType.METHOD,后面用注解表示了
BenchmarkMode
基准测试模式声明运行此基准测试的默认模式。有关可用的基准测试模式
@Target({ElementType.METHOD, ElementType.TYPE})
Mode[] value:模式,必须的
AverageTime - 调用的平均时间
SampleTime - 随机取样,最后输出取样结果的分布,输出会比较多,但是不会全部统计
SingleShotTime - 只会执行一次,通常用来测试冷启动时候的性能。
All - 所有的benchmark modes。
Fork
执行次数,除了value默认就好了
@Target({ElementType.METHOD,ElementType.TYPE})
int BLANK_FORKS = -1;
String BLANK_ARGS = "blank_blank_blank_2014";
/** @return 表示该benchMark执行多少次 */
int value() default BLANK_FORKS;
/** @return 线束应分叉并忽略结果的次数 */
int warmups() default BLANK_FORKS;
/** @return 要运行的 JVM 可执行文件 */
String jvm() default BLANK_ARGS;
/** @return 要在命令行中替换的 JVM 参数 */
String[] jvmArgs() default { BLANK_ARGS };
/** @return 要在命令行中预置的 JVM 参数*/
String[] jvmArgsPrepend() default { BLANK_ARGS };
/** @return :要在命令行中追加的 JVM 参数*/
String[] jvmArgsAppend() default { BLANK_ARGS };
fork(0)同一个进程执行一次
fork(1)新建一个进程执行一次
fork(n)新建n个进程
默认的-1等同于传5
Warmup
允许为基准设置默认预热参数
@Target({ElementType.METHOD,ElementType.TYPE})
/** @return 预热迭代次数 */
int iterations() default BLANK_ITERATIONS;
/** @return每次预热迭代的时间 */
int time() default BLANK_TIME;
/** @return 预热迭代持续时间的时间单位 */
TimeUnit timeUnit() default TimeUnit.SECONDS;
/** @return 批大小:每个操作的基准方法调用数*/
int batchSize() default BLANK_BATCHSIZE;
Measurement
设置默认测量参数。
这个和上面一样,就换成翻译了
@Target({ElementType.METHOD,ElementType.TYPE})
/** @return Number of measurement iterations */
int iterations() default BLANK_ITERATIONS;
/** @return Time of each measurement iteration */
int time() default BLANK_TIME;
/** @return Time unit for measurement iteration duration */
TimeUnit timeUnit() default TimeUnit.SECONDS;
/** @return Batch size: number of benchmark method calls per operation */
int batchSize() default BLANK_BATCHSIZE;
OutputTimeUnit
为统计结果的时间单位
@Target({ElementType.METHOD,ElementType.TYPE})
value: 时间单位
State
状态对象通常作为参数注入到方法中Benchmar。
@State 可以被继承使用,如果父类定义了该注解,子类则无需定义。由于 JMH 允许多线程同时执行测试,不同的选项含义如下:
@Target(ElementType.TYPE)
Scope.Benchmark:所有测试线程共享一个实例,测试有状态实例在多线程共享下的性能
Scope.Group:同一个线程在同一个 group 里共享实例
Scope.Thread:默认的 State,每个测试线程分配一个实例
感觉这个不太好理解,这里看官方示例
这个代码中measureShared多个线程会同时操作这个x。
如2线程轮流那么x是1 2 3 4 5 6
measureUnshared同时操作那么就是
1 1 2 2 3 3
@State(Scope.Benchmark)
public static class BenchmarkState {
volatile double x = Math.PI;
}
@State(Scope.Thread)
public static class ThreadState {
volatile double x = Math.PI;
}
@Benchmark
public void measureUnshared(ThreadState state) {
// 所有基准测试线程都将调用此方法。
//
// 但是,由于 ThreadState 是 Scope.Thread,因此每个线程将拥有自己的状态副本,此基准将衡量未共享的情况。
state.x++;
}
@Benchmark
public void measureShared(BenchmarkState state) {
// 由于 BenchmarkState 是 Scope.Benchmark,所有线程都将共享状态实例,我们最终将测量共享案例。
state.x++;
}
如果标记到类,我们看第四个代码.
那么我们相当于可以调用这个类的属性,而不用注入了。
@State(Scope.Thread)
public class JMHSample_04_DefaultState {
double x = Math.PI;
@Benchmark
public void measure() {
x++;
}
Setup and TearDown
会在执行 benchmark 之前/后被执行,主要用于初始化/资源处理。
@Target(ElementType.METHOD)
此方法的级别。
Level value() default Level.Trial;
参数
Level.Trial:Benchmark级别,benchmark执行完执行,最大的。
Level.Iteration:执行迭代级别,每次执行完都会
Level.Invocation:每次方法调用级别,每次方法调用就都执行
| 类型 | 结果 |
|---|---|
| Trial | Iteration 2:x = 1.059139639E9 |
| Iteration | # Warmup Iteration x = 3.54500352E8 Iteration 1: x = 7.0472257E8 Iteration 2:x = 1.059033135E9 |
| Invocation | 每次都调用一下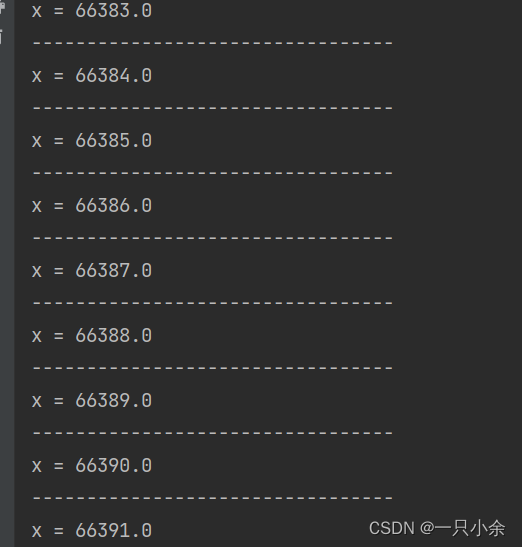 |
@TearDown(Level.Iteration)
public void check() {
System.out.println("---------------------------------");
System.out.println("x = " + x);
}
@Benchmark
public void measureRight() {
x++;
}
死码消除问题
介绍
在第8给示例中主要介绍了死码优化的问题。
如果一个方法调用后没有什么用,就在编译器被消除了,但这给我做基准测试带了一些麻烦
我们看第八个:
讲道理来演示的意思是measureWrong比rigth应该慢超级多,但是我怎么测试都测试不出来,不知道为什么。而且第九个也测试不出来。
private double x = Math.PI;
@Benchmark
public void baseline() {
// do nothing, this is a baseline
}
@Benchmark
public void measureWrong() {
// This is wrong: result is not used and the entire computation is optimized away.
Math.log(x);
}
@Benchmark
public double measureRight() {
// This is correct: the result is being used.
return Math.log(x);
}

解决
第九个示例告诉我们解决。
不过我测不出来。
- 使用他
- 注入Blackhole bh 对象,使用consume方法调用
@Benchmark
public void measureRight_2(Blackhole bh) {
bh.consume(Math.log(x1));
bh.consume(Math.log(x2));
}
同一个进程会互相影响
众所周知,JVM擅长按配置文件优化。这对基准测试不利,因为不同的测试可以将它们的配置文件混合在一起,然后为每个测试呈现“统一错误”的代码。分叉(在单独的进程中运行)每个测试都有助于避免此问题。默认情况下,JMH 将分叉测试。
@Benchmark
@Fork(0)
public int measure_1_c1() {
return measure(c1);
}
/*
* Then Counter2...
*/
@Benchmark
@Fork(0)
public int measure_2_c2() {
return measure(c2);
}
/*
* Then Counter1 again...
*/
@Benchmark
@Fork(0)
public int measure_3_c1_again() {
return measure(c1);
}
请注意,C1 更快,C2 更慢,但 C1 又慢了!这是因为 C1 和 C2 的配置文件已合并在一起。请注意分叉运行的测量是多么完美。

还有些案例,不过不想学了,这些够现在的用了,以后需要在学