文章目录
- 一、安装MFA
- 1.安装anaconda
- 2.创建并进入虚拟环境
- 3.安装pyTorch
- 二、训练新的声学模型
- 1.确保数据集的格式正确
- 2.训练声音模型-导出模型和对齐文件
- 3.报错处理
- 1.遇到类似: Command ‘[‘createdb’,–host=‘ ’, ‘Librispeech’]’ returned non-zero exit status 1 的报错
一、安装MFA
官方安装链接
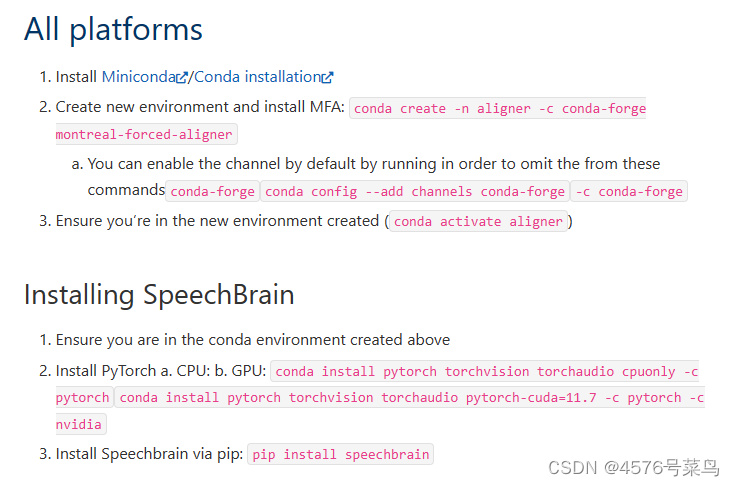
1.安装anaconda
2.创建并进入虚拟环境
conda create -n aligner -c conda-forge montreal-forced-aligner
conda activate aligner


3.安装pyTorch
CPU环境:
conda install pytorch torchvision torchaudio cpuonly -c pytorch
GPU环境:
conda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidia

二、训练新的声学模型
1.确保数据集的格式正确
mfa validate ~/mfa_data/my_corpus ~/mfa_data/my_dictionary.txt
~/mfa_data/my_corpus :数据集
~/mfa_data/my_dictionary.txt :字典
此命令将查看语料库,并确保 MFA 正确解析所有内容。MFA 支持几种不同类型的语料库格式和结构,但通常核心要求是您应该拥有具有相同名称的声音文件和转录文件对(扩展名除外)。查看验证程序输出,确保说话人数以及文件和语句数符合预期,并且词汇不足 (OOV) 项的数量不会太高。

2.训练声音模型-导出模型和对齐文件
mfa train ~/mfa_data/my_corpus ~/mfa_data/my_dictionary.txt ~/mfa_data/new_acoustic_model.zip # 仅导出声音模型
mfa train ~/mfa_data/my_corpus ~/mfa_data/my_dictionary.txt ~/mfa_data/my_corpus_aligned # 仅导出对齐文件
mfa train ~/mfa_data/my_corpus ~/mfa_data/my_dictionary.txt ~/mfa_data/new_acoustic_model.zip ~/mfa_data/my_corpus_aligned # 导出声音模型和对齐文件
如果数据很大,则可能需要增加 MFA 使用的作业数。
如果训练成功,将在输出目录中看到 TextGrids。TextGrid 导出与使用经过训练的声学模型运行时的导出相同。
如果选择导出声学模型,则现在可以将此模型用于其他实用程序和用例,例如通过向字典添加概率 (mfa train_dictionary) 或转录音频文件 (mfa 转录) 来优化发音词典以获取新数据。

等着训练完成吧~
3.报错处理
1.遇到类似: Command ‘[‘createdb’,–host=‘ ’, ‘Librispeech’]’ returned non-zero exit status 1 的报错
点击:原因是没有启动服务