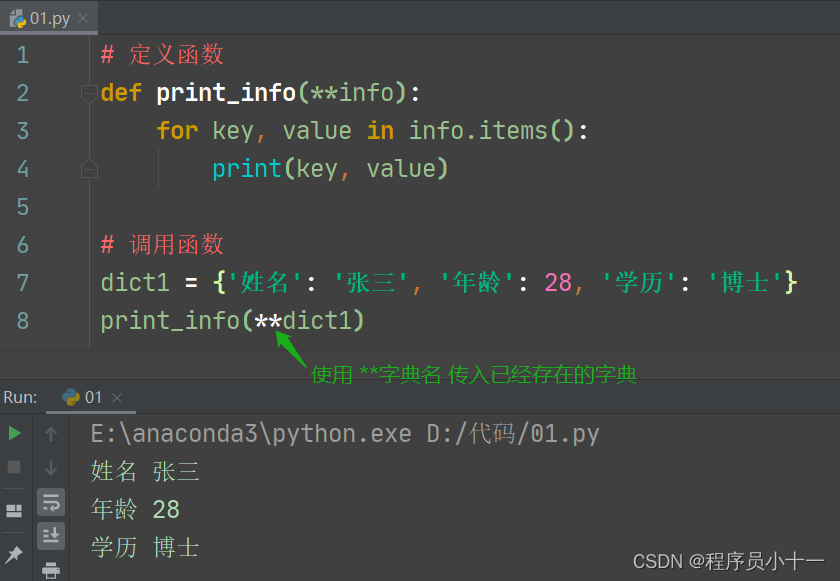
昨天面试大数据开发岗位,面试官问了一个开放性的问题,讲讲你对kafka的认识,一下有些懵住,不知道从哪里开始谈起。
今天和另外一个大佬聊天,他告诉我,就是要背面试题,背面试题是一种有效的学习方式,不仅面试有用,后面工作中也能用到。他说面试官也很忙,问的一些问题,都是在网上搜的,你要能答出来,说明你还是有背面试题的,能沉下心来做事情。
是以,总结一下,网上常见的kafka的面试题,为准备面试。
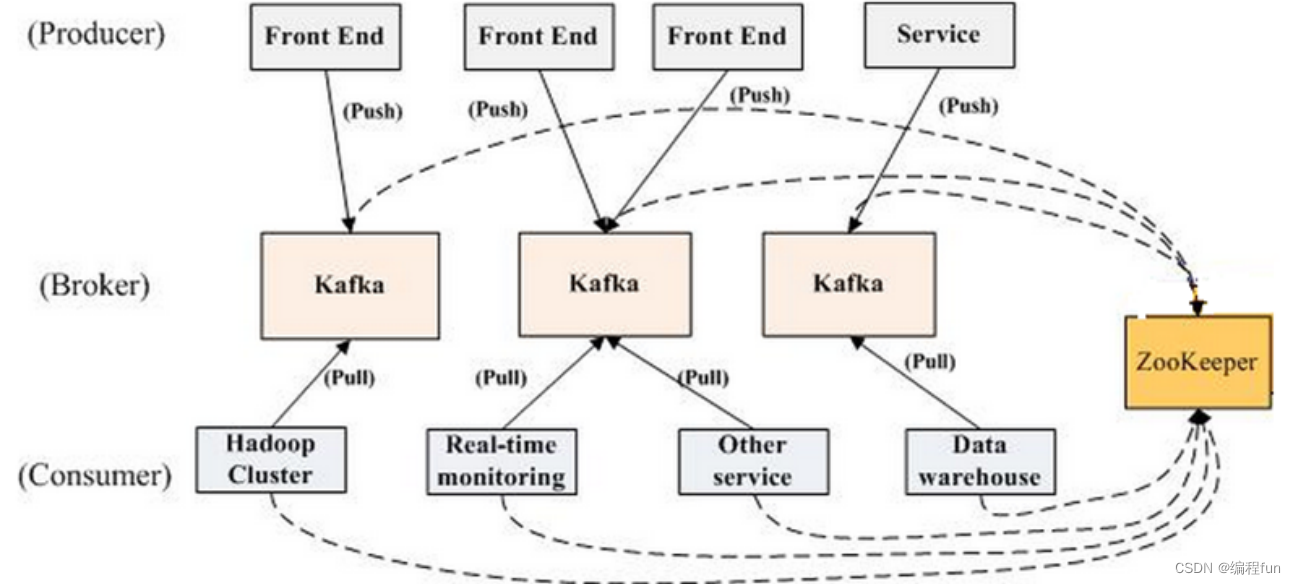
1. 讲⼀下kafka 的架构
Producer
:消息⽣产者。
Producer
可以发送消息到
Topic
Broker
:每个
Broker
⾥包含了不同
Topic
的不同
Partition
,
Partition
中包含了有序的消息
Consumer:消息消费者。Consumer
可以从
Topic
读取消息进⾏消费
便于理解的图:
2. kafka的message包括哪些信息
⼀个
Kafka
的
Message
由⼀个固定⻓度的
header
和⼀个变⻓的消息体
body
组成
header
部分由⼀个字节的
magic(
⽂件格式)
和四个字节的
CRC32(
⽤于判断
body
消息体是否正常
)
构成。
当
magic
的值为
1
的时候,会在
magic
和
crc32
之 间多⼀个字节的数据:attributes(
保存⼀些相关属性,⽐如是否压缩、压缩格式等等
)
;如果
magic
的值为
0
,那么 不存在attributes
属性
body
是由
N
个字节构成的⼀个消息体,包含了具体的
key/value
消息
3. kafka 实现高吞吐的原理
- 读写⽂件依赖OS⽂件系统的⻚缓存,⽽不是在JVM内部缓存数据,利⽤OS来缓存,内存利⽤率⾼
- sendfile技术(零拷⻉),避免了传统⽹络IO四步流程
- ⽀持End-to-End的压缩
- 顺序IO以及常量时间get、put消息
- Partition 可以很好的横向扩展和提供⾼并发处理