Python深度学习入门
第一章 Python深度学习入门之环境软件配置
第二章 Python深度学习入门之数据处理Dataset的使用
第三章 数据可视化TensorBoard和TochVision的使用
第四章 UNet-Family中Unet、Unet++和Unet3+的简介
第五章 个人数据集的制作
深度学习数据集的制作
- Python深度学习入门
- 前言
- 一、选择合适的标注工具进行标注
- 1、Labelme
- 2、Arcgis
- 2.1 使用ArcMap打开原图片(tif格式图片)
- 2.2 创建标注图层shp文件
- 2.3 样本标注准备工作
- 2.4 样本标注
- 2.5 给样本不同类别赋予不同颜色
- 二、标签图像处理
- 1、相同对象类别合并
- 2、shapefle文件转tif图像
- 3、统一图像大小
- 4、小样本制作
- 5、创建训练样本文件夹目录
- 总结
前言
众所周知,深度学习的三大要素:数据、算法、算力。这三者是相辅相成的、缺一不可。但越来越多的学者开始关注算法的设计与优化,而忽略了数据在深度学习中的重要地位。但数据是基础,任何研究都离不开数据,并且优秀的算法模型只有在大规模的数据集上进行的实验结果才具有说服力。因此,今天我将向大家介绍如何制作我们自己的数据集。
一、选择合适的标注工具进行标注
随着深度学习的不断发展,数据集的标注工具也是层出不穷,我这里简单介绍几个,然后深入介绍我目前使用的标注工具ArcGIS,做遥感高光谱的同学,我强力推荐这个软件!!!
1、Labelme
Lableme是一款开源的图像标注工具,常用做检测,分割和分类任务的图像标注,它的下载和使用也是非常的方便。我们可以直接从Anaconda Prompt中通过以下指令进行安装。
pip install labelme
然后等待下载完成,再输入启动指令即可进行标注了。
labelme
2、Arcgis
Arcgis是一款非常强大的制图软件,功能十分强大,对于图像的制作、提取、分割等等一系列操作都可以简单完成,这也是我目前使用的软件。首先我们需要下载这款软件,下载链接我们可以通过这个博主的链接进行下载:https://zhuanlan.zhihu.com/p/473689369
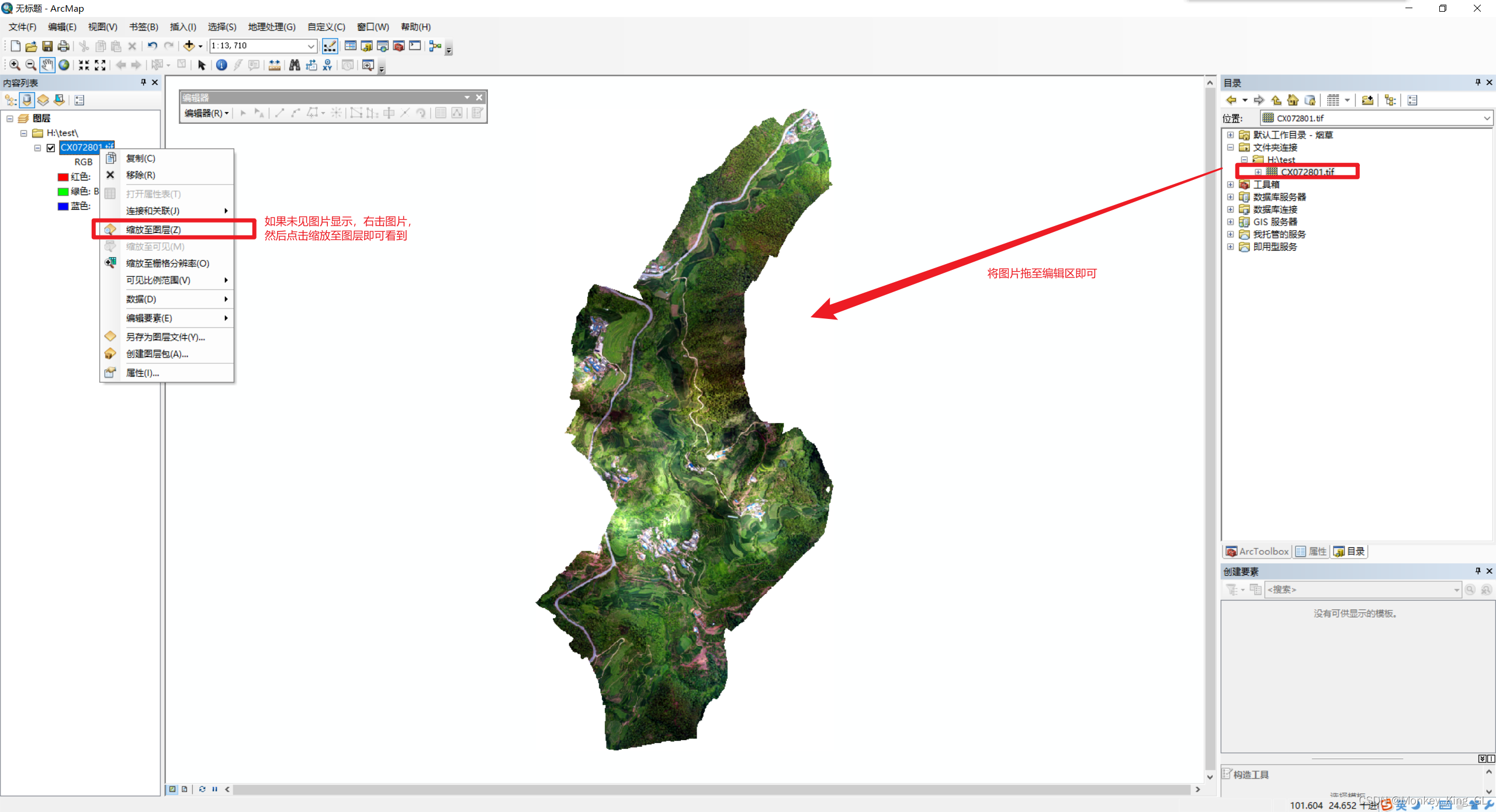
2.1 使用ArcMap打开原图片(tif格式图片)
下载完软件后,我们打开ArcGis中的ArcMap软件

然后我们就需要新建一个地图模板,接着我们打开右侧的文件目录结构右击文件夹链接,这样我们就可以将地图模板与我们的图片文件夹进行链接,方便操作。
 链接完文件夹,我们就可以将图片拉至我们的编辑区了。
链接完文件夹,我们就可以将图片拉至我们的编辑区了。
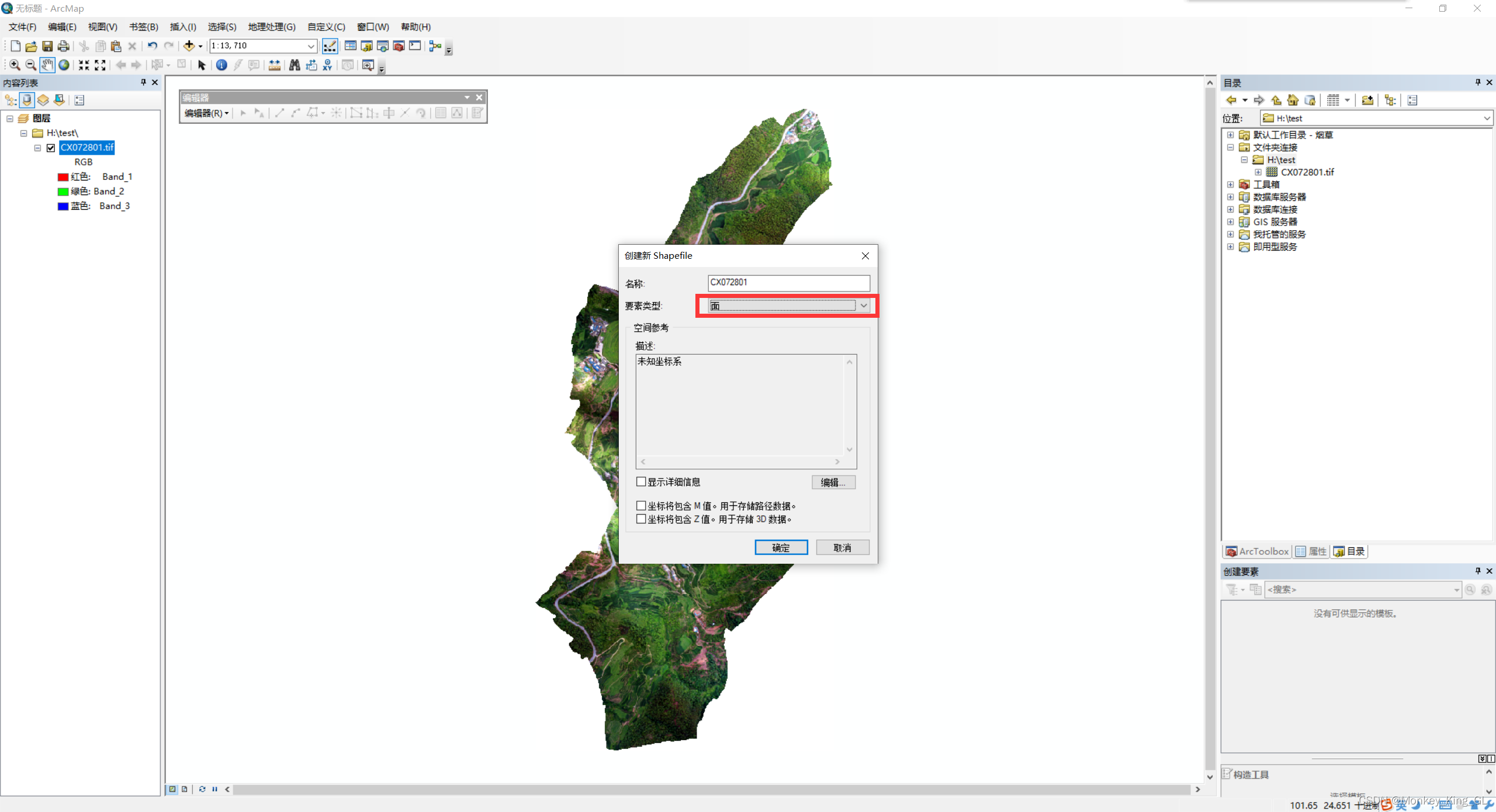
2.2 创建标注图层shp文件
右击图片所在文件夹,在该文件夹下创建Shapefile文件,要素类型选择面,并且一定要选择坐标系,坐标系的类型要和原图的坐标系类型保持一致!

2.3 样本标注准备工作
为了标注方便,我们需要先将初始标注框填充颜色改为无颜色,这样我们在标注的过程中就不会被颜色给遮住原图。然后我们需要给图层添加class属性来表示标注的类别,右击shp图层选中打开属性表,然后点击下面的箭头选中添加字段,输入名称为class,然后确认即可。
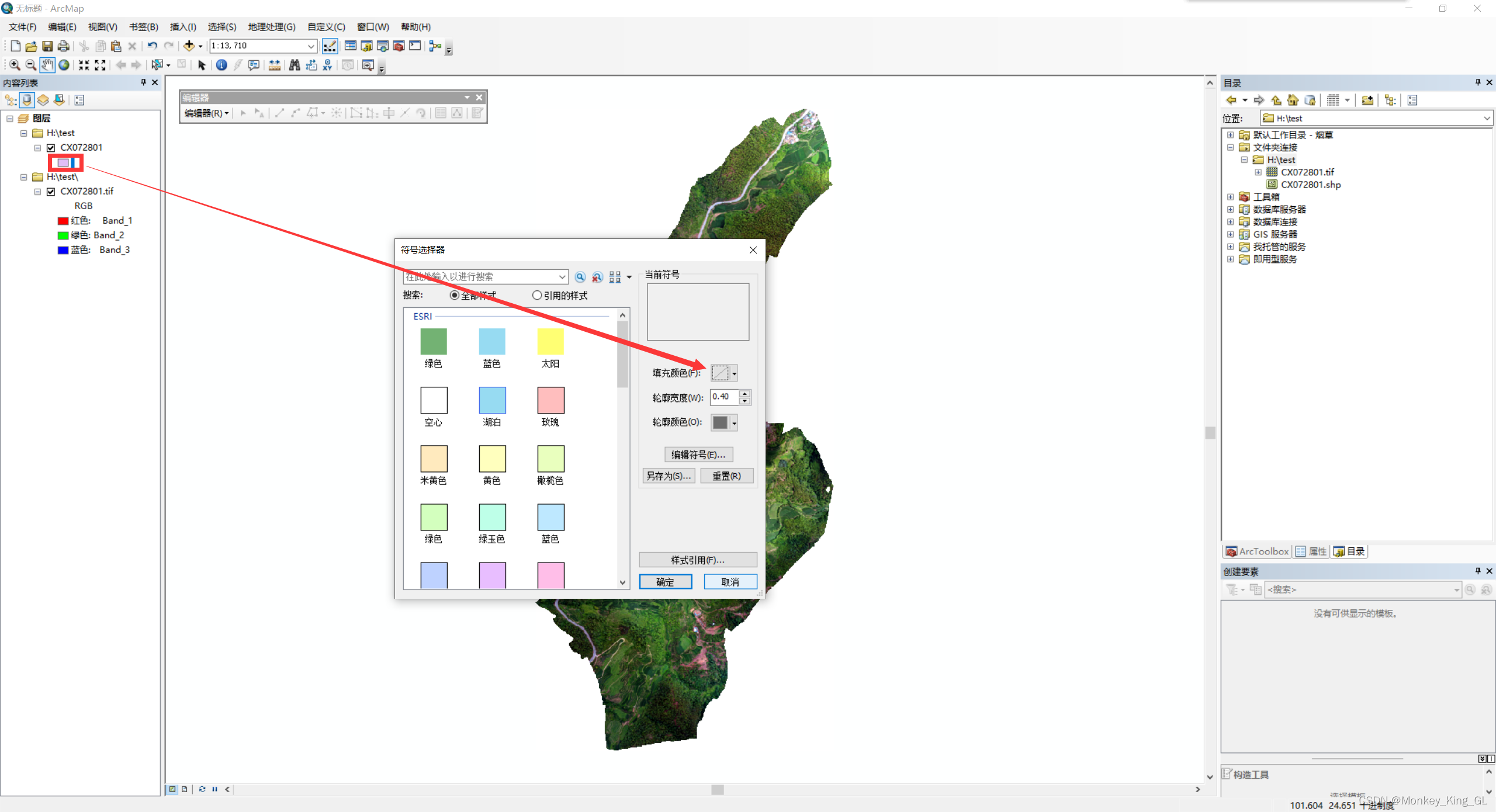
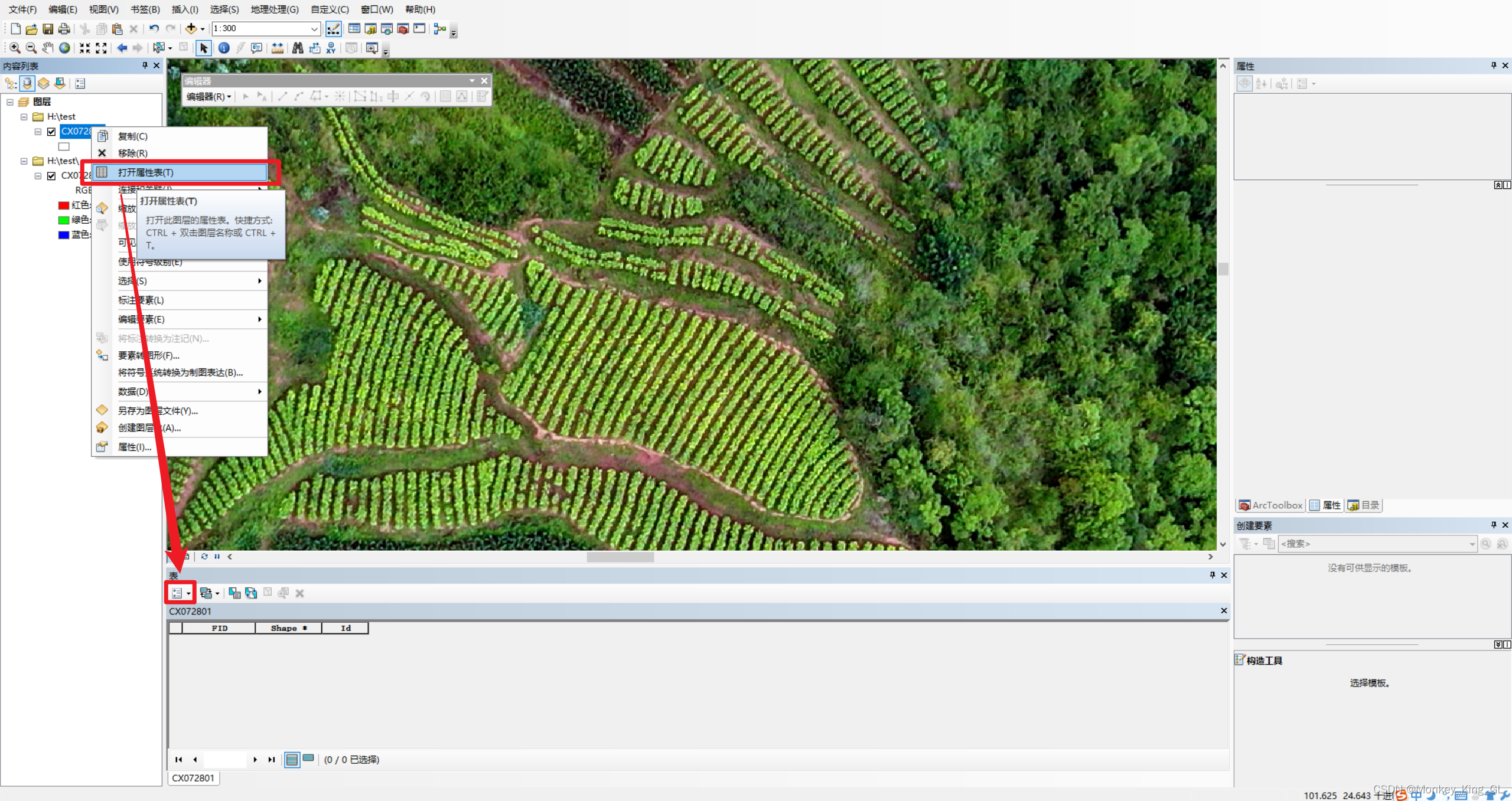
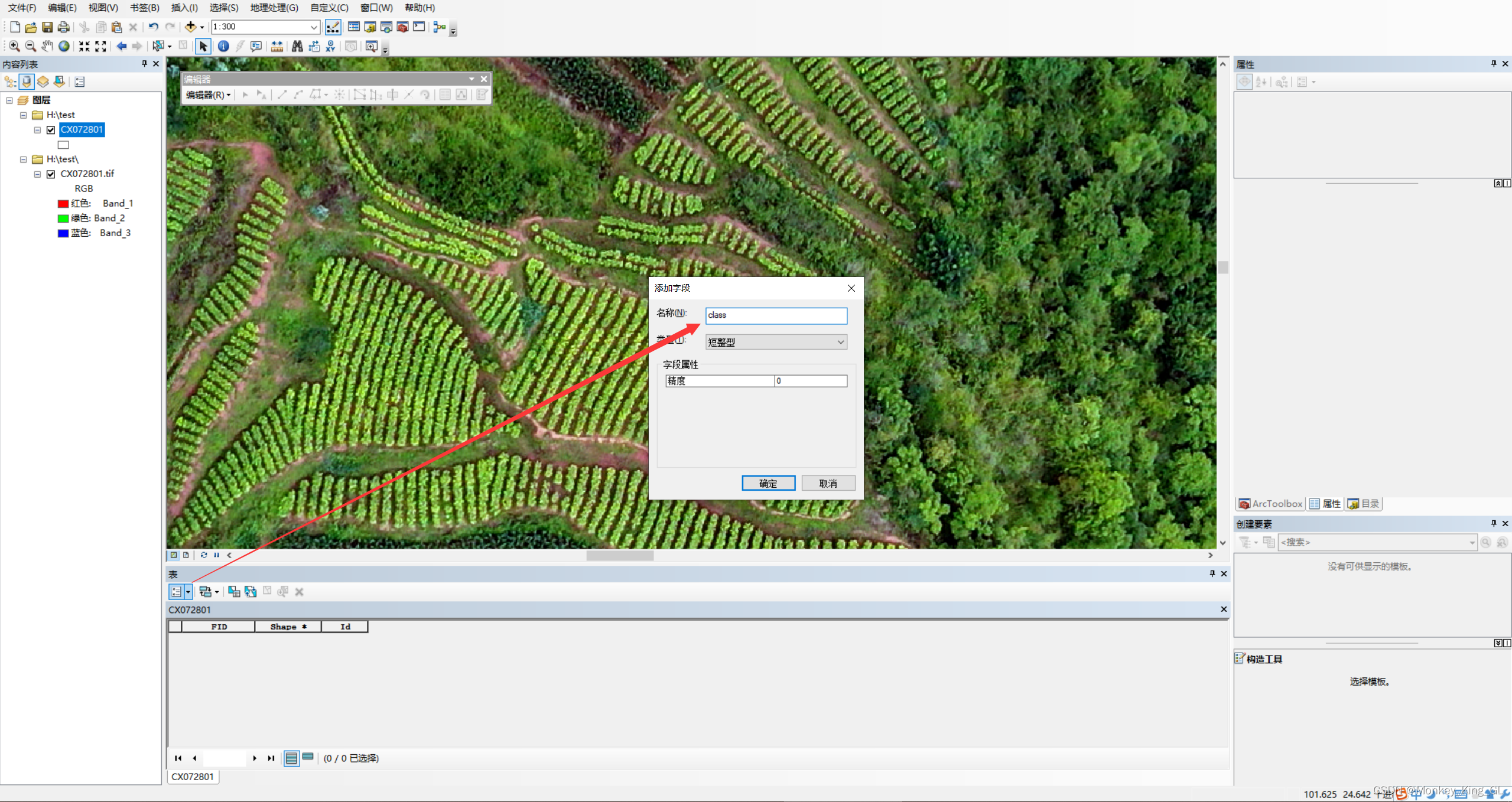
2.4 样本标注
添加完字段,我们就点击上面编辑器,选择开始编辑,然后选中图层中的面,然后沿着我们的标注目标对象的边缘不断点(要想数据集好,我们就要尽可能的让目标对象边缘精准),最后通过双击结束标注,最后在右侧的属性栏给这个目标对象填入类别标签(我这里是1)。

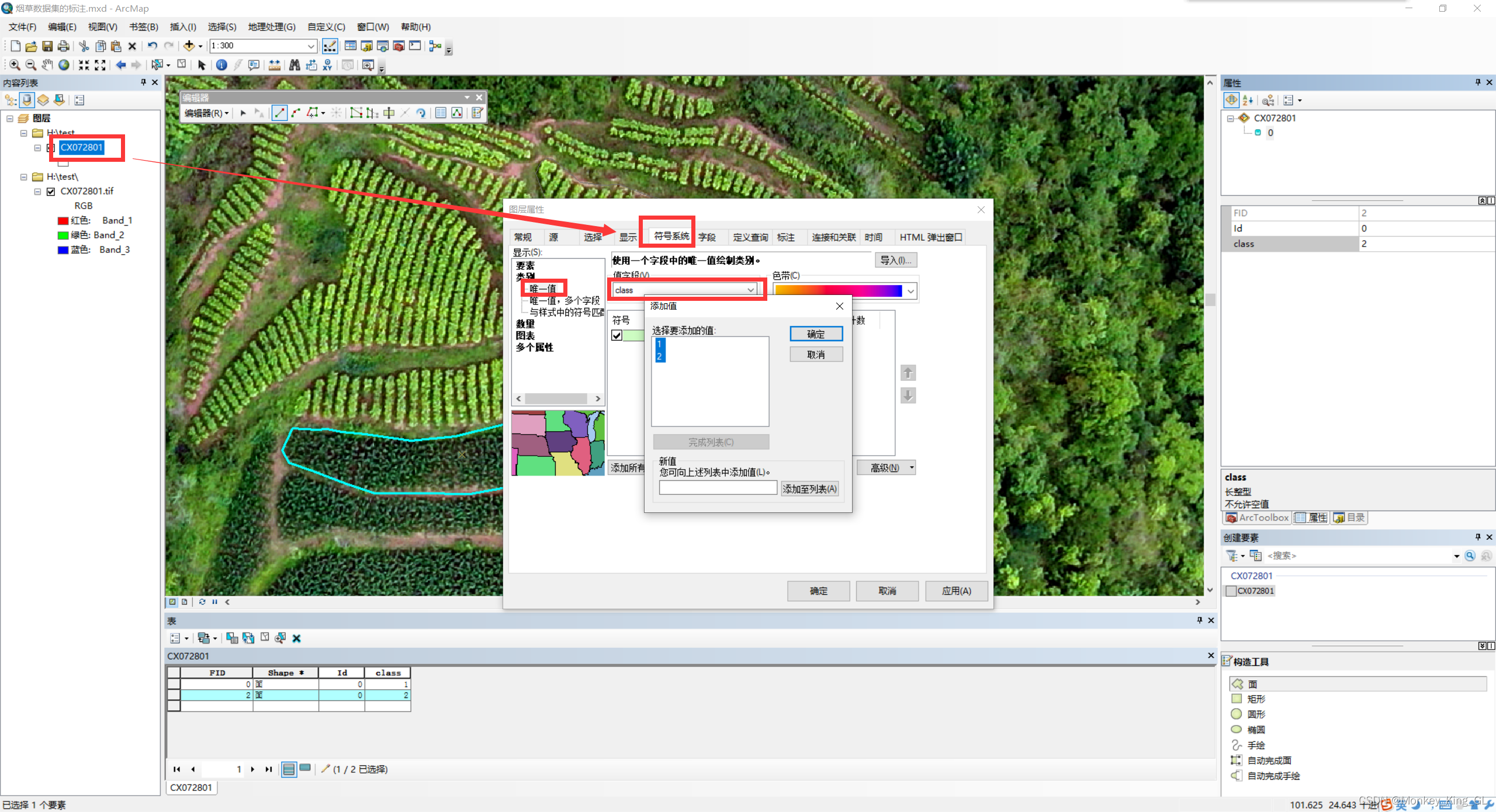
2.5 给样本不同类别赋予不同颜色
我们标注结束后,我们就可以给类别不同的颜色加以区分了,例如我这里有两类:1类用绿色,2类用黄色。首先双击图层,然后选择符号系统—>类别—>唯一值---->值字段(class)—>添加值。然后将我们有的值全部(1和2)添加进来,并选择颜色,点击确定即可。
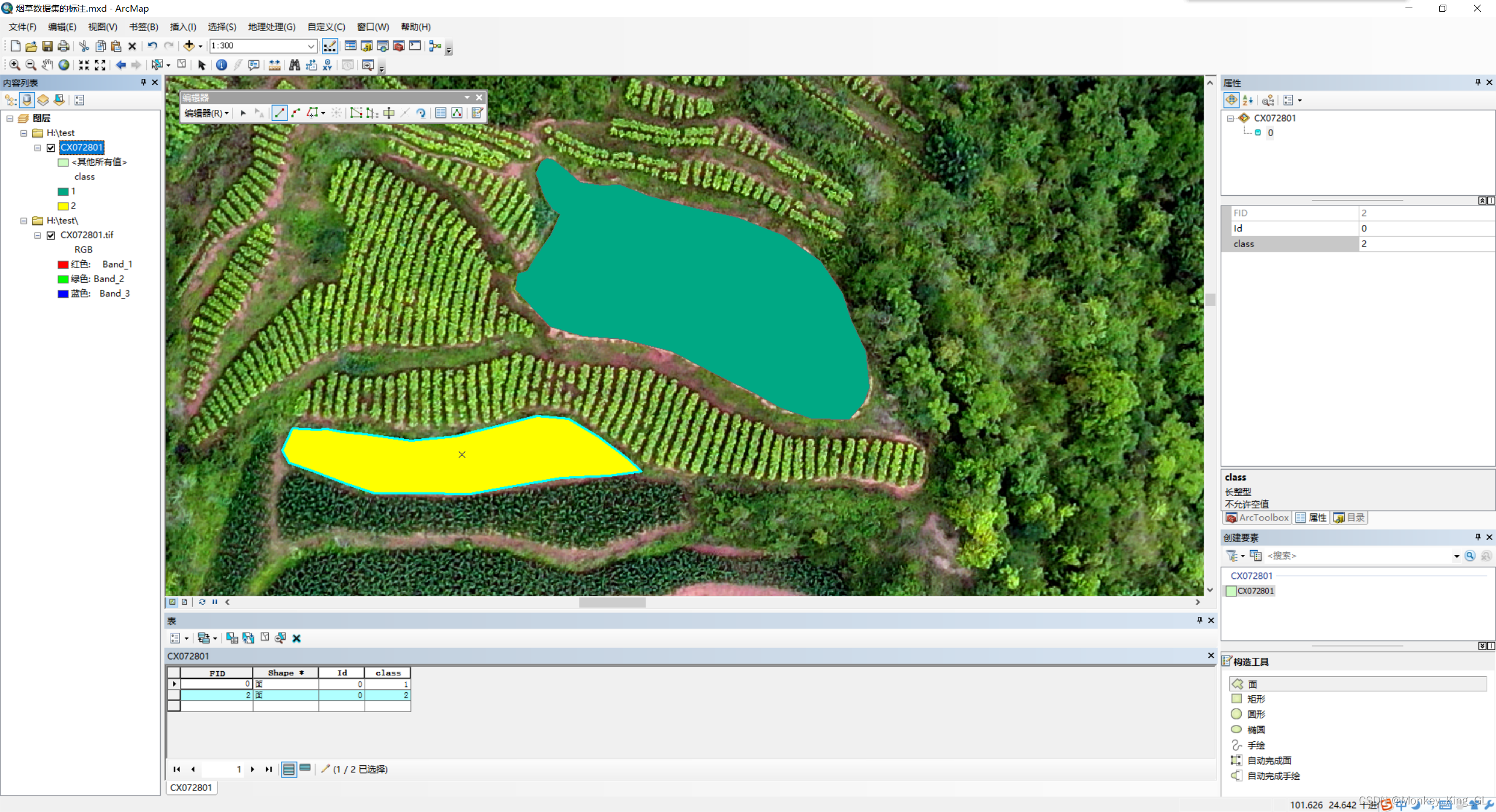
二、标签图像处理
通过以上处理我们将会得到一张与原图一样的标签图像,如下图。那我们如何得到一个一个的小样本呢?在此之前我们需要使用ArcMap对图像再次处理一下。
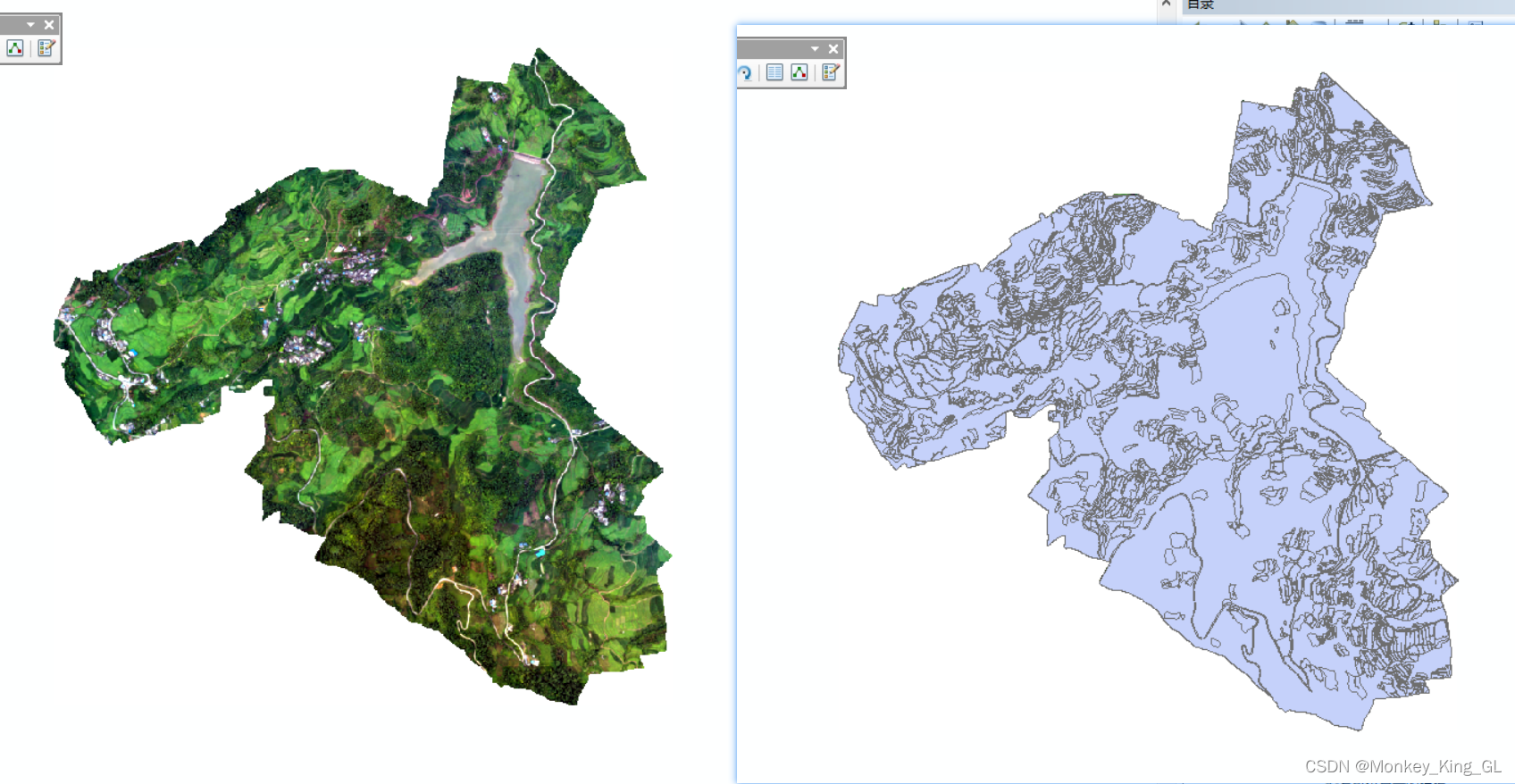
1、相同对象类别合并
得到一张完整的标签图像之后我们需要将同一类别的合并,让属性列表最终每一个类别只有一个对象。首先双击class,让类别排好序,然后选中类别相同的,点击编辑器中的合并按钮就可以将选中的对象合并。最终要达到每个类别最多只有一条记录(如下图)。

2、shapefle文件转tif图像
我们的标签图像的文件格式为shp,但是我们的原图为tif,因此我们需要通过ArcMap将shp转为tif。步骤流程如下图。
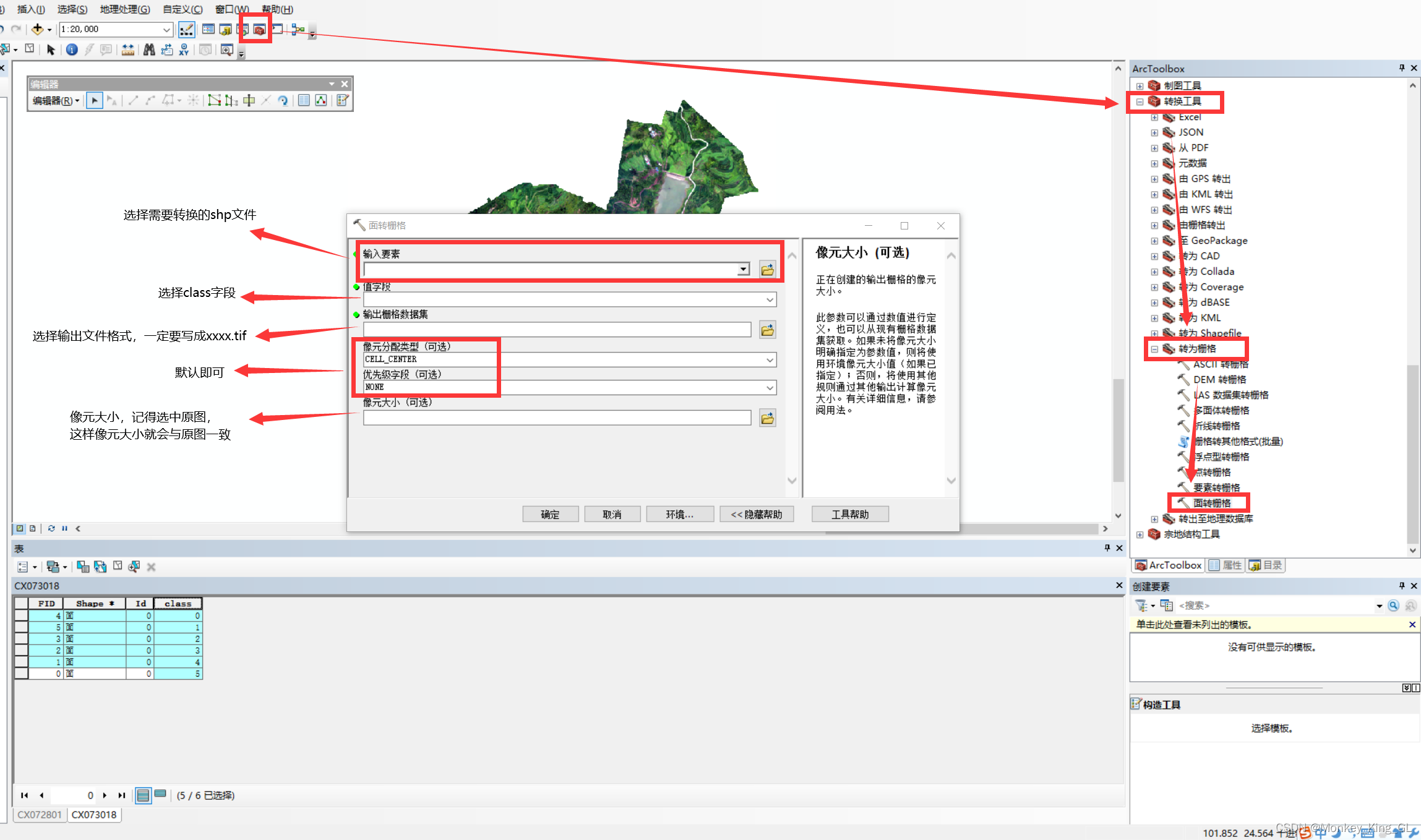
3、统一图像大小
为了防止后面对图像裁剪出现问题,我们需要对原图和标签图像进行大小的统一。首先我们按照上面的方法创建一个新的shp图层,在该图层上画一个刚好可以圈住原图内容的矩形,然后保存。如下图:
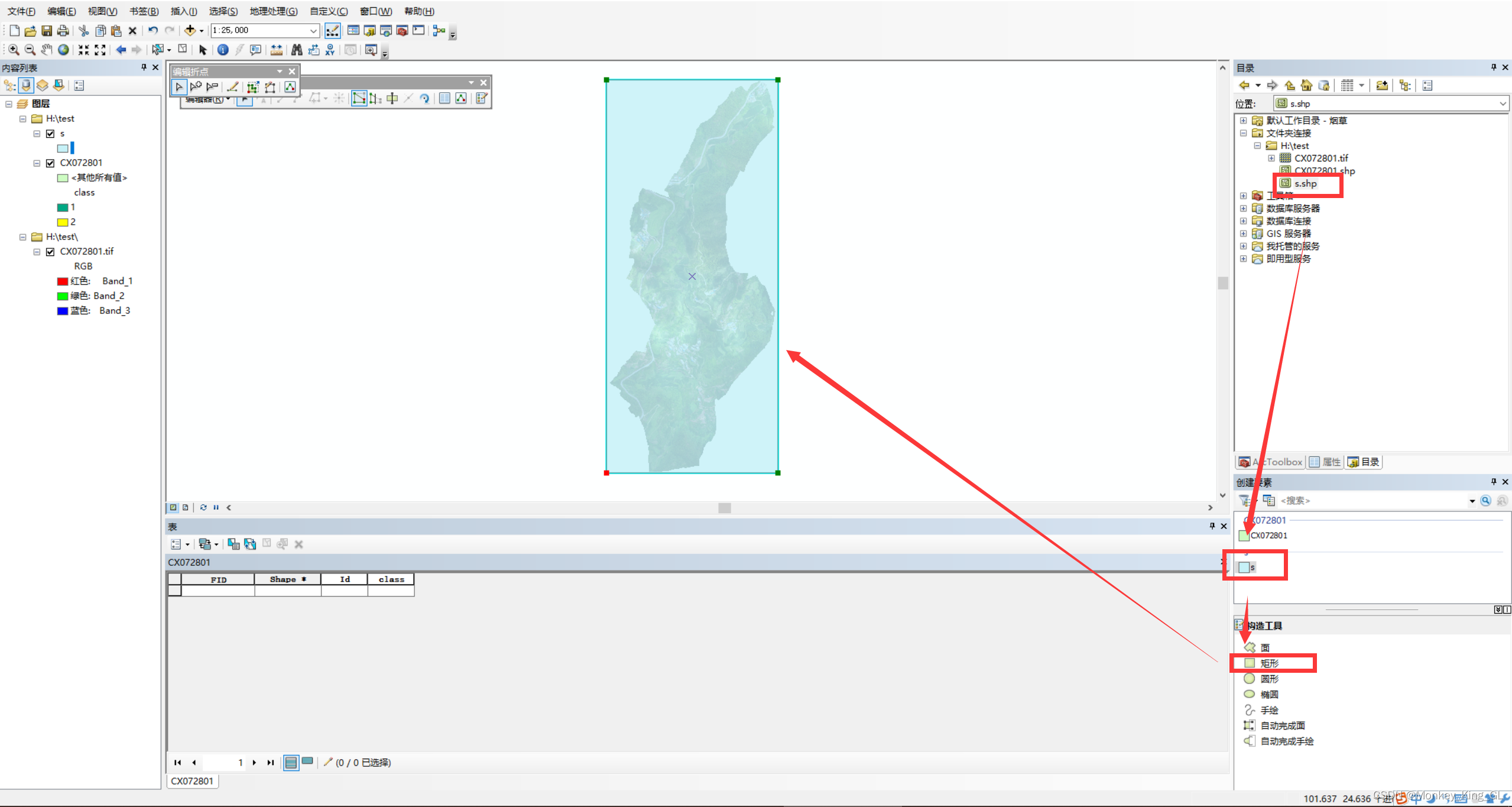
接着我们就可以以这个矩形为基准,裁剪原图和标签图像了。步骤如下:

4、小样本制作
通过以上处理我们就得到了一样尺寸,一一对应的原图和标签图了,接下来我们就需要对图像进行裁剪,裁剪代码如下:
#!/usr/bin/env python3
# coding=utf-8
import random
import os
import numpy as np
import sys
from shutil import copyfile, rmtree
from argparse import ArgumentParser
import rasterio
from rasterio.windows import Window
def creat_dataset(image_num=10000, imgPath=None, labelPath=None, basePath=None):
###landsat数据集
img_w = 224 # 切割小图的宽
img_h = 224 # 切割小图的长
sampleImg = os.path.join(basePath, "sampleImgs") # 要提前创建好样本文件夹sampleImgs
sampleLab = os.path.join(basePath, "sampleLabels") # 要提前创建好样本文件夹sampleLabels
if(os.path.exists(sampleImg)):
rmtree(sampleImg)
os.mkdir(sampleImg)
if(os.path.exists(sampleLab)):
rmtree(sampleLab)
os.mkdir(sampleLab)
print('creating dataset...')
fpImg = rasterio.open(imgPath)
srcImg = fpImg.read()
band, height, width = srcImg.shape
profileImg = fpImg.profile
fpLabel = rasterio.open(labelPath)
srcLabel = fpLabel.read()
band, height, width = srcLabel.shape
profileLabel = fpLabel.profile
print(srcLabel.shape)
print(height)
print(width)
count = 0
for random_width in range(0,width-img_w,img_w):
for random_height in range(0,height-img_h,img_h):
try:
src_roi = srcImg[:, random_height: random_height +
img_h, random_width: random_width + img_w]
label_roi = srcLabel[:, random_height: random_height +
img_h, random_width: random_width + img_w]
window = Window(random_width, random_height, img_w, img_h)
transform = fpImg.window_transform(window)
profileImg.update(width=img_w, height=img_h)
profileImg.update({'transform': transform})
samplePath = (sampleImg + '/%d.tif') % count
outImg = rasterio.open(samplePath, 'w', **profileImg)
outImg.write(src_roi)
window = Window(random_width, random_height, img_w, img_h)
transform = fpLabel.window_transform(window)
profileLabel.update(width=img_w, height=img_h)
profileLabel.update({'transform': transform})
samplePath = (sampleLab + '/%d.tif') % count
outLabel = rasterio.open(samplePath, 'w', **profileLabel)
outLabel.write(label_roi)
count+=1
except:
print("{} file error\n".format(image_sets[i]))
break
count1=0
if __name__ == '__main__':
parser = ArgumentParser()
parser.add_argument('--basePath', default=" ", type=str) # 图片存储文件夹路径
parser.add_argument('--imgPath', default=" ", type=str) # 原图切割图片路径
parser.add_argument('--labelPath', default=" ", type=str) # 标签图切割图片路径
parser.add_argument('--imageNum', default=500, type=int)
args = parser.parse_args()
creat_dataset(image_num=args.imageNum, imgPath=args.imgPath,
labelPath=args.labelPath, basePath=args.basePath)
5、创建训练样本文件夹目录
通过上面小样本的裁剪之后,我们就需要创建模型训练所需要的文件夹了,我们这里使用的是pascal voc的数据集格式,他的目录结构如下图:
.{pascal voc数据集格式}
├── VOC2012
│ ├── ImageSets
│ │ ├── Segmentation
│ │ | ├── train.txt
│ │ | ├── val.txt
│ ├── JPEGImages
│ │ ├── xxx.png
│ │ ├── xxx.png
│ │ ├── xxx.png
│ ├── SegmentationClass
│ │ ├── xxx.png
│ │ ├── xxx.png
创建完上面的文件目录结构之后就把对应的内容放入对应的文件夹,这样我们的训练数据集就制作成功啦!
总结
以上就是我个人在制作数据集的方法和步骤,这期间遇到的很多问题,幸好有师兄帮忙。为了让其他小伙伴少走弯路我就把这个方法一步一步的写给大家,希望可以帮助到大家,然后我个人通过这个方法已经拥有了3.5GB,18000+多张的个人数据集,希望能找个好模型测试一下这批数据。