作品介绍
一、需求分析
1.1 设计背景
气候变化是全球性问题,随着二氧化碳排放的增加生物的生存与生命受到威胁。人类活动对自然界生态系统的破坏,不仅降低了地球生物圈的生产力,威胁到人类社会未来经济的发展,同时还破坏了陆地与大气之间的自然平衡。因此,在国际地圈-生物圈计划 的核心研究计划“全球变化与陆地生态系统”中,碳循环研究被确定为核心内容之一。进入21世纪,三大国际组织IGBP、IHDP、WCRP提出了一个碳集成研究计划,其重点是回答目前全球碳源、碳汇的时空格局及成因,未来碳循环动态的控制与反馈机制(人为的和自然的),未来全球碳循环的可能动态等科学问题。针对这些科学问题,一些国家先后启动了碳循环科学研究计划。中国国家自然科学基金委员会于1993年12月正式立项“中国陆地生态系统对全球变化的反应模式研究”,其目的同样是从区域和国家尺度回答与中国碳循环相关的科学问题。与此相关,也掀起了碳汇的热潮。
随着碳汇研究的热潮,科学家们研究出了不少计算碳汇的模型,但是如何展示并与现实世界联系起来,为地区固碳能力及碳汇的科学演变和监控提供技术参考是一个需要考虑的问题。本系统就由此入手,以模型计算的20年NEP据为基础,设计了数据展示、分析、管理等多方面功能。
1.2 系统概述
基于上述背景,本系统在现有的植被碳汇能力计算模型基础上,分析适用于研究区域的碳汇计算最优模型,以近20年研究区遥感数据为基础,构建近20年植被碳汇数据图谱模型,得到近20年植被碳汇时空信息。在Web系统部分,考虑到多方面展示地区碳汇数据及时空演变情况。本系统设计了地图展示、数据分析、信息展示、数据管理四模块内容,地图展示模块从主体上直观展示近20年NEP计算结果,同时叠加地区土地覆盖类型数据;数据分析模块以多维度展示江淮分水岭地区碳汇动态演变情况;信息展示模块展示系统关键信息;数据管理模块管理20年各地区碳汇数据情况。
二、系统设计
2.1 系统功能设计

图1.功能设计图
2.2数据库设计
空间数据储存在Porta for ArcGIS与ArcGIS Server联合托管的企业级地理数据库中,非空间数据储存在非关系型数据库—MySQL。这样将数据分类存储,有效地保证了数据的时效性及用户访问快捷性,同时方便了对各类数据进行操作、管理、分析以及更新。
2.2.1地理数据库
企业级地理数据库是数据库管理系统中的表、视图和存储过程的集合。该系统选择在Microsoft SQL Server中存储地理数据库,并将非地理数据库数据和地理数据库数据一同存储。在数据库中创建地理数据库时,建数据库、SDE 用户(具有所需权限)和 SDE方案,然后由SDE用户使用启用企业级地理数据库地理处理工具创建地理数据库。
2.2.2MySQL数据库
MySQL拥有运行速度快、使用成本低、容易操作、可移植性强,使用用户多等优点,更加方便处理和使用数据。同时使用node.js + express + axios的方式连接MySQL数据库,对MySQL中的数据进行增加和删减。数据库中部分数据的属性结构如表1、表2所示:
表1 近五年各区域植被净初级生成力标准差属性结构
| 字段名 | 字段类型 | 属性说明 |
| YEAR | INT | 年份 |
| MingG | DOUBLE | 明光市植被净初级生成力标准差值 |
| FengY | DOUBLE | 凤阳县植被净初级生成力标准差值 |
| TianC | DOUBLE | 天长市植被净初级生成力标准差值 |
| HuaiN | DOUBLE | 淮南市植被净初级生成力标准差值 |
| LaiA | DOUBLE | 来安县植被净初级生成力标准差值 |
| DingY | DOUBLE | 定远县植被净初级生成力标准差值 |
| Shou | DOUBLE | 寿县植被净初级生成力标准差值 |
| ChangF | DOUBLE | 长丰县植被净初级生成力标准差值 |
| HuoQ | DOUBLE | 霍邱县植被净初级生成力标准差值 |
| ChuZ | DOUBLE | 滁州市植被净初级生成力标准差值 |
| FeiD | DOUBLE | 肥东县植被净初级生成力标准差值 |
| QuanJ | DOUBLE | 全椒县植被净初级生成力标准差值 |
| FeiX | DOUBLE | 肥西县植被净初级生成力标准差值 |
| HeF | DOUBLE | 合肥市植被净初级生成力标准差值 |
| LuA | DOUBLE | 六安市植被净初级生成力标准差值 |
表2 近五年各区域植被净初级生成力标准差属性结构
| 字段名 | 字段类型 | 属性说明 |
| Id | INT | 用户编号 |
| Name | VARCHAR | 用户名 |
| | VARCHAR | 用户邮箱 |
| Date | DATE | 用户年龄 |
| Password | VARCHAR | 登录密码 |
三、关键技术
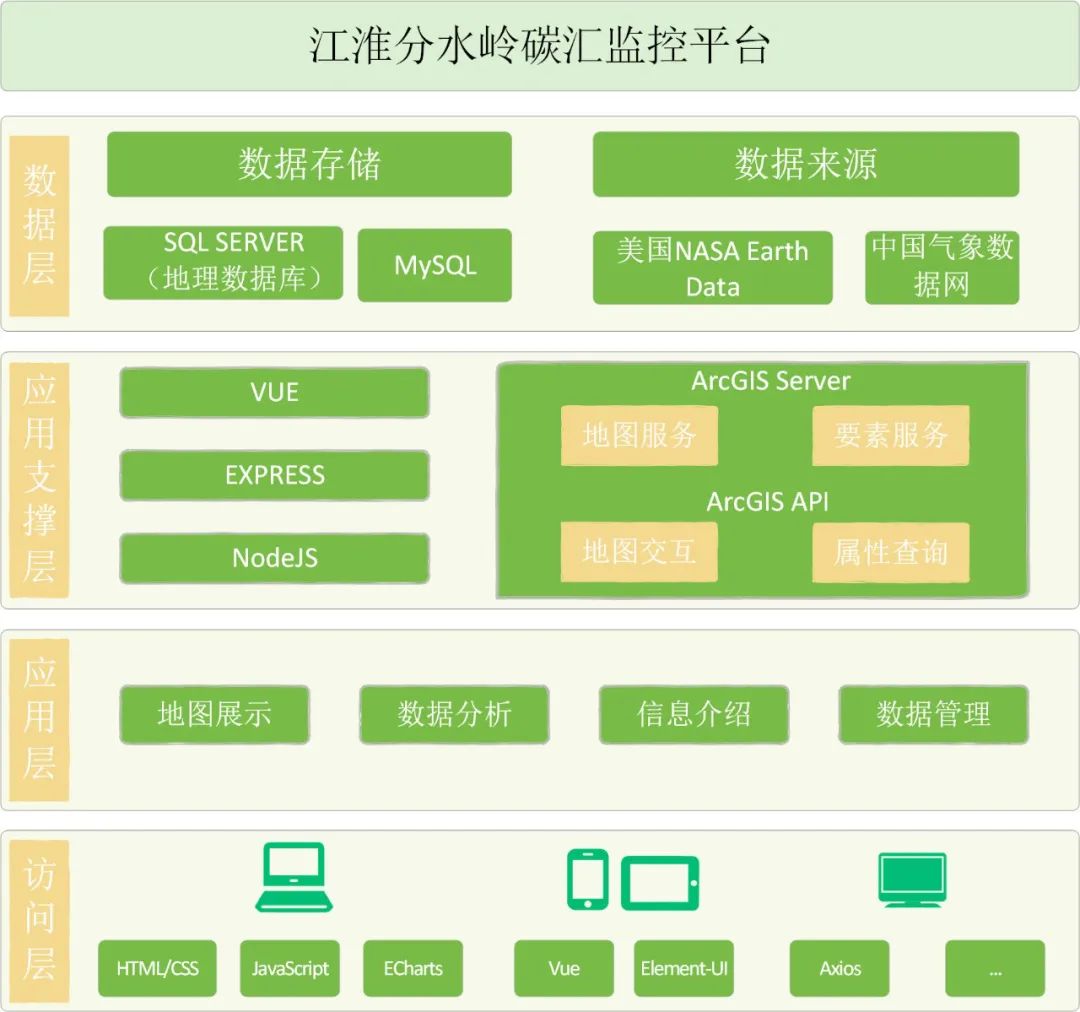
图2.系统架构图
四、功能实现
该系统主要分为地图展示,数据分析,信息介绍,数据管理四个主要模块。地图展示模块主要以地图可视化与数据分析的方式,针对2001~2021年江淮分水岭15县级区域生动展示每年植被碳汇数据;数据分析主要依托动态图表等对这20年研究区的植被碳汇数据总体进行分析,变化展示等;信息介绍主要包括对研究背景,研究区,数据来源以及模型公式等进行介绍;数据管理主要用于对新年份数据导入以及对错误信息的删除等。
1. 地图展示:
(1)江淮分水岭植被净初级生产力数据可视化: 可选择或输入查询需要查看得某年植被净初级生产力,底图上会出现该年各地NEP数据图层,并在右侧的展示框上出现该年各区域NEP总数据基本统计情况。
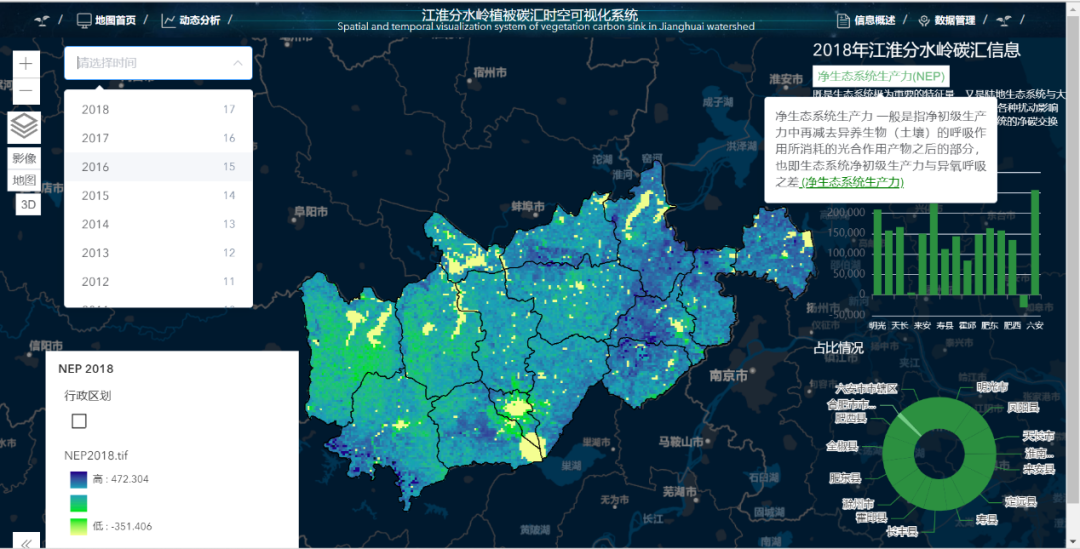
图3. 植被净初级生产力数据可视化模块
(2)信息介绍:可添加并叠加图层,向用户展示研究区域基本信息,同时可以点击按钮同时查看土地覆盖类型与植被净初级生产力,便于用户分析对比;
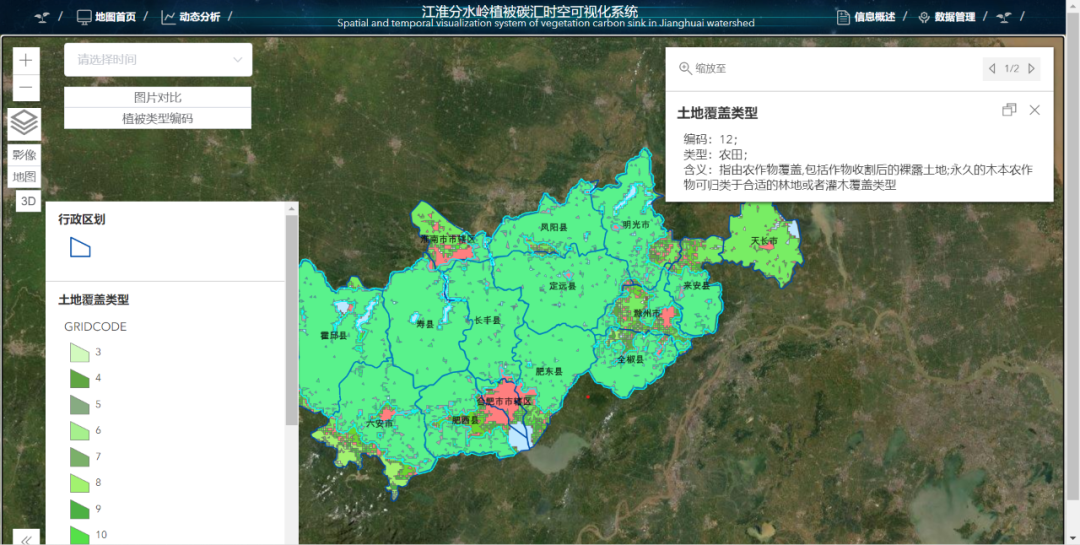
图4. 研究区域信息展示模块
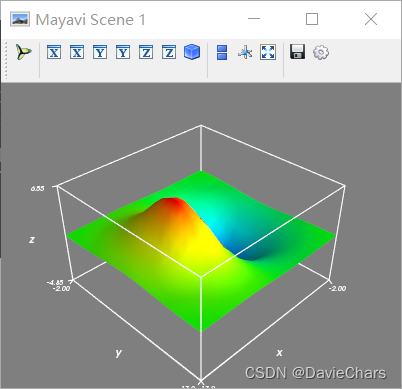
(3)3D分析模块:3D展示各年各区域NEP数据统计量。用户可通过右侧时间轴,点击查看不同时间各区域年NEP数据情况;
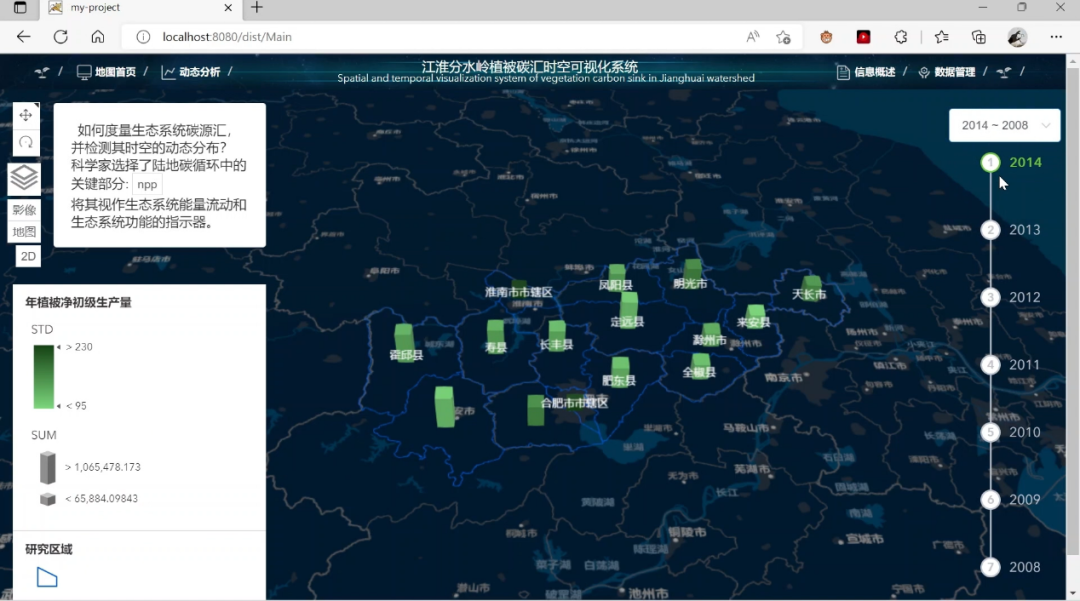
图5. 3D分析模块
2. 数据分析:
分别以柱状图和地图的形式,动态显示2001~2021年江淮分水岭各区域NPP年数据情况和2001~2018年江淮分水岭各区域NEP年数据情况;以表格的形式统计各指标达到的区域个数,以扇形图的形式展示各区域面积占比,以柱状图的形式统计各区域近五年NPP数值较平均值的增长情况;

图6. 数据分析NPP模块

图7. 数据分析NEP模块
3. 信息介绍:
以文字加图片的形式对研究区,背景以及运用计算公式模型进行介绍,同时以文字加视频的形式对数据处理方法进行基本的介绍;
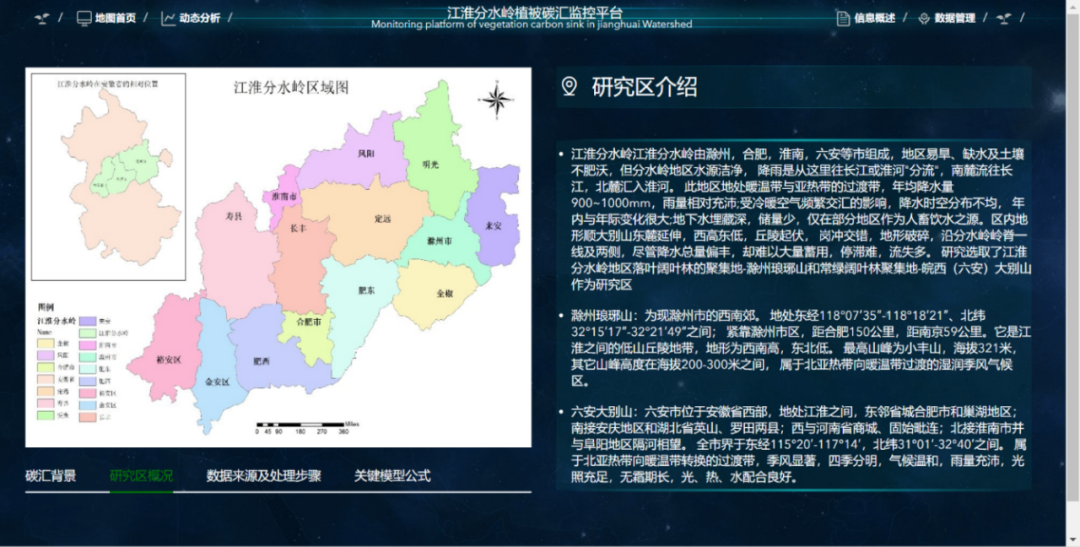
图8. 数据分析模块
4. 数据管理:
增加新年份的碳汇数据或删除错误数据,同时支持切换查看不同信息和下载信息表等功能。
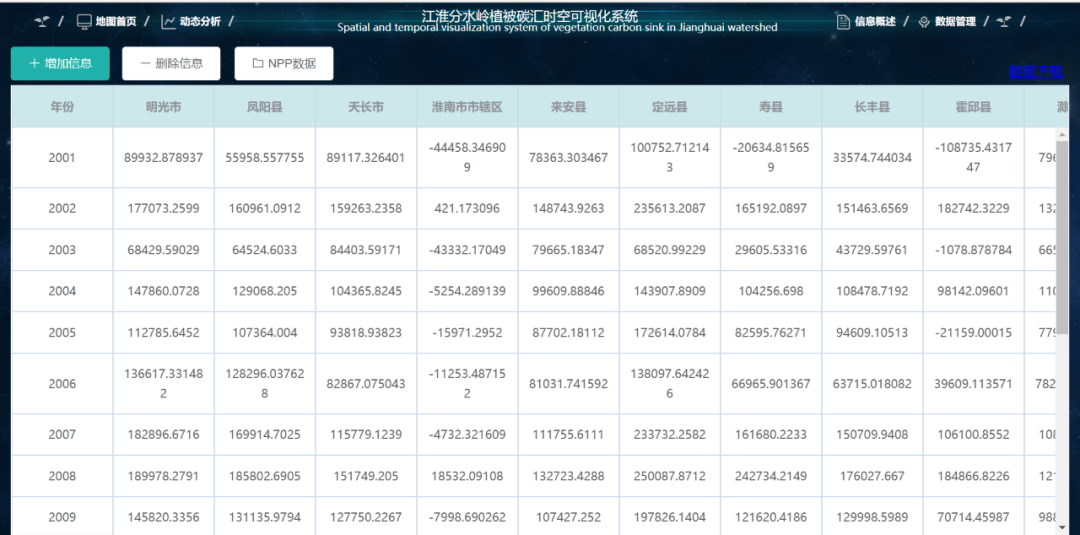
图9. 数据管理模块
五、关键亮点
1.数据来源:碳汇展示数据均为真实数据代入模型进行计算得来,数据真实可靠;
2.数据处理模型选择:通过比较各碳汇计算模型,选择了应用较为广泛的CASA模型进行研究区的碳汇计算,模型应用合适且具有较高可信度;
3.生态可视化: 系统使用了Vue.JS作为系统主要开发框架,而非使用原生JS进行开发,这使得系统的开发重心凝聚在功能的设计上,方便兼容ArcGIS API for JS、ECharts等多种前端库或与既有系统进行整合,为本系统的开发提供了保证,同时也实现了多维度展示信息的需求。




![Mysql问题:[Err] 1055 - Expression #1 of ORDER BY clause is not in GROUP BY clause](https://img-blog.csdnimg.cn/1066a58e1b5d4b119df843e604651406.png)





![Python蓝桥杯训练:基本数据结构 [二叉树] 中](https://img-blog.csdnimg.cn/dec5845a62084f10afa700ee7366802d.jpeg#pic_center)