Spark MLlib 模型训练
- 决策树
- 随机森林
- GBDT
Spark MLlib 开发框架下 :
- 监督学习 : 回归 (Regression) , 分类 (Classification) , 协同过滤 (Collaborative Filtering)
- 非监督学习 : 聚类 (Clustering) 、频繁项集 (Frequency Patterns)
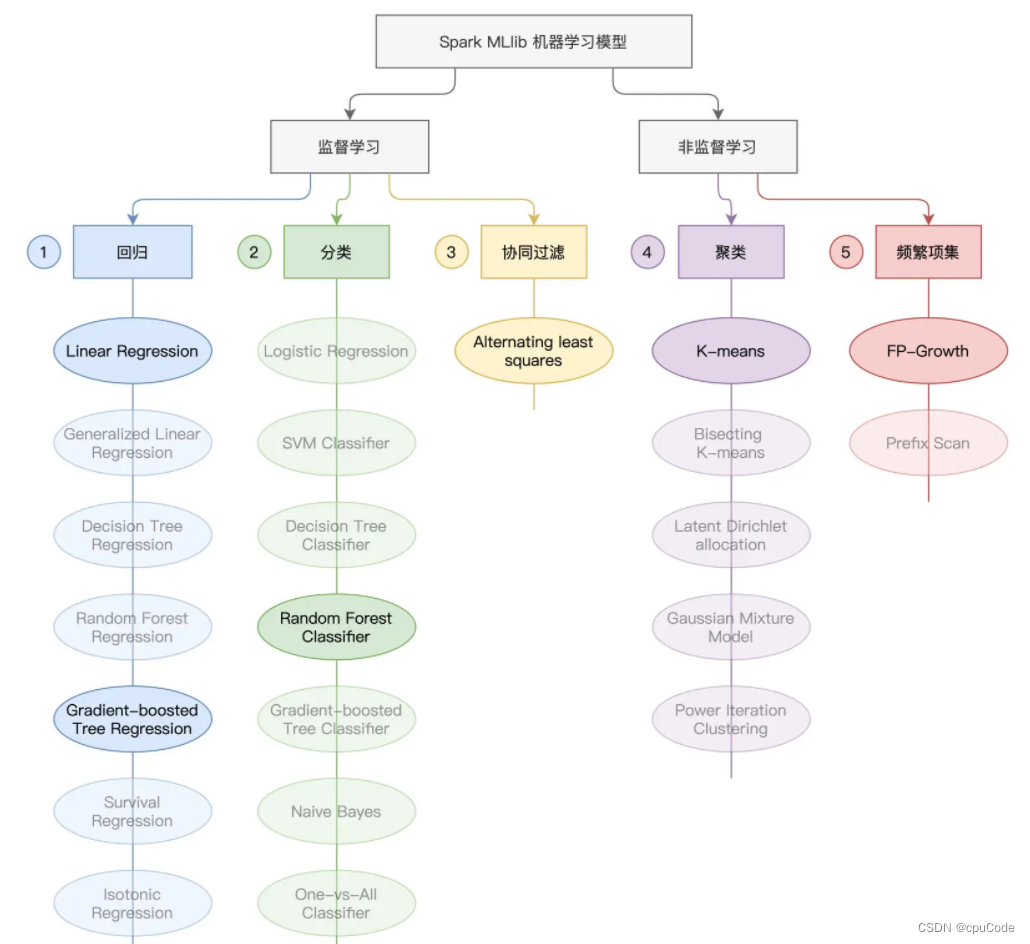
例子分类 :
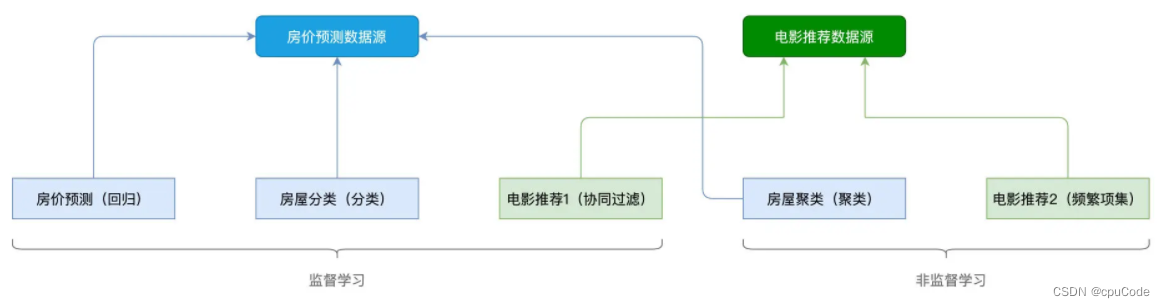
算法分类 :
| 算法分类 | 算法子分类 | 算法 | 原理 | 场景 |
|---|---|---|---|---|
| 监督学习 | 回归 , 分类 | 决策树 | 遍历每个特征, 构建决策树 | 解决分类, 回归 |
| 选所有数字字段 | GBDT | 每个树训练 , 都基于前树的拟合样本残差 , 使预测值逼近真实值 | ||
| 特征选择 | 随机森林 | 通过多树的随机选取训练样本与特征, | ||
| 归一化 | ALS | 用户, 物品推荐 | ||
| 非监督学习 | 聚类 | K-means | ||
| 频繁项集 | FPGrowth |
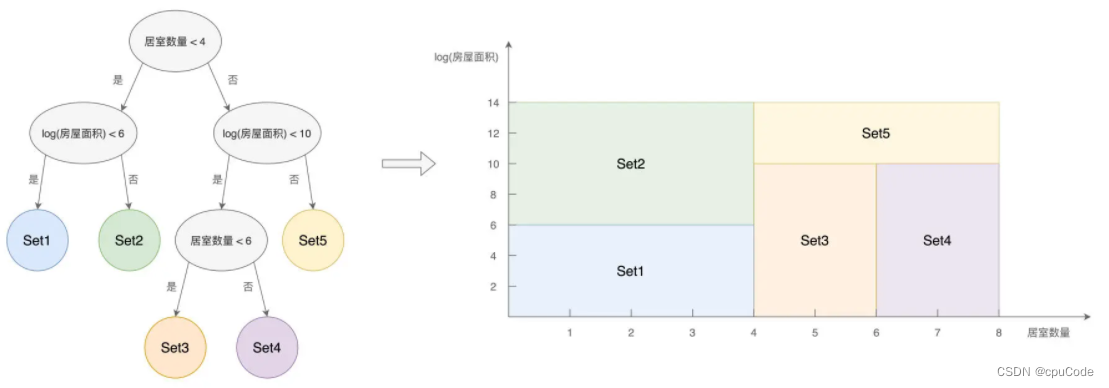
决策树
决策树 (Decision Trees) : 根据样本特征向量而构建的树形结构
- 决策树组成 : 由节点 (Nodes) 与有向边 (Vertexes)
- 节点分类 :
- 内部节点 : 样本特征
- 叶子节点 : 分类
决策树示意图 :
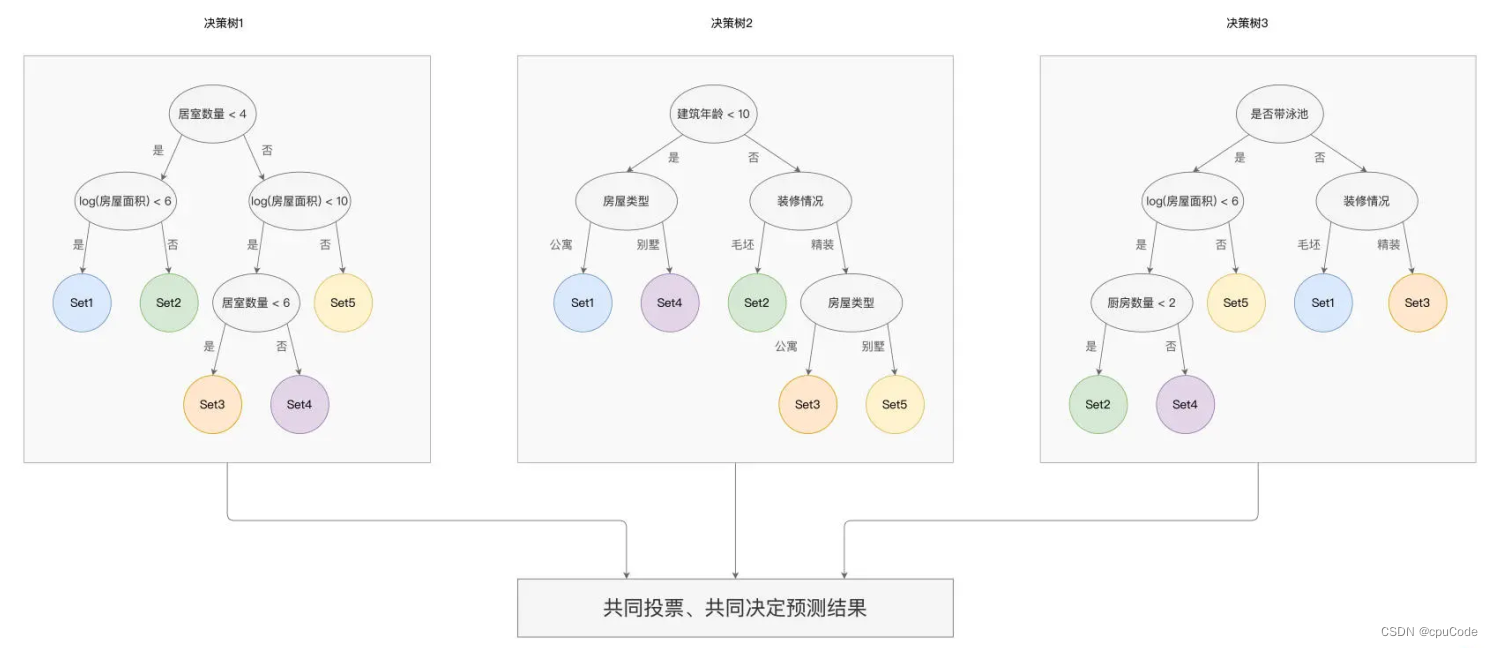
随机森林
随机森林 (Random Forest)
- 树与树相互独立,不存在任何依赖关系
- 最终的预测结果,以多数决策树为结果
GBDT
GBDT : 用多棵决策树来拟合数据样本,但树与树之间是有依赖关系的,每棵树的构建,都基于前棵树的训练结果
GBDT示意图 :
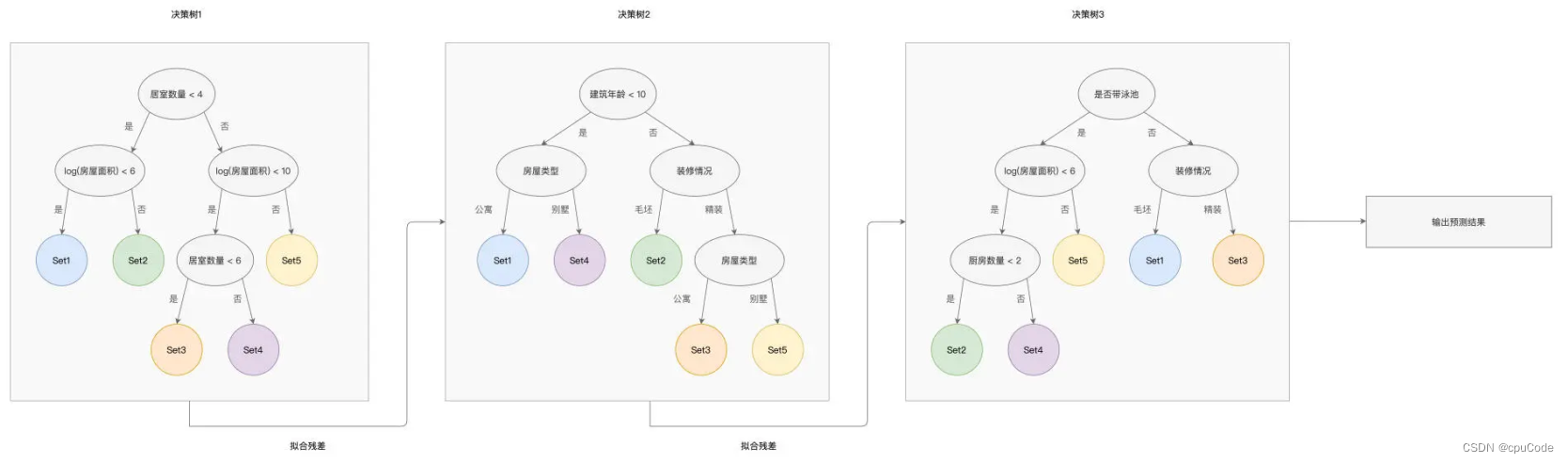
拟合残差 :
- 样本残差: 预测值与真实值 (Ground Truth) 之间的差值