一、概述
常见的排序算法有冒泡排序、插入排序、选择排序、快速排序、归并排序、桶排序、基数排序,这些排序各自有各自的特点。按照时间时间复杂度可以分为
- O(n^2):冒泡、插入、选择排序;
- O(nlogn):归并、快速排序;
- O(n):桶排序、计数排序、基数排序;
二、如何分析一个排序算法
- 最好、最坏、平均情况下的时间复杂度;
- 时间复杂度的常数、系数、低阶;
- 比较次数和交换(移动次数);
- 堆内存的消耗:针对空间复杂度,引入原地排序概念,就是指空间复杂度为O(1)的算法;
- 排序的稳定性:原序列中相同值数据的前后顺序在排序后会不会被打乱,分为稳定排序和不稳定排序;
三、冒泡排序
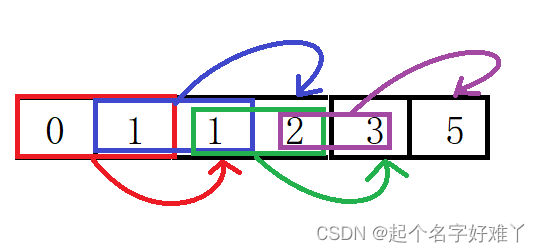
每次八前后两个元素比较,判断是否需要互换,一直到序列最后面,这样重复n次。最好情况在第一次排序后看有没有数据交换,如果没有的话说明此时已经有序了,时间复杂度时O(n^2)。 平均时间复杂度也是O(n^2)。
四、插入排序
将数据分为有序区间和无序区间,开始有序区间只有一个元素,然后从后面无序区间区第一个元素插入到有序区间中对应的位置。是原地排序,当遇到相同值时可以选择位置前后的防止,所以是稳定排序。可以选择从有序区间后面开始进行大小的比较,所以最好情况下时间复杂度为O(n),平均和最坏情况下时间复杂度都是O(n^2)。
相对于冒泡排序,插入排序在每次数据的移动比冒泡排序的数据交换简单,因此插入排序忧郁冒泡排序。

五、选择排序
将数据分为有序区间和无序区间,每次从无需区间找到最小值,放到有序区间的后面。空间复杂度是原地排序。不是稳定排序
六、归并排序
将序列递归的差分为左右两个区间,直到区间不能再拆分,然后在每次回归时将左右两个有序区间合并排序(类似两个有序链表的合并)。

//A是数组,n是数组大小
merge_sort(A, n)
{
merge_sort_c(A, p, r);
}
//A是数组,p是开始位置,r是结束位置
merge_sort_c(A, p, r)
{
if(q >= r)
{
return;
}
q = (p + r) / 2;
merge_sort_c(A, p, q);
merge_sort_c(A, q+1, r);
//将有序区间A[p, q],和A[q+1, r]合并为 A[p, r]
merge(A[p, q], A[q+1, r], A[p, r]);
}
对于merge(A[p, q], A[q+1, r], A[p, r])合并函数设计思路:建立一个大小为[p, r]的临时数组temp,将A[p, q], A[q+1, r]中数据按照大小一次放入,然后将temp的值赋给A[p, r]。因此归并排序不是原地排序。当[p, q], A[q+1, r]存在相同值时,我们可以选择总是将[p, q]的值放在前面,从而保证了数据的稳定性。
七、快速排序
快速排序采用由上到下的排序思路,每次选择一个参照节点,依照此节点的值,直接原地拆分为小于此节点值的区间和大于此节点值的两个区间,然后将前后两个区间在依照此方法递归拆分,直到无法拆分。
依照快排的拆分思路,如果要找到n个元素中的第k大的元素,可以选择拆分然后比较前后两个区间A[p, q]和A[q+1, r],判断q>k是否成立,从而选择继续实在前区间找还是在后区间继续找。
思考题
- 有 10 个接口访问日志文件,每个日志文件大小约 300MB,每个文件里的日志都是按照时间戳从小到大排序的。希望将这 10个较小的日志文件,合并为 1 个日志文件,合并之后的日志仍然按照时间戳从小到大排列。如果处理上述排序任务的机器内存只1GB,能“快速”地将这 10 个日志文件合并吗?
**思路:**为例充分利用内存,并减少io次数,理想状态下,每次从每个文件取40MB大小的记录(也不一定,保证文件拿到最后一个的花间戳取完,如果取不完的话,把这个取不完的时间戳舍弃掉不要)。然后在内存中采用归并的思路进行排序,每次从一个文件中把一条时间戳比较排序,然后把对应文件时间戳拿完。某个文件排完了,再从原文件里面计需取。当排序完成的为见到400MB时存储一次文件。
![[附源码]java毕业设计自治小区物业设备维护管理系统](https://img-blog.csdnimg.cn/c8ce617bd0f5444aa67f1f500d2b7720.png)
![[附源码]Python计算机毕业设计房地产销售系统](https://img-blog.csdnimg.cn/2086bf928f9f49eabaf961a06d9293f7.png)







类问题解决思路](https://img-blog.csdnimg.cn/img_convert/1d29937f9bc25c87cda7729a130be3a7.png)