1. 简单查询的解析方法
全表扫描:指针从第一条记录开始,依次逐行处理,直到最后一条记录结束;
横向选择+纵向投影=结果集2. 多表连接
交叉连接(笛卡尔积)
非等值连接
等值连接
内连
外连接(内连的扩展,左外,右外,全连接)
自连接
自然连接(内连,隐含连接条件,自动匹配连接字段)
集合运算 (多个结果集进行并、交、差)SQL> -- 范例:
SQL>
SQL> create table a1 (id int, name char (10));
create table b1 (id int, loc char (10));
insert into a1 values(1,'a');
Table created.
SQL>
Table created.
SQL> insert into a1 values(2,'b');
insert into a1 values(2,'c');
1 row created.
SQL>
1 row created.
SQL>
1 row created.
SQL> insert into a1 values(4,'d');
1 row created.
SQL> insert into b1 values(1,'A');
1 row created.
SQL> insert into b1 values(2,'B');
1 row created.
SQL> insert into b1 values(3,'C');
1 row created.
SQL> commit;
Commit complete.
SQL> select * from a1;
ID NAME
---------- ------------------------------
1 a
2 b
2 c
4 d
SQL> select * from b1;
ID LOC
---------- ------------------------------
1 A
2 B
3 C
SQL> 2.1 交叉连接/cross join(笛卡尔积)
连接条件无效或被省略,两个表的所有行都发生连接,所有行的组合都会返回(n*m)
SQL>
SQL> -- SQL99写法:
SQL> select * from a1 cross join b1;
ID NAME ID LOC
---------- ------------------------------ ---------- ------------------------------
1 a 1 A
2 b 1 A
2 c 1 A
4 d 1 A
1 a 2 B
2 b 2 B
2 c 2 B
4 d 2 B
1 a 3 C
2 b 3 C
2 c 3 C
4 d 3 C
12 rows selected.
SQL> -- oracle写法:
SQL> select * from a1, b1;
ID NAME ID LOC
---------- ------------------------------ ---------- ------------------------------
1 a 1 A
2 b 1 A
2 c 1 A
4 d 1 A
1 a 2 B
2 b 2 B
2 c 2 B
4 d 2 B
1 a 3 C
2 b 3 C
2 c 3 C
4 d 3 C
12 rows selected.
SQL> select * from a1 cross join b1;
ID NAME ID LOC
---------- ------------------------------ ---------- ------------------------------
1 a 1 A
2 b 1 A
2 c 1 A
4 d 1 A
1 a 2 B
2 b 2 B
2 c 2 B
4 d 2 B
1 a 3 C
2 b 3 C
2 c 3 C
4 d 3 C
12 rows selected.
SQL> -- 非等值连接:(连接条件非等值,也属于内连范畴)
SQL>
SQL> select * from salgrade;
GRADE LOSAL HISAL
---------- ---------- ----------
1 700 1200
2 1201 1400
3 1401 2000
4 2001 3000
5 3001 9999
SQL> select empno,ename,sal,grade,losal,hisal from emp,salgrade where sal between losal and hisal;
EMPNO ENAME SAL GRADE LOSAL HISAL
---------- ------------------------------ ---------- ---------- ---------- ----------
7369 SMITH 800 1 700 1200
7876 ADAMS 1100 1 700 1200
7900 JAMES 950 1 700 1200
7521 WARD 1250 2 1201 1400
7654 MARTIN 1250 2 1201 1400
7934 MILLER 1300 2 1201 1400
7499 ALLEN 1600 3 1401 2000
7844 TURNER 1500 3 1401 2000
7566 JONES 2975 4 2001 3000
7698 BLAKE 2850 4 2001 3000
7782 CLARK 2450 4 2001 3000
7788 SCOTT 3000 4 2001 3000
7902 FORD 3000 4 2001 3000
13 rows selected.
SQL> 2.2 内连接/inner join(等值连接)
SQL> -- SQL99写法:
SQL>
SQL> select * from a1 inner join b1 on a1.id = b1.id;
ID NAME ID LOC
---------- ------------------------------ ---------- ------------------------------
1 a 1 A
2 b 2 B
2 c 2 B
SQL> -- oracle写法:
SQL> select * from a1,b1 where a1.id = b1.id;
ID NAME ID LOC
---------- ------------------------------ ---------- ------------------------------
1 a 1 A
2 b 2 B
2 c 2 B
SQL> 2.3 外连接
在等值的数据基础上.也查询相应不等值的数据
2.3.1 左外连接/left join
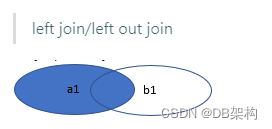
SQL>
SQL> -- SQL99语法:
SQL> select * from a1 left join b1 on a1.id = b1.id;
ID NAME ID LOC
---------- ------------------------------ ---------- ------------------------------
1 a 1 A
2 b 2 B
2 c 2 B
4 d
SQL> -- oracle语法:
SQL>
SQL> select * from a1, b1 where a1.id = b1.id(+);
ID NAME ID LOC
---------- ------------------------------ ---------- ------------------------------
1 a 1 A
2 b 2 B
2 c 2 B
4 d
SQL>
2.3.2 右外连接/right join
SQL>
SQL> -- SQL99语法:
SQL> select * from a1 right join b1 on a1.id = b1.id;
ID NAME ID LOC
---------- ------------------------------ ---------- ------------------------------
1 a 1 A
2 b 2 B
2 c 2 B
3 C
SQL> -- oracle语法:
SQL> select * from a1,b1 where a1.id(+)=b1.id;
ID NAME ID LOC
---------- ------------------------------ ---------- ------------------------------
1 a 1 A
2 b 2 B
2 c 2 B
3 C
SQL> 2.3.3 全外连接/full join
SQL> -- oracle语法:
SQL> select * from a1,b1 where a1.id(+)=b1.id;
ID NAME ID LOC
---------- ------------------------------ ---------- ------------------------------
1 a 1 A
2 b 2 B
2 c 2 B
3 C
SQL> -- SQL99语法:
SQL> select * from a1 full join b1 on a1.id = b1.id;
ID NAME ID LOC
---------- ------------------------------ ---------- ------------------------------
1 a 1 A
2 b 2 B
2 c 2 B
4 d
3 C
SQL> select * from a1,b1 where a1.id = b1.id (+)
2 union
3 select * from a1,b1 where a1.id(+)=b1.id;
ID NAME ID LOC
---------- ------------------------------ ---------- ------------------------------
1 a 1 A
2 b 2 B
2 c 2 B
4 d
3 C
SQL>
2.4 自连接/cross join
SQL>
SQL> -- sql99语法:
SQL>
SQL> select * from a1 cross join a1;
select * from a1 cross join a1
*
ERROR at line 1:
ORA-00918: column ambiguously defined
SQL> -- oracle语法:
SQL> select * from a1 x, a1 y;
ID NAME ID NAME
---------- ------------------------------ ---------- ------------------------------
1 a 1 a
1 a 2 b
1 a 2 c
1 a 4 d
2 b 1 a
2 b 2 b
2 b 2 c
2 b 4 d
2 c 1 a
2 c 2 b
2 c 2 c
2 c 4 d
4 d 1 a
4 d 2 b
4 d 2 c
4 d 4 d
16 rows selected.
SQL>
2.5 自然连接/natural join
属于内连中等值连接
在oralce中使用natural join,也就是自然连接.自然连接实验:
2.5.1 无公共列数据查询
SQL> select * from a1 natural join b1;
ID NAME LOC
---------- ------------------------------ ------------------------------
1 a A
2 b B
2 c B
SQL>
2.5.2 添加公共列
将两个表分别再加一个列ABC后,则有两个公共列(ID列和ABC列),添加数据后,再尝试自然连接如何匹配.
SQL> select * from a1 natural join b1;
ID NAME LOC
---------- ------------------------------ ------------------------------
1 a A
2 b B
2 c B
SQL>
SQL>
SQL> alter table a1 add abc char(2);
Table altered.
SQL> alter table b1 add abc char(2);
Table altered.
SQL>
SQL> select * from a1 natural join b1;
no rows selected
SQL>
2.5.3 新列插入数据
SQL>
SQL> update a1 set abc='s' where name='a';
1 row updated.
SQL> update a1 set abc='t' where name='b';
1 row updated.
SQL> update a1 set abc='u' where name='c';
1 row updated.
SQL> update a1 set abc='v' where name='d';
1 row updated.
SQL> update b1 set abc='w' where loc='A';
1 row updated.
SQL> update b1 set abc='t' where loc='B';
1 row updated.
SQL> update b1 set abc='r' where loc='C';
1 row updated.
SQL> select * from a1;
ID NAME ABC
---------- ------------------------------ ------
1 a s
2 b t
2 c u
4 d v
SQL> select * from b1;
ID LOC ABC
---------- ------------------------------ ------
1 A w
2 B t
3 C r
SQL> 2.5.4 查看自然连接如何匹配
SQL>
SQL> select * from a1 natural join b1;
ID ABC NAME LOC
---------- ------ ------------------------------ ------------------------------
2 t b B
SQL>
2.6 using关键字
当使用 natraul join 关键字时,如果两张表中有多个字段,它们具有相同的名称和数据类型,那么这些字段都将被oracle连接起来.
但如果名称相同,类型不同,或者需要在多个字段同时满足连接条件的情况下,想人为指定某个(些)字段做连接,那么可以使用using 关键字.在oracle连接(join)中使用using关键字
2.6.1 Using未引用的公共列要指定表名
SQL>
SQL> -- 此处的abc是公共列,要指定是a1表
SQL> select id,a1.abc, name, loc from a1 join b1 using(id);
ID ABC NAME LOC
---------- ------ ------------------------------ ------------------------------
1 s a A
2 t b B
2 u c B
SQL> -- 此处的abc是公共列,要指定是a1表
SQL> select id,abc, name, loc from a1 join b1 using(id);
select id,abc, name, loc from a1 join b1 using(id)
*
ERROR at line 1:
ORA-00918: column ambiguously defined
SQL> select * from a1;
ID NAME ABC
---------- ------------------------------ ------
1 a s
2 b t
2 c u
4 d v
SQL> select * from b1;
ID LOC ABC
---------- ------------------------------ ------
1 A w
2 B t
3 C r
SQL>
2.6.2 using引用的列名不可指定表
SQL>
SQL> -- using引用的列名不可指定表
SQL> select id,a1.abc, name, loc from a1 join b1 using(a1.id);
select id,a1.abc, name, loc from a1 join b1 using(a1.id)
*
ERROR at line 1:
ORA-01748: only simple column names allowed here
SQL>
2.6.3 using可指定多列
SQL>
SQL> select id,abc,name,loc from a1 join b1 using(id,abc);
ID ABC NAME LOC
---------- ------ ------------------------------ ------------------------------
2 t b B
SQL> -- select的公共列无需在using中指定表(using子句的列部分不能有限定词)
SQL> select id,a1.abc,name,loc from a1 join b1 using(id,abc);
select id,a1.abc,name,loc from a1 join b1 using(id,abc)
*
ERROR at line 1:
ORA-25154: column part of USING clause cannot have qualifier
SQL> select * from a1 join b1 using(id);
ID NAME ABC LOC ABC
---------- ------------------------------ ------ ------------------------------ ------
1 a s A w
2 b t B t
2 c u B t
SQL> 2.6.4 natural和using关键字不可同时出现
SQL>
SQL> -- natural和using关键字是互斥的
SQL> select * from a1 natural join b1 using(id);
select * from a1 natural join b1 using(id)
*
ERROR at line 1:
ORA-00933: SQL command not properly ended
SQL> 2.6.5 总结:
1、使用using关键字时,如果select的结果列表项中包含了using关键字所指明的那个关键字,那么,不要指明该关键字属于哪个表(知识点).
2、using中可以指定多个列名.
3、natural和using关键字是互斥的,也就是说不能同时出现.
在实际工作中看,内连接,左外连接,以及自然连接用的较多,而且两表连接时一般是多对一的情况居多,即a表行多,b表行少,从连接字段来看,b表为父表,其连接字段做主键, a表为子表,其连接字段为外键.
典型的就是dept表和emp表的关系,两表连接字段是deptno,键有主、外键关系
这与数据库设计要求符合第三范式有关.
SQL>
SQL> select * from emp; -- deptno外键
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
---------- ------------------------------ --------------------------- ---------- --------------- ---------- ---------- ----------
7369 SMITH CLERK 7902 17-DEC-80 800 20
7499 ALLEN SALESMAN 7698 20-FEB-81 1600 300 30
7521 WARD SALESMAN 7698 22-FEB-81 1250 500 30
7566 JONES MANAGER 7839 02-APR-81 2975 20
7654 MARTIN SALESMAN 7698 28-SEP-81 1250 1400 30
7698 BLAKE MANAGER 7839 01-MAY-81 2850 30
7782 CLARK MANAGER 7839 09-JUN-81 2450 10
7788 SCOTT ANALYST 7566 24-JAN-87 3000 20
7844 TURNER SALESMAN 7698 08-SEP-81 1500 0 30
7876 ADAMS CLERK 7788 02-APR-87 1100 20
7900 JAMES CLERK 7698 03-DEC-81 950 30
7902 FORD ANALYST 7566 03-DEC-81 3000 20
7934 MILLER CLERK 7782 23-JAN-82 1300 10
13 rows selected.
SQL> select * from dept; -- deptno主键
DEPTNO DNAME LOC
---------- ------------------------------------------ ---------------------------------------
10 ACCOUNTING NEW YORK
20 RESEARCH DALLAS
30 SALES CHICAGO
40 OPERATIONS BOSTON
SQL>
3. 集合运算
Union ,对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序;
Union All ,对两个结果集进行并集操作,包括所有重复行,不进行排序;
Intersect ,对两个结果集进行交集操作,不包括重复行、列名不必相同、但列的数量和数据类型必相同,同时进行默认规则的排序;
Minus ,对两个结果集进行差操作,不包括重复行,同时进行默认规则的排序. 集合操作有 并,交,差3种运算.
SQL>
SQL> -- 举例:
SQL> -- 新建一个表
SQL>
SQL> create table dept1 as select * from dept where rownum <=1;
Table created.
SQL> insert into dept1 values(80,'MARKTING','BEIJING');
1 row created.
SQL> select * from dept;
DEPTNO DNAME LOC
---------- ------------------------------------------ ---------------------------------------
10 ACCOUNTING NEW YORK
20 RESEARCH DALLAS
30 SALES CHICAGO
40 OPERATIONS BOSTON
SQL> select * from dept1;
DEPTNO DNAME LOC
---------- ------------------------------------------ ---------------------------------------
10 ACCOUNTING NEW YORK
80 MARKTING BEIJING
SQL>
3.1 union
对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序
SQL> select * from dept
2 union
3 select * from dept1;
DEPTNO DNAME LOC
---------- ------------------------------------------ ---------------------------------------
10 ACCOUNTING NEW YORK
20 RESEARCH DALLAS
30 SALES CHICAGO
40 OPERATIONS BOSTON
80 MARKTING BEIJING
SQL>
3.2 union all
对两个结果集进行并集操作,包括所有重复行,不进行排序;
SQL>
SQL> select * from dept
2 union all
3 select * from dept1;
DEPTNO DNAME LOC
---------- ------------------------------------------ ---------------------------------------
10 ACCOUNTING NEW YORK
20 RESEARCH DALLAS
30 SALES CHICAGO
40 OPERATIONS BOSTON
10 ACCOUNTING NEW YORK
80 MARKTING BEIJING
6 rows selected.
SQL>
特别注意:可以看出只有union all的结果集是没有排序的
3.3 intersect
SQL>
SQL> select * from dept
2 intersect
3 select * from dept1;
DEPTNO DNAME LOC
---------- ------------------------------------------ ---------------------------------------
10 ACCOUNTING NEW YORK
SQL>
3.4 minus
(注意谁minus谁)
SQL>
SQL> select * from dept
2 minus
3 select * from dept1;
DEPTNO DNAME LOC
---------- ------------------------------------------ ---------------------------------------
20 RESEARCH DALLAS
30 SALES CHICAGO
40 OPERATIONS BOSTON
SQL> select * from dept1 minus select * from dept;
DEPTNO DNAME LOC
---------- ------------------------------------------ ---------------------------------------
80 MARKTING BEIJING
SQL>
4. 集合运算中注意事项
4.1 列名不必相同,但大类型要匹配且顺序要对应
比如char 对varchar2,date对timestamp都可以,字段数要等同,不等需要补全.
SQL>
SQL> create table x (id_x int, name_x char (10));
Table created.
SQL> create table y (id_y int, name_y char (10), sal number (10,2));
Table created.
SQL> insert into x values (1, 'sohu');
1 row created.
SQL> insert into x values (1, 'sina');
1 row created.
SQL> insert into y values (1, 'sohu', 1000);
1 row created.
SQL> insert into y values (2, 'google', 2000);
1 row created.
SQL> commit;
Commit complete.
SQL> select * from x;
ID_X NAME_X
---------- ------------------------------
1 sohu
1 sina
SQL> select * from y;
ID_Y NAME_Y SAL
---------- ------------------------------ ----------
1 sohu 1000
2 google 2000
SQL> select id_x, name_x from x
2 union
3 select id_y,name_y from y;
ID_X NAME_X
---------- ------------------------------
1 sina
1 sohu
2 google
SQL> 4.2 多表可复合集合运算,四种运算符按自然先后顺序,特殊要求可以使用()
4.3 order by使用别名排序的问题
缺省情况下,集合运算后的结果集是按所有字段的组合进行排序的(除union all 外)
如果不希望缺省的排序,也可以使用order by显示排序
4.3.1 使用别名排序
SQL>
SQL> -- 使用别名排序
SQL> select id_x,name_x name from x
2 union
3 select id_y,name_y name from y
4 order by name;
ID_X NAME
---------- ------------------------------
2 google
1 sina
1 sohu
SQL> -- 参照第一个别名排序
SQL>
SQL> select id_x,name_x name from x
2 union
3 select id_y,name_y from y
4 order by name;
ID_X NAME
---------- ------------------------------
2 google
1 sina
1 sohu
SQL>
4.3.2 使用列号排序
SQL> -- 参照第一个select列的位置编号
SQL> select id_x, name_x from x
2 union
3 select id_y, name_y from y
4 order by 2;
ID_X NAME_X
---------- ------------------------------
2 google
1 sina
1 sohu
SQL> 显式order by是参照第一个select语句的列元素.所以order by后的列名只能是第一个select使用的列名、别名、列号(知识点)
4.3.3 补全的null值排序,则要使用别名
SQL>
SQL> select id_x, name_x name, to_number(null) from x
2 union
3 select id_y,name_y name , sal from y
4 order by sal;
order by sal
*
ERROR at line 4:
ORA-00904: "SAL": invalid identifier
SQL>
-- ORA-00904: "SAL": 标识符无效4.3.3.1 解决办法1:根据列号排序
SQL> select id_x, name_x name, to_number(null) from x
2 union
3 select id_y,name_y name , sal from y
4 order by sal;
order by sal
*
ERROR at line 4:
ORA-00904: "SAL": invalid identifier
SQL> select id_x, name_x name, to_number(null) from x
2 union
3 select id_y,name_y name , sal from y
4 order by 3;
ID_X NAME TO_NUMBER(NULL)
---------- ------------------------------ ---------------
1 sohu 1000
2 google 2000
1 sina
1 sohu
SQL>
SQL> 4.3.3.2 解决办法2:将第二个select放在前面
SQL>
SQL> select id_y,name_y name , sal from y
2 union
3 select id_x, name_x name, to_number(null) from x
4 order by sal;
ID_Y NAME SAL
---------- ------------------------------ ----------
1 sohu 1000
2 google 2000
1 sina
1 sohu
SQL>
4.3.3.3 解决办法3:按照别名排序
SQL> select id_x, name_x name, to_number(null) aa from x
2 union
3 select id_y,name_y name , sal aa from y
4 order by aa;
ID_X NAME AA
---------- ------------------------------ ----------
1 sohu 1000
2 google 2000
1 sina
1 sohu
SQL> 4.3.4 不能分别对个别表排序
排序是对结果集的排序(包括复合集合运算),不能分别对个别表排序,order by 只能出现一次且在最后一行;
SQL>
SQL> select id_x, name_x from x order by id_x
2 union
3 select id_y,name_y from y order by id_y;
union
*
ERROR at line 2:
ORA-00933: SQL command not properly ended
SQL>
-- ORA-00933: SQL 命令未正确结束