索引的底层原理(一)
- B-树索引
- B+树索引
tips:
通过使用malloc/new来申请4字节的内存,但是操作系统不是说每一次用户申请4字节内存,我就只分配4字节,这样申请次数多了就要涉及频繁的用户态和内核态的切换,开销比较大,所以我们调用malloc/new向系统申请内存时,系统的内存管理是以页为单位的(一个页面的大小为4k),系统分配2*4k大小的内存空间,其中4字节是我们所需要的,而剩下的空间由libc.so或者libc++.so库中的malloc实现ptmalloc或者tcmalloc来管理了,这样当后面我们继续申请内存时,就不用进行用户和内核态的切换,直接用户态下就能获得内存空间。
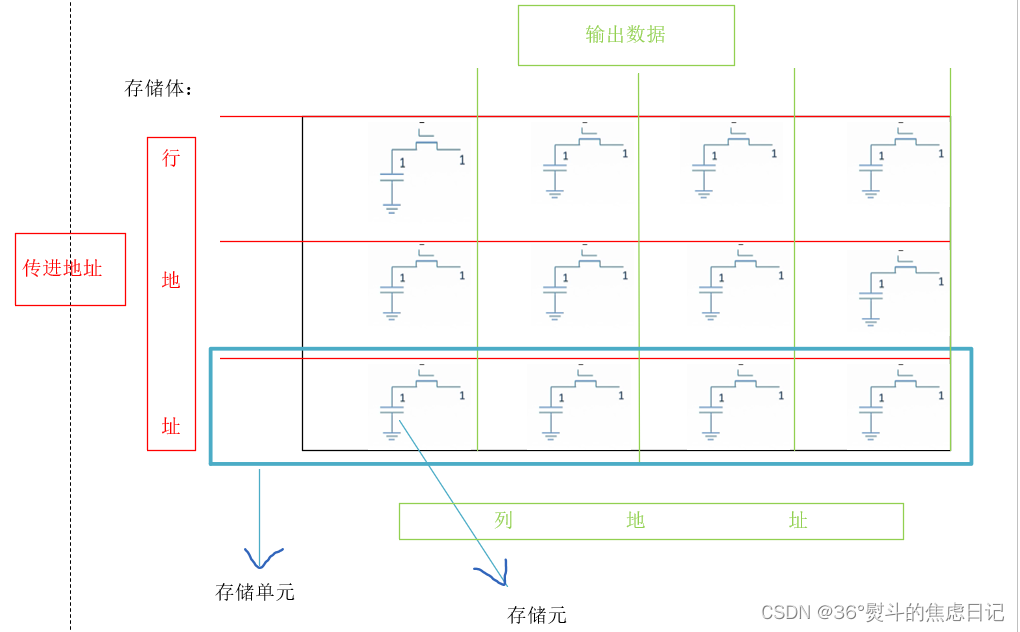
数据和索引都是存储在磁盘中的,所以MySQL Server执行查询的时候,需要花费磁盘I/O来把索引和数据读取到内存中,读取的单位是块,一般是16K,也是内存页面的整数倍
B-树索引
m阶平衡树,m一般取300~500
m取多少合适?最好的情况就是一次磁盘I/O读取的磁盘块的内容,刚好存储在B-树的一个节点中
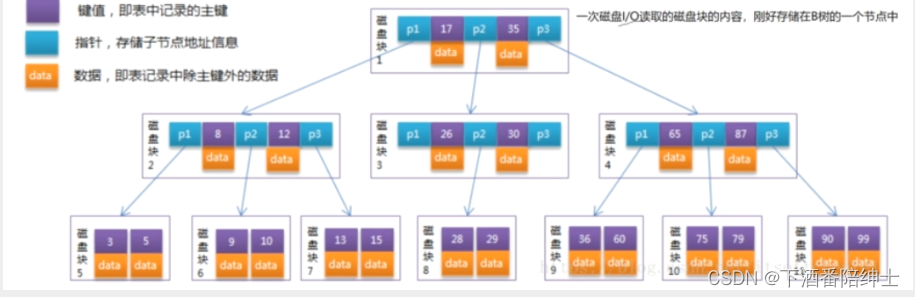
对于2000W规模的数据,取m为500,那么B-树只要三层(log2000W)<以m为底> ,花费的磁盘I/O不超过三次
当我们执行"select * from student where uid=5"这样的SQL语句时,uid是主键(InnoDB存储引擎自动为其添加索引),因为过滤条件中uid字段有索引,存储引擎就会向系统内核(kernel)请求进行磁盘I/O以读取索引文件的内容到内存中,然后在内存中用索引的数据构建B树来加快搜索。
我们再来看上面的B-树,其中键值(key)指的就是数据库表中创建了索引的字段的值,然后data里面存储的是数据本身还是数据在磁盘上的地址呢?这就和数据库表使用的存储引擎有关,我们知道MyISAM存储引擎是将数据以及索引分开进行存储的(.MYD,.MYI)所以此时data里面存储的就是数据在磁盘上的地址,而InnoDB是将数据和索引都存储在一个文件中(.ibd),所以data里面存储的就是数据本身
对于一个500阶平衡树,一个节点就有500个指针域指向孩子节点,我们可以看到每个节点中的数据(key)都是有序存储的,并且左孩子的值<父亲节点<右孩子,所以我们在一个节点中进行数据的搜索是按照二分搜索的方式进行的,就比如我们要搜索28,那我们在B-树中进行搜索的时间复杂度为O(logn)<以2为底>,虽然在二叉平衡树AVL中进行搜索所花费的时间复杂度也为O(logn)<以2为底>,虽然在内存中搜索的时间是一样的,但是最关键的地方在于使用B-树,一次磁盘I/O读取的磁盘块的内容,刚好存储能存储在B-树的一个节点中,这就意味着更少的磁盘I/O。
B+树索引
问题:为什么MySQL(MyISAM和InnoDB)索引底层选择B+树而不是B树呢?
-
索引+数据内容分散在不同的节点中,离根节点近,搜索就快;离根节点远,搜索就慢,这导致花费的磁盘I/O不平均,每一行搜索数据花费的时间也不平均
-
B-树中每一个节点不仅要存储key值还要存储key所对应的data,这样一个节点所能存放的key值得个数相比于只存放key值要少得多,key值的命中率也就会比较低
-
B-树不方便做范围搜索(比如where id<20这样的过滤条件,每一次都要搜索B-树),整表遍历也不方便
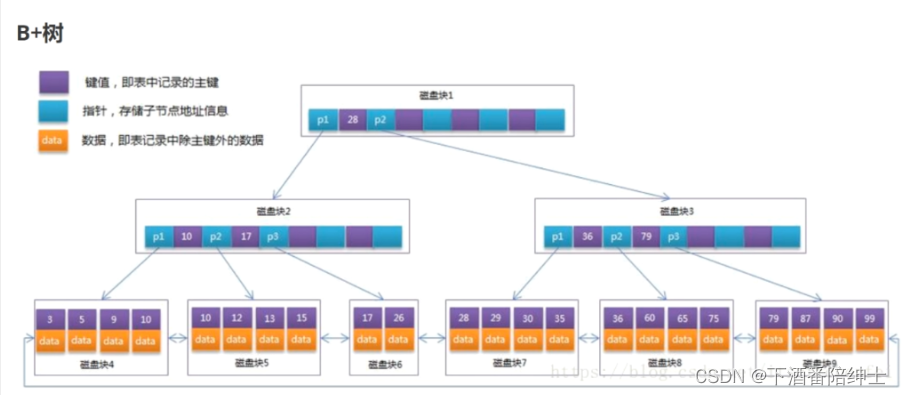
针对上面的问题,B+树都做了优化:
-
B+树每一个非叶子节点只存放key,不存储data,这样的好处就是一个节点存放的key值更多,B+树在理论上来说,层数会更低一些,搜索的效率会更好一些。
-
叶子节点上存储了所有的索引值,这就意味着每一个索引所对应的值data,都需要跑到叶子节点上,这样每一行记录搜索的时间是非常平均的!
-
B+树的叶子节点被串在一个链表中,形成了一个有序的链表,如果要进行索引树的搜索&整表搜索,直接遍历叶子节点的有序链表即可!或者做范围查询的时候,直接遍历叶子节点的有序链表即可!